
热门标签
热门文章
- 1MySQL:零基础学数据库要看哪些书?从入门到精通全书籍推荐!_数据库书籍
- 2Selenium自动化程序被检测为爬虫,怎么屏蔽和绕过_selenium 被检测
- 3ConfigServer配置中心_config service 打开
- 4arch 安装准备--包管理的使用pacman
- 5关闭vue2项目的eslient检验_vue2关闭eslint检测
- 6Windows进程列表命令_tasklist 输出进程信息
- 7JS特效第137弹:jQuery仿空间留言时间轴特效
- 8uniapp的打包:h5、微信小程序以及APP方式_uniapp打包h5
- 9云计算概述(二)(云计算类型、技术驱动力、关键技术、特征、特点、通用点、架构层次)
- 10使用vue的多条件筛选以及当前行多余内容隐藏_vue多条件联动筛选
当前位置: article > 正文
Vision Transformer里的MLP Head里的Pre-Logits层_pre_logits
作者:2023面试高手 | 2024-02-16 12:02:49
赞
踩
pre_logits
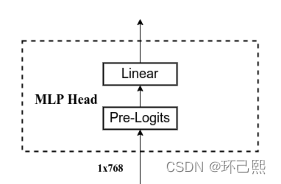
- # Representation layer
- if representation_size and not distilled:
- self.has_logits = True
- self.num_features = representation_size
- self.pre_logits = nn.Sequential(OrderedDict([
- ("fc", nn.Linear(embed_dim, representation_size)),
- ("act", nn.Tanh())
- ]))
- else:
- self.has_logits = False
- self.pre_logits = nn.Identity()
nn.Sequential:一个有序的容器,神经网络模块将按照在传入构造器的顺序依次被添加到计算图中执行,同时以神经网络模块为元素的有序字典也可以作为传入参数。
OrderedDict:python中字典dict是利用hash存储,因为各元素之间没有顺序。OrderedDict即按照有序插入顺序存储的有序字典。除此之外还可根据key,val进行排序。
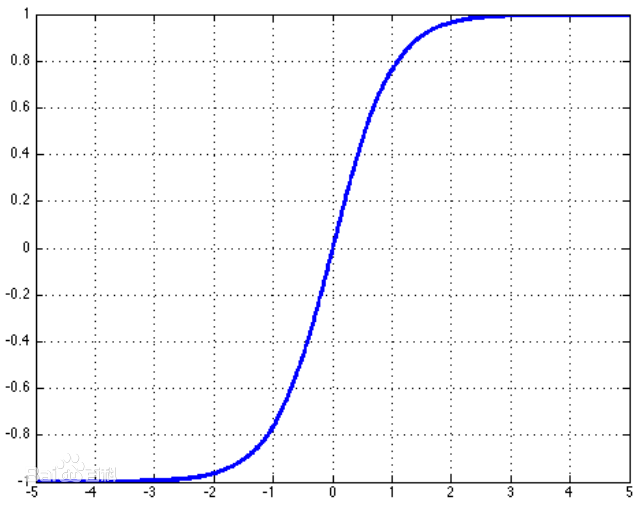
nn.tanh():双曲正切的激活函数
公式:
函数:y = tanh x;
图像:
nn.Identity: 恒等函数,即f(x) = x,相当于分类得到分类之前的特征。
声明:本文内容由网友自发贡献,转载请注明出处:【wpsshop博客】
推荐阅读
相关标签

