
- 1安装zh_core_web_sm-2.3.0.tar.gz.7z语言离线包_zh-core-web-sm 2.3
- 2yolov5目标检测多线程Qt界面_qt多线程目标检测
- 3 Mac下brew方式安装mysql
- 4Matlab中基于BM3D算法的图像去噪_批量进行bm3d图像去噪
- 5postgresql数据表备份 ansible发送备份文件到远程服务器_postgresql数据备份到其他服务器
- 6MySQL数据查询语法大全(汇总)_mysql查询语法
- 7计算机毕设 基于大数据住房数据分析与可视化 - python_python房屋数据分析可视化预测系统,计算机毕业设计
- 8MySQL数据库source命令导入sql文件_source导入sql文件
- 9Redis 基本命令—— 超详细操作演示!!!_redis 操作
- 10用Navicat管理MySQL数据库_两套数据库在本地,怎么在navicat分开
Java Spark读取Hbase数据,将结果写入HDFS文件_java spark读写hbase
赞
踩
环境:Hadoop2.6,Spark2.1, jdk1.8
注意:hadoop集群启用了kerberos认证,不带认证的需要根据注释简单修改几行代码即可
一、案例Java编程
要求:读取Hbase表zyl_user,按年龄降序将对应的人进行排序输出到HDFS上。
数据表zyl_user如下:
hbase(main):002:0> scan 'zyl_user'
ROW COLUMN+CELL
29008976151_1_2017 column=F1:age, timestamp=1500271723360, value=12
29008976151_1_2017 column=F1:name, timestamp=1500271723360, value=wz
29008976151_1_2017 column=F1:tel, timestamp=1500271723360, value=15167980092
42339809631_1_2017 column=F1:age, timestamp=1500271723360, value=25
42339809631_1_2017 column=F1:name, timestamp=1500271723360, value=zyl
42339809631_1_2017 column=F1:tel, timestamp=1500271723360, value=13690893324
52083010871_1_2017 column=F1:age, timestamp=1500271723367, value=19
52083010871_1_2017 column=F1:name, timestamp=1500271723367, value=gd
52083010871_1_2017 column=F1:tel, timestamp=1500271723367, value=17801038025
76230910931_1_2017 column=F1:age, timestamp=1500271723360, value=31
76230910931_1_2017 column=F1:name, timestamp=1500271723360, value=hxy
76230910931_1_2017 column=F1:tel, timestamp=1500271723360, value=13901903267
9813099-5660_1_2017 column=F1:age, timestamp=1500271723360, value=11
9813099-5660_1_2017 column=F1:name, timestamp=1500271723360, value=gmx
9813099-5660_1_2017 column=F1:tel, timestamp=1500271723360, value=0665-9903189
5 row(s) in 0.3240 seconds
二、java代码:
package com.test.hbase;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableInputFormat;
import org.apache.hadoop.hbase.protobuf.ProtobufUtil;
import org.apache.hadoop.hbase.protobuf.generated.ClientProtos;
import org.apache.hadoop.hbase.util.Base64;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.security.UserGroupInformation;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.PairFunction;
import scala.Tuple2;
public class DataFromHbase {
public static void main(String[] args) {
// 集群启用了kerberos认证
// Configuration configuration = kerberos();//集群启用了kerberos认证,没有认证的话,将这行注释掉即可
Configuration configuration = new Configuration();
String tableName = "zyl_user";
String FAMILY = "F1";
String COLUM_NAME = "name";
String COLUM_AGE = "age";
SparkConf sparkConf = new SparkConf().setAppName("SparkDataFromHbase");//.setMaster("local");
JavaSparkContext sc = new JavaSparkContext(sparkConf);
// Hbase配置
Configuration hconf = HBaseConfiguration.create(configuration);// kerberos认证集群必须传递已经认证过的conf
hconf.set("hbase.zookeeper.quorum", "cdh129130,cdh129136,cdh129144");
hconf.set("hbase.zookeeper.property.clientPort", "2181");
hconf.set(TableInputFormat.INPUT_TABLE, tableName);
Scan scan = new Scan();
scan.addFamily(Bytes.toBytes(FAMILY));
scan.addColumn(Bytes.toBytes(FAMILY), Bytes.toBytes(COLUM_AGE));
scan.addColumn(Bytes.toBytes(FAMILY), Bytes.toBytes(COLUM_NAME));
try {
//添加scan
ClientProtos.Scan proto = ProtobufUtil.toScan(scan);
String ScanToString = Base64.encodeBytes(proto.toByteArray());
hconf.set(TableInputFormat.SCAN, ScanToString);
//读HBase数据转化成RDD
JavaPairRDD<ImmutableBytesWritable, Result> hbaseRDD = sc.newAPIHadoopRDD(hconf,
TableInputFormat.class, ImmutableBytesWritable.class, Result.class);
hbaseRDD.cache();// 对myRDD进行缓存
System.out.println("数据总条数:" + hbaseRDD.count());
//将Hbase数据转换成PairRDD,年龄:姓名
JavaPairRDD<Integer, String> mapToPair = hbaseRDD.mapToPair(new PairFunction<Tuple2<ImmutableBytesWritable,
Result>, Integer, String>() {
private static final long serialVersionUID = -2437063503351644147L;
@Override
public Tuple2<Integer, String> call(
Tuple2<ImmutableBytesWritable, Result> resultTuple2)throws Exception {
byte[] o1 = resultTuple2._2.getValue(Bytes.toBytes(FAMILY), Bytes.toBytes(COLUM_NAME));//取列的值
byte[] o2 = resultTuple2._2.getValue(Bytes.toBytes(FAMILY), Bytes.toBytes(COLUM_AGE));//取列的值
return new Tuple2<Integer, String>(new Integer(new String(o2)), new String(o1));
}
});
//按年龄降序排序
JavaPairRDD<Integer, String> sortByKey = mapToPair.sortByKey(false);
//写入数据到hdfs系统
sortByKey.saveAsTextFile("hdfs://********:8020/tmp/test");
hbaseRDD.unpersist();
} catch (Exception e) {
e.printStackTrace();
} finally {
}
}
/**
* kerberos认证
*/
public static Configuration kerberos() {
String krb5Path = "E:/kerberos/129/krb5.conf";
String principal = "hbase/XXX@MYCDH";
String keytabPath = "E:/kerberos/129/hbase.keytab";
Configuration configuration = new Configuration();
configuration.set("hadoop.security.authentication", "Kerberos");
System.setProperty("java.security.krb5.conf", krb5Path);
configuration.set("hbase.security.authentication", "Kerberos");
configuration.set("hbase.master.kerberos.principal",
"hbase/_HOST@MYCDH");
configuration.set("hbase.regionserver.kerberos.principal",
"hbase/_HOST@MYCDH");
UserGroupInformation.setConfiguration(configuration);
try {
UserGroupInformation.loginUserFromKeytab(principal, keytabPath);
} catch (IOException e) {
e.printStackTrace();
System.exit(1);
}
System.out.println("********** HBase Succeeded in authenticating through Kerberos! **********");
return configuration;
}
}
三、pom.xml文件
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.tydic</groupId>
<artifactId>SparkDemo</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging>
<name>SparkDemo</name>
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>jdk.tools</groupId>
<artifactId>jdk.tools</artifactId>
<version>1.7</version>
<scope>system</scope>
<systemPath>${JAVA_HOME}/lib/tools.jar</systemPath>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.10</artifactId>
<version>1.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase</artifactId>
<version>1.0.0</version>
<type>pom</type>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>1.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-common</artifactId>
<version>1.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>1.0.0</version>
</dependency>
</dependencies>
<build>
<!-- 不打包core.properties -->
<!-- <resources> <resource> <directory>src/main/resources</directory> <excludes>
<exclude>core.properties</exclude> </excludes> </resource> </resources> -->
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<version>2.4</version>
<configuration>
<archive>
<manifest>
<addClasspath>true</addClasspath>
<classpathPrefix>lib/</classpathPrefix>
<mainClass>com.zyl.hbase.DataFromHbase</mainClass>
</manifest>
</archive>
</configuration>
</plugin>
<!-- 将依赖包放到lib文件夹中 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-dependency-plugin</artifactId>
<executions>
<execution>
<id>copy</id>
<phase>package</phase>
<goals>
<goal>copy-dependencies</goal>
</goals>
<configuration>
<outputDirectory> ${project.build.directory}/lib
</outputDirectory>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
四、打包Maven install
SparkDemo-0.0.1-SNAPSHOT.jar
将jar上传到服务器上,jar只是源码,引用的第三方jar包不用打进jar包中。
五、yarn模式提交
yarn-client 提交
spark-submit --keytab /root/XXX.keytab --principal XXX@MYCDH --master yarn-client --jars /tmp/test/lib/hbase-client-1.0.0-cdh5.4.7.jar,/tmp/test/lib/hbase-common-1.0.0-cdh5.4.7.jar,/tmp/test/lib/hbase-server-1.0.0-cdh5.4.7.jar,/tmp/test/lib/hbase-protocol-1.0.0-cdh5.4.7.jar,/tmp/test/lib/htrace-core-3.1.0-incubating.jar --driver-class-path /opt/lib/hbase/lib/*:/etc/hbase/conf --class com.test.hbase.DataFromHbase /tmp/test/SparkDemo-0.0.1-SNAPSHOT.jar
(-keytab /root/XXX.keytab --principal XXX@MYCDH 这两个参数是kerberos认证相关的,集群没有认证可去掉)
六、执行结果
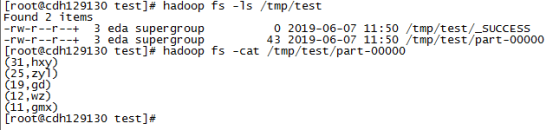
七、问题
1、java.lang.IllegalStateException: unread block data:
19/06/07 10:16:26 INFO scheduler.TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0, cdh129136, NODE_LOCAL, 2214 bytes)
19/06/07 10:16:26 WARN scheduler.TaskSetManager: Lost task 0.0 in stage 0.0 (TID 0, cdh129136): java.lang.IllegalStateException: unread block data
at java.io.ObjectInputStream$BlockDataInputStream.setBlockDataMode(ObjectInputStream.java:2449)
at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1385)
at java.io.ObjectInputStream.defaultReadFields(ObjectInputStream.java:2018)
at java.io.ObjectInputStream.readSerialData(ObjectInputStream.java:1942)
at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:1808)
at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1353)
at java.io.ObjectInputStream.readObject(ObjectInputStream.java:373)
at org.apache.spark.serializer.JavaDeserializationStream.readObject(JavaSerializer.scala:72)
at org.apache.spark.serializer.JavaSerializerInstance.deserialize(JavaSerializer.scala:98)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:194)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
19/06/07 10:16:26 INFO scheduler.TaskSetManager: Starting task 0.1 in stage 0.0 (TID 1, cdh129136, NODE_LOCAL, 2214 bytes)
解决方法:缺少jar包,加上--jar参数,将Hbase-*和其他的几个jar带上即可。

