
- 1Linux_pyenv: No command 'pyenv' found_pyenv: command not found
- 2在浏览器中输入www.taobao.com后执行的全部过程_avtaobao
- 3Linux 清理磁盘空间&使用du指令排查服务器磁盘占用过大的文件_linux磁盘满了如何排查
- 4N阶Butterworth滤波器的频率响应(Python实现)_python如何绘制滤波器的频率响应图
- 5树莓派开机自启动python_树莓派设置开机自启动的两种方式
- 6NvidiaRTX3070Ti/GTX960M深度学习环境搭建教程_gtx960m怎么用pytorch
- 7批处理 探测在线计算机,批处理(bat)用来监测Windows网络状态脚本
- 8YOLOv8在NX上的tensorrt的加速部署(60帧率)
- 9SpringMVC必知必会_springmvc底层原理
- 103D Gaussian Splatting(高斯飞溅3D算法) Windows系统部署(简版) |导入到Unity_3d gaussian splatting unity
【深度学习】AlexNet CIFAR-10从70%到86%:CNN调参经验总结_cifar10 cnn loss下降慢
赞
踩
前言
最近课程实验是使用AlexNet训练CIFAR-10,并在验证集上验证。而AlexNet出现与2012年,模型结构也比较简单,在准确率方面与当今流行的网络肯定没法比,所以想要达到更改的准确率还是需要很多额外的改进。最终从70%左右的准确率提升到了86%,虽然也不是特别高但是有很多可以总结的地方。在整个实验过程中为了提升准确率也做了很多的尝试,各种参数加起来也跑了好几百个Epoch,这里总结了一些小规律,记录下来以供以后参考。
网络调整经验
1、更“宽”的网络
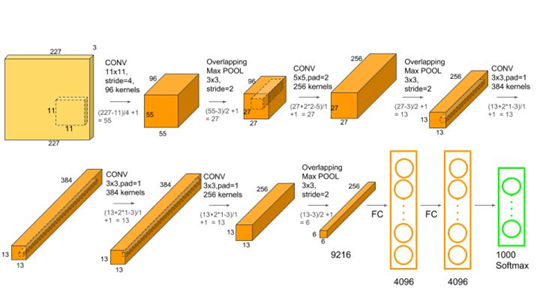
AlexNet的结构可以看这张图,因为只有一块显卡并没有使用原论文中的分两组训练。但是显然,CIFAR-10 32×32的分辨率与10类标签的设定是首先需要对输入输出进行调整的。比如第一个卷积的11×11就要换成3×3(为什么3×3可以参考之前的一些博客,当然图像分辨率的限制也有关系),然后pool因为分辨率的原因我也调小了一点,当然也有利于减少参数量。然后输出的全连接层1000个channel肯定要改成10了。这样就完成了对CIFAR-10基本的适配。
但是因为计算资源有限,起初还在尽可能等比的情况下缩小了各层的输入输出的通道数,例如256改成128,384改成192等等。后来使用AI Studio就快了很多(最初我装错PyTorch版本了,所以速度还是很慢,模型规模设置的还是很小)。
模型的宽度某种意义上可以理解为通道数,我开始觉得32×32不需要学习太多的feature map,但是后来实践证明我错了。当我使用各种trick在缩小了两三倍通道数的模型上训练最大达到83%的准确率,而当我稍有提高差不多达到了85%,而当还原回AlexNet原始通道数后便到了86%以上的效果。
显然,除了深度(为了保持AlexNet的结构就没去增减卷积层)宽度对模型的效果影响也很大,当然随之而来的也是更大的计算量以及更小的模型推断速度。
2、Batch Norm
这个不多说了,具体可以看Batch Norm的原理,总之这项技术对准确率提升效果真的很明显的。在使用之前77%就极限了,使用以后轻松上80%。对于卷积神经网络它的效果是有目共睹的。
3、Dropout
Dropout一般用在全连接层激活之前,这个没做对比测试,但是应该是有明显提升的,而且能防止过拟合,一般的模型中FC+Dropout还是很多的,配合Batch Norm效果更佳。
4、归一化
归一化可以把数据调整一个特定区间中,同时将其转化为无量纲的数值,这样可以使数据处理更为方便,可以加快模型收敛。所以计算了一下CIFAR-10的均值方差对其进行了归一化。
但是这会不会与Batch Norm有所重叠呢,BN是在每个batch计算的过程中每个卷积层进行归一化,这也保证了数据的分布,在避免很多数值问题的情况下提升了效果,而数据总体的归一化后再对每个batch归一化会产生怎样的效果呢?会不会甚至适得其反呢?可以推导下,不过感觉是重复了,因为bn更加强大而且在每个层都会处理。这里严格来说我也不是特别明白,留个坑吧。
train_loader = torch.utils.data.DataLoader(CIFAR10(args.data_path, train=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(((0.4914, 0.4822, 0.4465)), (0.2470, 0.2435, 0.2616))
])),
batch_size=args.batch_size, shuffle=True)
- 1
- 2
- 3
- 4
- 5
- 6
5、激活函数
AlexNet本身使用的是ReLU,现在也是公认效果比较好的激活函数,在一般的问题上普遍优于sigmoid、tanh。而ELU虽然增加了轻微的计算量但在很多情况下表现要好一些,不过也不绝对优于ReLU,好也没有好太多,所以在模型训练后期我想能不能改变激活函数来再微小的提升性能。
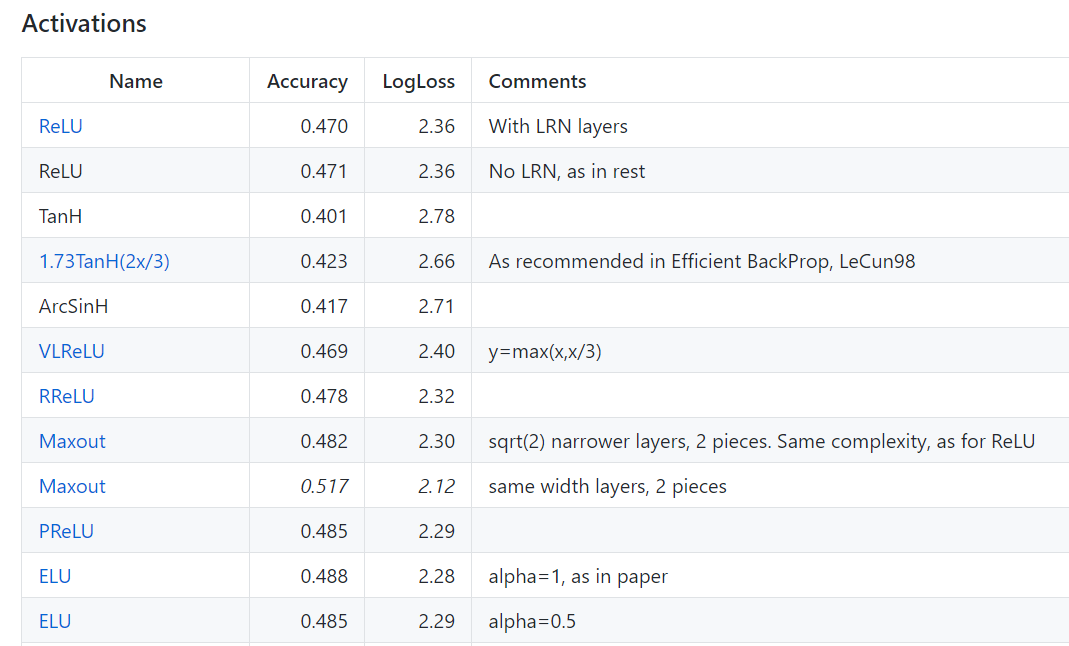
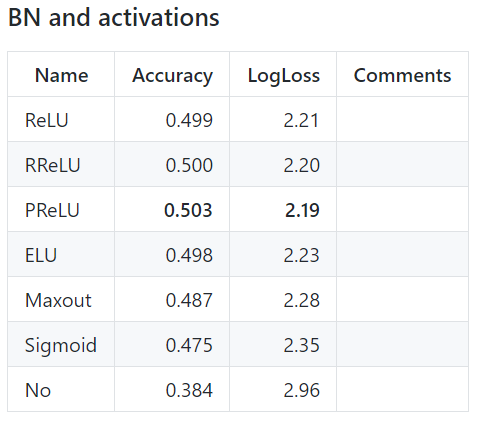
后来训练发现其效果不仅没有提升而且有所下降,收敛速度也变慢了。看了上面的对比发现好像ELU的效果还经常不如ReLU+BN,只是很多时候比ReLU好一点,所以后来还是使用了ReLU。不过上图也不绝对,只是对于其测试的数据表现出这样的效果。不过所以使用BN的时候用ReLU效果总不会太差。
6、学习率设置
最初训练模型的时候学习率是恒定的,使用Adam所以一般设置为了0.001。但在训练后期这个学习率显然偏大,使模型无法收敛到最佳效果,总是有一段距离。使用一些学习率衰减算法效果肯定会好,实验中我简单通过epoch分了几段进行手动衰减最终效果也还好。总之固定学习率是难以学到最有效果的,缩小后的学习率能够让准确率再提升一些。
7、优化方法
Adam在前期表现很好,但是看到一些论文也指出后期效果不如SGDm。但是这个实验总体问题不大,对准确率没有太大的影响。后来发现有种技术叫做AdaBound能够兼顾两者有点,后面的实验可以考虑使用一下。
8、FC channel
FC的channel数也做了尝试,因为增大模型宽度取得了比较好的效果想讲FC还原为4096会不会效果更好。但是实际测试从1024到2048最后的准确率好像没有明显变化,只是训练速度明显下降了。这可能也是32×32图像的像素较小造成的,并不需要太大的FC。至于FC的一般设计规律还有待进一步研究。
总结
上面介绍的主要都是为了提高模型准确率进行的各种尝试。一般来说提高模型宽度以及增加BN、Dropout对模型泛化能力提升较大,而优化方法和学习率等等也能有小幅度的提升,FC数量过大也没有明显的变化,毕竟就分10类。不过我想应该也会有帮助,可能是太大收敛了吧。总的来说这些经验还是有一些参考价值的,尽管是从AlexNet这样简单的网络中得到的,对于更高级的网络也可以适当选取。
参考资料
https://github.com/ducha-aiki/caffenet-benchmark/blob/master/Activations.md

