
- 1yolov8/yolov7/yolov5-车辆测距+前车碰撞预警(追尾预警)+车辆检测识别+车辆跟踪测速(原创算法-毕业设计)_yolo测距
- 2C# list 成员对象是int型存在堆区还是栈区
- 3“探秘JS加密算法:MD5、Base64、DES/AES、RSA你都知道吗?”_js md5
- 4win10安装mysql-8.0.12-winx64解压版
- 5python for ArcGIS 绘制苏州市板块地图_苏州市arcgis地图
- 6Pytorch nn.Module_pytorch中nn模块
- 7深度:蚂蚁金融科技全面开放战略背后的技术布局
- 8程序员为什么不习惯关电脑?
- 9最前端|手把手教你打造前端规范工程
- 10RTL Project Directory_rtlproject
Kafka的分区和副本机制_kafka分区和副本
赞
踩
Leader和Follower
在 Kafka 中,每个 topic 都可以配置多个分区以及多个副本。每个分区都有一个 leader 以及 0 个或者多个 follower,在创建 topic 时,Kafka 会将每个分区的 leader 均匀地分配在每个 broker 上。我们正常使用kafka是感觉不到leader、follower的存在的。但其实,所有的读写操作都是由leader处理,而所有的follower都复制leader的日志数据文件,如果leader出现故障时,follower就会被选举为leader。所以,可以这样说:
Kafka中 的 leader 负责处理读写操作,而 follower 只负责副本数据的同步。
如果 leader 出现故障,其他 follower 会被重新选举为leader。
follower 像一个 consumer 一样,拉取 leader 对应分区的数据,并保存到日志数据文件中。
生产者分区写入策略
生产者写入消息到topic,Kafka将依据不同的策略将数据分配到不同的分区中。
- 轮询分区策略
- 随机分区策略
- 按key分区分配策略
- 自定义分区策略
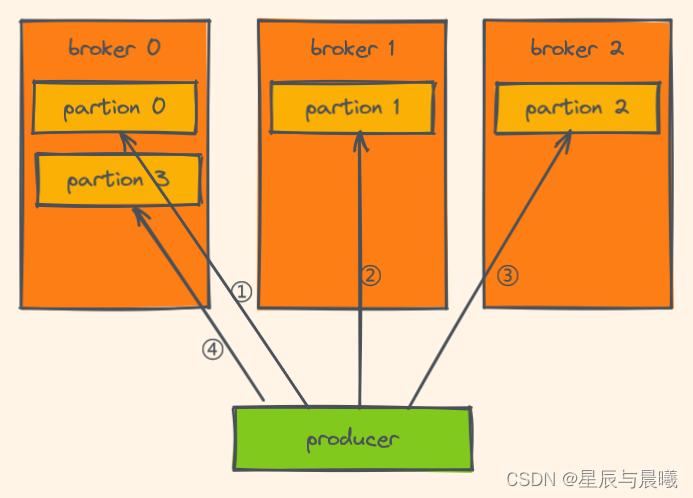
轮询分区策略
- 即就是默认的策略也是使用最多的策略,可以最大限度保证所有消息平均分配到一个分区。
- 如果在生产消息时,key 为 null,则使用轮询算法均衡地分配分区。
轮询就是根据字面意思的循环的意思
随机策略(不用)
随机策略,每次都随机地将消息分配到每个分区。在较早的版本,默认的分区策略就是随机策略,也是为了将消息均衡地写入到每个分区。但后续轮询策略表现更佳,所以基本上很少会使用随机策略。
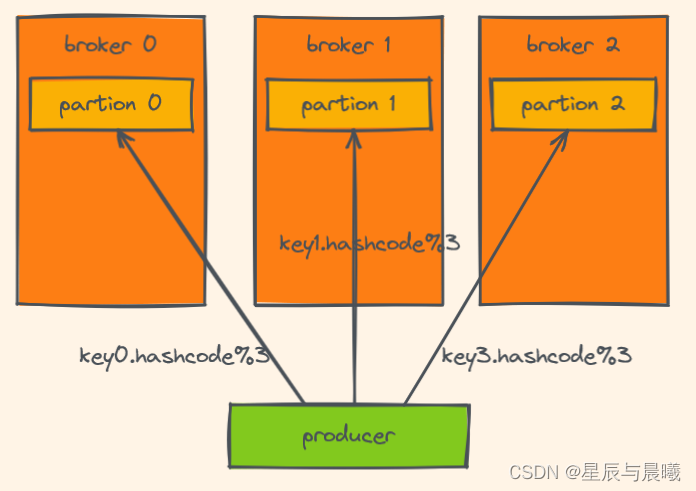
按key分配策略
根据key的hash码求余来计算找到对应的位置
但按key分配策略,有可能会出现数据倾斜,例如:某个key包含了大量的数据,因为key值一样,所有所有的数据将都分配到一个分区中,造成该分区的消息数量远大于其他的分区。
乱序问题
在上面的轮询策略、随机策略都会导致一个问题,生产到 Kafka 中的数据是乱序存储的。而按 key 分区可以一定程度上实现数据有序存储——也就是局部有序,但这又可能会导致数据倾斜,所以在实际生产环境中要结合实际情况来做取舍。
自定义分区策略
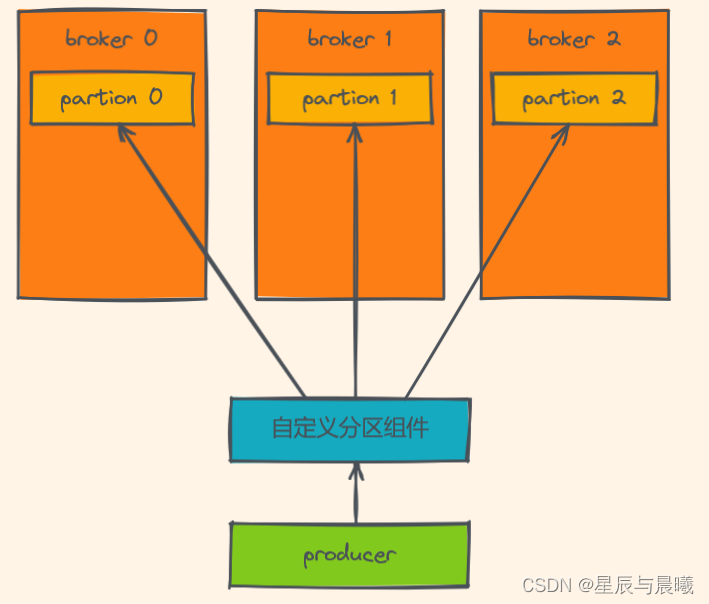
- 创建自定义分区器
public class KeyWithRandomPartitioner implements Partitioner {
- 1
- 2
- 3

