
- 1最通俗易懂的PID讲解(控制原理详解及作用分析)
- 2醉里起始页源码(简洁大气免费开源)
- 3Python筑基之旅-MySQL数据库(三)
- 4云原生的应用性能监控:如何实现实时的性能观测
- 5从Windows docker desktop 软件的Dashboard启动docker时默认支持NVIDIA GPU_{ "builder": { "gc": { "defaultkeepstorage": "20gb
- 6正则表达式匹配任意字符(包括换行符)_正则表达式匹配包括换行符
- 7css实现图片边缘模糊效果_css 图片周围模糊
- 8【Qt UI相关】Qt设置窗体或控件的背景色透明_qt中如何使背景变成完全透明
- 9基于WEB课程教学网站的设计与实现(论文+源码)_Nueve_web课程设计源码
- 10CWRU数据说明_boudiaf a, moussaoui a, dahane a, et al. a compara
PySpark:DataFrame及其常用列操作_pyspark dataframe
赞
踩
Spark版本:V3.2.1
1. DataFrame
虽然RDD是Spark最基本的抽象,但RDD的计算函数对Spark而言是不透明的。也就是说Spark并不知道你要在计算函数里干什么。无论你是要做连接、过滤、选择还是聚合,对Spark来说都是一个lambda表达式而已。正是由于不能掌握RDD中的计算或表达式,因此Spark无法对表达式进行优化。
为了解决上述问题,从Spark 2.x开始,RDD被降级为低层的API,并提供了高层的结构化数据抽象:DataFrame和Dataset(Pyspark仅支持DataFrame)。DataFrame和Dataset都是基于RDD创建的。
DataFrame类似于传统数据库中的二维表格。DataFrame与 RDD的主要区别在于:前者带有schema 元信息,即DataFrame所表示的二维表数据集的每一列都带有名称和类型。同时DataFrame具有不可变的性质,所有转化操作不会改变原有的DataFrame,只会将转化的结果作为新的DataFrame返回。
2. DataFrame的创建
2.1 数据类型与表结构
Spark 的 DataFrame 的列支持的数据类型主要有:整型、字符串型、数组、映射表、实数、日期、时间戳等。DataFrame中的数据类型与Python中的数据类型的对应关系如下(这些数据类型的API在pyspark.sql.types中):
| 数据类型 | Python中对应的数据类型 |
|---|---|
| ByteType | int |
| ShortType | int |
| IntegerType | int |
| LongType | int |
| FloatType | float |
| DoubleType | float |
| StringType | str |
| BooleanType | bool |
| DecimalType | decimal.Decimal |
| BinaryType | bytearray |
| TimestampType | datetime.datatime |
| DateType | datetime.date |
| ArrayType | 列表、多元组或数组 |
| MapType | dict |
| StructType | 列表或元组 |
| StructField | 表示字段类型定义的值 |
Spark中的表结构为DataFrame定义了各列的名字和对应的数据类型。表结构既可以在读取数据由Spark推断,也可以提前定义。定义表结构的两种方式如下:
- from pyspark.sql import SparkSession
- from pyspark.sql.types import *
- #使用编程的方式定义表结构
- schema=StructType([
- StructField('author',StringType(),False),
- StructField('title',StringType(),False),
- StructField('pages',IntegerType(),False)
- ])
- #使用数据定义语言(DDL)定义表结构
- schema="author STRING,title STRING,pages INT"
StructField()方法中的参数主要有以下几种:
- name: 指定字段名;
- datatype:指定字段数据类型;
- nullable:指定是否可以接受空值;
- metadata: 元数据(暂时还不知道这个字段是怎么用的)
相比于在读取数据时确定表结构,提前定义表结构有如下三个优点:
- 可以避免Spark推断数据类型的额外开销;
- 防伪Spark为决定表结构而单独创建一个作业来从数据文件读取很大一部分内容;
- 如果数据与表结构不匹配,可以尽早发现错误;
Tips:这里重点补充几种不常用的数据类型的使用。具体如下:
- from pyspark.sql import SparkSession
- from pyspark.sql.types import *
- from decimal import Decimal
-
- data=[(bytearray('hello','utf-8'),[1,2,3],Decimal(5.5)),
- (bytearray('AB','utf-8'),[2,3,4],Decimal(4.5)),
- (bytearray('AC','utf-8'),[3,4],Decimal.from_float(4.5))]
-
- schema=StructType([StructField('A',BinaryType()),
- StructField('B',ArrayType(elementType=IntegerType())),
- StructField('C', DecimalType())])
-
- spark=SparkSession.builder.appName("jsonRDD").getOrCreate()
-
- df=spark.createDataFrame(data,schema)
另外,关于DataFrame中的数据类型还需要注意一些问题:https://blog.csdn.net/yeshang_lady/article/details/127465717
2.2 构造DataFrame
- 使用createDataFrame构建DataFrame
createDataFrame()可以将像List型的数据转变为DataFrame,也可以将RDD转化成DataFrame。
- from pyspark.sql import SparkSession
- from pyspark.sql.types import *
- import pandas as pd
- from pyspark.sql import Row
- from datetime import datetime, date
-
- #RDD转化为DataFrame
- spark=SparkSession.builder.appName("jsonRDD").getOrCreate()
- sc=spark.sparkContext
- stringJSONRDD=sc.parallelize([
- ["123","Katie",19,"brown"],
- ["234","Michael",22,"green"],
- ["345","Simone",23,"blue"]])
- schema=StructType([StructField("id", StringType(),False),
- StructField("name", StringType(),False),
- StructField("age", IntegerType(),False),
- StructField("eyeColor", StringType(),False)])
-
- df=spark.createDataFrame(stringJSONRDD,schema=schema)
- df.show()
-
- #将静态数据转化为DataFrame
- data=[['124','Joe',23,'black'],
- ['125','Mark',24,'green']]
- df1=spark.createDataFrame(data,schema=schema)
- df1.show()
-
- data=pd.DataFrame(data,columns=['id','name','age','eyeColor'])
- df2=spark.createDataFrame(data)
- df2.show()
-
- #利用Row对象构DataFrame
- df3=spark.createDataFrame([
- Row(a=1, b=2., c='string1', d=date(2000, 1, 1), e=datetime(2000, 1, 1, 12, 0)),
- Row(a=2, b=3., c='string2', d=date(2000, 2, 1), e=datetime(2000, 1, 2, 12, 0)),
- Row(a=4, b=5., c='string3', d=date(2000, 3, 1), e=datetime(2000, 1, 3, 12, 0))])
- df3.show()

其结果如下:
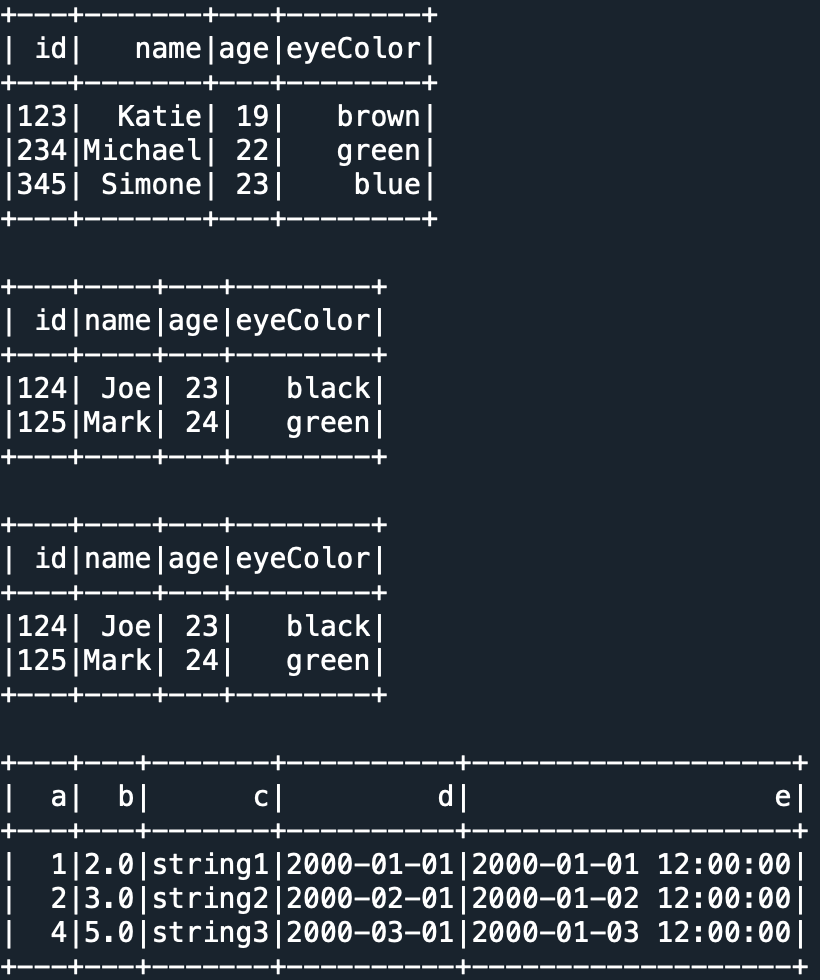
注意:虽然python是动态类型语言,但使用pyspark时依然要注意数据类型。比如,若在data中的age的定义若既使用了整型22,又使用了float型19.0的话,在创建DataFrame时会报TypeError错。
- 从外部数据源中读取数据到DataFrame——DataFrameReader推荐方法
Spark提供了DataFrameReader这个接口,允许从JSON、CSV、Parquet、Text、Avro、ORC等各种数据源读取数据到DataFrame。但要注意,只能通过SparkSession实例访问DataFrameReader。也就是说不能自行创建DataFrameReader实例。Spark中获取该实例句柄的方式如下:
- SparkSession.read
- SparkSession.readStream
其中read方法返回的DataFrameReader句柄可以用来从静态数据源读取DataFrame,而readStream方法返回的实例则用于读取流失数据源。DataFrameReader句柄推荐的使用模式如下:
DataFrameReader.format(args).option("key","value").schema(args).load()其中的方法、参数和选项如下:
- format: 可选参数有:"parquet"(默认值)、"csv"、"txt"、“json”、"jdbc"、"orc"、"avro"等;
- option: 一系列键值对;
- schema: DDL字符串或StructType对象;
- load: 读取的数据源路径;
其用法如下:
- from pyspark.sql import SparkSession
- from pyspark.sql.types import *
-
- spark=SparkSession.builder.appName("csvRDD").getOrCreate()
-
- schema=StructType([StructField('State',StringType()),
- StructField('Color',StringType()),
- StructField('Count',IntegerType()) ])
- df=spark.read.format('csv').option("header",True).schema(schema).\
- load(r'/data/mnm_dataset.csv')
- df.show(10)
其结果如下:

- 从外部数据源中读取数据到DataFrame——各种类型数据的专用方法
除了上文使用的DataFrameReader推荐方式之外,SparkSession.read还为各种数据类型提供了专门的数据读取方法。其方法名称如下:csv()、json()、text()、parquet()、jdbc()、orc()等。这里要说明一点,使用上述DataFramerReader推荐的使用方式读取外部数据数据的时候,不同的数据类型其option()方法中可选的key即为对应方法中的参数,value即为该参数的取值。上述读取CSV文件的代码等价于下述代码:
- df=spark.read.csv(path=r'/data/mnm_dataset.csv',schema=schema,
- header=True)
3. 列操作
Spark DataFrame中的列是具有公有方法的对象,以Column类表示。Column实例是可单独存在的,并且可以持有一个表达式,Column实例会在使用时,和调用的DataFrame相关联,这个表达式将作用于每一条数据, 对每条数据都生成一个值。
在Spark中既可以列出所有列的名字,也可以使用关系型或计算型的表达式对相应列的值进行操作。为了将Colum对象的操作结果显示出来,这里将会用到DataFrame的select()和show()方法。
3.1 DataFrame取列的方法
- data=[(123,"Katie",19,'brown'),
- (234,"Michael",22,"green"),
- (345,"Simone",57,"blue")]
- schema=StructType([
- StructField("id",LongType(),True),StructField("name",StringType(),True),
- StructField("age",LongType(),True),StructField("eyeColor",StringType(),True)])
-
- df=spark.createDataFrame(data,schema)
- #取列的名称
- print(df.columns)
-
- print(df['id'],df.name)
其结果如下:
![]()
3.2 Column表达式
Spark DataFrame不仅支持对列使用关系型或计算型的表达式,也支持逻辑表达式。举例如下:
- data=[(123,"Katie",19,'brown'),
- (234,"Michael",22,"green"),
- (345,"Simone",57,"blue")]
- schema=StructType([
- StructField("id",LongType(),True),StructField("name",StringType(),True),
- StructField("age",LongType(),True),StructField("eyeColor",StringType(),True)])
-
- df=spark.createDataFrame(data,schema)
- df.select(df.age+1,df.age==19,
- df.id!=df.age,
- (df.age==19)|(df.id==123),
- (df.age==19)&(df.id==123)).show()
其结果如下:

3.3 Column对象自带方法
这里主要介绍几种Column对象自带的方法,具体如下:
- alias()方法修改列名(select的用法在第4部分)
- df.select(df['age']+1).show()
- df.select((df['age']+1).alias('new_age')).show()
其结果如下:

- asc()、desc()返回排序表达式
- df.sort(df['age'].asc()).show()
- df.sort(df['age'].desc()).show()
其结果如下:

除了这两个排序方法之外,asc_nulls_first()、asc_nulls_last()、desc_nulls_first()、desc_nulls_last()方法规定了空值的位置。
- cast()、astype()方法修改数据类型,这两个方法作用相同
- df_1=df.withColumn('str_age',df['age'].cast("string"))
- print(df_1.dtypes)
其结果如下:
![]()
- contains()、startswith()、endswith()、like()、rlike()、substr()字符串操作方法
- #contains:判断字符串是否包含特定字符串
- #starswith:判断字符串是否以特定字符串开头
- #endswith:判断字符是否以特定字符串结尾
- #rlike:判断字符串是否符合特定正则表达式、
- #like:SQL中的like
- #substr:提取子串
-
- from pyspark.sql import functions as func
-
- data=[(123,"Katie",19,'brown',2),
- (234,"Michael",22,"green",4),
- (345,"Simone",57,"blue",3)]
- schema=StructType([
- StructField("id",LongType(),True),StructField("name",StringType(),True),
- StructField("age",LongType(),True),StructField("eyeColor",StringType(),True),
- StructField('len', IntegerType(),True)])
-
- df=spark.createDataFrame(data,schema)
- df.select(df.name.contains('M').alias('A'),df.name.startswith('K').alias('B'),
- df.name.endswith('e').alias('C'),df.name.rlike('[\w]+').alias('D'),
- df.name.like('Ka%').alias('E'),df.name.substr(2,3).alias('F'),
- df.name.substr(func.lit(1),df.len).alias('G')).show()
其结果如下:
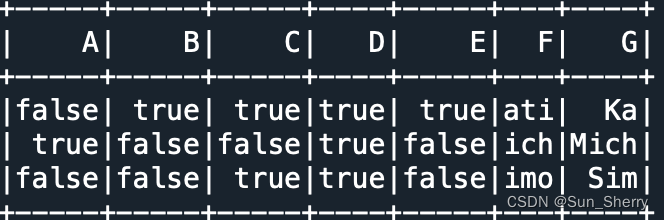
注意:使用substr()时字符串的索引位置是从1开始的;另外substr()的两个参数可以是int型变量也可以是Column型变量,只要这两个参数保持一致即可。
- between()方法判断数值是否在指定的范围内
df.select(df.age.between(22,57)).show()其结果如下:

- 两个Column实例进行二进制按位运算:bitwiseAND()、bitwiseOR()、bitwiseXOR()
- data=[(123,19,),(234,22),(345,57)]
- df=spark.createDataFrame(data,['a','b'])
- df.select(df.a.bitwiseAND(df.b),
- df.a.bitwiseOR(df.b),
- df.a.bitwiseXOR(df.b)).show()
其结果如下:

- dropFields()、withField()、getField()方法向DataFrame中的嵌套Row中删除元素、添加元素、获取对应元素
- df.select(df.value.getField('age')).show()
- df.select(df.value.withField('School',func.lit('TsingHua'))).show()
- df.select(df.value.dropFields('age')).show()
其结果如下:
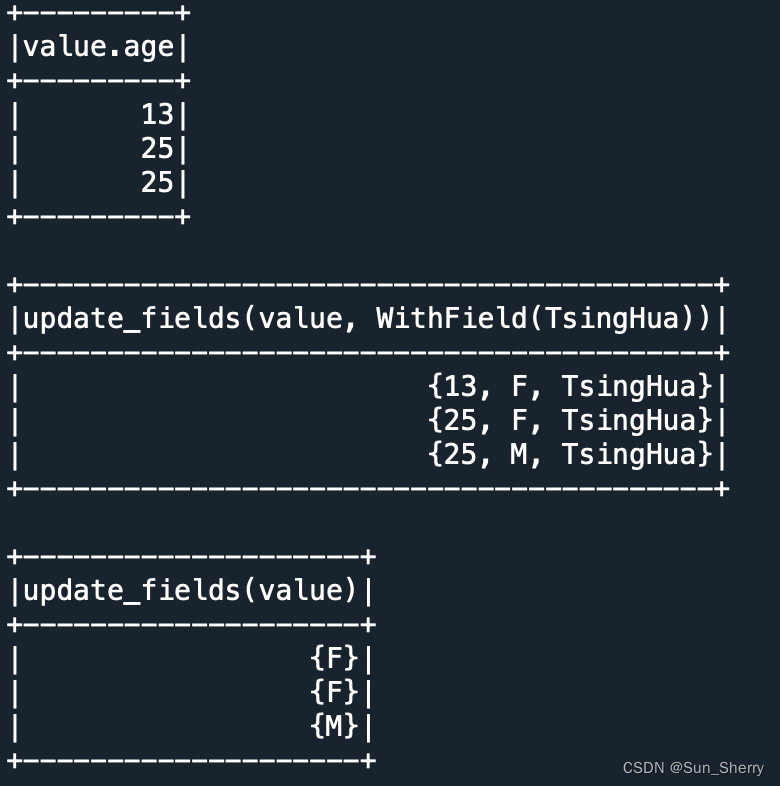
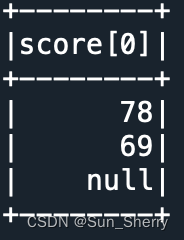
- getItem()方法按索引获取ArrayType类型数据的元素
- from pyspark.sql import Row
-
- data=[Row(name='Alice',score=[78,90,85]),
- Row(name='Bob',score=[69,85]),
- Row(name='Jack',score=None)]
- df=spark.createDataFrame(data)
-
- df.select(df.score.getItem(0)).show()
其结果如下:
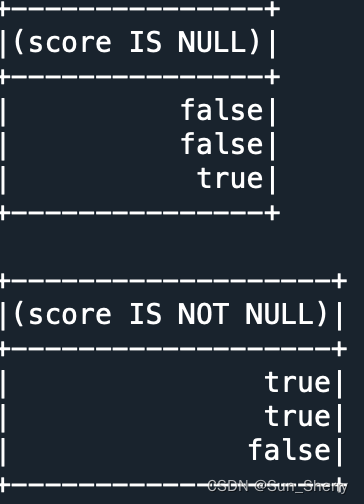
- isNotNull()、isNull()判断是否为空
- from pyspark.sql import Row
-
- data=[Row(name='Alice',score=78),
- Row(name='Bob',score=69),
- Row(name='Jack',score=None)]
- df=spark.createDataFrame(data)
-
- df.select(df.score.isNull()).show()
- df.select(df.score.isNotNull()).show()
其结果如下:
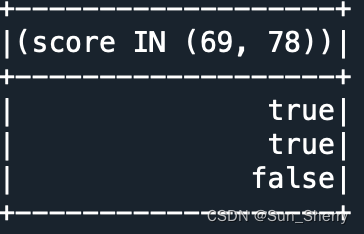
- isin()对数据进行筛选
- from pyspark.sql import Row
-
- data=[Row(name='Alice',score=78),
- Row(name='Bob',score=69),
- Row(name='Jack',score=100)]
- df=spark.createDataFrame(data)
- df.select(df.score.isin([69,78])).show()
其结果如下:
- eqNullSafe()空值比较
- from pyspark.sql import Row
-
- data=[Row(name='Alice',score=float('NaN')),
- Row(name='Bob',score=69.0),
- Row(name='Jack',score=None)]
- df=spark.createDataFrame(data)
- df.select(df.score==None,df.score.eqNullSafe(None),
- df.score.eqNullSafe(float('Nan'))).show()
其结果如下:

3.4 pyspark.sql.funcitons包中提供的方法
pyspark.sql.functions包中也提供了很多可以对DataFrame的列进行操作的方法。这里有一些与Column自带的方法同名的方法,不再赘述。
- 数学类(Math)方法
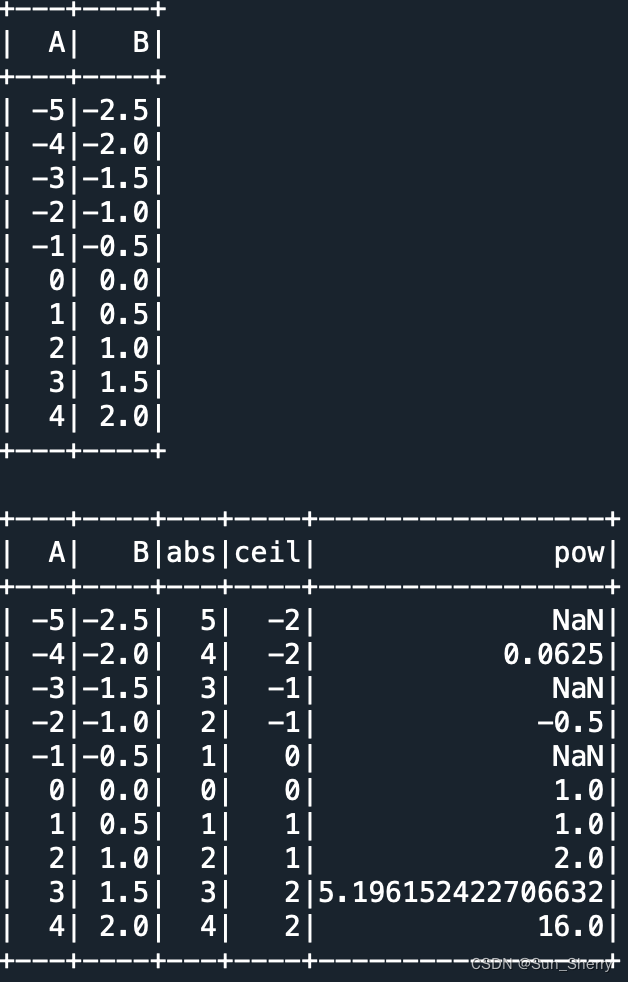
数值类计算操作主要包括:abs、acos、acosh、asin、asinh、atan、atan2、atanh、cos、cosh、exp、expm1(其结果为exp()-1)、pow、sqrt、tan、tanh、sin、sinh、log、log10、log1p、log2、ceil(向上取整)、floor(向下取整)、round(HALF-UP型四舍五入)、bround(HALF-EVEN型四舍五入)、rint(返回最靠近该值的双精度整数)、cbrt(立方根)、factorial(阶乘)、corr()、signum(符号函数)、hypot(其计算值为sqrt(col1^2+col2^2))、degrees(将以弧度为单位测量的角度转换为以度为单位测量的近似等效角度)、radians(degrees的逆操作)。仅以几个例子进行说明:
- from pyspark.sql.types import *
- from pyspark.sql import SparkSession
- from pyspark.sql import functions as func
-
- spark=SparkSession.builder.appName("jsonRDD").getOrCreate()
-
- data=[[item,item*0.5] for item in range(-5,5)]
- df=spark.createDataFrame(data,['A','B'])
- df.show()
- df.select('A','B',func.abs('A').alias('abs'),func.ceil('B').alias('ceil'),
- func.pow('A','B').alias('pow')).show()
其他结果如下:
- 聚合操作
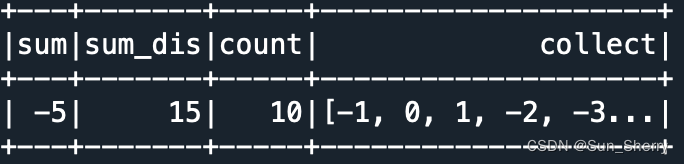
常用的聚合操作有:avg、mean、min、max、count、count_distinct(不同值计数)、sum、sum_distinct(不同的值的总和)、stddev、stddev_pop、stddev_samp、var_pop、var_samp、variance、first(返回群组的第1个值)、last(返回群组的最后一个值)、skewness(偏度)、kurtosis(峰度)、aggregate、approx_count_distinct(近似不同值计数)、grouping(指定分组列表中的列是否聚合)、grouping_id(指定分组的层级)、collect_list(把某一列的值聚合成一个列表)、collect_set(把某一列的值聚合成一个集合,去重)。用法举例如下:
- data=[[item,item*0.5] for item in range(-5,5)]
- df=spark.createDataFrame(data,['A','B'])
-
- df.select(func.sum('A').alias('sum'),
- func.sum_distinct(func.abs('A')).alias('sum_dis'),
- func.count('A').alias('count'),
- func.collect_set('A').alias('collect')).show()
其结果如下:
- ArrayType类型列操作
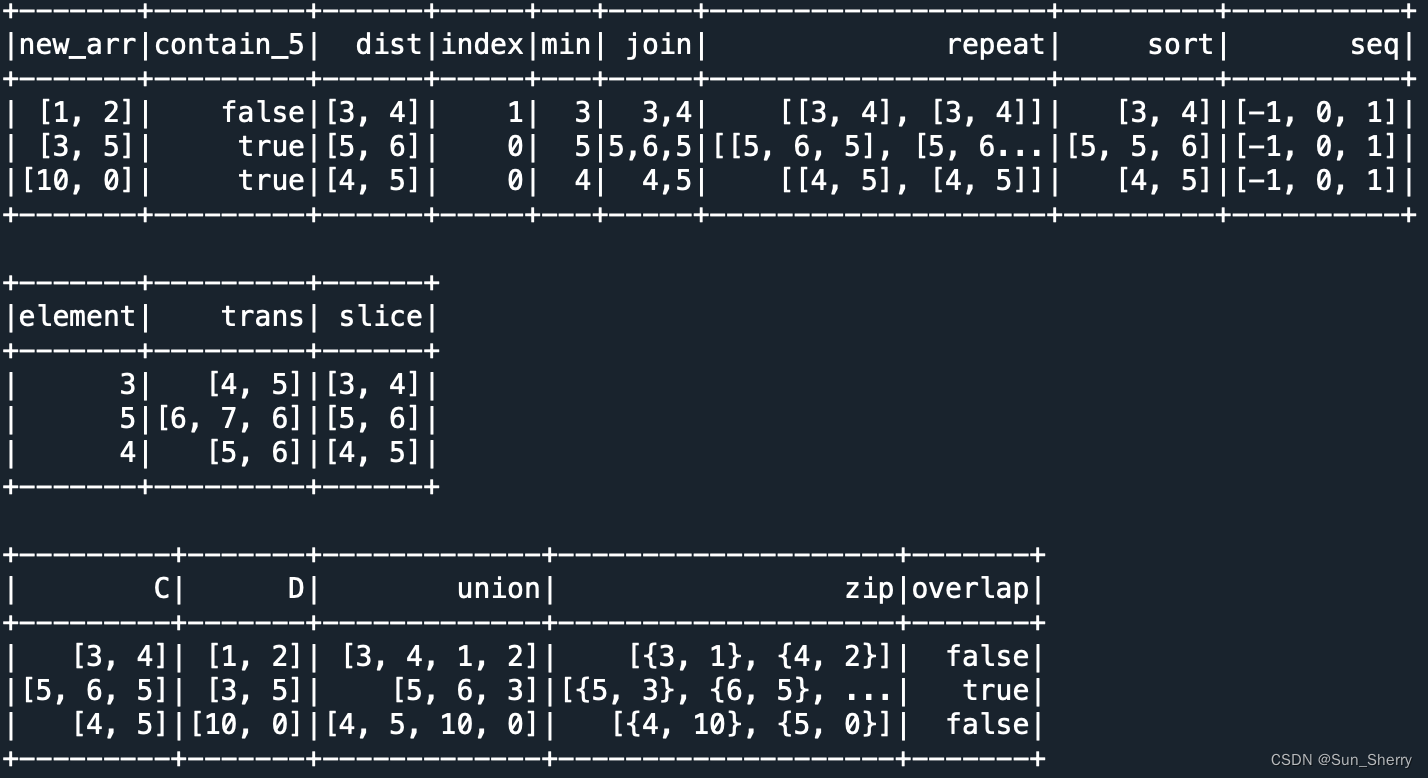
常用的ArrayType类型列操作: array(将两个表合并成array)、array_contains、array_distinct、array_except(两个array的差集)、array_intersect(两个array的交集不去重)、array_join、array_max、array_min、array_position(返回指定元素在array中的索引,索引值从1开始,若不存在则返回0)、array_remove、array_repeat、array_sort、array_union(求两个array的并集,不去重)、arrays_overlap(如果两个array中包含非空的相同元素,则返回True;如果两个array中都包含空元素,返回空;否则返回False)、arrays_zip、size、sort_array(可以指定是否逆序)、slice、element_at(返回指定索引的值)、flatten、forall(判断array中的所有元素是否都满足设定的条件)、shuffle、transform(对array中的每个元素进行转化)、sequence(类似range)、zip_with。用法举例如下:
- data=[(1,2,[3,4]),(3,5,[5,6,5]),(10,0,[4,5])]
- df=spark.createDataFrame(data,['A','B','C'])
-
- df.select(func.array('A','B').alias('new_arr'),
- func.array_contains('C', 5).alias('contain_5'),
- func.array_distinct('C').alias('dist'),
- func.array_position('C', 3).alias('index'),
- func.array_min('C').alias('min'),
- func.array_join('C',',').alias('join'),
- func.array_repeat('C',2).alias('repeat'),
- func.array_sort('C').alias('sort'),
- func.sequence(func.lit(-1),func.lit(1)).alias('seq')).show()
-
- df.select(func.element_at('C', 1).alias('element'),
- func.transform('C',lambda x:x+1).alias('trans'),
- func.slice('C',1,2).alias('slice')).show()
-
- df=df.withColumn('D',func.array('A','B'))
- df.select('C','D',
- func.array_union('C','D').alias('union'),
- func.arrays_zip('C','D').alias('zip'),
- func.arrays_overlap('C', 'D').alias('overlap')).show()
其结果如下:
- 日期类操作
常用的日期类操作有:current_date、current_timestamp、date_add、date_format(将日期转化为指定格式)、date_sub、date_trunc(在指定位置对数据进行阶截断)、datediff、dayofmonth、dayofweek、dayofyear、hour、minute、month、months_between(两个日期相差的月份数)、next_day(返回日期之后第一个周几)、quarter、second、timestamp_seconds(将时间戳转化为日期)、weekofyear、year、to_date、to_timestamp、to_utc_timestamp、unix_timestamp(将日期转化为时间戳)、trunc(将日期在指定位置截断)、add_months、session_window、from_unixtime(将时间戳转化为日期)、from_utc_timestamp(将时间戳转化为日期)、last_day(返回日前所在月份的最后一天)。
- data=[('2012-10-23','2013-01-15'),
- ('2013-03-05','2013-05-07'),
- ('2014-04-03','2015-09-13')]
- df=spark.createDataFrame(data,['startdate','enddate'])
-
- df.select(func.dayofweek('startdate').alias('A'),
- func.date_sub('startdate',2).alias('B'),
- func.datediff('enddate','startdate').alias('C'),
- func.month('startdate').alias('D'),
- func.quarter('startdate').alias('E'),
- func.year('startdate').alias('F'),
- func.next_day('startdate','Sun').alias('G'),
- func.current_date().alias('H'),
- func.date_trunc('mon','startdate').alias('trunc')).show()
其结果如下:

补充:date_trunc中的format的取值为: 'year', 'yyyy', 'yy' , 'month', 'mon', 'mm''day', 'dd', 'microsecond', 'millisecond', 'second', 'minute', 'hour', 'week', 'quarter'
- 字符串操作
常用的字符类操作有:ascii(返回字符串首字母的ASCII值)、concat、concat_ws、length、lower、lpad、ltrim、regexp_extract(按正则表达式进行抽取)、regexp_replace、repeat、reverse、rpad、rtrim、split、substring(抽取子串)、substring_index(返回第n个分隔符之前的所有字符)、translate、trim、locate(返回指定位置之后某个字符第一次出现的位置)、initcap(字符串首字母大写)、input_file_name(从当前spark任务中的文件中创建字符串)、instr(返回子串第一次出现时的位置索引)、levenshtein(两个字符串的编辑距离)、sentences(将字符串分割成句子的集合)、to_json、to_csv。用法举例如下:
- data=[('a','abc','def'),
- ('c','defg','adc'),
- ('d','edge','ghi')]
- df=spark.createDataFrame(data,['A','B','C'])
-
- df.select('A','B','C',
- func.ascii('B').alias('B_ascii'),
- func.length('C').alias('C_len'),
- func.lpad('A',3,'#').alias('A_lpad'),
- func.concat('B','C').alias('B_C_concat'),
- func.concat_ws('_','A','B','C').alias('ABC_concat_ws'),
- func.reverse('B').alias('B_reverse'),
- func.substring('B',1,3).alias('B_substring'),
- func.translate('B','abcd','123').alias('B_translate')).show()
-
- #translate中:a->1,b->2,c->3,d-''
其结果如下:

- map型操作
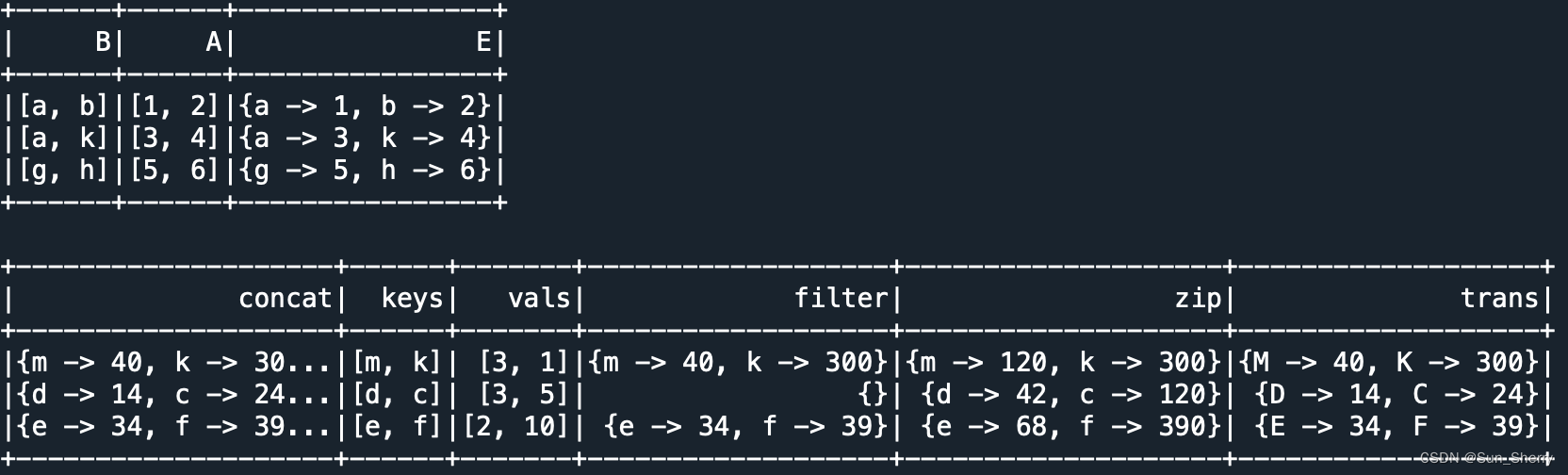
常用的map型操作有:create_map、map_concat(将两个列组合成map)、map_entries、map_filter、map_from_arrays、map_from_entries、map_keys、map_values、map_zip_with、explode(将map的key和value分成两列)、explode_outer(将map的key和value分成两行)、transform_keys(对key进行操作)、transform_values(对value进行操作)。用法举例如下:
- data=[([1,2],['a','b'],{'m':40,'k':300},{'m':3,'k':1}),
- ([3,4],['a','k'],{'d':14,'c':24},{'d':3,'c':5}),
- ([5,6],['g','h'],{'e':34,'f':39},{'e':2,'f':10})]
-
- df=spark.createDataFrame(data,['A','B','C','D'])
-
- df=df.withColumn('E',func.map_from_arrays('B', 'A'))
-
- df.select('B','A','E').show()
- df.select(func.map_concat('C','E').alias('concat'),
- func.map_keys('C').alias('keys'),
- func.map_values('D').alias('vals'),
- func.map_filter('C',lambda k,v:v>30).alias('filter'),
- func.map_zip_with('C','D',lambda k,v1,v2:v1*v2).alias('zip'),
- func.transform_keys('C',lambda x,_:func.upper(x)).alias('trans')).show()
其结果如下:
- 多列操作
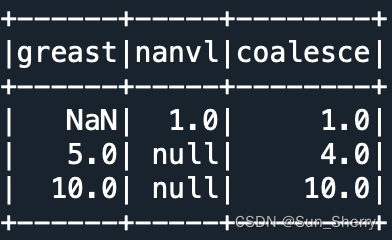
这一类方法可以同时对多个列进行操作。常用的方法主要包括:greatest、least、nanvl(如果第一列的值为空,则返回第二列的值)、coalesce(返回第一个不为空的列值)。用法举例如下:
- data=[(1,float('nan'),2,3),
- (None,None,4,5),
- (None,None,None,10)]
-
- df=spark.createDataFrame(data,['A','B','C','D'])
-
- df.select(func.greatest('A','B','C','D').alias('greast'),
- func.nanvl('A','B').alias('nanvl'),
- func.coalesce('A','B','C','D').alias('coalesce')).show()
其结果如下:
- 窗口函数
Spark SQL中的窗口函数用法与MySQL 8中的窗口函数相同,关于窗口函数的理论可以参考:MySQL8.0中的窗口函数_Sun_Sherry的博客-CSDN博客_mysql8窗口函数
Spark DataFrame中常用的窗口函数有:rank、dense_rank、row_number、ntile、nth_value、lead、lag、percent_rank、cume_dist。另外聚合函数也可以作为窗口函数。用法举例如下:
- from pyspark.sql import Window as win
-
- data=[('A',1,2),('B',3,4),
- ("A",4,5),('C',7,9),
- ('C',4,0),('B',8,2)]
-
- df=spark.createDataFrame(data,['C1','C2','C3'])
-
- df.select('C1','C2','c3',
- func.rank().over(win.partitionBy('C1').orderBy('C3')).alias('C4'),
- func.sum('C3').over(win.partitionBy('C1').orderBy('C2').\
- rowsBetween(win.unboundedPreceding, win.currentRow)).alias('C5')).show()
其结果如下:

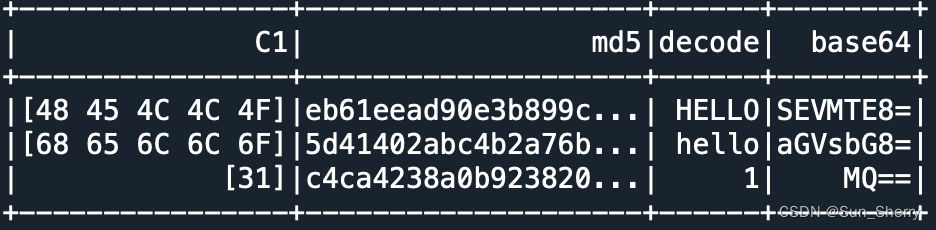
- 二进制列操作
常用的二进制列方法有:decode、encode、base64、unbase64、sha1、sha2、xxhash64、md5、hash。用法举例如下:
- data=[([bytearray('HELLO','utf-8')]),
- ([bytearray('hello','utf-8')]),
- ([bytearray('1','utf-8')])]
-
- df=spark.createDataFrame(data,['C1'])
- df.select('C1',
- func.md5('C1').alias('md5'),
- func.decode('C1','utf-8').alias('decode'),
- func.base64('C1').alias('base64')).show()
结果如下:
- 分区函数
常用的分区转化函数有:days、hours、months、years。
- 位转移
常用的位转移方法有:shiftleft、shiftright、shiftrightunsigned。用法举例如下:
- data=[[item] for item in range(0,5)]
- df=spark.createDataFrame(data,['A'])
-
- df.select('A',
- func.shiftleft('A',3).alias('shift_left'),
- func.shiftrightunsigned('A',1).alias('shift-right')).show()
其结果如下;

- 进制转换
常用的进制转换方法有:hex(返回16进制对应的数据)、unhex()、conv(进制转换)、bin(将数据的整数部分转化成二进制)
- data=[('AB3',2.3),
- ('2DA',4.5),
- ('48F',4.2)]
-
- df=spark.createDataFrame(data,['A','B'])
- df.select('A','B',
- func.hex('A').alias('hex'),
- func.conv('A',16,8).alias('conv'),
- func.bin('B').alias('bin')).show()
其结果如下:

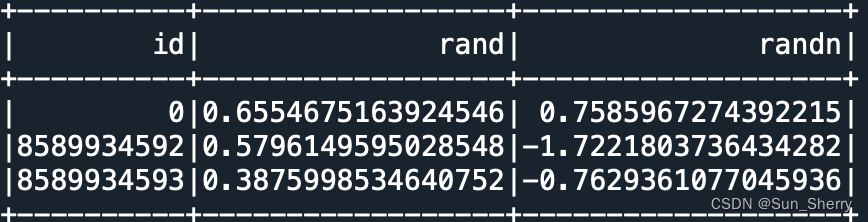
- 创建特定的列
常用的创建特定的列的方法有:monotonically_increasing_id(自增)、lit(常量列)、rand(随机数)、randn(随机数)。用法举例如下:
- data=[('AB3',2.3),
- ('2DA',4.5),
- ('48F',4.2)]
-
- df=spark.createDataFrame(data,['A','B'])
- df.select(func.monotonically_increasing_id().alias('id'),
- func.rand().alias('rand'),
- func.randn().alias('randn')).show()
其用法如下:
- 其他方法
(1) when()……otherwise()条件判断,类似于SQL中的case……when
- data=[('AB3',2.3),
- ('2DA',4.5),
- ('48F',4.2)]
-
- df=spark.createDataFrame(data,['A','B'])
- df.select('B',
- func.when(func.col('B')>3,True).otherwise(False).alias('when')).show()
其结果如下:

(2) udf(f,returnType)自定义函数
- data=[('AB3',2.3),
- ('2DA',4.5),
- ('48F',4.2)]
-
- new_func=func.udf(lambda x:True if x>3 else False,BooleanType())
- df=spark.createDataFrame(data,['A','B'])
- df.select('B',
- new_func('B').alias('new_col')).show()
其结果如下:

(3) pandas_udf()使用Pandas中的函数
- from pyspark.sql.functions import pandas_udf
-
- data=[('AB3',2.3),('2DA',4.5),('48F',4.2)]
- df=spark.createDataFrame(data,['A','B'])
- new_func1=func.pandas_udf(lambda x:x.str.len(),IntegerType())
- new_func2=func.pandas_udf(lambda x:x>3,BooleanType())
- df.select(new_func1('A').alias('A_len'),
- new_func2('B').alias('B_TF')).show()
-
- @pandas_udf("int")
- def new_func3(x:pd.Series) -> pd.Series:
- return x.str.len()
-
- @pandas_udf('boolean')
- def new_func4(x:pd.Series) -> pd.Series:
- return x>3
-
- df.select(new_func3('A').alias('A_len1'),
- new_func4('B').alias('B_TF1')).show()
其结果如下:

关于pandas_udf有以下几点需要说明:
- 使用pandas_udf()需要安装pandas和PyArrow包。
- pandas_udf()中f的定义中的参数x相当于pandas.Series,可以直接使用pandas.Series自带的所有函数和方法,而udf()中f的定义中的x则对应DataFrame中对应的Column列中的每一个元素。
- pandas_udf()中的可选参数functionType在未来的版本中会弃用,spark推荐使用类型提示(type hints)来代替functionType。上述四个使用pandas_udf定义的函数:new_func1、new_func2、new_func3和new_func4。其中new_func1和new_func3、new_func2和new_func4的作用相同,而new_func3和new_func4才是推荐的写法。
参考文献
- 《Spark快速大数据分析》

