- 1aws lakeformation跨账号共享数据的两种方式和相关配置
- 2代码随想录算法训练营Day54|LeetCode123买卖股票的最佳时机III、LeetCode188买卖股票的最佳时机IV(补卡)
- 32020B证(安全员)考试及B证(安全员)考试试题_.通过对一些典型事故进行原因分析、事故教训及预防事故发生所回提供施工现场
- 4【哈希冲突解决】线性探测再散列和二次探测再散列_线性探测再散列二次探测再散列
- 5安装nginx
- 630道软件测试基础面试题!(含答案)_软件测试面试常见问题及答案
- 7SparkStreaming 实现黑名单过滤功能_套接字流实现黑名单过滤
- 8Python-VBA函数之旅-property函数_vbaproperty
- 9糖尿病预测 - 基于Pima Indians糖尿病数据集的分析_pimaindiansdiabetes2数据集介绍
- 10Python学习笔记 - 探索字符串格式化
【python】GIL全局锁_python gil
赞
踩
一、原理:
全局解释器锁(Global Interpreter Lock,GIL)规定全局范围内任意时候一个进程里只能同时执行一个线程。每一个线程在执行时,都会锁住GIL,以阻止别的线程执行;执行一段时间后,会释放GIL,以允许别的线程开始利用资源,如果遇到阻塞情况,也会提前释放锁。
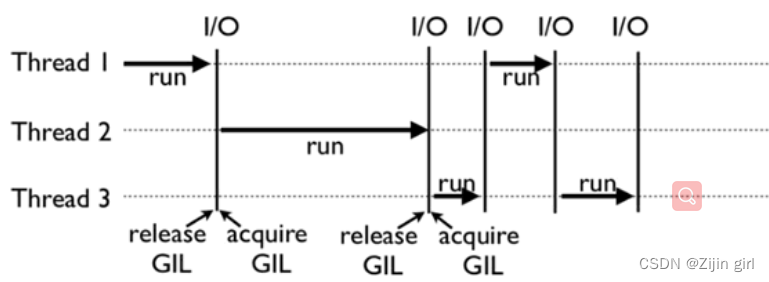
如果你的程序是单线程,该GIL锁并不会对程序造成什么影响。但如果在计算密集型的多线程代码中,GIL就是一个性能瓶颈,使Python多线程成为伪并行多线程。
“全局”的理解:
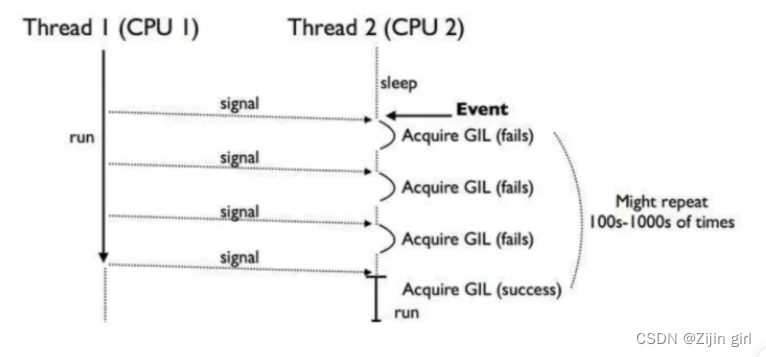
如果你的服务器拥有八核,GIL锁也就是规定8核CPU同时仅能执行一个线程,如果线程1在CPU1中运行着,线程2想在CPU2上运行,只能继续等待线程1结束,获得GIL锁,才可以在CPU2上运行。
在稍微极端一点的情况下,比如线程1使用了while True在CPU 1 上执行,那就真是“一核有难,八核围观”了,如下图所示:
“计算密集型”理解:
在提到开发性能瓶颈的时候,我们经常把对资源的限制分为两类,一类是计算密集型(CPU-bound),一类是 I/O 密集型(I/O-bound)。
计算密集型的程序是指的是把 CPU 资源耗尽的程序,也就是说想要提高性能速度,就需要提供更多更强的 CPU,比如矩阵运算,图片处理这类程序。
I/O 密集型的程序只的是那些花费大量时间在等待 I/O 运行结束的程序,比如从用户指定的文件中读取数据,从数据库或者从网络中读取数据,I/O 密集型的程序对 CPU 的资源需求不是很高。
对于计算密集型应用,由于CPU一直处于被占用状态,GIL锁直到规定时间才会释放,然后才会切换状态,导致多线程处于绝对的劣势,此时可以采用多进程+协程。
对于IO密集型应用,多线程的应用和多进程应用区别不大。即便有GIL存在,由于IO操作会导致GIL释放,其他线程能够获得执行权限。由于多线程的通讯成本低于多进程,因此偏向使用多线程。
何时释放锁?
在python3.2前是通过计数,默认是100,在python3.2时已经不是通过计数来切换,而是时间间隔。
C:\Users\12977>python
Python 3.9.2 (tags/v3.9.2:1a79785, Feb 19 2021, 13:44:55) [MSC v.1928 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> import sys
>>> sys.getswitchinterval()
0.005
>>>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
https://docs.python.org/zh-cn/3.9/whatsnew/3.2.html?highlight=gil
并行运行的Python线程的序列化执行机制(通常称为GIL或全局解释器锁)已被重写。其中的目标是更可预测的切换间隔和减少由于锁争用和后续系统调用数量造成的开销。允许线程切换的“检查间隔”的概念已经被放弃,取而代之的是以秒表示的绝对持续时间。该参数可通过sys.setswitchinterval()调节。它目前默认为5毫秒。
二、GIL存在的意义:
首先了解一下引用计数这个概念。Python 使用引用计数来进行内存管理,即垃圾回收。引用计数就是说 Python 里创建的所有对象,Python 都有一个变量(reference count)记录着当前有多少个引用指向了这个对象,当引用数变成 0 的时候,Python 就会回收这个对象所占用的内存。
Python 的引用计数需要避免资源竞争的问题,我们需要在有两个或多个线程同时增加或减少引用计数的情况下,依然保证引用计数的结果是正确的。
当有多个线程同时改一个对象的引用计数的时候,有可能导致内存泄漏(对象的引用计数永远没有归零的机会),还有可能导致对象提起释放,触发莫名奇妙的 bug,程序崩溃(一个对象存在引用的情况下引用计数变成了 0,导致此对象提前释放)。
通过对不同线程访问、修改引用计数增加锁,我们就可以保证引用计数总是被正确的修改。但是,如果我们对每一个对象或者每一组对象都增加锁,这就意味在在你的 Python 程序中有很多个锁同时存在。多个锁同时存在会有其他的风险–死锁。除此之外,性能下降也是多个锁存在的一大弊端。因为申请锁和释放锁都是一笔不小的开销。
GIL 是一个锁,或者一把锁,这把锁加载了 Python 的解释器上,它要求任何 Python 代码在执行的时候需要先申请这把锁,否则就别想执行。只有一把锁,带来的好处就是 1、不会有死锁,2、对因为引入锁而导致的性能下降影响不大,然而坏处就是 GIL 这把锁让计算密集型的代码也只能使用单线程执行。
三、规避措施:
1.更换解释器:
python解释器有很多个,包括 CPython, Jython, IronPython, PyPy,分别是用 C,Java,C#,Python 实现的。但GIL 锁只存在于 CPython 解释器中。如果你的代码和依赖库不依赖 CPython 的话,那么换其他的解释器也是可行的方案。
通常加锁也有2种不同的粒度的锁:
fine-grained(所谓的细粒度), 那么程序员需要自行地加,解锁来保证线程安全
coarse-grained(所谓的粗粒度), 那么语言层面本身维护着一个全局的锁机制,用来保证线程安全
前一种方式比较典型的是 java, Jython 等, 后一种方式比较典型的是 CPython。
2.将计算型线程改写为进程:(https://docs.python.org/zh-cn/3.9/library/multiprocessing.html)
解决 GIL 锁最通用的方法是使用多进程。因为每个 Python 进程都有自己的 Python 解释器,有自己的内存空间,有自己的 GIL 锁,相互之间没有影响。自然也就没有问题了。
3.多线程调用c动态链接库,来达到多核:
通过编写C语言扩展与Python交互,在C语言层面绕过GIL实现多核利用。使用ctypes模块。
4.协程:
协程又称用户态线程,Python3.4版本后新增了对协程的支持,也是对性能的提升提供了一种选择。
四、疑问:为什么同一个多线程程序在python2中和python3中表象不一致呢?
因为Python3 针对 GIL 做了很多优化。
上面我们说性能瓶颈的时候,谈到了代码有计算密集型和 I/O 密集型,那么如果一个程序既有计算密集型又有 I/O 密集型呢?在这种情况下,Python3.0的 GIL 知道他更应该把 GIL 分给计算密集型的线程,会饿死I/ o绑定的线程。这种机制的实现原理是强制获取到GIL 锁的线程在规定的时间段长之后交出 GIL 锁,如果此时没有其他线程申请锁,那么原来的线程可以继续持有锁,继续运行。
然而这种机制带来新的问题是大部分计算密集型线程都会在其他线程申请 GIL 锁之前再次申请 GIL 锁,这会导致有些线程永远拿不到 GIL 锁(我们虽然希望 CPU 密集型的线程能相比 I/O 密集型的线程能更长时间的获得锁,但是并不希望 CPU 密集型拿着锁永远不释放)。这个问题在 Python3.2 版本中,通过引入线程没有获取到 GIL 锁的请求次数的机制解决,并且在其他线程有机会运行前,不允许当前进程重新获得GIL。
其他:
哪里可以去了解到每个python版本中做了哪些升级?
官方文档:https://docs.python.org/3/