
- 1【服务器数据恢复】服务器硬盘指示灯显示黄色的数据恢复案例_服务器硬盘灯亮黄灯
- 2K8S问题记录_failed to create pod sandbox: rpc error: code = un
- 3uboot启动流程详细分析(基于i.m6ull)
- 4用docker-compose快速部署ChirpStack_使用docker compose快速部署chirpstack
- 5使用篇=SpringCloud异常处理统一封装我来做、建议收藏_enableglobaldispose
- 6LAYA 3D编辑器(unity3D)使用教程(基础课)_laya跑酷3a
- 7六星经典CSAPP-笔记(7)加载与链接(上)
- 8蓝牙连接的sco问题_startbluetoothsco
- 9livego介绍以及最全使用方法介绍_livego还是go2rtc
- 10Autodesk官方最新的.NET教程(五)(C#版) _c# autocad allowsubselections 什么意思
操作系统的程序内存结构 —— data和bss为什么需要分开,各自的作用_data bss
赞
踩
1、操作系统的程序内存结构
1.1、程序编译运行过程
源代码(source coprede)→预处理器(processor)→编译器(compiler)→汇编程序(assembler)→目标程序(object code)→链接器(Linker)→可执行程序(executables)
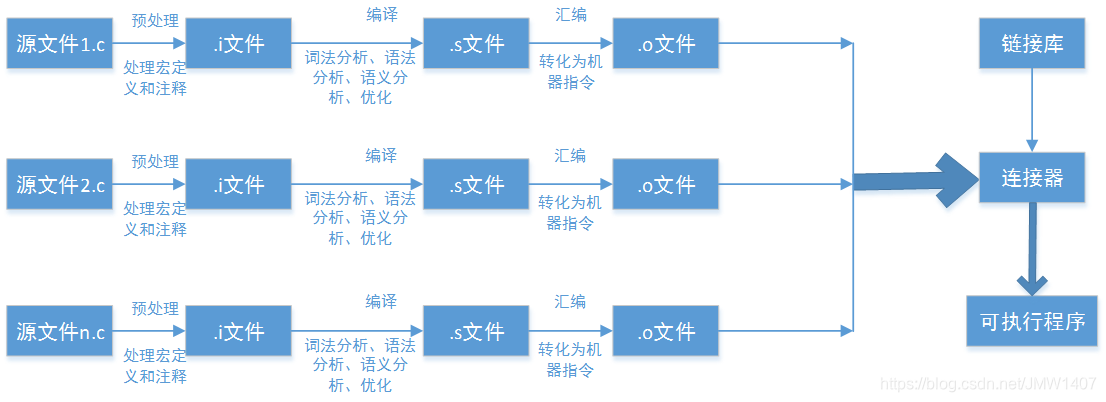
分配程序执行所需的栈空间、代码段、静态存储区、映射堆空间地址等,操作系统会创建一个进程结构体来管理进程,然后将进程放入就绪队列,等待CPU调度运行。参考1.2
1.2、程序的内存分布

- 1、
代码段(.text),也称文本段(TextSegment),存放着程序的机器码和只读数据,可执行指令就是从这里取得的。如果可能,系统会安排好相同程序的多个运行实体共享这些实例代码。这个段在内存中一般被标记为只读,任何对该区的写操作都会导致段错误(Segmentation Fault)。 2、数据段,包括已初始化的数据段(.data)和未初始化的数据段(.bss),- data:用来存放保存全局的和静态的已初始化变量,
- bss:后者用来保存全局的和静态的未初始化变量。数据段在编译时分配。
3、堆栈段分为堆和栈:堆(Heap):用来存储程序运行时分配的变量。- 堆的大小并不固定,可动态扩张或缩减。其分配由
malloc()、new()等这类实时内存分配函数来实现。 - 当进程调用
malloc等函数分配内存时,新分配的内存就被动态添加到堆上(堆被扩张); - 当利用
free等函数释放内存时,被释放的内存从堆中被剔除(堆被缩减) - 堆的内存释放由应用程序去控制,通常一个new()就要对应一个delete(),如果程序员没有释放掉,那么在程序结束后操作系统会自动回收。
- 堆的大小并不固定,可动态扩张或缩减。其分配由
栈(Stack)是一种用来存储函数调用时的临时信息的结构,如函数调用所传递的参数、函数的返回地址、函数的局部变量等。在程序运行时由编译器在需要的时候分配,在不需要的时候自动清除。- 栈的特性: 最后一个放入栈中的物体总是被最先拿出来,这个特性通常称为先进后出(FILO)队列。
- 栈的基本操作: PUSH操作:向栈中添加数据,称为压栈,数据将放置在栈顶;
- POP操作:POP操作相反,在栈顶部移去一个元素,并将栈的大小减一,称为弹栈。
堆和栈的区别:

1.3、.data和.bss分开的理由
1、首先介绍各段的关系:
.text部分是编译后程序的主体,也就是程序的机器指令。.data 和 .bss保存了程序的全局变量,.data保存有初始化的全局变量,.bss保存只有声明没有初始化的全局变量。text和data段都在可执行文件中(在嵌入式系统里一般是固化在镜像文件中),由系 统从可执行文件中加载;bss段不在可执行文件中,由系统初始化。
2、.bss的简单说明
BSS 是“Block Started by Symbol”的缩写,意为“以符号开始的块”。BSS是Unix链接器产生的未初始化数据段。
BSS段的变量只有名称和大小却没有值。此名后来被许多文件格式使用,包括PE。“以符号开始的块” 指的是编译器处理未初始化数据的地方。BSS节不包含任何数据,只是简单的维护开始和结束的地址,以便内存区能在运行时被有效地清零。BSS节在应用程序 的二进制映象文件中并不存在。
3、将.data和.bss分开的理由是为了节约磁盘空间,.bss不占实际的磁盘空间,为什么.bss不占磁盘空间呢?
#include <stdio.h>
int a[1000];
int b[1000] = {1};
int main()
{
printf("123\n");
return 0;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
这里编写了一个test.c文件,gcc编译gcc test.c -o test之后,使用ls -l test 命令就可以得到可执行文件的信息,文件的大小为12696字节
ls -l test
-rwxrwxr-x 1 xxx xxx 12696 Dec 1 01:04 test
size test
text data bss dec hex filename
1174 4568 4032 9774 262e test
- 1
- 2
- 3
- 4
- 5
- 6
接着我们修改源程序:
#include <stdio.h>
int a[1000] = {1};
int b[1000] = {1};
int main()
{
printf("123\n");
return 0;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
同样ls -l test
ls -l test
-rwxrwxr-x 1 xxx xxx 16696 Dec 1 01:09 test
size test
text data bss dec hex filename
1174 8568 8 9750 2616 test
- 1
- 2
- 3
- 4
- 5
- 6
- 可以看到大小从12696变成了16696,与之前相比,该文件占据的大小涨了4000字节,这不就是我们的数组a[1000]的大小吗?
- 我们所在的改动
仅仅是初始化了a[1000],让这个数组的所在段从.bss段改到了.data段。 - 通过
size test命令查看bss段的大小也减小了。这就证明了.bss段中的数据并没有占据磁盘空间,从而节约了磁盘的空间。
linux环境下的c语言,初始值为零和没有赋初始值的变量放在BSS段,因为这些值都是零,所以就不需要放到文件里面,等程序加载的时候再赋值就好了。
int a[1000]既然不占据实际的磁盘空间(是指不占据应该分配的内存大小),那么它的大小和符号存在哪呢?
- .bss段占据的大小存放在ELF文件格式中的段表(Section Table)中,段表存放了各个段的各种信息,比如段的名字、段的类型、段在elf文件中的偏移、段的大小等信息。我们可以通过命令
readelf -S test来查看test可执行文件的段表。 - .bss不占据实际的磁盘空间,只在段表中记录大小,在符号表中记录符号。当文件加载运行时,才分配空间以及初始化
$ readelf -S test.o There are 13 section headers, starting at offset 0x2d0: Section Headers: [Nr] Name Type Address Offset Size EntSize Flags Link Info Align [ 0] NULL 0000000000000000 00000000 0000000000000000 0000000000000000 0 0 0 [ 1] .text PROGBITS 0000000000000000 00000040 0000000000000017 0000000000000000 AX 0 0 1 [ 2] .rela.text RELA 0000000000000000 00000220 0000000000000030 0000000000000018 I 10 1 8 [ 3] .data PROGBITS 0000000000000000 00000057 0000000000000000 0000000000000000 WA 0 0 1 [ 4] .bss NOBITS 0000000000000000 00000057 0000000000000000 0000000000000000 WA 0 0 1 [ 5] .rodata PROGBITS 0000000000000000 00000057 0000000000000010 0000000000000000 A 0 0 1 [ 6] .comment PROGBITS 0000000000000000 00000067 000000000000002a 0000000000000001 MS 0 0 1 [ 7] .note.GNU-stack PROGBITS 0000000000000000 00000091 0000000000000000 0000000000000000 0 0 1 [ 8] .eh_frame PROGBITS 0000000000000000 00000098 0000000000000038 0000000000000000 A 0 0 8 [ 9] .rela.eh_frame RELA 0000000000000000 00000250 0000000000000018 0000000000000018 I 10 8 8 [10] .symtab SYMTAB 0000000000000000 000000d0 0000000000000120 0000000000000018 11 9 8 [11] .strtab STRTAB 0000000000000000 000001f0 000000000000002b 0000000000000000 0 0 1 [12] .shstrtab STRTAB 0000000000000000 00000268 0000000000000061 0000000000000000 0 0 1 Key to Flags: W (write), A (alloc), X (execute), M (merge), S (strings), I (info), L (link order), O (extra OS processing required), G (group), T (TLS), C (compressed), x (unknown), o (OS specific), E (exclude), l (large), p (processor specific)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 其中,.rela.text是针对.text段的重定位表,链接器在处理目标文件时,需要对目标文件中的某些部位进行重定位,即代码段和数据段那些对绝对地址的引用的位置,这些重定位的信息都会放在.rela.text中,.rel开头的都是用于重定位。
- LINK表示符号表的下标,INFO表示它作用于哪个段,值是相应段的下标。
- 字符串表(.strtab):保存普通字符串,比如符号名字。
- 段表字符串表(.shstrtab):保存段表中用到的字符串,比如段名。
- ELF文件头和段表都有各自的结构体,这里不列举,只需要知道它里面存储的是什么东西就好。
总结:为什么需要.bss段?
1、.data部分:
- 数据部分包含初始化的数据项的数据定义。初始化数据是在程序开始运行之前具有值的数据。这些值是可执行文件的一部分。当将可执行文件加载到内存中以供执行时,它们会加载到内存中。
- 定义的初始化数据项越多,可执行文件将越大,并且在运行它时将其从磁盘加载到内存所需的时间也越长。
2、 .bss部分:
- 在程序开始运行之前,并非所有数据项都需要具有值。例如,当您从磁盘文件中读取数据时,需要有一个放置数据的位置,以便将数据从磁盘中导入。程序的.bss部分中定义了类似的数据缓冲区。您为缓冲区留出了一定数量的字节,并为缓冲区指定了名称
- .data节中定义的数据项与.bss节中定义的数据项之间存在至关重要的区别:.data节中的数据项增加了可执行文件的大小。.bss部分中的数据项没有
1.4、程序的指令和数据分开原因:
-
1、一方面是当程序被装载后,
数据和指令分别被映射到两个虚存区域。由于数据区域对于进程来说是可读写的,而指令区域对于进程来说是只读的,所以这两个虚存区域的权限可以被分别设置成可读写和只读。这样可以防止程序的指令被有意或无意地改写。 -
2、另外一方面是对于现代的CPU来说,它们有着极为强大的缓存(Cache)体系。指令区和数据区的分离有利于提高程序的局部性。现代CPU的缓存一般都被设计成数据缓存和指令缓存分离,所以程序的指令和数据被分开存放对CPU的缓存命中率提高有好处。
-
3、,其实也是最重要的原因,就是当系统中运行着多个该程序的副本时,它们的指令都是一样的,所以内存中只须要保存一份改程序的指令部分。对于指令 这种只读的区域来说是这样,对于其他的只读数据也一样,比如很多程序里面带有的图标、图片、文本等资源也是属于可以共享的。当然每个副本进程的数据区域是不一样的,它们是进程私有的。不要小看这个共享指令的概念,它在现代的操作系统里面占据了极为重要的地位,特别是在有动态链接的系统中,可以节省大量的内存。比如我们常用的Windows Internet Explorer 7.0运行起来以后,它的总虚存空间为112 844 KB,它的私有部分数据为15 944 KB,即有96 900 KB的空间是共享部分。如果系统中运行了数百个进程,可以想象共享的方法来节省大量空间。关于内存共享的更为深入的内容我们将在装载这一章探讨。
- 简单来说就是:代码段是可以共享的,数据段是私有的,当运行多个程序的副本时,只需要保存一份代码段部分。
参考
1、https://www.zhihu.com/search?type=content&q=.data%E5%92%8C.bss
2、https://zhuanlan.zhihu.com/p/145263213

