
- 1黑盒测试案例设计技术_网上银行支付交易系统的基本流和备选流的描述
- 2技术分享 某下一代防火墙远程命令执行漏洞分析及防护绕过_深信服下一代防火墙ngaf login远程命令执行漏洞_博达下一代防火墙 存在远程代码执行
- 3pl/sql developer 编码格式设置_plsql developer 配置编码格式utf-8
- 4版本控制工具--git_git版本控制工具的优缺点
- 5VMware虚拟机屏幕大小(屏幕分辨率)调整_vmix调整输出分辨率
- 6微信小程序自定义tabbar_微信小程序 自定义 tabbar
- 7邓俊辉数据结构学习笔记3-二叉树_b-ary tree
- 8《统计学简易速速上手小册》第5章:回归分析(2024 最新版)
- 9AI绘画专栏之Stablediffusion webui Controlnet SDXL 插件之segment-anything(40)
- 10DeepSpeed使用体会_deepspeed评测
ActiveMQ、RabbitMQ、RocketMQ、Kafka区别
赞
踩
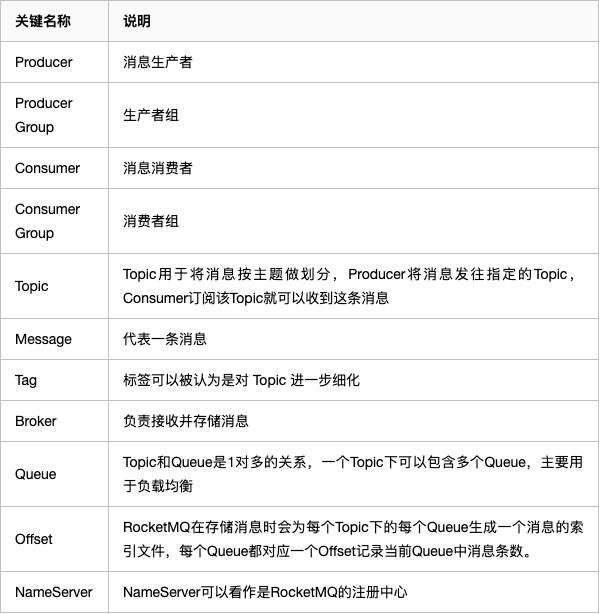
1、4种消息中间件比较
| 特性 | ActiveMQ | RabbitMQ | RocketMQ | Kafka |
| 开发语⾔ | java | erlang | java | scala |
| 单机吞吐量 | 万级 | 万级 | 10万级 | 10万级 |
| 时效性 | ms级 | us级 | ms级 | ms级以内 |
| 可⽤性 | ⾼(主从架构) | ⾼(主从架构) | ⾮常⾼(分布式架构) | ⾮常⾼(分布式架构) |
| 功能特性 | 成熟的产品, 在很多公司得到应⽤; 有较多的⽂档; 各种协议⽀持较好 | 基于erlang开发, 所以并发能⼒很强, 性能极其好, 延时很低; 管理界⾯较丰富 | MQ功能⽐较完备, 扩展性佳 | 只⽀持主要的MQ功能, 像⼀些消息查询,消息回 溯等功能没有提供,毕竟 是为⼤数据准备的,在⼤ 数据领域应⽤⼴。 |
1.1、消息中间件的使用场景
解耦、异步、削峰
如果我方系统A要与三方B系统进行数据对接,推送系统人员信息,通常我们会使用接口开发来进行。但是如果运维期间B系统进行了调整,或者推送过程中B系统网络进行了调整,又或者后续过程中我们需要推送信息到三方C系统中,这样的话就需要我们进行频繁的接口开发调整,还需要考虑接口推送消息失败的场景。如果我们使用消息中间件进行消息推送,我们只需要按照一种约定的数据结构进行数据推送,其他三方系统从消息中间件取值消费就可以,即便是三方系统出现宕机或者其他调整,我们都可以正常进行数据推送。
如果我们现在需要同时推送消息到BCD三个系统中,而BCD系统接收到消息后需要进行复杂的逻辑处理,以及读库写库处理。如果一个三方系统进行消息处理需要1s,那我们遍历推送完一次消息,就需要三秒。而如果我们使用消息中间件,我们只需要推送到消息中间件,然后进行接口返回,可能只需要20ms,大大提升了用户体验。消息推送后BCD系统各自进行消息消费即可,不需要我们等待。
如果某一时间段内,每秒都有一条消息推送,如果我们使用接口进行推送,BCD三个系统处理完就需要三秒。这样会导致用户前端体验较差,而且系统后台一直处于阻塞状态,后续的消息推送接口一直在等待。如果我们使用消息中间件,我们只需要将消息推送至消息中间件中,BCD系统对积压的消息进行相应的处理。
1.2、消息中间件的缺点
系统关联的中间件越多,越容易引发宕机问题。原本进行消息推送我们只需要开发接口进行推送即可,引入消息中间件后就需要考虑消息中间件的高可用问题,如果消息中间件出现宕机问题,我们所有的消息推送都会失败。
如果我们使用接口进行消息推送,我们只需要考虑接口超时以及接口推送消息失败的问题。但我们引入消息中间件后,就需要考虑消息中间件的维护,以及消息重复消费,消息丢失的问题。
如果我们使用接口进行消息推送,推送消息我们可以放在事务中处理,如果推送过程中出现异常,我们可以进行数据回滚,但我们引入消息中间件后,就需要考虑消息推送后,消费失败的问题,以及如果我们同时推送消息到BCD系统中,如何保证他们的事务一致性。
2、ActiveMQ
2.1、Activemq 是什么
Activemq 是一种开源的,实现了JMS1.1规范的,面向消息(MOM)的中间件,为应用程序提供高效的、可扩展的、稳定的和安全的企业级消息通信。
2.2、Activemq 的作用及原理
Activemq 的作用就是系统之间进行通信,原理就是生产者生产消息, 把消息发送给activemq, Activemq 接收到消息, 然后查看有多少个消费者,然后把消息转发给消费者, 此过程中生产者无需参与。 消费者接收到消息后做相应的处理和生产者没有任何关系。
2.3、Activemq 的通信方式
发布/订阅方式用于多接收客户端的方式,作为发布订阅的方式,可能存在多个接收客户端,并且接收端客户端与发送客户端存在时间上的依赖。一个接收端只能接收他创建以后发送客户端发送的信息。
2p的过程则理解起来比较简单。它好比是两个人打电话,这两个人是独享这一条通信链路的。一方发送消息,另外一方接收,就这么简单。在实际应用中因为有多个用户对使用p2p的链路,相互通信的双方是通过一个类似于队列的方式来进行交流。和前面pub-sub的区别在于一个topic有一个发送者和多个接收者,而在p2p里一个queue只有一个发送者和一个接收者。
2.4、Activemq 的消息持久化机制
JDBC: 持久化到数据库
AMQ :日志文件(已基本不用)
KahaDB : AMQ基础上改进,默认选择
LevelDB :谷歌K/V数据库
在activemq.xml中查看默认的broker持久化机制。
2.5、Activemq 的消息确认机制
- AUTO_ACKNOWLEDGE = 1 自动确认
- CLIENT_ACKNOWLEDGE = 2 客户端手动确认
- DUPS_OK_ACKNOWLEDGE = 3 自动批量确认
- SESSION_TRANSACTED = 0 事务提交并确认
- INDIVIDUAL_ACKNOWLEDGE = 4 单条消息确认
3、RabbitMQ
3.1、RabbitMQ是什么
RabbitMQ是一个由erlang语言编写的、开源的、在AMQP基础上完整的、可复用的企业消息系统。
3.2、RabbitMQ的作用及原理


3.3、RabbitMQ的通信方式
最简单的工作队列,其中一个消息生产者,一个消息消费者,一个队列。也称为点对点模式
一个消息生产者,一个交换器,一个消息队列,多个消费者。同样也称为点对点模式
Pulish/Subscribe,无选择接收消息,一个消息生产者,一个交换机(交换机类型为fanout),多个消息队列,多个消费者,生产者只需把消息发送到交换机,绑定这个交换机的队列都会获得一份一样的数据。
在发布/订阅模式的基础上,有选择的接收消息,也就是通过 routing 路由进行匹配条件是否满足接收消息。
topics(主题)模式跟routing路由模式类似,只不过路由模式是指定固定的路由键 routingKey,而主题模式是可以模糊匹配路由键 routingKey,类似于SQL中 = 和 like 的关系。
RPC是指远程过程调用,也就是说两台服务器A,B,一个应用部署在A服务器上,想要调用B服务器上应用提供的处理业务,处理完后然后在A服务器继续执行下去,把异步的消息以同步的方式执行。
3.4、RabbitMQ的消息持久化机制
- Queue(消息队列)的持久化是通过durable=true来实现的。
- Message(消息)的持久化 ,通过设置消息是持久化的标识。
- Exchange(交换机)的持久化 。
3.5、RabbitMQ的消息确认机制
- confirm机制:确认消息是否成功发送到Exchange
- ack机制:确认消息是否被消费者成功消费
- AcknowledgeMode.NONE:自动确认
- AcknowledgeMode.AUTO:根据情况确认
- AcknowledgeMode.MANUAL:手动确认
4、RocketMQ
4.1、RocketMQ是什么
RocketMQ是阿里开发的一款纯java、分布式、队列模型的开源消息中间件,支持事务消息、顺序消息、批量消息、定时消息、消息回溯等。
4.2、RocketMQ的作用及原理
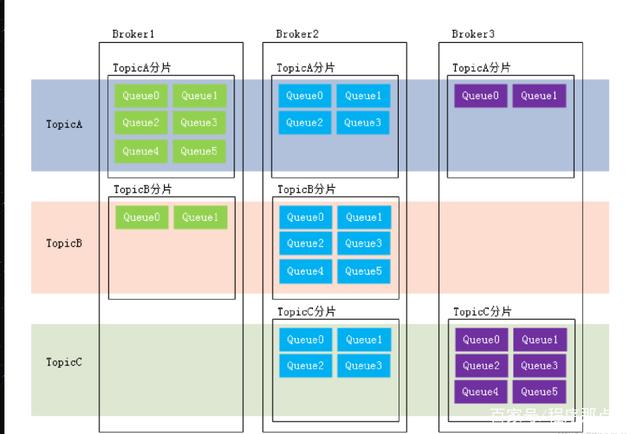
4.3、RocketMQ的通信方式
RocketMQ消息订阅有两种模式
一种是Push模式(MQPushConsumer),即MQServer主动向消费端推送
另外一种是Pull模式(MQPullConsumer),即消费端在需要时,主动到MQ Server拉取
但在具体实现时,Push和Pull模式本质都是采用消费端主动拉取的方式,即consumer轮询从broker拉取消息
集群模式和广播模式
集群模式:默认情况下我们都是使用的集群模式,也就是说消费者组收到消息后,只有其中的一台机器会接收到消息。
广播模式:消费者组内的每台机器都会收到这条消息。
4.4、RocketMQ的消息持久化机制
exchange持久化、queue持久化、message持久化
CommitLog:日志数据文件,存储消息内容,所有 queue 共享,不区分 topic ,顺序读写 ,1G 一个文件
ConsumeQueue:逻辑 Queue,基于 topic 的 CommitLog 的索引文件,消息先到达 commitLog,然后异步转发到 consumeQueue,包含 queue 在 commitLog 中的物理偏移量 offset,消息实体内容大小和 Message Tag 的 hash 值,大于 600W 个字节,写满之后重新生成,顺序写
IndexFile:基于 Key 或 时间区间的 CommitLog 的索引文件,文件名以创建的时间戳命名,固定的单个 indexFile 大小为 400M,可以保存 2000W 个索引
4.5、RocketMQ的消息确认机制
- confirm机制:确认消息是否成功发送到Exchange
- ack机制:确认消息是否被消费者成功消费
5、Kafka
5.1、Kafka是什么
Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。Kafka是一个分布式、分区的、多副本的、多订阅者,基于zookeeper协调的分布式日志系统,可作为消息中间件
5.2、Kafka的作用及原理


5.3、Kafka的通信方式
- 生产者发送模式
- 发后即忘(fire-and-forget):只管往Kafka中发送消息而并不关心消息是否正确到达
- 同步(sync):一般是在send()方法里指定一个Callback的回调函数,Kafka在返回响应时调用该函数来实现异步的发送确认。
- 异步(async):send()方法会返回Futrue对象,通过调用Futrue对象的get()方法,等待直到结果返回
- 消费者消费模式
- At-most-once(最多一次):在每一条消息commit成功之后,再进行消费处理;设置自动提交为false,接收到消息之后,首先commit,然后再进行消费。
- At-least-once(最少一次):在每一条消息处理成功之后,再进行commit;设置自动提交为false;消息处理成功之后,手动进行commit。
- Exactly-once(正好一次):将offset作为唯一id与消息同时处理,并且保证处理的原子性;设置自动提交为false;消息处理成功之后再提交。
5.4、Kafka的消息持久化机制
Kafka直接将数据写入到日志文件中,以追加的形式写入
5.5、Kafka的消息确认机制
- confirm机制:确认消息是否成功发送
- ack机制:确认消息是否被消费者成功消费
6、消息重复消费问题
为什么要考虑重复消费的问题?
比如我们消费后通过消费中间件来调用,扣费10元,但是消费者消费消息后还没来得及进行确认,消息中间件进行了重启,那么消息者就会进行再次扣费处理,这样就会出问题!
kafka重复消费例子:
Kafka 实际上有个 offset 的概念,就是每个消息写进去,都有一个 offset,代表消息的序号,然后 consumer 消费了数据之后,每隔一段时间(定时定期),会把自己消费过的消息的 offset 提交一下,表示我已经消费过了,下次我要是重启啥的,你就让我继续从上次消费到的 offset 来继续消费吧。但是,如果在这期间重启系统或者直接 kill 进程了,再重启。这会导致 consumer 有些消息处理了,但是没来得及提交 offset。重启之后,少数消息会再次消费一次。如果消费者干的事儿是拿一条数据就往数据库里写一条,会导致说,你可能就把数据在数据库里插入了 2 次,那么数据就错啦。
重复消费问题引发后,我们就需要考虑怎么保证幂等性
如果是数据插入操作,没有数据新增,已有数据那我们只进行更新就行。
如果是基于数据库的唯一键来保证重复数据不会重复插入多条。因为有唯一键约束了,重复数据插入只会报错,不会导致数据库中出现脏数据。
insert into(a,b) values('1','2') on duplicate key update a='3'- merge into student a
- using (select id from dual) s
- on (a.id = s.id)
- when matched then
- update set a.student_name = '沈畅'
- when not matched then
- insert (id, student_name, fk_class) values ('1', '小沈', '3')
7、消息丢失问题
7.1、ActiveMQ
生产者丢失消息的问题可以通过消息重投、重试机制来解决
ActiveMQ丢失消息的问题需要通过ActiveMQ消息持久化机制+高可用(见ActiveMQ章节)来解决,ActiveMQ的消息持久化机制有以下几种
- JDBC: 持久化到数据库
- AMQ :日志文件(已基本不用)
- KahaDB : AMQ基础上改进,默认选择
- LevelDB :谷歌K/V数据库
- 在activemq.xml中查看默认的broker持久化机制。
消费者丢失消息通过ack机制来解决,消息者进行业务处理后,再进行ack确认,避免消息丢失。
7.2、RabbitMQ
生产者消息丢失,通过confirm机制来确认消息发送,然后进行相应的消息重投、重试机制
- RabbitMQ丢失消息的问题需要通过RabbitMQ消息持久化机制+高可用(见RabbitMQ章节)来解决,
- RabbitMQ持久化包含:
- Queue(消息队列)的持久化是通过durable=true来实现的。
- Message(消息)的持久化 ,通过设置消息是持久化的标识。
- Exchange(交换机)的持久化 。
消费者丢失消息通过ack机制来解决,消息者进行业务处理后,再进行ack确认,避免消息丢失。
7.3、RocketMQ
生产者消息丢失,通过confirm机制来确认消息发送,然后进行相应的消息重投、重试机制
RocketMQ丢失消息的问题需要通过RocketMQ消息持久化机制+高可用(见RocketMQ章节)来解决
RocketMQ持久化包含:exchange持久化、queue持久化、message持久化
消费者丢失消息通过ack机制来解决,消息者进行业务处理后,再进行ack确认,避免消息丢失。
7.4、Kafka
生产者消息丢失,通过confirm机制来确认消息发送,然后进行相应的消息重投、重试机制
Kafka直接将数据写入到日志文件中,以追加的形式写入
消费者丢失消息通过ack机制来解决,消息者进行业务处理后,再进行ack确认,避免消息丢失。
8、消息积压问题
如何解决消息队列的延时以及过期失效问题?消息队列满了以后该怎么处理?有几百万消息持续积压几小时,怎么处理?
其实消息积压的问题,一般都是由消费端出了问题导致的,在实际业务场景中一般不会出现,但是出现问题一般都是大问题。
- 模拟场景
一个消费者一秒是 1000 条,一秒 3 个消费者是 3000 条,一分钟就是 18 万条。由于消费者宕机导致现在MQ中积压几百万数据
- 解决思路
- 先修复 consumer 的问题,确保其恢复消费速度,然后将现有 consumer 都停掉(避免重复消费)。
- 新建一个 topic,partition 是原来的 10 倍,临时建立好原先 10 倍的 queue 数量。
- 然后写一个临时的分发数据的 consumer 程序,这个程序部署上去消费积压的数据,消费之后不做耗时的处理,直接均匀轮询写入临时建立好的 10 倍数量的 queue。
- 接着临时征用 10 倍的机器来部署 consumer,每一批 consumer 消费一个临时 queue 的数据。这种做法相当于是临时将 queue 资源和 consumer 资源扩大 10 倍,以正常的 10 倍速度来消费数据。
- 等快速消费完积压数据之后,得恢复原先部署的架构,重新用原先的 consumer 机器来消费消息。

