
- 1Java基础 & 常见数据结构与算法 & 项目总结_java常用数据结构和基本算法
- 2Codeforces Round #336 (Div. 1) D. Power Tree(dfs序线段树)
- 3【Leetcode】反转链表 合并链表 相交链表 链表的回文结构_链表交叉合并
- 4rbac之 权限粒度控制到按钮级别
- 5批处理命令大全_批处理文件命令大全
- 6Java程序员不得不会的124道面试题(含答案)_java面试题
- 7基于 P-Tuning v2 进行 ChatGLM2-6B 微调实践 | 京东云技术团队_chatglm2 微调 推理
- 8[AIGC] 开源流程引擎哪个好,如何选型?
- 9深度学习-TensorFlow2 :构建DNN神经网络模型【构建方式:自定义函数、keras.Sequential、Compile&Fit、自定义Layer、自定义Model】_使用tensorflow搭建dnn
- 10Stable Diffusion 安装教程(详细)_stable diffusion安装
如何做中文文本的情感分析?_方面级情感分析能应用到中文的模型
赞
踩
如何做中文文本的情感分析?
这是本学期在大数据哲学与社会科学实验室做的第三次分享了。
第一次分享的是:如何利用“wordcloud+jieba”制作中文词云?
第二次分享的是:如何爬取知乎中问题的回答以及评论的数据?
本次给大家分享两种实现中文文本情感分析的方式,第一种是借助百度AI平台的文本情感分析,第二种是使用snownlp的文本情感分析。
1. 百度AI平台的文本情感分析
使用百度AI平台的文本情感分析主要分为两个步骤,第一步是创建一个账号,第二步是根据SDK调用平台提供的API函数进行情感分析。
第一步:创建账号
首先,我们打开百度AI网站,然后点击控制台。
http://ai.baidu.com/

跳转到登陆界面,输入账号密码后,跳转到管理界面,此时我们点击自然语言处理。进入到自然语言处理应用界面。
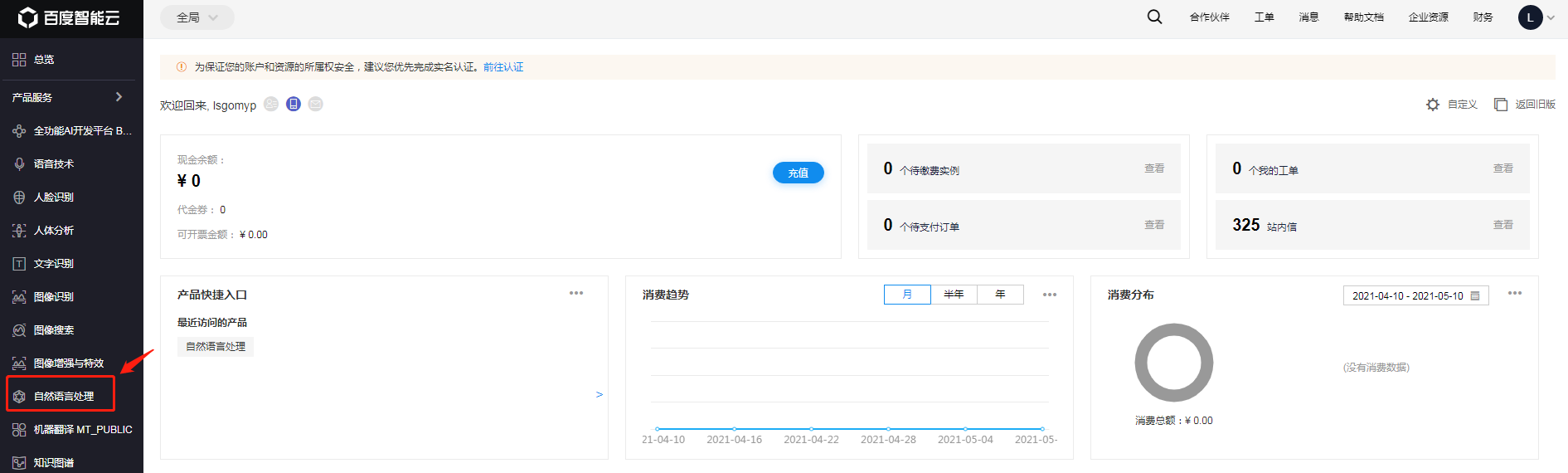
然后创建一个应用(如已创建好,就点击管理应用)。
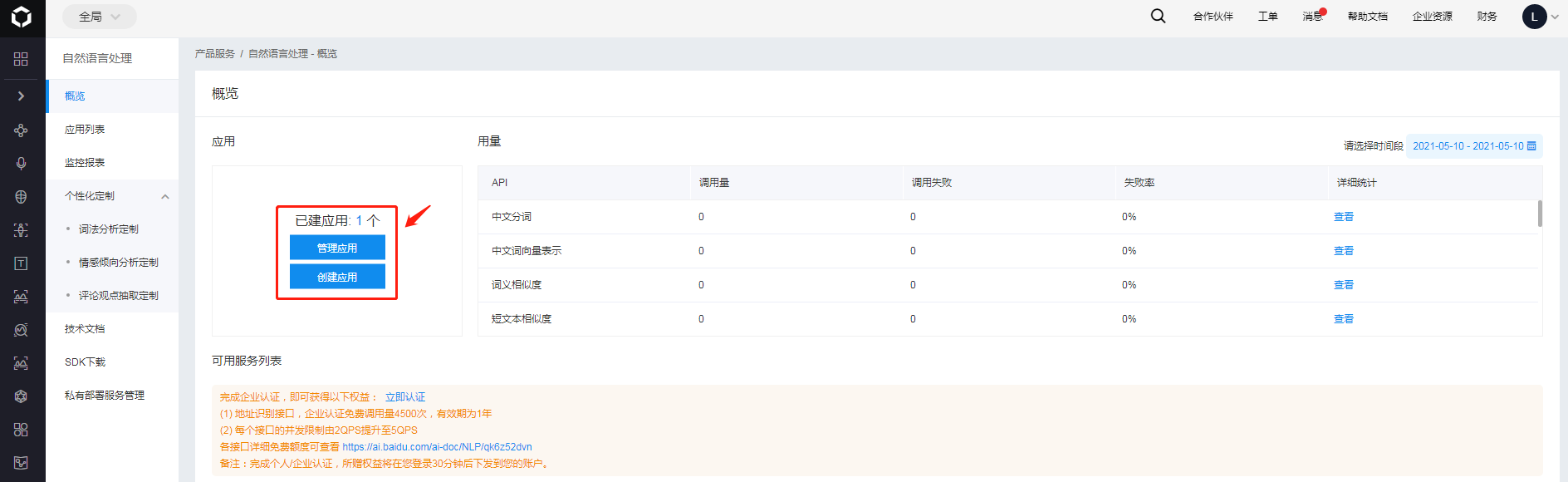
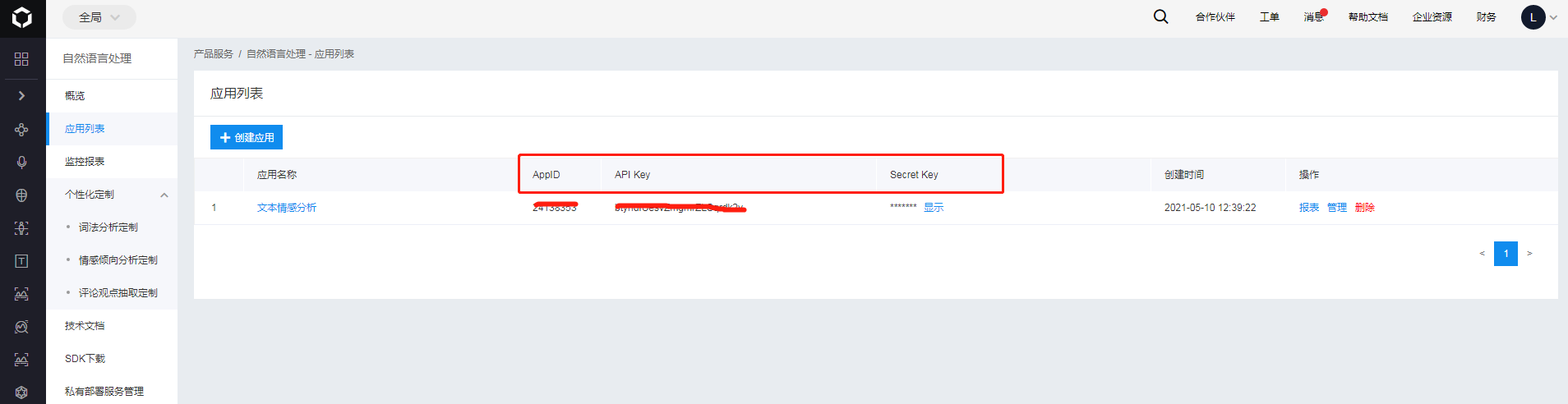
创建好后,进入到应用列表中,记下来AppID、API Key、Secret Key这三个参数的值。在后面对API进行调用的时候需要用到这三个参数。
第二步:进行文本情感分析
有关百度AI平台的自然语言处理的SDK(Software Development Kit)文档见如下网址:
http://ai.baidu.com/ai-doc/NLP/tk6z52b9z
这份SDK文档,包括了词法分析、词向量表示、词义相似度、短文本相似度、评论观点抽取、情感倾向分析、文章标签、文章分类、文本纠错、中文分词、词性标注、新闻摘要、地址识别等常用NLP功能。有关这些功能的使用,我们后面再来写图文进行详细介绍,下面只介绍情感分析功能。
首先,我们先安装要使用到的库。
pip install baidu-aip
- 1
安装好后,我们就可以调用API函数来对包含主观观点信息的文本进行情感极性类别(积极、消极、中性)的判断了,代码如下:
from aip import AipNlp
""" 你的 APPID AK SK """
APP_ID = '你的APP_ID'
API_KEY = '你的API_KEY'
SECRET_KEY = '你的SECRET_KEY'
client = AipNlp(APP_ID, API_KEY, SECRET_KEY)
text = "王建红真帅"
""" 调用情感倾向分析 """
dict = client.sentimentClassify(text)
print(dict)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
sentimentClassify(text)函数:用于对文本的情感分析,参数text是进行分析的文本内容(GBK编码),最大2048字节。
它的返回示例:
{
'log_id': 5284845474026755873,
'text': '王建红真帅',
'items': [
{
'positive_prob': 0.999855, #表示属于积极类别的概率
'negative_prob': 0.000144523, #表示属于消极类别的概率
'confidence': 0.999679, #表示分类的置信度
'sentiment': 2 #表示情感极性分类结果
}
]
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
返回数据参数详情如下:
| 参数 | 类型 | 说明 |
|---|---|---|
| text | string | 输入的文本内容 |
| items | array | 输入的词列表 |
| +sentiment | number | 表示情感极性分类结果, 0:负向,1:中性,2:正向 |
| +confidence | number | 表示分类的置信度 |
| +positive_prob | number | 表示属于积极类别的概率 |
| +negative_prob | number | 表示属于消极类别的概率 |
【例子】测试一个有关中医的文本
text = u"因为中医自己都不认可自己,你就别为难外人了。中医们嘴上吹嘘自己有多厉害," \
u"实际上,他们能当上中医,还得西医给他们体检合格了才能入职。中医理论不能指导中医入职体检," \
u"中医术语不能用于中医入职体检报告,甚至中医死了,他的死亡证明也和中医理论与术语没什么关系。" \
u"你看中医自己都不用,只能说明中医药是专供中医粉的。"
dict = client.sentimentClassify(text)
print(dict['items'])
# [{'positive_prob': 1.76205e-05, 'confidence': 0.999961, 'negative_prob': 0.999982, 'sentiment': 0}]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
我们可以发现这段关于中医的描述偏消极('sentiment': 0)。
2. 使用snownlp的文本情感分析
Python有一个第三方库snownlp,它是专门用来处理中文文本内容的库,有中文分词(s.words)、词性标注(s.tags)、情感分析(s.sentiments)、提取关键词(s.keywords())等功能。
首先,我们先安装要使用到的库(安装后可以直接用)。
pip install snownlp
- 1
安装好后,我们就可以调用函数来对包含主观观点信息的文本进行情感分析了,它会计算出文本语义接近积极的概率,越接近0情感表现越消极,越接近1情感表现越积极。代码如下:
from snownlp import SnowNLP
text = "王建红真帅"
s = SnowNLP(text)
print(text, s.sentiments)
# 王建红真帅 0.868676346818001
- 1
- 2
- 3
- 4
- 5
- 6
- 7
【例子】测试一个有关中医的文本
from snownlp import SnowNLP text = u"因为中医自己都不认可自己,你就别为难外人了。中医们嘴上吹嘘自己有多厉害," \ u"实际上,他们能当上中医,还得西医给他们体检合格了才能入职。中医理论不能指导中医入职体检," \ u"中医术语不能用于中医入职体检报告,甚至中医死了,他的死亡证明也和中医理论与术语没什么关系。" \ u"你看中医自己都不用,只能说明中医药是专供中医粉的。" s = SnowNLP(text) for sentence in s.sentences: print(sentence, SnowNLP(sentence).sentiments) # 因为中医自己都不认可自己 0.816024132542549 # 你就别为难外人了 0.6792294609027675 # 中医们嘴上吹嘘自己有多厉害 0.32479885192764957 # 实际上 0.478723404255319 # 他们能当上中医 0.7191238537063072 # 还得西医给他们体检合格了才能入职 0.2899327459226514 # 中医理论不能指导中医入职体检 0.9719464371262481 # 中医术语不能用于中医入职体检报告 0.9964791023333988 # 甚至中医死了 0.5308849018309401 # 他的死亡证明也和中医理论与术语没什么关系 0.994350435104035 # 你看中医自己都不用 0.6714833680109371 # 只能说明中医药是专供中医粉的 0.9076878772503925 print(s.sentiments) # 0.9999999813523964 from snownlp import sentiment sen = sentiment.classify(text) print(sen) # 0.9999999813523964

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
我们看到snownlp的情感分析结果与百度AI的情感分析结果相反。所以,在实际的项目中,需要根据实际的数据重新训练情感分析的模型。
首先,我们看一下snownlp的语料库:
C:\ProgramData\Anaconda3\Lib\site-packages\snownlp
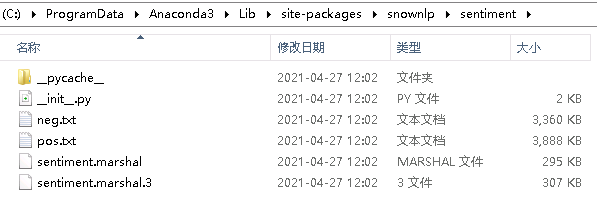
sentiments目录下有5个文件,其中__init__.py是程序,neg.txt和pos.txt分别是消极和积极语料库(也就是用来训练的数据集)sentiment.marshal.3和sentiment.marshal是训练保存的模型。(python2保存的是sentiment.marshal;python3保存的是sentiment.marshal.3)。
其次,我们看一下__init__.py文件中的代码。
data_path = os.path.join(os.path.dirname(os.path.abspath(__file__)), 'sentiment.marshal') class Sentiment(object): def __init__(self): self.classifier = Bayes() # 使用的是Bayes的模型 def save(self, fname, iszip=True): self.classifier.save(fname, iszip) # 保存最终的模型 def load(self, fname=data_path, iszip=True): self.classifier.load(fname, iszip) # 加载贝叶斯模型 # 分词以及去停用词的操作 def handle(self, doc): words = seg.seg(doc) # 分词 words = normal.filter_stop(words) # 去停用词 return words # 返回分词后的结果 def train(self, neg_docs, pos_docs): data = [] # 读入负样本 for sent in neg_docs: data.append([self.handle(sent), 'neg']) # 读入正样本 for sent in pos_docs: data.append([self.handle(sent), 'pos']) # 调用的是Bayes模型的训练方法 self.classifier.train(data) def classify(self, sent): # 1、调用sentiment类中的handle方法 # 2、调用Bayes类中的classify方法 ret, prob = self.classifier.classify(self.handle(sent)) # 调用贝叶斯中的classify方法 if ret == 'pos': return prob return 1 - probclass Sentiment(object): classifier = Sentiment() classifier.load() def train(neg_file, pos_file): neg_docs = codecs.open(neg_file, 'r', 'utf-8').readlines() pos_docs = codecs.open(pos_file, 'r', 'utf-8').readlines() global classifier classifier = Sentiment() classifier.train(neg_docs, pos_docs) def save(fname, iszip=True): classifier.save(fname, iszip) def load(fname, iszip=True): classifier.load(fname, iszip) def classify(sent): return classifier.classify(sent)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
从上述的代码中,classify函数和train函数是两个核心的函数,其中,train函数用于训练一个情感分类器,classify函数用于预测。在这两个函数中,都同时使用到的handle函数,handle函数的主要工作为:对输入文本分词和去停用词。
了解snownlp的语料库以及训练的代码之后,就可以用自己的语料库进行训练了。训练的过程大致分为如下的几个步骤:
- 准备正负样本,并分别保存,如正样本保存到pos.txt,负样本保存到neg.txt;
- 利用snownlp训练新的模型;
- 保存好新的模型;
重新训练情感分析的代码如下:
from snownlp import sentiment
# 重新训练模型
sentiment.train('./neg.txt', './pos.txt')
# 保存好新训练的模型
sentiment.save('sentiment.marshal')
- 1
- 2
- 3
- 4
- 5
- 6
训练完成后,可以把sentiment.marshal复制到sentiments目录下替换原来的或者改变读取模型的路径。
# data_path = os.path.join(os.path.dirname(os.path.abspath(__file__)),
# 'sentiment.marshal')
data_path = '这里填入新模型的路径'
- 1
- 2
- 3
- 4
经过以上操作,就可以利用新的模型来做情感分析了。
3. 总结
本文介绍了两种对文本进行情感分析的方式,大家可以根据自身喜好来进行选择。百度AI的自然语言处理和snownlp库,不止这一种功能,后面我会写一系列图文来介绍它们的使用方法。

