
- 1单链表基本操作(2)_6-1 单链表
- 2Python学习干货,如何用Python进行数据分析?_在熟悉各种典型的数据预处理方法原理的基础上,选择数据分析工具python语言进行数
- 342. 【农产品溯源项目前后端Demo】后端-区块链连接服务_区块链网络 连接前端连还是后端连
- 4Python制作【大麦网】抢票程序,看演唱会再也不怕没票了_python 操控苹果手机抢大麦网演唱会的票
- 5node【引入模块查找机制】_npm模块搜索
- 6(大数据静态处理demo)flume+hadoop+hive+sqoop+mysql
- 7mac上搭建鸿蒙开发环境(2024)_鸿蒙 mac
- 8Vue3项目运行Error: Cannot find module ‘vue-loader-v16/package.json‘问题处理_loader error 3
- 9如何解决“来自计算机网络的异常流量”_我们的系统检测到您的计算机网络中存在异常流量。请稍后重新发送请求。为什么会这
- 10可能是MacOS中最好用的集成开发工具-Xcode初学者(C/C++ 新生)教程_xcode 开发教程
识别物体是否存在_图像识别 -- 新思路?
赞
踩
康德最重要的著作《纯粹理性批判》的核心思想是,不是主体被动反映客体,而是主体主动构造客体。先有概念(范畴),然后才能“看见”物体。
所谓“真实外部世界”就是我们的认知范畴创造的世界,康德把真正的外部世界叫做“物自体”——有一个东西在那里,你要认知它真正是什么,以及何所由来,永远不可知。
经过康德大神的启发性思考,我们来认真思考,人类大脑是如何认知猫就是猫的,其实我们并不需要看几十甚至几百中猫后,才能知道猫就是猫。通常我只要看过一只猫,或者一只猫的图片,我们就能知道什么是猫了。
---- 我们大脑中有什么样的范式,决定了我们能看见什么东西。
---- 人脑里先是有了相应的功能模块,或者范式,然后才能认识物体。
目前,我们知道大脑中有关于,听觉,视觉,感觉,空间,时间,情绪,存在,逻辑推理,语言等模块。
目前图像识别领域,主要还是利用NN在二维上进行图像的识别。 而这些图像中的大多数实物,在真实世界中应该是三维的。 是否可以理解为,大脑中已存在可以识别体的模块。 这样操作起来会容易很多。 像目前的图像识别,是以二维的模式,去识别三维世界物体在二维平面上的投射。同一个三维的体,会有无数多种在二维世界的投射图像。
所以目前做机器学习的时候,需要大量的数据,通过对体的不同的二维世界的投影,来识别体本身。
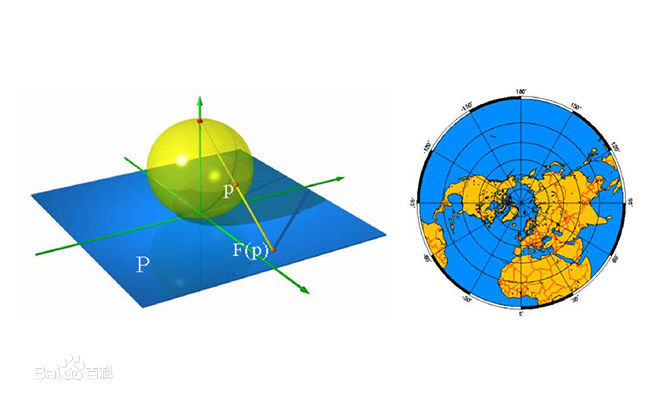
这样看来,还是太麻烦了一些。我们是否有办法,直接设计一个体的识别模块。 如果非要在二维世界中对体进行认识,可否把三维的体,处理成二维的图片,然后进行识别? 注意:不是三维体部分投影的图片,而是如下图这样,把三维的体处理成二维图片。
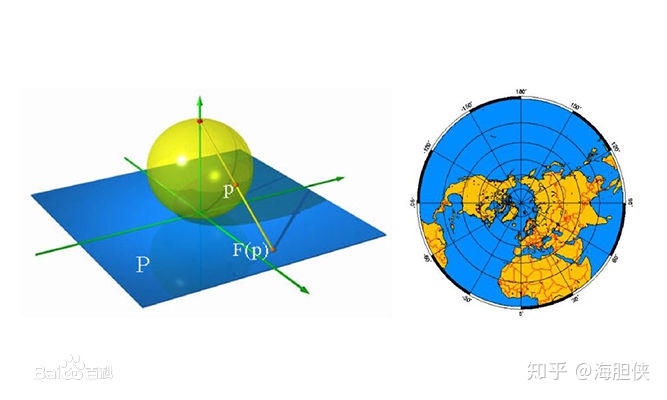
这样,作为球体的地球的全部信息,就展示在右边这张图片上了,就相当于我们已经给机器建立了一个左边地球的完整概念(忽略距离维度)。 在机器有了地球这个概念以后,我们是否就能够摆脱大量的数据训练出来的模型。 而让机器更直观的识别出别的地球的图片??
当然,这里的地球,可以换成其他的三维物体,包括:猫,狗,火车,飞机等。
对此想法感兴趣的人,我们可以聊一下。
有空还需要好好拜读一下康德的《纯粹理性批判》,你大爷终究是你大爷。
————————————————
版权声明:本文为CSDN博主「weixin_43721354」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_43721354/article/details/102495391

