
- 1[太原理工大学] 2023 大三下 软件安全技术考试重点_完全控制原则
- 2一家超市,数据分析可以用哪些模型?_商超零售分析模型
- 3windows错误代码详解
- 4计算机毕业设计:python招聘数据分析系统+爬虫+可视化 +django框架+vue框架(包含文档+源码+部署教程)_vue python 分析系统
- 5vue项目实现前端打印功能_vue前端打印
- 6秒懂开源许可证GPL、BSD、MIT、Mozilla、Apache和LGPL的区别_bsd和mit的区别
- 7db和model用哪个开发大型项目 thinkphp_谈谈腾讯和百度的C++开发环境
- 8Kafka——Broker与客户端通信网络模型_broker框架
- 9Ubuntu14.04 server 静态IP配置总结_服务器em1静态ip
- 10Python 的Tkinter包系列之二:菜单_tkinter 菜单
3. 机器学习中为什么需要梯度下降_以物理学观点形象优雅解释机器学习中梯度下降法...
赞
踩
本文展示了通过将随机或小批量梯度下降视为朗之万随机过程,其中利用损失函数识别能量,并通过学习率融入随机化,我们可以理解为什么这些算法可以与全局优化器工作的一样好。这是一个优雅的结果,表明从多个视度看问题不仅是必要的,而且是非常有用的!
经典热力学/统计力学
想象一个场景,坐在你未点燃的燃气灶上的一壶水。为什么水很好地放在锅底?这是两种力量平衡的结果:
- 水分子彼此相邻而产生的力; 换句话说,彼此相邻的两个分子比两个远离的分子具有更低的能量。
- 由统计事实产生的“力”,即水分子更可能出现在最常发生的组态中。这是一个简单的组合事实:分子在锅底部均匀分布的方式多于在锅右侧具有更高的密度的方式。有很多、很多分子,所以“大数定律”告诉我们,我们不太可能看到统一分布的大偏离。
前者,来自能量的力对我们来说非常熟悉;后者仅适用于具有随机性的微观系统,是熵力。
调节能量力和熵力之间力平衡的“旋钮”是温度。温度越高,随机性越高,熵力占主导地位。这正是当你打开炉子并且水开始沸腾时会发生的事情:分子开始变得更随机,并且以牺牲使它们想要粘在一起的能量力为代价来探索更多的组态(配置)。当整个罐变成蒸汽时,能量力为零,但是分子在室内均匀分布方式的数量指数大于它们在罐中分布方式的数量。
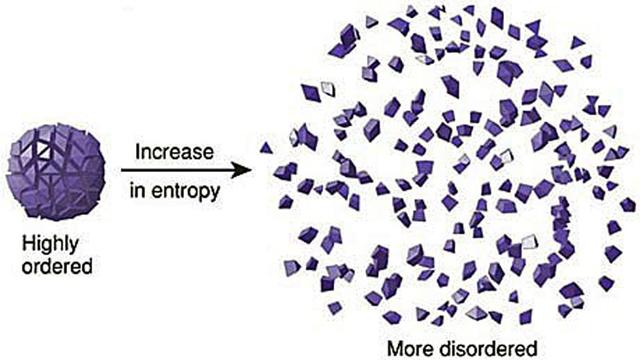
与机器学习的两个精妙类比
但是,这又与机器学习有什么关系呢?
状态变量速度p和位置q,就像线性回归中的权重系数,或深度学习网络中的权重一样。以与颗粒沉降到能量最小值相同的方式,权重将稳定在使损失函数最小化的配置中。
所以,我们在这里有热力学和机器学习之间的第一个类比:
给定状态配置中的能量(p,q)=损失函数(w)
这是将统计力学与机器学习联系起来的主要问题之一。统计力学传统上与均衡状态有关; 也就是说,给定熵的能量最小的状态,或者给定能量的熵最大的状态。换句话说,一切都已稳定下来的状态。
上世纪九十年代,Crooks涨落定理和Jarzynski恒等式的提出,使非平衡热力学方法得到学界的认同,并在诸多实验中得到验证。
回到我们的水的类比中,想象一下这次你坐在桌子上有一瓶水。我们已经说过,水瓶的平衡状态,水均匀分布在水的底部,是经典热力学力的结果。现在,摇动瓶子并将其放回原处。在放下水瓶的时刻和水再次沉降到其平衡状态的时刻之间发生的过程称为松弛。量化非平衡状态的松弛的一个主要概念是香农信息,或者,或许更直观地说,均衡分布和非均衡分布之间的KL-散度。
回到我们的ML算法,从我们最初的、随机分布的权重到最终的最小损失权重的转换,是从最初的非平衡状态开始的这种热力学松弛的精确镜像。这给了我们机器学习和统计物理学之间的第二个类比:
从初始非平衡状态松弛=优化权重实现从示例中学习的目的
通过最小化其能量来松弛平衡的物理系统类似于最小化其损失的机器学习模型。换句话说,摇动一瓶水然后将它放在桌子上并等待它平衡落定就像训练模型一样。水分子处于最小化系统能量的状态,而模型的重量则处于最小化损失函数的状态。
Langevin方程作为全局最小化算法
梯度下降法是机器学习最流行的优化方法之一。我们要论证的目标是用Langevin方程解释为什么梯度下降法的变体是有效的全局优化器。
流体中的随机运动
1905年爱因斯坦在一篇论文中得出了一个叫布朗的模型,即由较小的、快速移动的分子(在水中移动的花粉粒)碰撞引起的悬浮颗粒在液体中的随机运动。

布朗运动:尘埃粒子与气体分子碰撞
Langevin动力学
1908年,也就是爱因斯坦发表其具有里程碑意义的论文三年后,法国物理学家保罗·朗之万发表了另一篇开创性的文章,他在中概括了爱因斯坦的理论并开发了一个描述布朗运动的新微分方程,现在称为朗之万方程(LE):
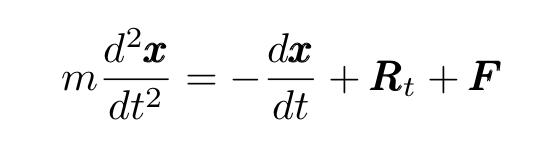
其中x是移动粒子的位置,m是其质量,R代表与较小的,快速移动的流体分子碰撞产生的(随机)力(看上文中的动画),F代表任何其他外力。随机力R是δ相关的平稳高斯过程,具有以下均值和方差:
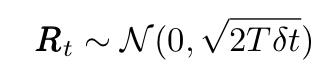
术语"Δ相关"意味着两个不同时间的力具有零相关性。LE是描述热力学不平衡的第一个数学方程。

保罗·朗之万
如果粒子的质量足够小,我们可以将左侧设置为零。此外,我们可以表达(保守)力作为某些势能的导数。我们获得:
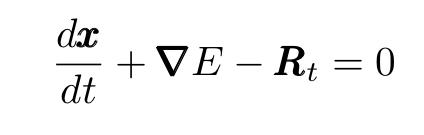
进而得到:
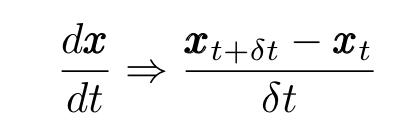
其中δt是一个小的时间间隔,并且移动项,我们获得了质量小的粒子的离散Langevin方程:
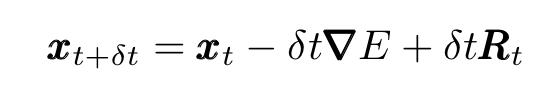
以这种方式表达,Langevin方程描述了经历布朗运动的粒子的增量位移。
Langevin动力学和全局最小
Langevin动力学的一个重要特性是随机过程x(t)的扩散分布p(x)(其中x(t)服从上面给出的Langevin方程)收敛于静止分布,普遍存在的玻尔兹曼分布(BD)
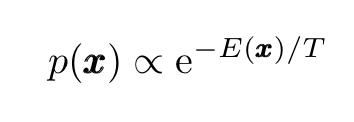
它集中在势能E(x)的全局最小值,从其函数形式,我们可以很容易地看到玻尔兹曼分布峰值在势能E(x)的全局最小值上。
更确切地说,如果在不连续的步骤之后温度缓慢降至零:
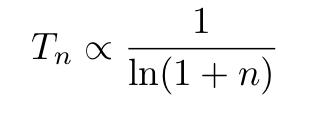
那么,p(x)将收敛到玻尔兹曼分布,得到大的n值(并且x将收敛到E(x)的全局最小值)。时间依赖温度的朗之万方程通常被解释为描述亚稳态物理状态衰变到系统的基态:这是能量的全局最小值。因此,可以使用Langevin动力学来设计即使是潜在的非凸函数也是全局最小化的算法。
该原理是模拟退火技术的基础,用于获得近似的全局函数最优值。
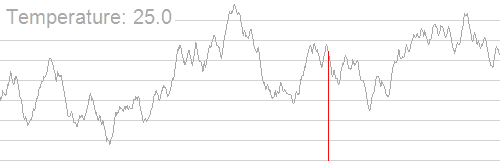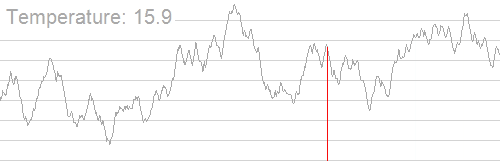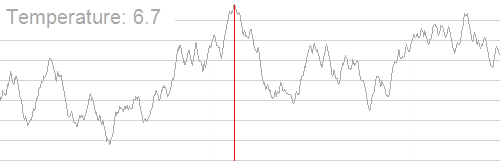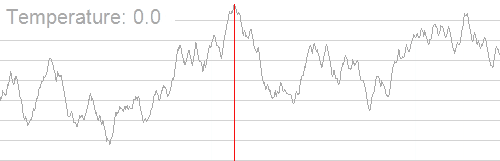
应用模拟退火搜索最大值
梯度下降算法
主角来了,现在切换到机器学习优化算法。
梯度下降是用于最小化(或最大化)损失(成本)函数的简单迭代优化算法。损失函数一般是多变量损失函数L(w)。GD算法是从任一点开始,在函数L(w)减小最快的负梯度方向:
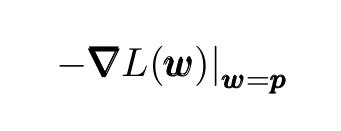
首先猜测或者说随机取一个最小值的初始值,并计算序列:
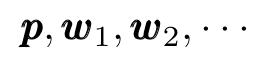
遵循迭代过程:
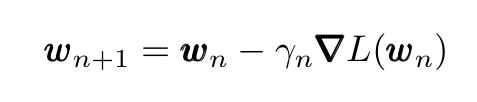
其中γ是学习率,允许在每次迭代时改变n。如果损失函数L及其梯度 具有某些特性并且遵循选择学习速率变化,则保证局部收敛(仅当L是凸的时才保证收敛到全局最小值,因为对于凸函数,任何局部最小值也是全局的一)。
随机梯度下降(SGD)和小批量梯度下降
与在每次迭代时扫描完整数据集的基本GD算法相比,SGD和小批量GD仅使用训练数据的子集。SGD使用训练数据的单个样本来更新每次迭代中的梯度,即当扫描训练数据时,它针对每个训练示例执行上述w的更新。小批量GD使用小批量的训练示例执行参数更新。
咱们用数学术语来表达。对于一般训练集:
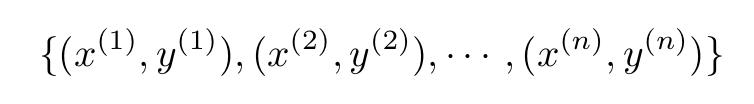
训练集n个样本。
损失函数具有一般形式:
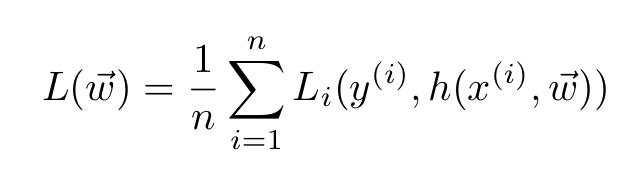
在小批量梯度下降的情况下,总和仅在批次内的训练样本上。特别是SGD仅使用一个样品。与GD相比,这些程序有两个主要优点:它们更快,可以处理更大的数据集(因为它们使用一个或几个样本)。
如下所示定义G和g,在这种情况下我们有:
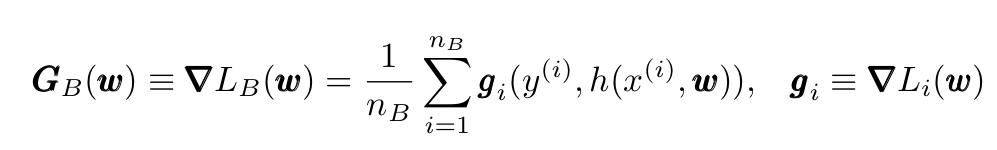
看一下下面的形象生动的动画,SGD融合与其他优化方法比较显示(这些其他方法,是SGD的改进)。
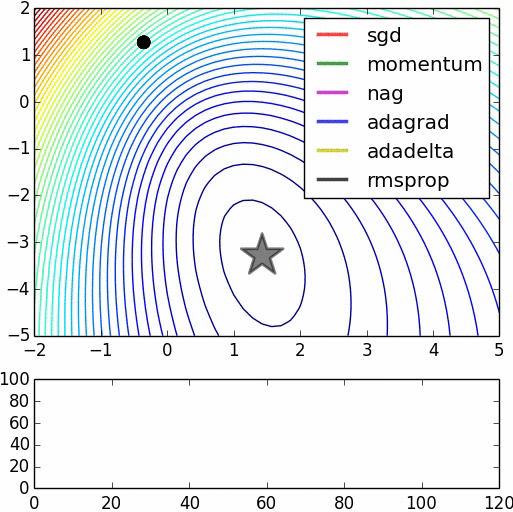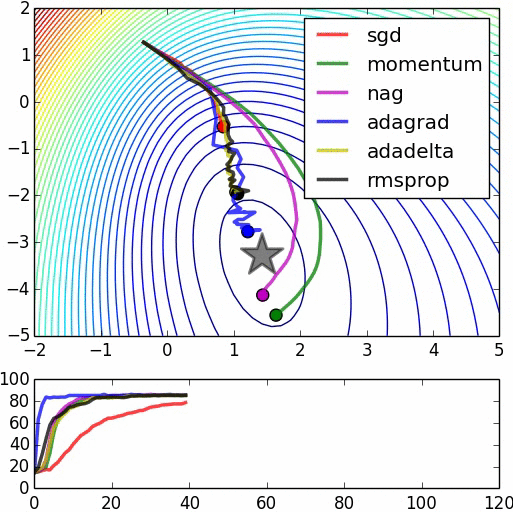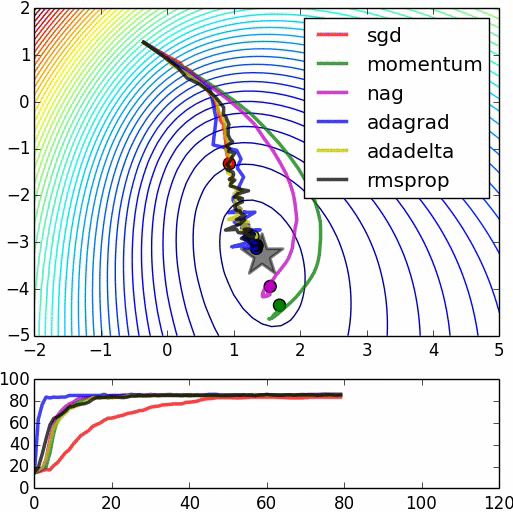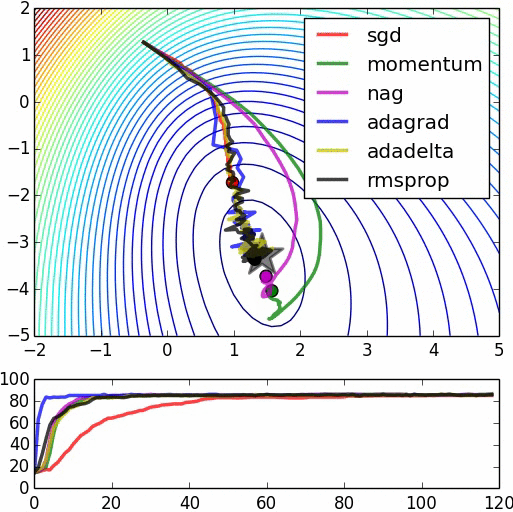
将物理学观点引入机器学习:梯度下降作为Langevin过程
下一步(也是最后一步)对于论证至关重要。忽略更严格的方面来解决主要想法。
我们可以将小批量梯度写为完整梯度和正态分布η之和:
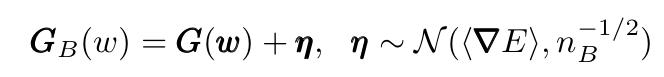
现在在GD迭代表达式中替换此表达式,我们得到:
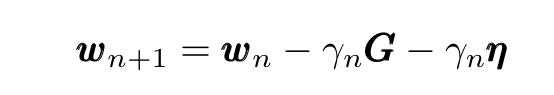
形象优雅的对接
将小批量梯度下降迭代的表达式与Langevin方程进行比较,我们可以立即注意到它们的相似性。更准确地说,它们使用以下对应关系变得相同:
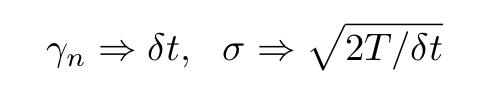
在第二个表达式中用δ代替δt,我们发现
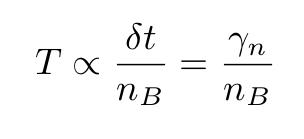
所以,SGD或小批量梯度下降算法在形式上类似于Langevin过程,这解释了为什么,如果学习速率根据前面提到的协议变化,则它们具有非常高的选择全局最小值的可能性。
实际上有表明在通常的梯度下降递归中增加一个噪声项会使算法收敛到全局最小值。必须强调的是,学习速率的"冷却协议"提供了关键的"额外"随机化,允许算法逃避局部最小值并收敛到全局最小值。

