
- 1服务器部署redis和springboot整合redis详细步骤_redis怎么集成到服务器伤
- 2鱼哥好书分享活动第23期:《深入浅出存储引擎》不同数据库背后的数据存储方案_深入浅出存储引擎 pdf 下载
- 3微信小程序简介、发展史、小程序的优点、申请账号、开发工具、初识wxml文件和wxss文件_pc上 微信 小程序 dark mode
- 4【Mysql】utf8与utf8mb4区别,utf8mb4_bin、utf8mb4_general_ci、utf8mb4_unicode_ci区别
- 5PLSQL中文显示乱码问题及解决方法_plsql中文乱码显示?????
- 6茴字有四种写法,HTAP呢?_hstap
- 7JimuReport 积木报表 v1.7.6 版本发布,免费的低代码报表_jimureport的pg初始化脚本
- 8轻松通关Flink第06讲:Flink 集群安装部署和 HA 配置_flink ha
- 9聚类方法:K-means、K-modes和K-prototypes_kmodes聚类算法与kmeans
- 10Java连接linux虚拟机的redis报错问题解决办法_java 项目 链接虚拟机redis
Hive架构、组件_hive架构的运行原理
赞
踩
Hive
Hive 的架构是设计用于在大数据环境下进行数据仓库操作和分析的系统。它建立在 Hadoop 生态系统之上,利用 Hadoop 的存储(HDFS)和计算(MapReduce、Tez、Spark 等)能力。

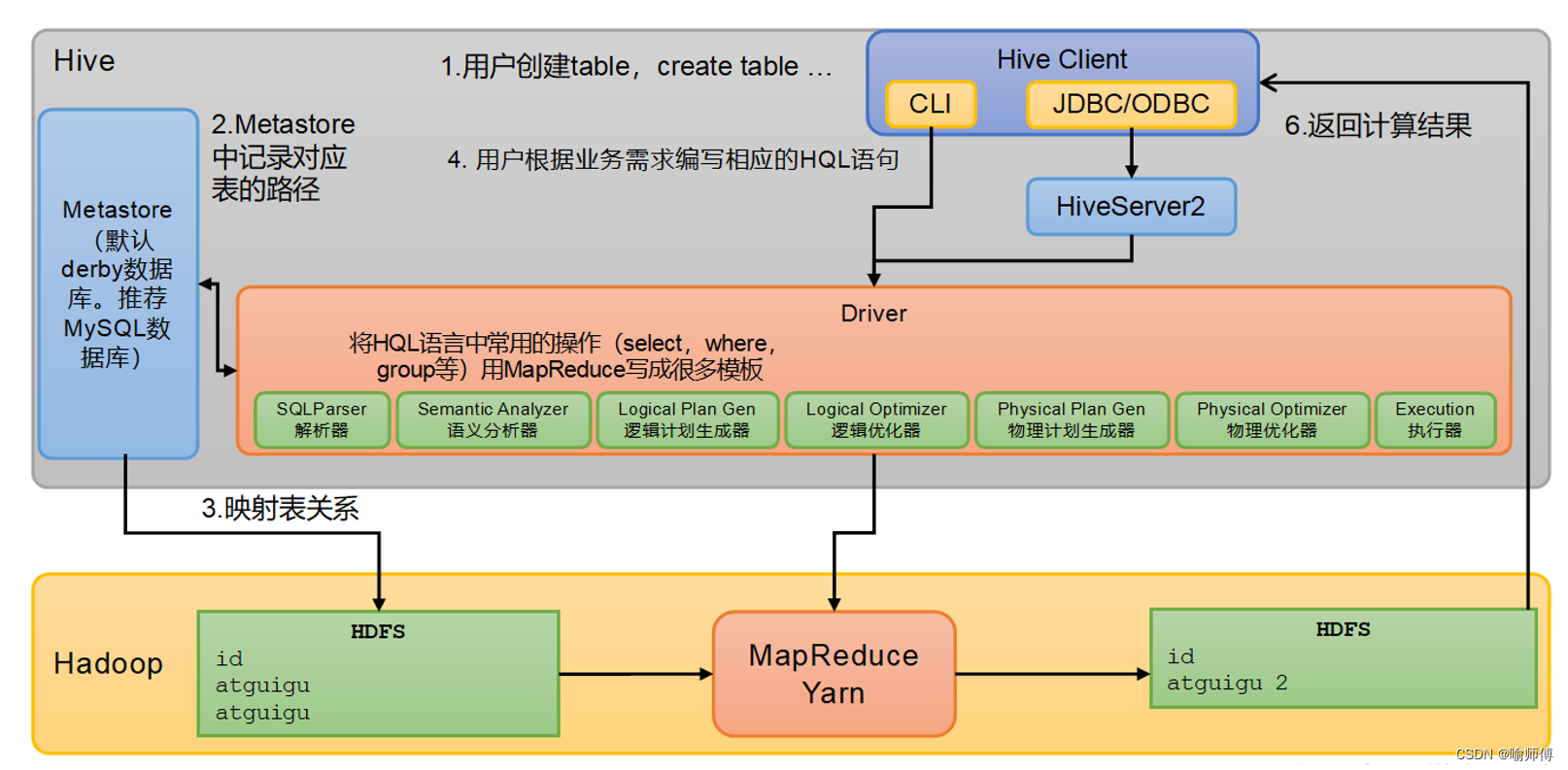
1. 元数据存储(Metastore):



- Metastore 是 Hive 的元数据管理组件,负责存储表的结构信息、分区信息、表的存储位置等。
- 这些元数据通常存储在关系型数据库中,如 MySQL、Derby 等。
- Metastore 提供了对元数据的增删改查接口,使用户可以方便地管理表的元数据信息。

2. 查询解析和优化:
-
当用户提交一个 HiveQL 查询时,Hive 的 Driver 模块负责接收并解析该查询,构建查询执行计划。

-
在构建执行计划的过程中,Hive 会进行优化,包括逻辑优化、物理优化和执行计划生成。这些优化可以提高查询的执行效率,并减少资源消耗。
3. 查询执行引擎(Execution Engine):
-
执行引擎负责实际执行查询任务,它根据查询执行计划将任务分发到集群中的多个节点上执行。

-
Hive 支持多种执行引擎,包括传统的 MapReduce、更高效的 Tez、内存计算框架 Spark 等。用户可以根据需求选择合适的执行引擎。
4. 数据存储:
- Hive 将数据存储在 Hadoop 分布式文件系统(
HDFS)中,通常以文件的形式存储。 - 对于内部表(
Managed Table),Hive 负责管理数据的存储路径和格式。 - 而对于外部表(
External Table),用户可以自行管理数据的存储位置和格式。
5. 任务调度和资源管理:

- 在执行查询任务时,Hive 需要有效地管理集群资源并调度任务。
- 通常情况下,Hive 使用
YARN(Yet Another Resource Negotiator)作为资源管理器,负责为查询任务分配适当的资源,并监控任务的执行状态。
6. 用户界面和客户端接口:
-
Hive 提供了多种用户界面和客户端接口,使用户可以方便地与系统交互。其中包括命令行界面(CLI)、Web UI、Hue 插件等。

-
此外,Hive 还提供了 JDBC 和 ODBC 接口,使得用户可以通过标准的数据库连接方式与 Hive 进行交互。
7. 扩展性和灵活性:
- Hive 的架构设计具有良好的扩展性和灵活性,它可以与 Hadoop 生态系统中的其他组件(如 HBase、Kafka、Presto 等)紧密集成,以满足不同的数据处理和分析需求。
- 同时,Hive 还支持用户自定义函数(UDFs)、用户定义的聚合函数(UDAFs)和用户定义的表生成器(UDTFs),使得用户可以根据自身需求扩展 Hive 的功能。
8.Tips:
1.用户接口:Client
CLI(command-line interface)、JDBC/ODBC。
JDBC和ODBC的区别:
- (1)JDBC的移植性比ODBC好(通常情况下,安装完ODBC驱动程序之后,还需要经过确定的配置才能够应用。而不相同的配置在不相同数据库服务器之间不能够通用。所以,安装一次就需要再配置一次。JDBC只需要选取适当的JDBC数据库驱动程序,就不需要额外的配置。在安装过程中,JDBC数据库驱动程序会自己完成有关的配置。)
- (2)两者使用的语言不同,JDBC在Java编程时使用,ODBC一般在C/C++编程时使用。
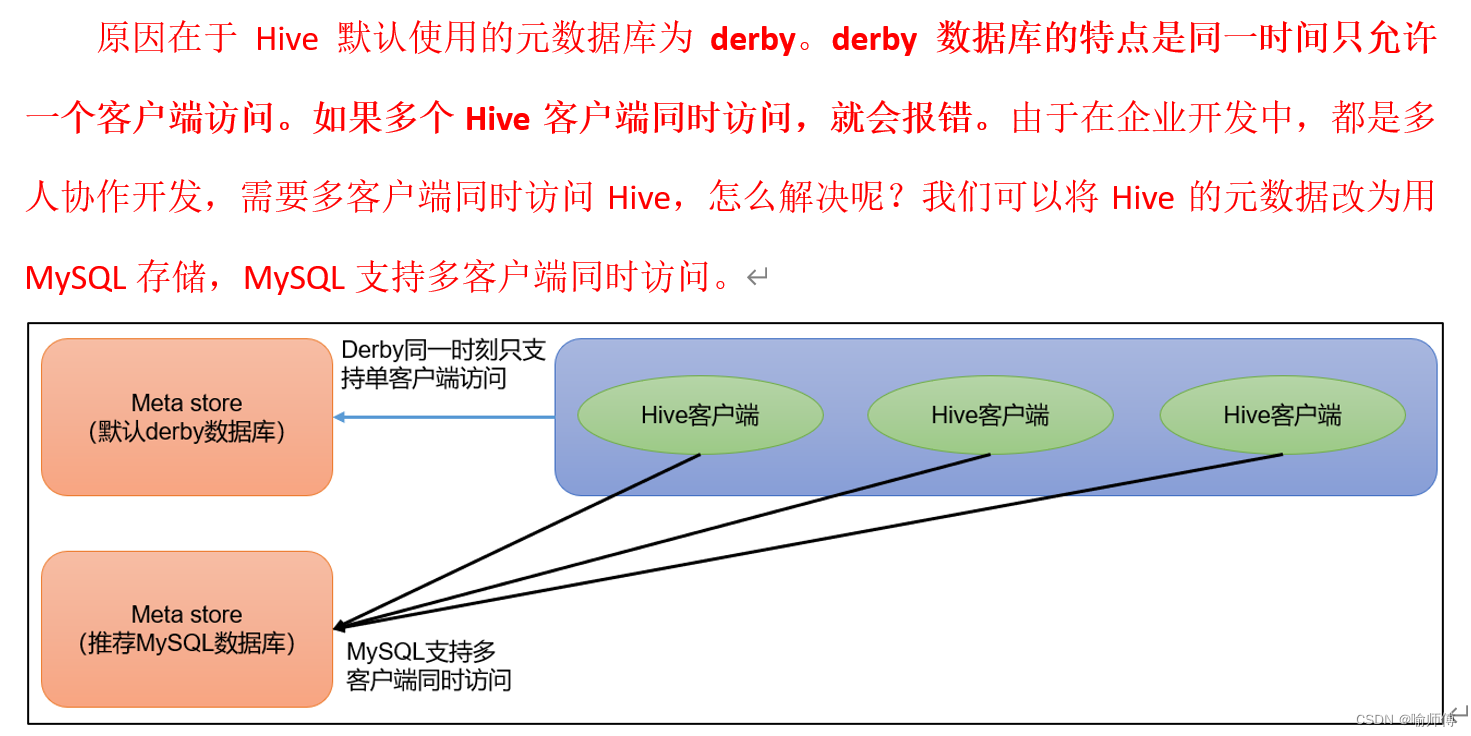
2.元数据:Metastore
- 元数据包括:数据库(默认是default)、表名、表的拥有者、列/分区字段、表的类型(是否是外部表)、表的数据所在目录等。
- 默认存储在自带的derby数据库中,由于derby数据库只支持单客户端访问,生产环境中为了多人开发,推荐使用MySQL存储Metastore。
3.驱动器:Driver
在 Hive 架构中,驱动器(Driver)是一个重要的组件,负责接收用户提交的 HiveQL 查询,然后解析、优化并执行这些查询。

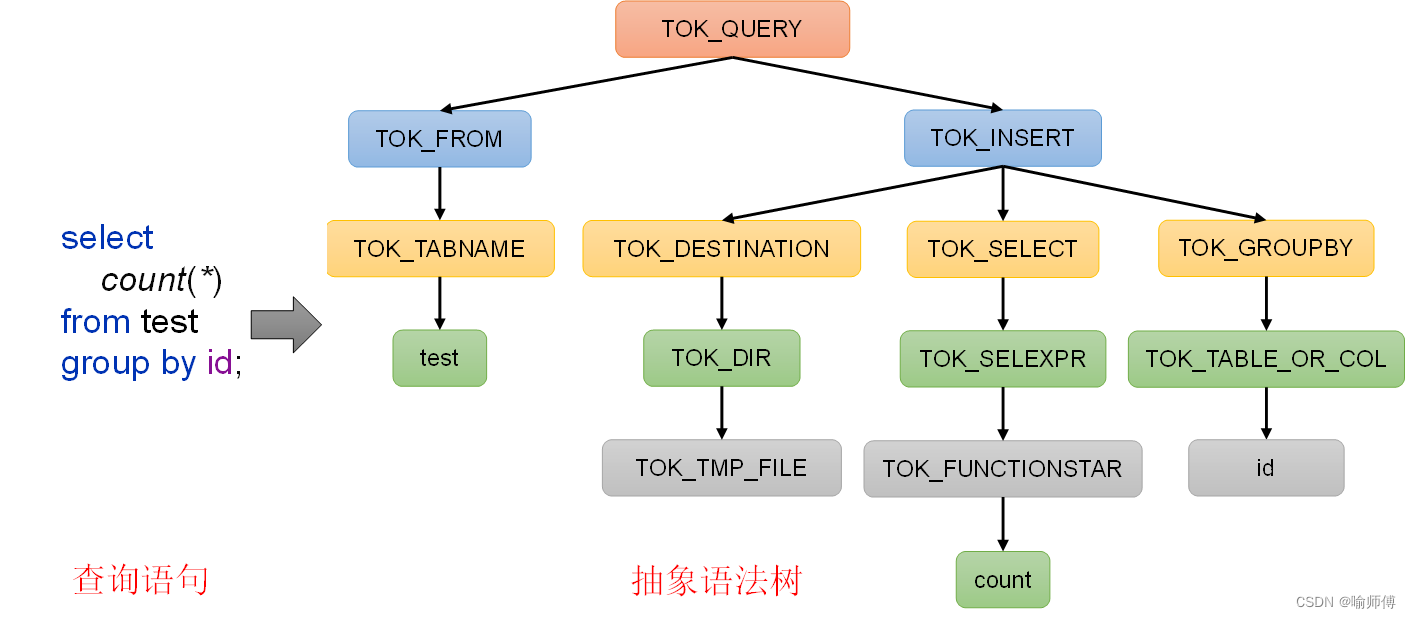
1. 查询解析(Parsing):
- 驱动器首先会对用户提交的 HiveQL 查询进行解析,将其转换成抽象语法树(Abstract Syntax Tree,AST)。
- 在这个过程中,它会检查查询语句的语法是否正确,以及查询中所引用的表是否存在等。
2. 查询优化(Optimization):
一旦查询被解析成 AST,驱动器会对其进行优化,以提高查询的执行效率。这个优化过程包括逻辑优化和物理优化两个方面:
-
逻辑优化:驱动器会对查询进行逻辑优化,例如通过重写查询、合并查询片段等方式,消除查询中的冗余操作,从而减少查询执行的计算量。
-
物理优化:一旦逻辑优化完成,驱动器会根据执行环境和数据特性选择合适的执行计划。这可能涉及选择合适的执行引擎、优化连接顺序、选择合适的算法等。
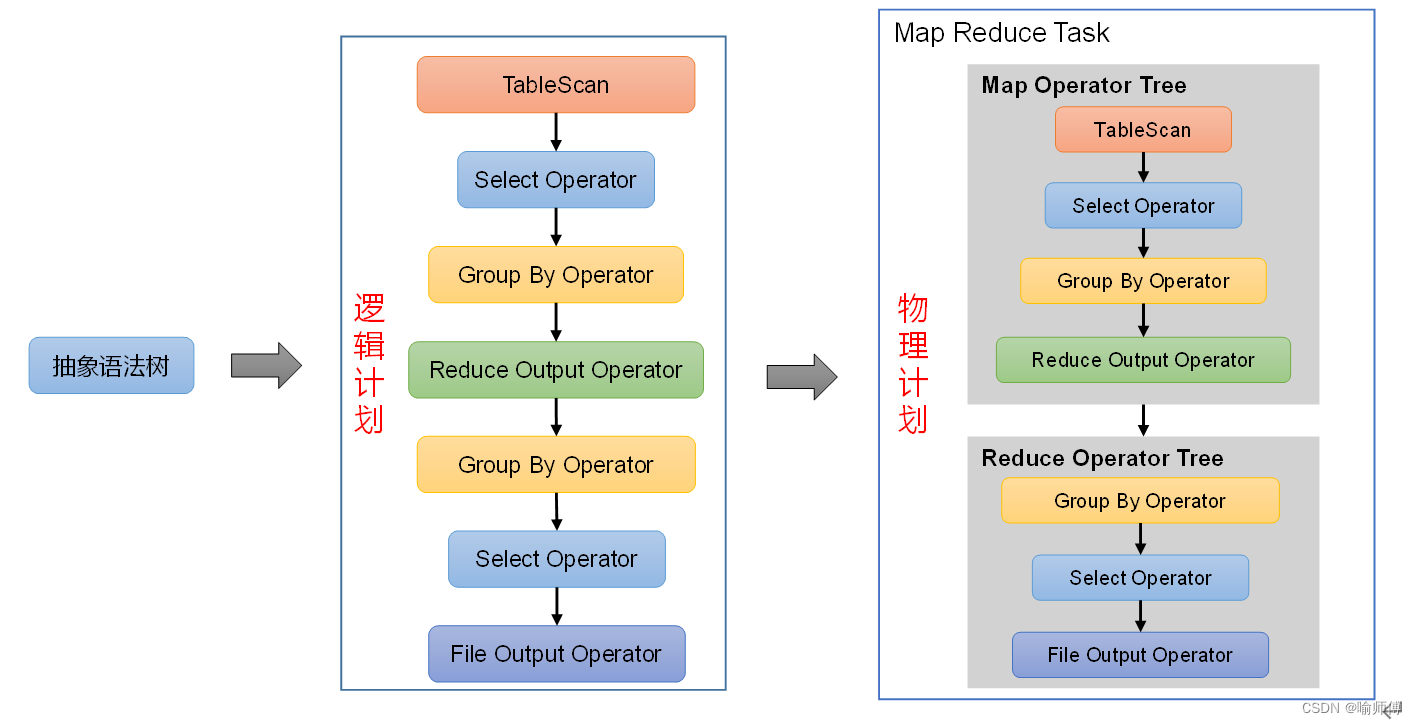
3. 查询执行计划生成(Execution Plan Generation):
- 优化完成后,驱动器将生成一个执行计划(Execution Plan),描述了如何执行查询以及执行的顺序。
- 执行计划通常是一个有向无环图(DAG),其中每个节点表示一个查询操作,每个边表示数据流向。
4. 任务调度和执行(Task Scheduling and Execution):
- 一旦执行计划生成,驱动器将根据执行计划将任务分发到集群中的多个节点上执行。
- 这包括将查询任务转换成 MapReduce 任务、Tez 任务、Spark 任务等,并将这些任务提交给相应的执行引擎执行。
5. 监控和错误处理(Monitoring and Error Handling):
- 在查询执行过程中,驱动器负责监控任务的执行状态,并及时处理可能出现的错误。
- 它会收集任务执行的日志和统计信息,以便后续的调优和故障排除。
6. 结果返回(Result Retrieval):
- 最后,当查询执行完成后,驱动器会从执行引擎中收集查询结果,并将其返回给用户。
- 用户可以通过命令行界面、Web UI 或客户端接口等方式获取查询结果。
驱动器在 Hive 架构中扮演着重要的角色,它负责接收、解析、优化和执行用户提交的查询,保证查询能够高效地在集群上执行,并及时返回执行结果给用户。

