
- 1Unity中脚本中Start函数的两种执行方式_unity start其他函数能调用吗start吗?
- 2下载安装MinGW-w64详细步骤(c/c++的编译器gcc的windows版,win10真实可用)
- 3Python123练习【序列操作,程序控制结构】_使用程序计算整数n到整数n+100
- 4VUE+SpringBoot运行原理_springboot和vue项目运行
- 5关于Chrome谷歌浏览器开发者工具(f12)中Network中Name空白的解决方案_chrome浏览器name不显示sug
- 6手眼标定,眼在手中,眼在手外_gen_cam_par_area_scan_telecentric_division
- 7渲染管线_渲染管线 cs
- 8文本分类(LSTM+PyTorch)_lstm文本分类
- 9Unity导出exe报错,PC端_unity报错build completed with a result of 'failed' i
- 10后台管理UI的选择_后台管理系统ui选择
[AI]算法小抄-总结大模型微调方式_大模型微调算法
赞
踩
系列文章主要目的快速厘清不同方法的原理差异和应用场景,
对于理论的细节请参考文末的Reference,
Reference中会筛选较为正确,细节的说明
想要建构属于自己应用或特定垂直领域的大模型,除了类似LangChain, TaskMatrix.AI使用Prompt工程的方式,微调(Fine tunning)是更可控且可以持续迭代的方式,预训练语言模型(PLM) + Finetuning的方式也是目前主流的范式,以下介绍几个主流方案,每个方案针对的场景,所需要的数据,成本都不相同:
Supervised finetuning
Prompt tuning
相比于直接透过子任务的结构去进行finetuning,prompt tuning主要是让数据变成更像是预训练模型更熟悉的模式进行finetuning,前身是In-Context Learning (ICL),比如文本情绪分类任务,传统的finetuning数据和promt-tuning区别如下
[Normal Fintuning]
Input: This movie is great
label: happy
[Prompt Tuning]
Input: This movie is great, feel [Mask]
label: This movie is great, feel happy
可以观察到Prompt-tining的数据更接近自然语言的表述,更接近PLM训练的dmomain。主要的步骤包含:模版建构(Template construction)和标签词映射(Label Word Verbalizer),详细的原理可以参考Prompt-Tuning——深度解读一种新的微调范式
Instruction finetuning
首先由Finetuned Language Models Are Zero-Shot Learners提出,主要是将finetuning的子任务转化成自然语言指令(Instruction)进行微调,具体的子任务并不重要,主要是让PLM能够更了解人类的指令,并做出正确的解答,以下是论文中的示例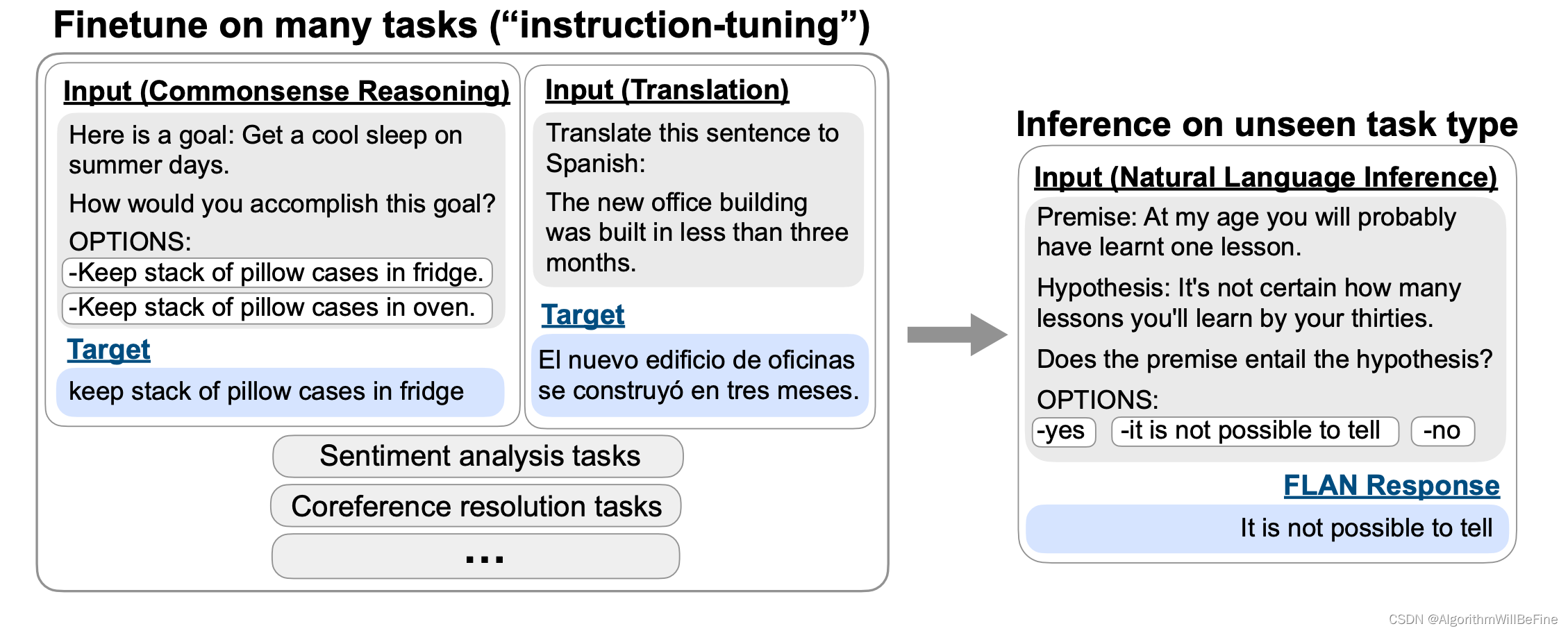
Intrsuction fintuning也是GPT3之后的大模型能够很好响应人类指令的原因,LangChain, LlmaIndex乃至于GPT-Plugin等工具能够实用也主要是因为个微调方法
Reinforcement learning human fine tuning (RLHF)
RLHF跟之前两个提到方法的区别主要在于其主要的学习目标是人类真实的偏好,也是CahtGPT的回答能够更好满足人类需求的关键所在,训练框架也跟之前较为不同,引入强化学习的训练方式,收先提出这个方案的是Fine-Tuning Language Models from Human Preferences
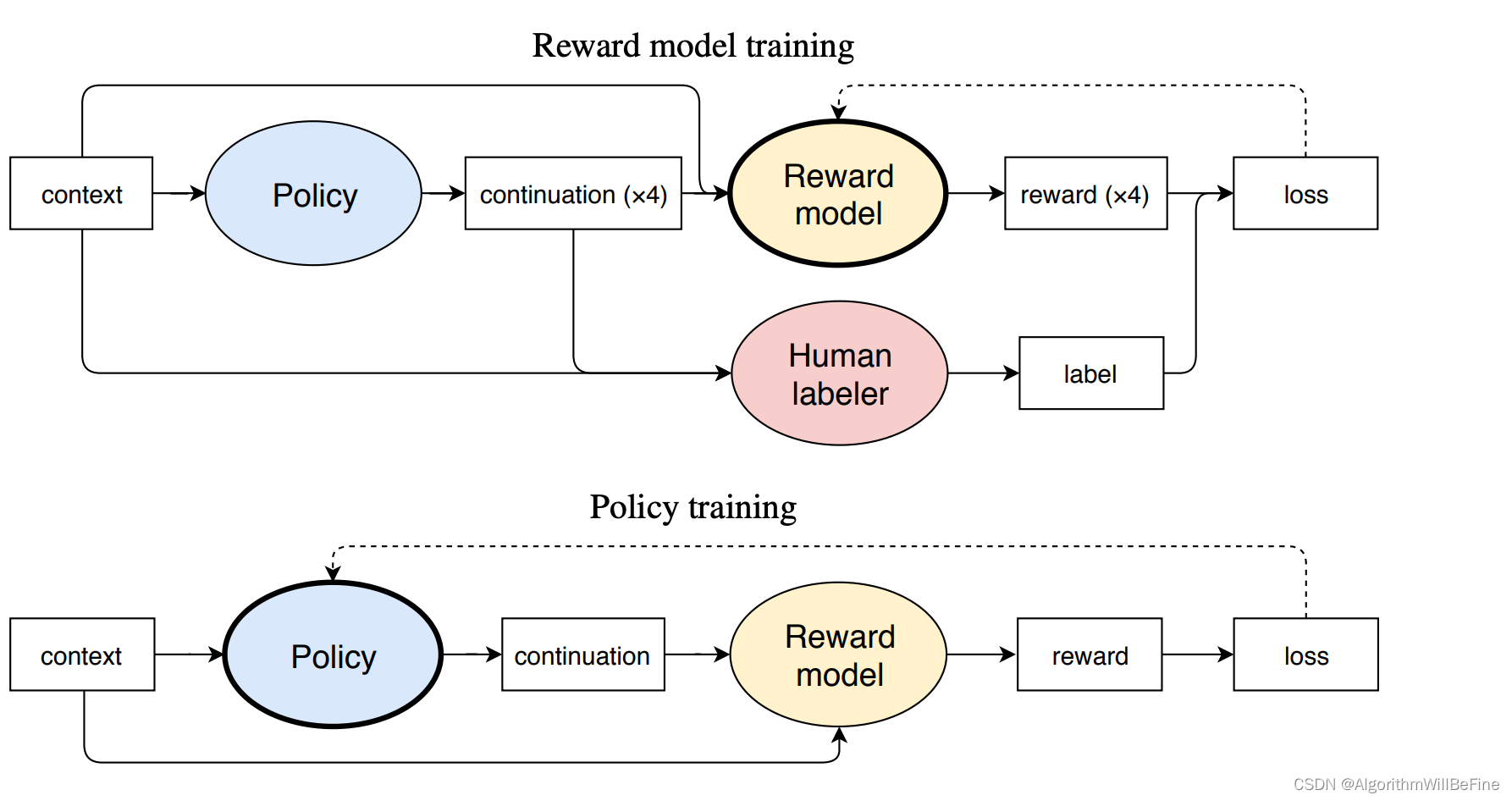
训练的方式是让policy network(GLM)提出几种可能的答案,并混入人工撰写的答案,然后训练reward model了解人类打分的偏好,进而引导Plocy network输出更符合人类偏好的结果,但是可以看得出来,数据制作的成本远高于上述的两个方法,需要涉及人类排序以及人工撰写的过程
总结
以下根据适合的任务,成本对于上述的方法进行总结
| 方法 | 适合任务 | 数据成本 | 训练成本 |
|---|---|---|---|
| Prompt-tuning | 自然语言类型子任务,如:文本分类,语义分析...等 | 中,模版设计和映射对于效果影响巨大 | 低,一个子任务只需要少部分数据 |
| Instruction-tuning | 通用型分发任务,比如:API调度,AutoGPT等 | 低,半自动化生成,参考Alpaca | 低,一个子任务只需要少部分数据 |
| RLHF | 强用户体验相关,比如:人格化,聊天...等 | 高,需要人工打分以及人工撰写 | 高,数据跟训练效果未知 |

