
- 1华为OD机试C、D卷 - 火星文计算2(Java & JS & Python & C & C++)
- 2【数据库】binlog和redo log的区别_redo log和bin log到底有什么区别?
- 3GitHub也会断供:美国制裁地区帐号都受限,毫无预警,个人页面直接404
- 4PHP快速入门05-时间日期与时区,附30个常用案例_php时间和日期函数练习
- 5大数据技术原理与应用 01.大数据概述
- 6神经网络激活函数:Sigmoid、tanh、ReLU、LeakyReLU、pReLU、ELU、maxout_in层和leaky relu
- 7JavaWeb学习建议_对java web课程的建议和想法
- 8Android C/C++ native编程NDK开发中logcat的使用_android ndk c 打印日志
- 9《数据结构》-第六章 图(习题)_图的bfs生成树的树高比dfs生成树的树高()。
- 10rand函数_Excel函数(2)if、rand、round函数
手把手教你用LoRA训练自己的Stable Diffusion模型_lora stable diffusion 工作流
赞
踩
目录
写在前面
Stable Diffusion大家已经很熟悉了,那么如何训练自己的sd模型呢,今天我就介绍一下用LoRA训练sd的方法。
建议先看一下这两篇文章,了解一些前置知识:
手把手教你在linux中部署stable-diffusion-webui
我们以Chilloutmix为例,Chilloutmix可以生成好看的小姐姐。为了实验LoRA的能力,我们用小哥哥的图片对它进行微调,看效果如何。

一、准备数据
从网上找一些小帅的图片,需要脸部清晰的、多角度的、正脸的、侧脸的、最好是背景干净的、各种表情的,这样增加训练集的多样性,提高模型的泛化能力。
素材可以少(一般几十张就不少了,太多了也会过拟合),但是质量一定要高。
背景最好是纯色,想训练什么就突出什么,对于我们的任务,需要选取人脸为重点的图片。
搜集好训练用的图像后,需要进行大小的规范处理,需要是64的倍数。一般都处理为512*512,也可以是768*768,不建议超过1024,尺寸越大则越吃显存。
推荐一个批量处理图像尺寸的网站挺好用的:https://www.birme.net/
处理后的图片长这样:

二、数据打标签
其实我们要训练的是ControlNet,现在图片有了,还差图片的描述或者叫标签。我们不需要自己手动给每张图片打标签,sd-webui有现成的工具(DeepBooru)生成图片的标签。
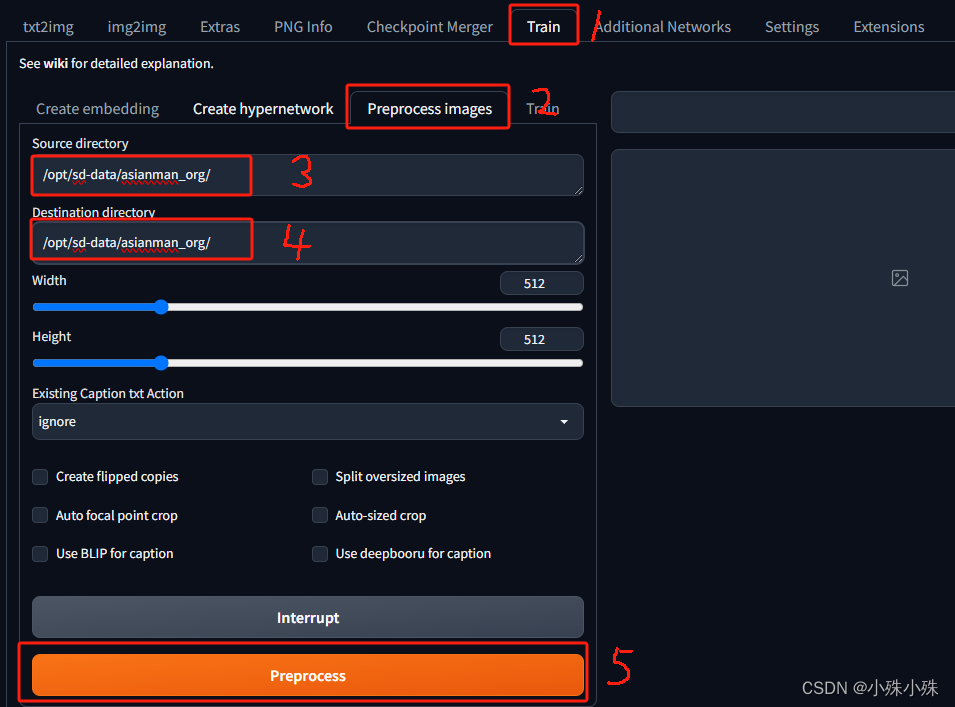
在sd-webui中进行如上操作,在3填写输入图片的目录,4填写输出目录,处理之后原图片和标签文件txt都会放在输出目录
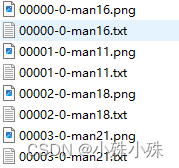
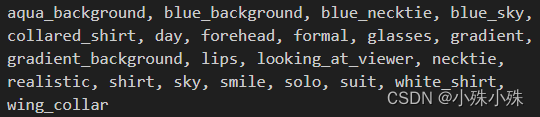
txt中的内容长这样,都是一个一个的标签:
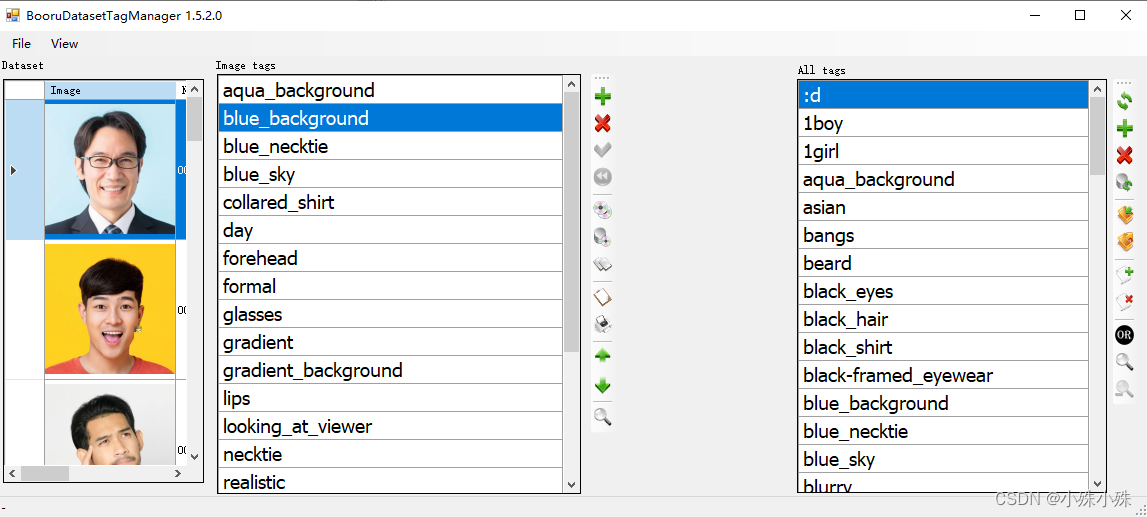
接下来我们要检查每张图片的标签,这里有两个简单的原则:
1.通用的特征标签需要去掉,比如人物的眼睛、眉毛、鼻子、头发长度等代表人物本身的属性。凡是绑定在人物身上的,就要把它们删除。再比如出图只要黑色头发,那训练数据都喂黑色头发,并且删掉类似“black_hair”的标签。
2.留下非通用的标签,比如不是每张训练数据都是微笑的,所以对于微笑的数据应该有“smile”标签;不是所有的数据背景都是白色,就要保留“white backgroud”。
具体保留或者增加什么标签其实没有硬性的规定,还是要根据具体情况反复尝试。
sd-webui是有打标签的插件的,但是我更喜欢一款小工具,方便多人使用,BooruDatasetTagManager,地址:https://pan.baidu.com/s/1Ff7nkwf95AziCcZWTofIzg?pwd=jfoe
数据和标签准备好后放在一个自定义的目录中待用,有一点需要注意,文件名的格式是数字_字母,前面的数字是每次训练过程中网络训练单张图片的次数,比如10_asianman。这个目录命名很重要,一定不要写错!!!
三、执行训练
LoRA训练我们使用kohya,kohya是日本人开发的,所以会经常出现日文,凑活这看吧。
1.下载kohya,别忘了下载sd-scripts目录中的项目:kohya-ss (Kohya S.) · GitHub,下载后执行:
pip install -r requirements.txt2.因为我们是对Chilloutmix进行微调,所以先在这里下载Chilloutmix,并放在model目录下。
3.启动kohya:
python kohya_gui.py --listen 0.0.0.0 --server_port 12348 --inbrowser4.打开地址http://[ip]:12348/ ,并填写配置信息:
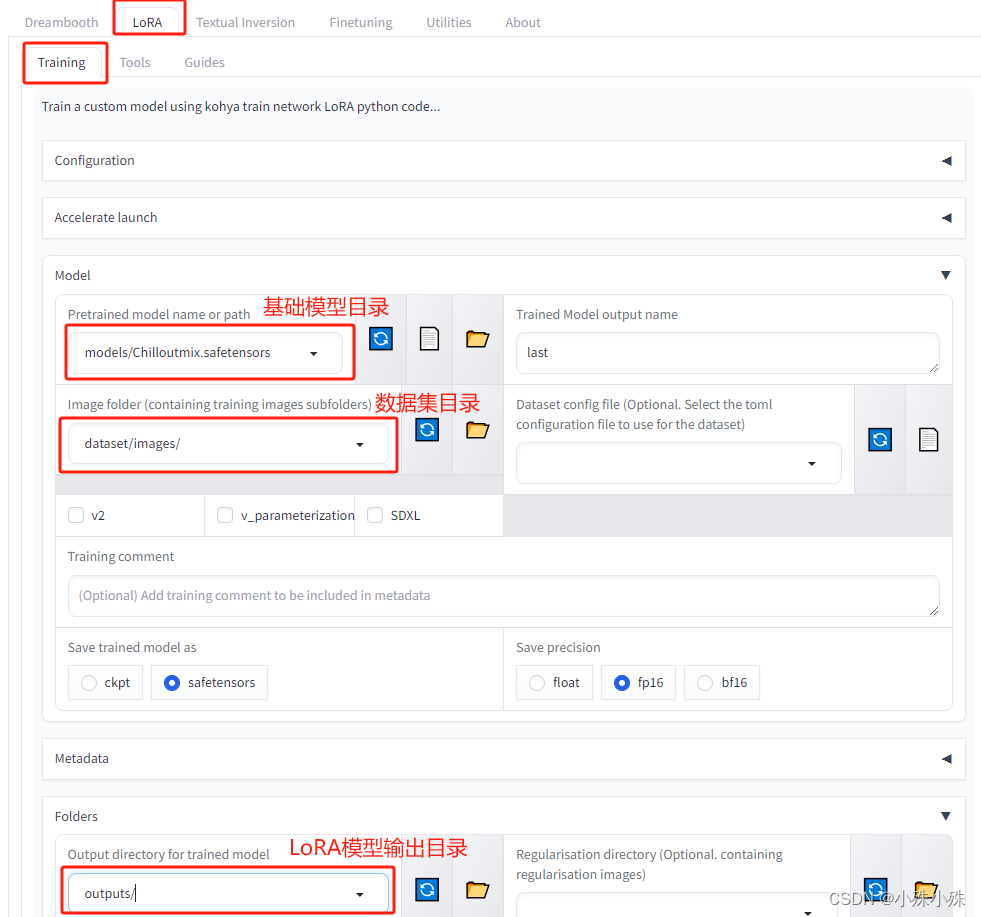
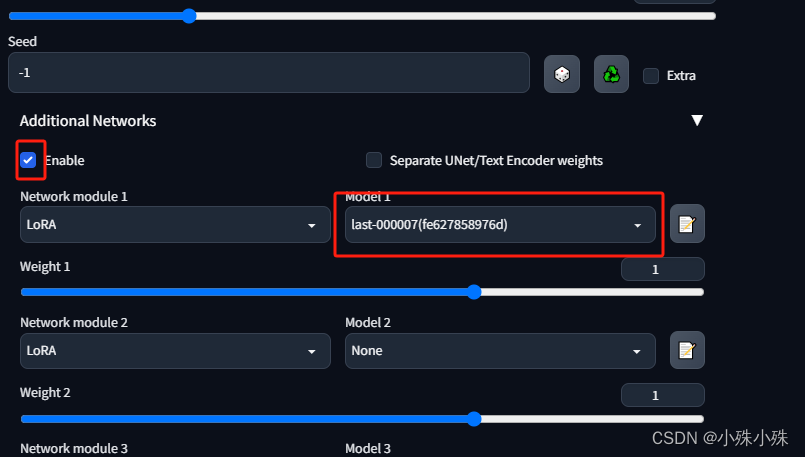
同时Parameters菜单中还有一些高级设置,比如batch size、train steps、LoRA的秩、Alpha等:


一些注意:
1.训练时的总epoch数是算出来的,上面的Epoch好像没有用,计算公式是:
Max train steps * Train batch size / (数据总数 * 训练单张图片的次数),这算法很奇怪,他把Train batch size当做了batch size per device
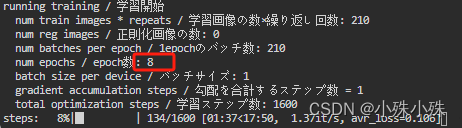
2.LoRA的秩用8就可以了,Alpha训练人物一般都设32,64都可以;训练风格可以用到128。
3. 我看到有的文章说不能直接用safetensors文件直接训练,必须还要有config.json,但是我没有遇到这种情况。如果遇到了可以下载这个,放在项目根目录的openai/clip-vit-large-patch14 和 laion/CLIP-ViT-bigG-14-laion2B-39B-b160k
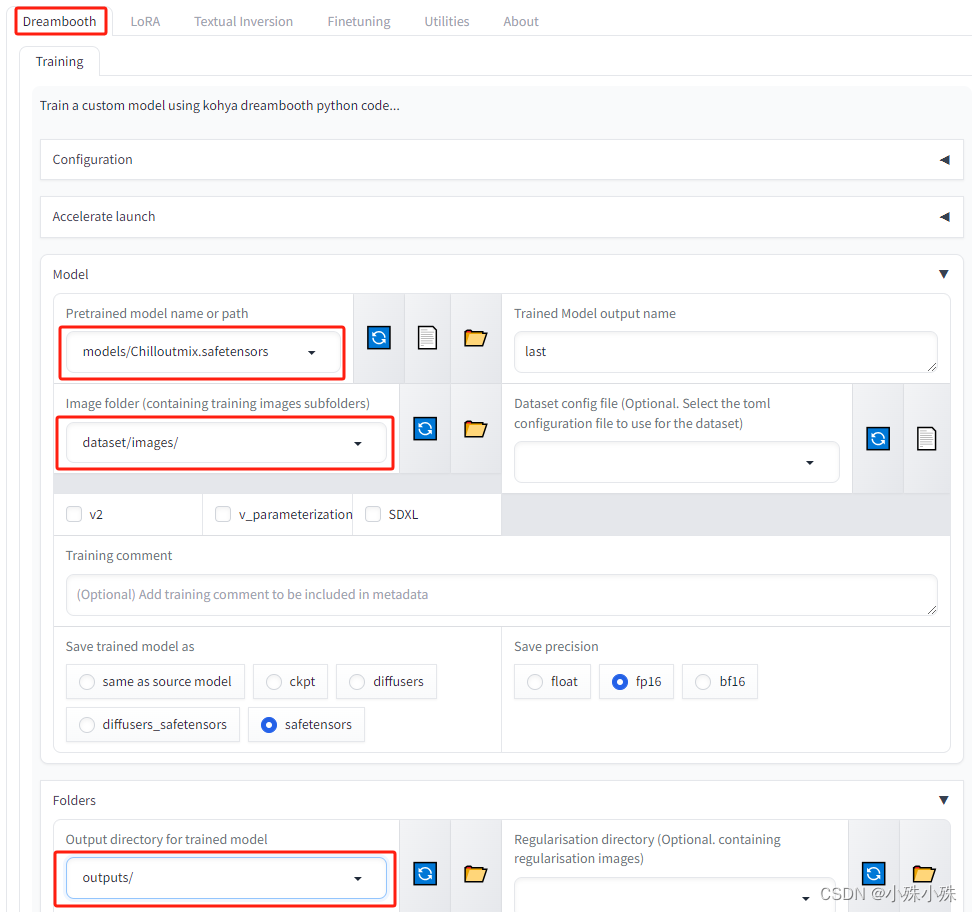
4.如果要全参数训练只需选择Dreambooth菜单,其它使用方式和LoRA基本相同:
5.如果报这个错的话:'FieldInfo' object has no attribute 'required'. Did you mean: 'is_required'?,是一些库的版本冲突了,可以试试如下命令:
- pip install gradio==3.48.0
- pip install pydantic==1.10.13 pydantic_core==2.14.6
- pip install transformers==4.38.0
- pip install accelerate==0.25.0
- pip install torch==2.1.1
- pip install xformers==0.0.23
四、执行推理
训练成功后模型会存在输出目录,比如叫做models/last-000007.safetensors。
1.LoRA推理
(1)安装additional-networks
如果sd-weiui的“text2img”和“img2text”中已经有Additional Networks菜单,则之间跳过该步骤。
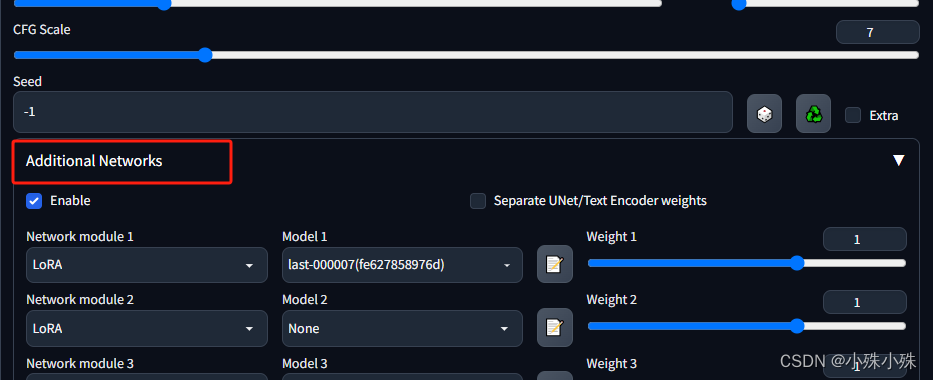
安装additional-networks插件,有两种方式:
a.在“Extensions-URL for extension's git repository”输入https://github.com/kohya-ss/sd-webui-additional-networks就可以安装了。
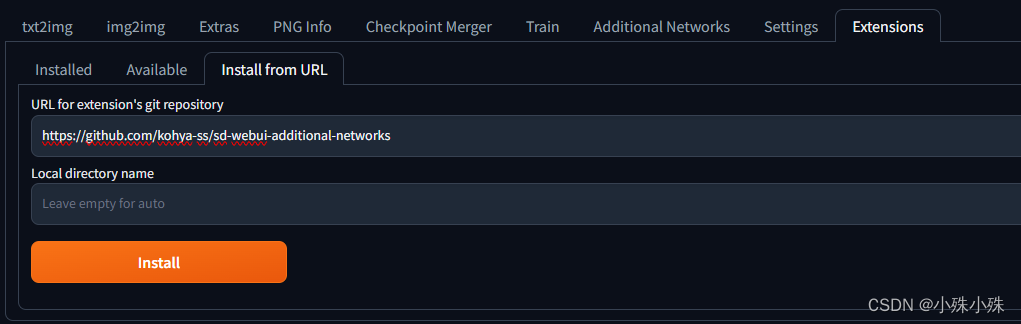
b.如果网络不允许的话,就自行下载压缩包解压放到SD的extensions目录下。
安装完之后一定要重启sd进程!之后我们可以看到选项卡上多了一个Additional Network选项。
(2)将Chilloutmix基础模型放在models/Stable-diffusion目录
(3)将训练完的LoRA模型放在sd-webui的extensions/sd-webui-additional-networks/models/lora目录
(4)使用基础模型重绘一张图片看看,都是小姐姐: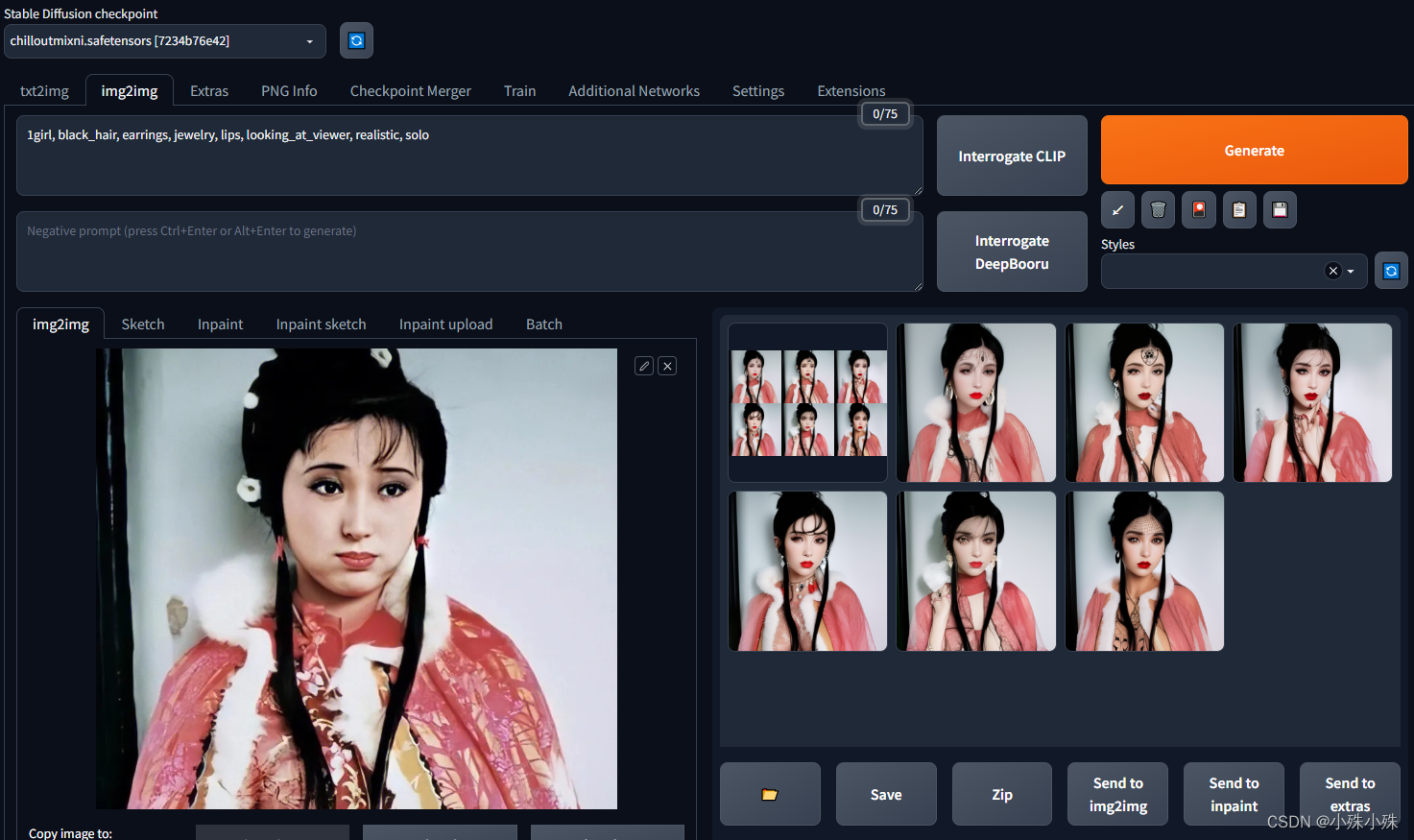
(5)使用LORA,再生成看看:
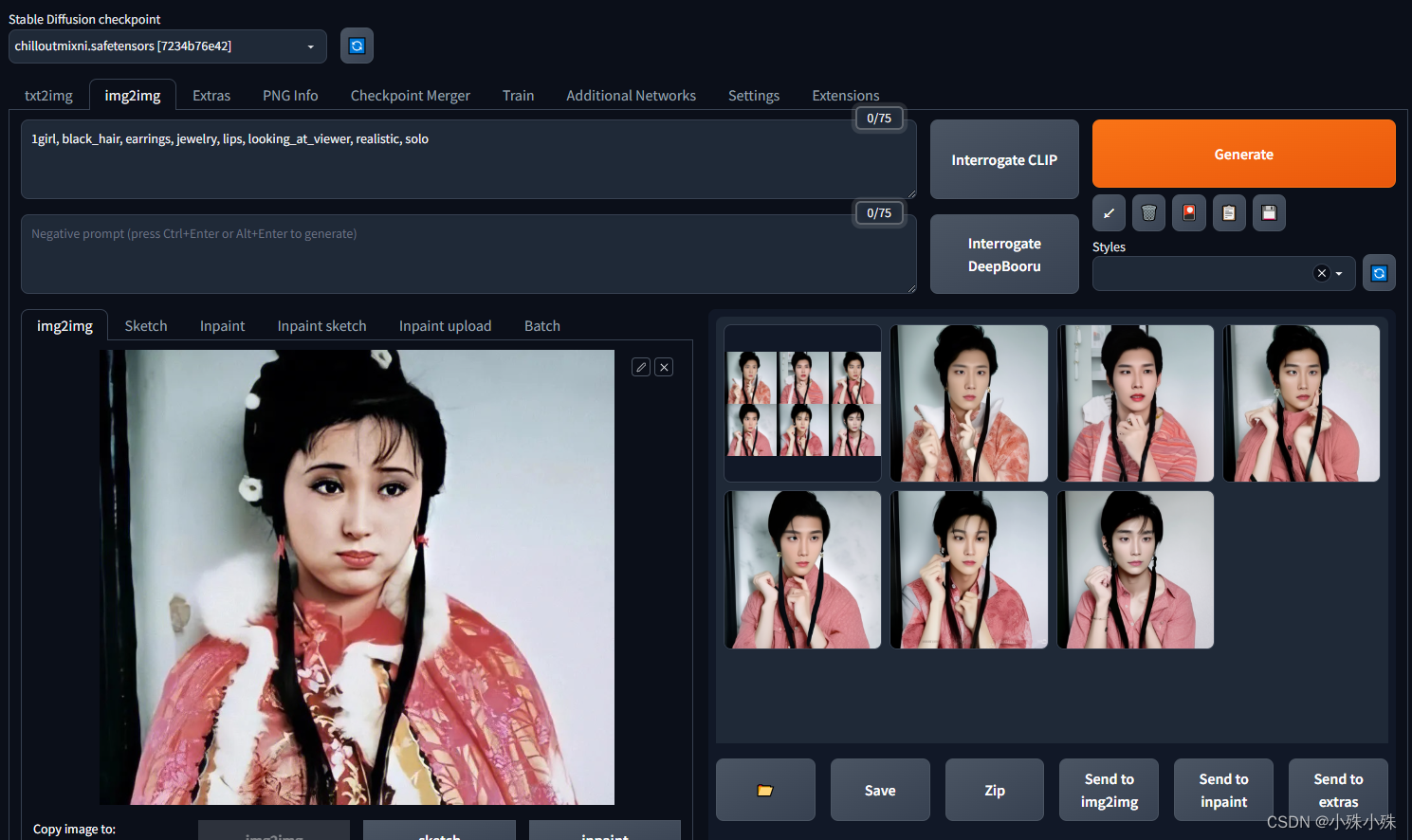
emmm,已经有很强的男性特征,证明LoRA生效了。
2.全参数推理
如果使用全参数训练的模型,模型结果比较大,有几个g。使用更简单了,放在models/Stable-diffusion中,直接选择这个模型就可以了。
用LoRA训练自己的SD模型就介绍到这里,关注不迷路(#^.^#)
关注订阅号了解更多精品文章

交流探讨、商务合作请加微信


