
- 1Centos停止维护后我们可以这么做!
- 2Spring自定义注解加cglib动态代理,实现bean扫描注入和数据源切换_spring接口多个实现自动注入cglib代理
- 3[开发技巧]·深度学习使用生成器加速数据读取与训练简明教程(TensorFlow,pytorch,keras)_基于深度学习的测试用例生成器
- 4java打印unicode_用java实现打印汉字的Unicode和GBK编码一览表
- 5emby,jellyfin,kodi系列_repository.emby.kodi-1.0.6.zip
- 6SakuraFrp内网穿透访问远程无公网IP服务器(linux,ssh)_樱花映射可以给别的电脑创建隧道吗
- 7Python|cpython 源码解析|Python 程序运行原理_python源码解析
- 8内网服务器批量挂载本地iso镜像的yum源_内网挂载yum
- 9大模型学习笔记四:LangChain开发框架解析
- 10IPv4 ACL访问列表简介、ACL的3种主要分类介绍与配置、以大白话介绍ACL通配符、ACL动作、定义方向、Rule序号。_在espn上划分acl
ELF文件详解—初步认识_.elf
赞
踩
一、 引言
在讲解ELF文件格式之前,我们来回顾一下,一个用C语言编写的高级语言程序是从编写到打包、再到编译执行的基本过程,我们知道在CPU上执行的是低级别的机器语言,从高级语言到低级别的机器语言肯定是要经过翻译过程,这个过程大体的过程如下图所示:

在Unix系统中,从源文件到可执行目标文件是由编译驱动程序完成的,如大名鼎鼎的gcc,翻译过程包括图中的是个阶段;
Ø 预处理阶段
预处理器(cpp)根据以字符#开头的命令修给原始的C程序,结果得到另一个C程序,通常以.i作为文件扩展名。主要是进行文本替换、宏展开、删除注释这类简单工作。
对应的命令:linux> gcc -E hello.c hello.i
Ø 编译阶段
编译器将文本文件hello.i翻译成hello.s,包含相应的汇编语言程序
对应的命令:linux> gcc -S hello.c hello.s
Ø 汇编阶段
将.s文件翻译成机器语言指令,把这些指令打包成一种叫做可重定位目标程序的格式,并将结果保存在目标文件.o中(把汇编语言翻译成机器语言的过程)。
把一个源程序翻译成目标程序的工作过程分为五个阶段:词法分析;语法分析;语义检查和中间代码生成;代码优化;目标代码生成。主要是进行词法分析和语法分析,又称为源程序分析,分析过程中发现有语法错误,给出提示信息。
对应的命令:linux> gcc -c hello.c hello.o
Ø 链接阶段
此时hello程序调用了printf函数。 printf函数存在于一个名为printf.o的单独的预编译目标文件中。 链接器(ld)就负责处理把这个文件并入到hello.o程序中,结果得到hello文件,一个可执行文件。最后可执行文件加载到储存器后由系统负责执行, 函数库一般分为静态库和动态库两种。静态库是指编译链接时,把库文件的代码全部加入到可执行文件中,因此生成的文件比较大,但在运行时也就不再需要库文件了。其后缀名一般为.a。动态库与之相反,在编译链接时并没有把库文件的代码加入到可执行文件中,而是在程序执行时由运行时链接文件加载库,这样可以节省系统的开销。动态库一般后缀名为.so,gcc在编译时默认使用动态库。
二、目标文件
由上面的过程,我们可以看出在经过汇编器和连接器作用后都会输出一个目标文件,那这两个目标文件有什么样的区别呢?说到这里我们先引入目标文件的形式
2.1 三种目标文件形式
(1)可重定位目标文件:包含二进制代码和数据,其形式可以和其他目标文件进行合并,创建一个可执行目标文件
(2)可执行目标文件:包含二进制代码和数据,可直接被加载器加载执行
(3)共享目标文件:可被动态的加载和链接(本文暂时不讨论)
由此我们可知由汇编器生成的就是可重定位目标文件,经过链接器作用后才生成可执行目标文件,链接器的作用就是以一组可重定位目标文件作为输入,生成可加载和运行的可执行目标文件,具体需要完成以下两个工作:
Ø 符号解析:符号解析的目的是将目标文件中每个符号(静态变量、函数、全局变量)和其定义进行关联
Ø 重定位:将每个符号的定义与具体在虚拟内存中的位置进行关联
最终生成可执行目标文件
说到这里好像还是没有说清楚这两种目标文件有什么区别,我们还是先把这个问题放一下,相信你看完下一节,应该会有答案,下面我们开始引入目标文件ELF文件。
三、ELF文件
目标文件再不同的系统或平台上具有不同的命名格式,在Unix和X86-64 Linux上称为ELF(Executable and Linkable Format, ELF)。
ELF文件格式提供了两种不同的视角,在汇编器和链接器看来,ELF文件是由Section Header Table描述的一系列Section的集合,而执行一个ELF文件时,在加载器(Loader)看来它是由Program Header Table描述的一系列Segment的集合
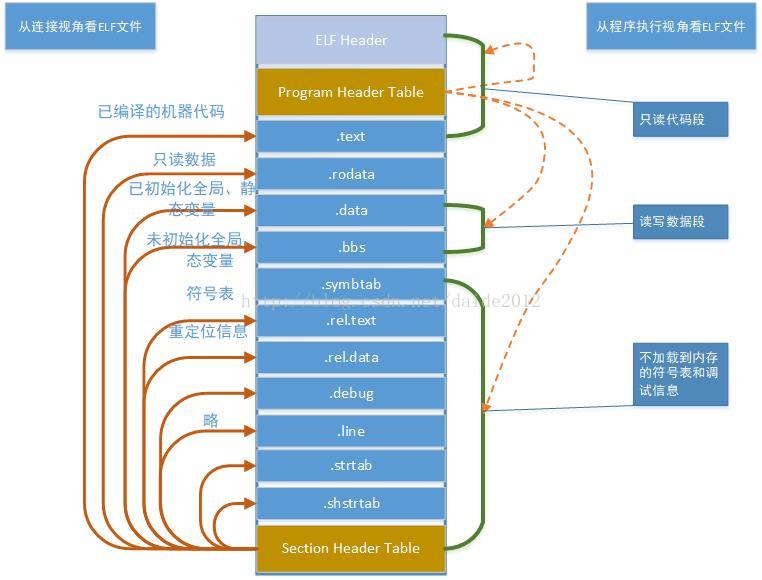
左边是从汇编器和链接器的视角来看这个文件,开头的ELF Header描述了体系结构和操作系统等基本信息,并指出Section Header Table和Program Header Table在文件中的什么位置,Program Header Table在汇编和链接过程中没有用到,所以是可有可无的,Section Header Table中保存了所有Section的描述信息。右边是从加载器的视角来看这个文件,开头是ELF Header,Program Header Table中保存了所有Segment的描述信息,Section Header Table在加载过程中没有用到,所以是可有可无的。注意Section Header Table和Program Header Table并不是一定要位于文件开头和结尾的,其位置由ELF Header指出,上图这么画只是为了清晰。
我们在汇编程序中用.section声明的Section会成为目标文件中的Section,此外汇编器还会自动添加一些Section(比如符号表)。Segment是指在程序运行时加载到内存的具有相同属性的区域,由一个或多个Section组成,比如有两个Section都要求加载到内存后可读可写,就属于同一个Segment。有些Section只对汇编器和链接器有意义,在运行时用不到,也不需要加载到内存,那么就不属于任何Segment。
目标文件需要链接器做进一步处理,所以一定有Section Header Table;可执行文件需要加载运行,所以一定有Program Header Table;而共享库既要加载运行,又要在加载时做动态链接,所以既有Section Header Table又有Program Header Table。
关于目标文件的具体节的数据结构,有兴趣的读者参照北大的一个资料写的非常详细
下面用readelf工具读出目标文件max.o的ELF Header和Section Header Table,然后我们逐段分析。

接下来我们来看Section Header Table格式

从Section Header中读出各Section的描述信息,其中.text和.data是我们在汇编程序中声明的Section,而其它Section是汇编器自动添加的。Addr是这些段加载到内存中的地址(我们讲过程序中的地址都是虚拟地址),加载地址要在链接时填写,现在空缺,所以是全0。Off和Size两列指出了各Section的文件地址,比如.data从文件地址0x60开始,一共0x38个字节,回去翻一下程序,.data中定义了14个4字节的整数,一共是56个字节,也就是0x38个。根据以上信息可以描绘出整个目标文件的布局。
| 起始文件地址 | Section或Header |
| 0 | ELF Header |
| 0x34 | .text |
| 0x60 | .data |
| 0x98 | .bss(此段为空) |
| 0x98 | .shstrtab |
| 0xc8 | Section Header Table |
| 0x208 | .symtab |
| 0x288 | .strtab |
| 0x2b0 | .rel.text |
这个文件不大,我们直接用hexdump或者使用010 Editor工具把目标文件的字节全部打印出来看。

3.1 .shstrtab和.strtab
.shstrtab和.strtab这两个Section中存放的都是ASCII码:

可见.shstrtab中保存着各Section的名字,.strtab中保存着程序中用到的符号的名字。每个名字都是以'\0'结尾的字符串。
我们知道,C语言的全局变量如果在代码中没有初始化,就会在程序加载时用0初始化。这种数据属于.bss段,在加载时它和.data段一样都是可读可写的数据,但是在ELF文件中.data段需要占用一部分空间保存初始值,而.bss段则不需要。也就是说,.bss段在文件中只占一个Section Header而没有对应的Section,程序加载时.bss段占多大内存空间在Section Header中描述。在我们这个例子中没有用到.bss段,以后我们会看到这样的例子。
3.2.rel.text和.symtab
我们继续分析readelf输出的最后一部分,是从.rel.text和.symtab这两个Section中读出的信息。

.rel.text告诉链接器指令中的哪些地方需要重定位,我们在下一节讨论。
.symtab是符号表。Ndx列是每个符号所在的Section编号,例如data_items在第3个Section里(也就是.data),各Section的编号见Section Header Table。Value列是每个符号所代表的地址,在目标文件中,符号地址都是相对于该符号所在Section的相对地址,比如data_items位于.data段的开头,所以地址是0,_start位于.text段的开头,所以地址也是0,但是start_loop和loop_exit相对于.text段的地址就不是0了。从Bind这一列可以看出_start这个符号是GLOBAL的,而其它符号是LOCAL的,GLOBAL符号是在汇编程序中用.globl指示声明过的符号。
3.3 .text节

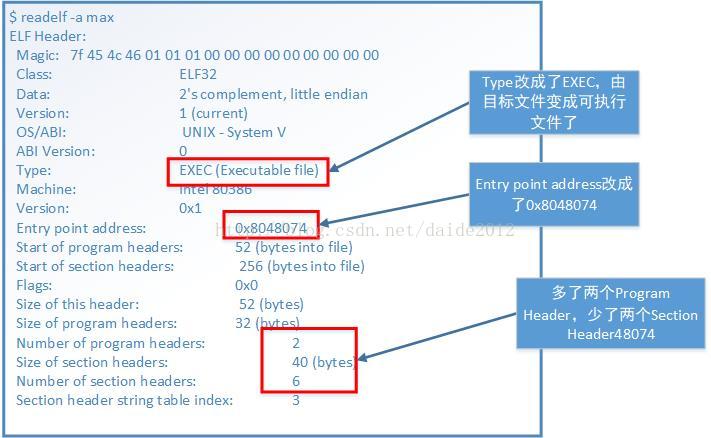
在看section header的变化

.text和.data的加载地址分别改成了0x08048074和0x0804 90a0。.bss段没有用到,所以被删掉了。.rel.text段就是用于链接过程的,链接完了就没用了,所以也删掉了。
在看多出来的两个program header

多出来的Program Header Table描述了两个Segment的信息。.text段和前面的ELFHeader、Program Header Table一起组成一个Segment(FileSiz指出总长度是0x9e),.data段组成另一个Segment(总长度是0x38)。VirtAddr列指出第一个Segment加载到虚拟地址0x0804 8000(注意在x86平台上后面的PhysAddr列是没有意义的),第二个Segment加载到地址0x0804 90a0。Flg列指出第一个Segment的访问权限是可读可执行,第二个Segment的访问权限是可读可写。最后一列Align的值0x1000(4K)是x86平台的内存页面大小。在加载时要求文件中的一页对应内存中的一页,对应关系如下图所示。

这个可执行文件很小,总共也不超过一页大小,但是两个Segment必须加载到内存中两个不同的页面,因为MMU的权限保护机制是以页为单位的,一个页面只能设置一种权限。此外还规定每个Segment在文件页面内偏移多少加载到内存页面仍然偏移多少,比如第二个Segment在文件中的偏移是0xa0,在内存页面0x0804 9000中的偏移仍然是0xa0,所以是从0x0804 90a0开始,这样规定是为了简化链接器和加载器的实现。从上图也可以看出.text段的加载地址应该是0x0804 8074,也正是_start符号的地址和程序的入口地址。
原来目标文件符号表中的Value都是相对地址,现在都改成绝对地址了。此外还多了三个符号__bss_start、_edata和_end,这些是在链接过程中添进去的,加载器可以利用这些信息把.bss段初始化为0。
再看一下反汇编的结果:

到此为止ELF文件的问题已介基本介绍,关于共享目标文件的格式和加载过程将在后续补上。

