
热门标签
热门文章
- 1python+pygame 最强大脑联动归位游戏_联动归位试玩
- 2Yum(Yellowdog Updater Modified)命令大全详解
- 330天自学(白帽黑客)网络安全技术
- 4大量机器学习&深度学习资料
- 5LeetCode:贪心算法(30道经典题目)_贪心算法经典例题
- 6涵盖从Java 5到Java 11所有重要特性,让Java学习不再难!_java5到java11特性
- 7Idea Community社区版,新建module不使用maven archetype
- 8安装NVIDIA-DOCKER_windows系统安装nvidia-docker
- 9Elasticsearch:如何创建 Elasticsearch PEM 和/或 P12 证书?_elastic-certificates.p12证书生成
- 10MQ选型:ActiveMQ、RocketMQ、RabbitMQ、Kafka对比_rocketmq和rabbitmq哪个用的多
当前位置: article > 正文
TextCNN(MR数据集----情感分类)
作者:2023面试高手 | 2024-02-09 19:46:25
赞
踩
mr数据集
TextCNN

一、文件目录

二、语料库(MR)
MR数据集(电影评论):
1.积极评论
2.消极评论
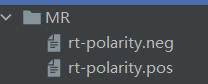
三、数据处理(MR_Dataset.py)
1.词向量导入
2.数据集加载
3.构建word2id并pad成相同的长度
4.求词向量均值和方差
5.生成词向量
6.生成训练集,验证集和测试集
from torch.utils import data import os import random import numpy as np from gensim.test.utils import datapath, get_tmpfile from gensim.models import KeyedVectors class MR_Dataset(data.Dataset): def __init__(self, state="train",k=0,embedding_type="word2cec"): self.path = os.path.abspath('.') if "data" not in self.path: self.path+="/data" # 加载MR数据集 pos_samples = open(self.path+"/MR/rt-polarity.pos", errors="ignore").readlines() neg_samples = open(self.path+"/MR/rt-polarity.neg", errors="ignore").readlines() datas = pos_samples + neg_samples datas = [data.split() for data in datas] labels = [1] * len(pos_samples) + [0] * len(neg_samples) # 区分积极,消极的标签 # 构建word2id并pad成相同长度 max_sample_length = max([len(sample) for sample in datas]) word2id = {"<pad>": 0} for i, data in enumerate(datas): for j, word in enumerate(data): if word2id.get(word) == None: word2id[word] = len(word2id) datas[i][j] = word2id[word] datas[i] = datas[i] + [0] * (max_sample_length - len(datas[i])) # 将所有句子pad成max_sample_length的长度 [10662,59] self.n_vocab = len(word2id) self.word2id = word2id if embedding_type=="word2vec": self.get_word2vec() # 将数据和标签打包一起打乱 c = list(zip(datas, labels)) random.seed(1) random.shuffle(c) datas[:], labels[:] = zip(*c) if state == "train": # [0 : 9]->[1 : 9] self.datas = datas[:int(k * len(datas) / 10)] + datas[int((k + 1) * len(datas) / 10):] self.labels = labels[:int(k * len(datas) / 10)] + labels[int((k + 1) * len(labels) / 10):] # [1 : 9]->[0 : 0.9*[1,9]] self.datas = np.array(self.datas[0:int(0.9 * len(self.datas))]) self.labels = np.array(self.labels[0:int(0.9 * len(self.labels))]) elif state == "valid": # [0 : 9]->[1 : 9] self.datas = datas[:int(k * len(datas) / 10)] + datas[int((k + 1) * len(datas) / 10):] self.labels = labels[:int(k * len(datas) / 10)] + labels[int((k + 1) * len(labels) / 10):] # [1 : 9]->[0.9*[1,9] : [1,9]] self.datas = np.array(self.datas[int(0.9 * len(self.datas)):]) self.labels = np.array(self.labels[int(0.9 * len(self.labels)):]) elif state == "test": # [0 : 9]->[0 : 1] self.datas = np.array(datas[int(k * len(datas) / 10):int((k + 1) * len(datas) / 10)]) self.labels = np.array(labels[int(k * len(datas) / 10):int((k + 1) * len(datas) / 10)]) def get_word2vec(self): if not os.path.exists(self.path+"/word2vec_embedding_mr.npy"): # 如果已经保存了词向量,就直接读取 print ("Reading word2vec Embedding...") # 求所用词向量均值和方差 wvmodel = KeyedVectors.load_word2vec_format("./GoogleNews-vectors-negative300.bin.gz", binary=True) # 词向量导入 tmp = [] # 词向量 for word, index in self.word2id.items(): try: tmp.append(wvmodel.get_vector(word)) except: pass mean = np.mean(np.array(tmp)) # 均值 std = np.std(np.array(tmp)) # 方差 # 生成词向量 vocab_size = len(self.word2id) embed_size = 300 embedding_weights = np.random.normal(mean, std, [vocab_size, embed_size]) # 在word2id中找不到的话随机初始化实现 for word, index in self.word2id.items(): try: embedding_weights[index, :] = wvmodel.get_vector(word) # (21402, 300) except: pass np.save(self.path + "/word2vec_embedding_mr.npy", embedding_weights) # 保存生成的词向量 else: embedding_weights = np.load(self.path + "/word2vec_embedding_mr.npy") # 载入生成的词向量 self.weight = embedding_weights def __getitem__(self, index): return self.datas[index], self.labels[index] def __len__(self): return len(self.datas) if __name__ == "__main__": # 生成训练集 mr_train_dataset = MR_Dataset() print(mr_train_dataset.__len__()) # 生成验证集 mr_valid_dataset = MR_Dataset("valid") print(mr_valid_dataset.__len__()) # 生成测试集 mr_test_dataset = MR_Dataset("test") print(mr_test_dataset.__len__())

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
四、模型(TextCNN.py)
import torch import torch.nn as nn import numpy as np class C2W(nn.Module): def __init__(self, config): super(C2W, self).__init__() self.char_hidden_size = config.char_hidden_size self.word_embed_size = config.word_embed_size self.lm_hidden_size = config.lm_hidden_size self.character_embedding = nn.Embedding(config.n_chars,config.char_embed_size) # 字符嵌入层,64,50 self.sentence_length = config.max_sentence_length self.char_lstm = nn.LSTM(input_size=config.char_embed_size,hidden_size=config.char_hidden_size, bidirectional=True,batch_first=True) # 字符lstm,50,50, self.lm_lstm = nn.LSTM(input_size=self.word_embed_size,hidden_size=config.lm_hidden_size,batch_first=True) # 语言模型lstm.50,150 self.fc_1 = nn.Linear(2*config.char_hidden_size,config.word_embed_size) # 线性组合生成词表示 self.fc_2 =nn.Linear(config.lm_hidden_size,config.vocab_size) # 生成类别用于预测 def forward(self, x): input = self.character_embedding(x) #[64, 16, 50] char_lstm_result = self.char_lstm(input) #[64, 16, 100] word_input = torch.cat([char_lstm_result[0][:,-1,0:self.char_hidden_size], char_lstm_result[0][:,0,self.char_hidden_size:]],dim=1) #[64,100] word_input = self.fc_1(word_input) #[64,50] word_input = word_input.view([-1,self.sentence_length,self.word_embed_size]) #[8,8,50] lm_lstm_result = self.lm_lstm(word_input)[0].contiguous() #[8, 8, 150] lm_lstm_result = lm_lstm_result.view([-1,self.lm_hidden_size]) #[64, 150] print(lm_lstm_result.shape) out = self.fc_2(lm_lstm_result) #[64, 1000] return out class config: def __init__(self): self.n_chars = 64 # 字符的个数 self.char_embed_size = 50 # 字符嵌入大小 self.max_sentence_length = 8 # 最大句子长度 self.char_hidden_size = 50 # 字符lstm的隐藏层神经元个数 self.lm_hidden_size = 150 # 语言模型的隐藏神经元个数 self.word_embed_size = 50 # 生成的词表示大小 config.vocab_size = 1000 # 词表大小 if __name__=="__main__": config = config() c2w = C2W(config) test = np.zeros([64,16]) c2w(test)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
五、防止过拟合(pytorchtools.py)
import numpy as np import torch class EarlyStopping: """如果在给定的耐心之后,验证失败没有改善,那么Early会停止培训。""" def __init__(self, patience=7, verbose=False, delta=0,cv_index = 0): """ Args: patience (int):上次验证失败改善后需要等待多长时间。 默认值:7 verbose (bool): 如果为真,则为每个验证丢失改进打印一条消息。 默认值:False delta (float):监控量的最小变化,符合改善条件。 默认值:0 """ self.patience = patience self.verbose = verbose self.counter = 0 self.best_score = None self.early_stop = False self.val_loss_min = np.Inf self.delta = delta self.cv_index = cv_index def __call__(self, val_loss, model): score = -val_loss if self.best_score is None: self.best_score = score self.save_checkpoint(val_loss, model) elif score < self.best_score + self.delta: self.counter += 1 print('EarlyStopping counter: %d out of %d'%(self.counter,self.patience)) if self.counter >= self.patience: self.early_stop = True else: self.best_score = score self.save_checkpoint(val_loss, model) self.counter = 0 def save_checkpoint(self, val_loss, model): '''验证损失减少时保存模型。''' if self.verbose: print('Validation loss decreased (%.5f --> %.5f). Saving model ...'%(self.val_loss_min,val_loss)) torch.save(model.state_dict(), './checkpoints/checkpoint%d.pt'%self.cv_index) self.val_loss_min = val_loss
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
六、训练和测试
from pytorchtools import EarlyStopping import torch import torch.autograd as autograd import torch.nn as nn import torch.optim as optim from model import TextCNN from data import MR_Dataset import numpy as np import config as argumentparser config = argumentparser.ArgumentParser() config.filters = list(map(int,config.filters.split(","))) # conv的大小 torch.manual_seed(config.seed) # 随机种子 # 判断cuda是否可用 if torch.cuda.is_available(): torch.cuda.set_device(config.gpu) i=0 early_stopping = EarlyStopping(patience=10, verbose=True,cv_index=i) #训练集 training_set = MR_Dataset(state="train",k=i,embedding_type=config.embedding_type) # config.n_vocab = training_set.n_vocab # 词表大小 training_iter = torch.utils.data.DataLoader(dataset=training_set, batch_size=config.batch_size, shuffle=True, num_workers=0) # num_workers=2,线程个数2 if config.use_pretrained_embed: config.embedding_pretrained = torch.from_numpy(training_set.weight).float() # 标记 else: config.embedding_pretrained = False #验证集 valid_set = MR_Dataset(state="valid", k=i,embedding_type="no") valid_iter = torch.utils.data.DataLoader(dataset=valid_set, batch_size=config.batch_size, shuffle=False, num_workers=0) #测试集 test_set = MR_Dataset(state="test", k=i,embedding_type="no") test_iter = torch.utils.data.DataLoader(dataset=test_set, batch_size=config.batch_size, shuffle=False, num_workers=0) model = TextCNN(config) if config.cuda and torch.cuda.is_available(): model.cuda() config.embedding_pretrained.cuda() criterion = nn.CrossEntropyLoss() optimizer = optim.Adam(model.parameters(), lr=config.learning_rate) count = 0 loss_sum = 0 def get_test_result(data_iter,data_set): model.eval() data_loss = 0 true_sample_num = 0 for data, label in data_iter: if config.cuda and torch.cuda.is_available(): data = data.cuda() label = label.cuda() else: data = torch.autograd.Variable(data).long() out = model(data)#(bc,2) loss = criterion(out, autograd.Variable(label.long())) data_loss += loss.data.item() true_sample_num += np.sum((torch.argmax(out, 1) == label).cpu().numpy()) acc = true_sample_num / data_set.__len__() return data_loss,acc for epoch in range(config.epoch): # 训练开始 model.train() for data, label in training_iter: if config.cuda and torch.cuda.is_available(): data = data.cuda() label = label.cuda() else: data = torch.autograd.Variable(data).long() label = torch.autograd.Variable(label).squeeze() out = model(data) l2_loss = config.l2*torch.sum(torch.pow(list(model.parameters())[1],2)) loss = criterion(out, autograd.Variable(label.long()))+l2_loss loss_sum += loss.data.item() count += 1 if count % 100 == 0: print("epoch", epoch, end=' ') print("The loss is: %.5f" % (loss_sum / 100)) loss_sum = 0 count = 0 optimizer.zero_grad() loss.backward() optimizer.step() # save the model in every epoch # 一轮训练结束 # 验证集上测试 valid_loss,valid_acc = get_test_result(valid_iter,valid_set) early_stopping(valid_loss, model) print ("The valid acc is: %.5f" % valid_acc) if early_stopping.early_stop: print("Early stopping") break # 训练结束,开始测试 acc = 0 model.load_state_dict(torch.load('./checkpoints/checkpoint%d.pt' % i)) test_loss, test_acc = get_test_result(test_iter, test_set) print("The test acc is: %.5f" % test_acc) acc += test_acc / 10 print("The test acc is: %.5f" % acc)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
实验结果
输出loss值:

举个例子判断:
x = "it's so bad"
x = x.split()
x = [training_set.word2id[word] for word in x]
x = np.array(x+[0]*(59-len(x))).reshape([1,-1])
x = torch.autograd.Variable(torch.Tensor(x)).long()
out = model(x)
- 1
- 2
- 3
- 4
- 5
- 6
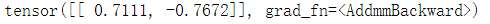
明显0.7111比较大,所以输出为位置0,0表示消极。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/2023面试高手/article/detail/72865
推荐阅读
相关标签

