
- 1宝塔给多个网站添加ssl证书报错解决办法
- 2mysql执行错误#1251 (mysql-front连接)解决方案_my1251
- 3基于python大数据的电影可视化分析及电影推荐_基于大数据的电影数据分析
- 4Centos 7安装搜狗输入法_use yum to install sougoupinyin
- 5【chp2】车万翔-自然语言处理:基于预训练模型的方法_自然语言处理基于预训练模型的方法pdf 车万翔
- 6面向隐私安全的车联网群智感知系统架构_用户数据隐私感知系统csdn
- 7浏览器加载图片错误解决方案_image browser: imagereward is not installed, canno
- 8Android 自定义下拉菜单的实现(基于PopupWindow+RecyclerView)_android 下拉菜单
- 9Python异步async/await概念、用法(二)_python async await用法
- 10python_写一个函数,求两个整数之和,要求在函数体内不得使用+、-、*、/四则运算符号。_(+,-,*/)和两个整数python
【TabularData】DNN和表格数据分析建模综述_tabular data
赞
踩
论文名称:Deep Neural Networks and Tabular Data: A Survey
论文下载:https://arxiv.org/abs/2110.01889
论文年份:2021
论文被引:8(2022/04/30)
论文代码:https://github.com/kathrinse/TabSurvey
论文总结

Abstract
Heterogeneous tabular data are the most commonly used form of data and are essential for numerous critical and computationally demanding applications. On homogeneous data sets, deep neural networks have repeatedly shown excellent performance and have therefore been widely adopted. However, their application to modeling tabular data (inference or generation) remains highly challenging. This work provides an overview of state of the art deep learning methods for tabular data. We start by categorizing them into three groups: data transformations, specialized architectures, and regularization models. We then provide a comprehensive overview of the main approaches in each group. A discussion of deep learning approaches for generating tabular data is complemented by strategies for explaining deep models on tabular data. Our primary contribution is to address the main research streams and existing methodologies in this area, while highlighting relevant challenges and open research questions. We also provide an empirical comparison of traditional machine learning methods with deep learning approaches on real tabular data sets of different sizes and with different learning objectives. Our results indicate that algorithms based on gradientboosted tree ensembles still outperform the deep learning models. To the best of our knowledge, this is the first in-depth look at deep learning approaches for tabular data. This work can serve as a valuable starting point and guide for researchers and practitioners interested in deep learning with tabular data.
【研究意义】
异构表格数据(Heterogeneous tabular data)是最常用的数据形式,对于许多关键和计算要求高的应用程序至关重要。
【已有研究的问题】
在同构数据集上,深度神经网络多次表现出优异的性能,因此被广泛采用。然而,它们在表格数据建模(推理或生成)中的应用仍然极具挑战性。
【本文工作】
这项工作概述了用于表格数据的最先进的深度学习方法。我们首先将它们分为三组:
-
数据转换
-
专用架构
-
正则化模型
然后,我们对每组中的主要方法进行全面概述。用于生成表格数据的深度学习方法的讨论由解释表格数据的深度模型的策略补充。我们的主要贡献是解决该领域的主要研究流和现有方法,同时强调相关挑战和开放的研究问题。我们还提供了传统机器学习方法与深度学习方法在不同大小和不同学习目标的真实表格数据集上的经验比较。
【本文结论】
我们的结果表明,基于梯度提升树集成的算法仍然优于深度学习模型。据我们所知,这是第一次深入了解表格数据的深度学习方法。对于对使用表格数据进行深度学习感兴趣的研究人员和从业者来说,这项工作可以作为一个有价值的起点和指南。
I. INTRODUCTION
【DNN的优缺点】
深度神经网络的成功——尤其是那些基于卷积、循环深度学习机制 [1] 或 transformer [2] 的网络——已经通过负担得起的计算和存储资源以及大型标记数据集 [3] 的可用性得到了加速, [4]。尽管深度学习方法在同类数据(例如图像、音频和文本数据)上的分类或数据生成任务中表现出色,但表格数据仍然对这些模型构成挑战 [5]-[7]。
【表格数据的特点】
Kadra et al. 将表格数据集称为深度神经网络模型的最后一个“未征服的城堡”[8]。与图像或语言数据相比,表格数据是异构的 (heterogeneous),导致密集的数字和稀疏的分类特征。此外,特征之间的相关性弱于图像或语音数据中的空间或语义关系。变量可以是相关的,也可以是独立的,特征没有位置信息。因此,有必要在不依赖空间信息的情况下发现和利用相关性[9]。
【表格数据的应用场景】
异构数据是最常用的数据形式 [7],它在许多关键应用中无处不在,例如基于患者病史的医学诊断 [10]-[12]、金融应用的预测分析(例如,风险分析、信用度估计、投资策略推荐和投资组合管理)[13]、点击率 (CTR) 预测 [14]、用户推荐系统 [15]、客户流失预测 [16]、[17]、网络安全 [ 18]、欺诈检测 [19]、身份保护 [20]、心理学 [21]、延迟估计 [22]、异常检测 [23] 等。在所有这些应用程序中,预测性能和稳健性的提升可能对最终用户和提供此类解决方案的公司都有相当大的好处。同时,这需要处理许多与数据相关的陷阱,例如噪声、不精确、不同的属性类型和值范围,或者不可用的值。
同时,与传统机器学习方法相比,深度神经网络具有多种优势。它们非常灵活 [24] 并允许进行有效的迭代训练。深度神经网络对于 AutoML [25]-[30] 尤其有价值。使用深度神经网络可以生成表格数据,例如,可以帮助缓解类不平衡问题 [31]。最后,神经网络可以部署用于多模态学习问题,其中表格数据可以是许多输入模态之一 [27]、[32]-[35],用于表格数据蒸馏 [36]、[37],用于联邦学习 [38] ],以及更多场景。
【用于表格数据中的数据生成问题】
由于数据收集步骤,尤其是异构数据,成本高且耗时,因此有许多合成表格数据生成的方法。然而,对表格数据中行的概率分布进行建模并生成真实的合成数据具有挑战性,因为异构表格数据通常包含离散变量和连续变量的混合。连续变量可能有多种模式,而离散列通常是不平衡的。所有这些缺陷与缺失、噪声或无界值相结合,使得表格数据生成问题变得相当复杂,即使对于现代深度生成架构也是如此。我们在第 V 节讨论了表格数据生成的最新方法。
【用于表格数据的神经网络的可解释性】
另一个重要方面是对表格数据的深度神经网络的解释 [39]。许多用于解释深度神经网络的流行方法源于计算机视觉领域,其中一个像素组被突出显示,创建了一个所谓的显著图(saliency map)。然而,对于表格数据集,突出显示变量关系也是必不可少的。
许多现有的方法——尤其是那些基于注意力机制的方法[2]——通过设计提供了对关系的突出显示,并且它们的注意力图可以很容易地可视化。
【本文的目的】
本次调查的目的是提供
- 1)对现有关于表格数据深度学习的科学文献的全面回顾
- 2)对异构表格数据的分类和回归任务的可用方法进行分类分类
- 3)对现有技术的介绍以及对有前景的表格数据生成的展望
- 4)表格数据深度模型的现有解释方法概述
- 5)传统机器学习方法和深度学习模型在多个现实世界异构表格数据集上的广泛经验比较
- 6)主要讨论深度学习在表格数据上取得有限成功的原因
- 7)与表格数据深度学习相关的开放挑战列表
因此,数据科学从业者和研究人员将能够为手头的用例或研究问题快速确定有希望的起点和指导。
调查的其余部分安排如下:
第 II 节讨论了相关工作。
第 III 节提供了使用的形式,简要概述了该领域的历史,列出了通常遇到的主要挑战,并提出了使用表格数据进行深度学习的可能方法的统一分类。
第 IV 节详细介绍了使用深度神经网络对表格数据进行建模的主要方法。
第 V 节概述了使用深度神经网络生成表格数据。
第 VI 节概述了表格数据的深度模型的解释机制。
在第 VIII 节中,我们总结了该领域的现状并给出了未来的展望。
在第 IX 节结束之前,我们列出了开放的研究问题。
为了帮助改进调查,请随时向通讯作者发送更正和建议。
II. RELATED WORK
据我们所知,没有专门研究将深度神经网络应用于表格数据,涵盖监督学习,无监督学习和数据合成领域。之前的工作涵盖了其中一些方面,但没有一个系统地讨论本调查广泛的现有方法。我们也找不到任何回顾使用深度神经网络合成表格数据的最先进方法的工作。
但是,有些作品涵盖了该领域的部分内容。 [40] 的作者对分类数据编码作为深度神经网络的预处理步骤的常用方法进行了全面分析。该调查的作者比较了对各种表格数据集和不同深度学习架构进行分类数据编码的现有方法。我们还在第 IV -A1 节中讨论了关键的分类数据编码方法。
[41] 的作者根据经验评估了大量最先进的深度学习方法,用于广泛数据集上的表格数据。有趣的是,作者证明了具有类似 ResNet 架构的调整深度神经网络模型 [42] 显示出与一些最先进的表格数据深度学习方法相当的性能。
最近,[7] 的作者发表了一项关于表格数据的几种不同深度模型的研究,包括 TabNet [5]、NODE [6]、Net-DNF [43]。此外,他们将深度学习方法与梯度提升决策树算法的准确性、训练工作量、推理效率以及超参数优化时间进行了比较。他们观察到,深度模型在其原始论文中使用的数据集上具有最佳结果,但是,总体而言,没有任何深度模型可以超越其他模型。他们受到梯度提升决策树的挑战,这就是为什么作者得出结论,使用深度神经网络进行有效的表格数据建模仍然是一个悬而未决的问题。通过我们的调查,我们旨在为未来在这个问题上的工作提供必要的背景。
[44] 的作者进行的一项定量研究分析了神经网络的鲁棒性,同时考虑了不同的最先进的正则化技术。为了欺骗预测模型,表格数据可能会被破坏,并且可能会产生对抗性示例。如 [19] 的作者所示,使用这些数据,可能会误导欺诈检测模型以及人类。在关键环境中对表格数据使用深度学习模型之前,应该意识到可能容易受到攻击。
最后,[45] 的作者最近的一项调查总结了表格数据背景下的可解释技术。因此,我们不会在本文中详细讨论可解释的表格数据机器学习。然而,为了完整起见,我们在第六节中强调了一些最相关的工作。
III. TABULAR DATA AND DEEP NEURAL NETWORKS
A. Definitions
在本节中,我们给出了这项工作中使用的中心术语的定义。我们还为更详细的方法解释提供参考。
本次调查中的一个重要概念是(深度)神经网络之一。在这项工作的大多数段落中,我们使用这个概念作为前馈网络的同义词,如 [4] 所述,并在我们偏离这个概念时命名具体模型。
一个深度神经网络定义了一个映射
f
^
\hat{f}
f^
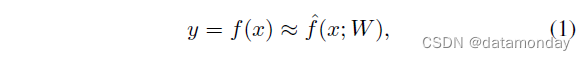
它学习实现
f
f
f 的最佳近似的参数
W
W
W 的值(神经网络的“权重”)。如果输入信息在没有任何反馈连接的情况下沿一个方向流向输出,则该网络称为前馈。
本调查重点关注异构数据,通过包含各种属性类型,例如来自不同分布的连续或离散数值属性(例如二进制值,序数值,高基数分类值)。根据 Lane 的定义[46],分类变量是定性值。它们“并不意味着数字排序”,这与“以数字衡量”的定量值不同。此外,分类变量可以采用一组有限的唯一值。表格数据集中的分类变量示例包括性别、用户 ID、产品类型、主题。
表格数据(有时是文献中的结构化数据)是异构数据格式的一个子类别,通常以表格 [47] 的形式呈现,其中数据点为行,特征为列。因此,在这项工作的范围内,我们还将一个表格数据集定义为一个包含 n 个数值列 { N 1 , . . . , N n } \{N_1, . . . , N_n\} {N1,...,Nn} 和 c c c 分类列 { C 1 , . . . , C c } \{C_1, . . . ,C_c\} {C1,...,Cc}。所有列都是遵循联合分布 P ( N 1 : n , C 1 : c ) P(N_{1:n}, C_{1:c}) P(N1:n,C1:c) 的随机变量。每个数据点都可以理解为表格中的一行,或者——从概率的角度来看——作为来自未知联合分布的样本。在处理表格数据时,我们对其特征之间的结构和关系的先验知识有限。表格数据广泛用于实际机器学习和数据科学。
B. Brief History of Deep Learning on Tabular Data
表格数据是最古老的数据形式。在文本、图像和声音的数字化收集成为可能之前,几乎所有数据都是表格的。因此,它是早期机器学习研究的目标。然而,深度神经网络在数字时代开始流行,并进一步发展,重点关注同质数据(homogeneous data)。近年来,已经提出了各种监督、自监督和半监督的深度学习方法,这些方法再次明确地解决了表格数据建模的问题。早期的工作主要集中在用于预处理的数据转换技术[48]-[50],这在今天仍然很重要[40]。
一个巨大的刺激是电子商务的兴起,这需要新颖的解决方案,尤其是在广告方面[14],[51]。这些任务需要对具有许多分类变量的异构数据集进行快速准确的估计,而传统的机器学习方法并不十分适合(例如,具有高基数的分类特征会导致非常稀疏的高维特征向量和非鲁棒模型)。因此,研究人员和数据科学家开始寻找更灵活的解决方案,例如,基于深度神经网络,能够捕获数据中复杂的非线性依赖关系。
特别是点击率预测问题受到了很多关注[14]、[52]、[53]。提出了各种各样的方法,其中大多数依赖于用于异构表格数据的专用神经网络架构。我们的调查中包含了估算点击率的最重要方法。
基于正则化可以提高深度神经网络在表格数据上的性能 [8] 的想法,一种新的研究方向发展起来。这个想法是由 [54] 的作者提出的,导致对正则化方法的研究得到加强。
由于基于注意力的方法(如文本 [55] 和视觉数据 [56]、[57] 的Transformer)的巨大成功,研究人员最近开始将基于注意力的方法和自监督学习技术应用于表格数据。在 [5] 的作者的第一个也是最有影响力的工作引起了研究兴趣之后,transformer 正在迅速普及,尤其是对于大型表格数据集。
C. Challenges of Learning With Tabular Data
如上所述,在处理表格数据时,深度神经网络通常不如更传统的(例如线性或基于树的)机器学习方法。但是,通常不清楚为什么深度学习无法达到与图像分类和自然语言处理等其他领域相同水平的预测质量。在下文中,我们确定并讨论了四个可能的原因:
- 1)不适当的训练数据:数据质量是现实世界表格数据集的常见问题。它们通常包括缺失值 [58]、极端数据(异常值)[23]、错误或不一致的数据 [59],并且相对于从数据生成的高维特征向量而言总体尺寸较小 [60]。此外,由于数据收集的昂贵性质,表格数据经常是类别不平衡的。
- 2)缺失或复杂的不规则空间依赖关系:表格数据集中的变量之间通常没有空间相关性[61],或者特征之间的依赖关系相当复杂和不规则。因此,用于同类数据的流行模型中使用的归纳偏差(inductive biases),例如卷积神经网络,不适合对这种数据类型进行建模 [43]、[62]、[63]。
- 3)广泛的预处理:处理表格数据时的主要挑战之一是如何处理分类特征[40]。在大多数情况下,第一步是将类别转换为数字表示,例如,使用简单的 one-hot 或 ordinal 编码方案。然而,由于分类特征可能非常稀疏(称为维度灾难的问题),这可能导致非常稀疏的特征矩阵(使用 one-hot 编码方案)或无序值的合成对齐(使用序数编码方案)。 [40] 的作者分析了分类变量的不同嵌入技术。处理分类特征也是我们在第四节讨论的主要方面之一。使用同质数据的应用程序有效地使用了数据增强[64]、迁移学习[65]和测试时间增强[66]。对于异构表格数据,这些技术通常难以应用。然而,一些用于学习表格数据的框架,如 VIME [67] 和 SAINT [9],在嵌入空间中使用数据增强策略。最后,请注意,在对深度神经网络应用预处理方法时,我们经常会丢失与原始数据相关的信息,从而导致预测性能下降 [68]。
- 4)模型敏感性:深度神经网络对于输入数据的微小扰动可能非常脆弱 [69]、[70]。分类(或二元)特征的最小可能变化可能已经对预测产生很大影响。对于同构(连续)数据集,这通常问题不大。与深度神经网络相比,决策树算法可以通过选择特征和阈值并“忽略”数据样本的其余部分来出色地处理扰动。由于它们的极端敏感性,人工神经网络模型具有高曲率决策边界 [71]、[72],而基于决策树的算法可以学习类似超平面的边界。为了降低深度神经网络与输入相关的敏感性,一些方法提出将强正则化应用于学习参数[8]、[54]。我们将在第 IV -C 节中更详细地讨论这些方法。
最后,深度神经网络通常具有过多的超参数 [4],而传统的表格数据机器学习方法(例如,基于决策树的模型、支持向量机 [73])的超参数通常要少得多。因此,深度学习模型的调整时间远高于基于决策树的方法。此外,神经网络往往对超参数的选择很敏感(例如学习率、隐藏层数或激活函数)。一般来说,为了降低非鲁棒预测的风险,最好使用较少的超参数。
D. Unified Taxonomy
在本节中,我们介绍了一种方法分类法,它对该领域的有一个统一的视角。在准备这项调查时遇到的工作分为三大类:数据转换方法、专业架构和正则化模型。表格数据方法的深度学习统一分类如图 1 所示。
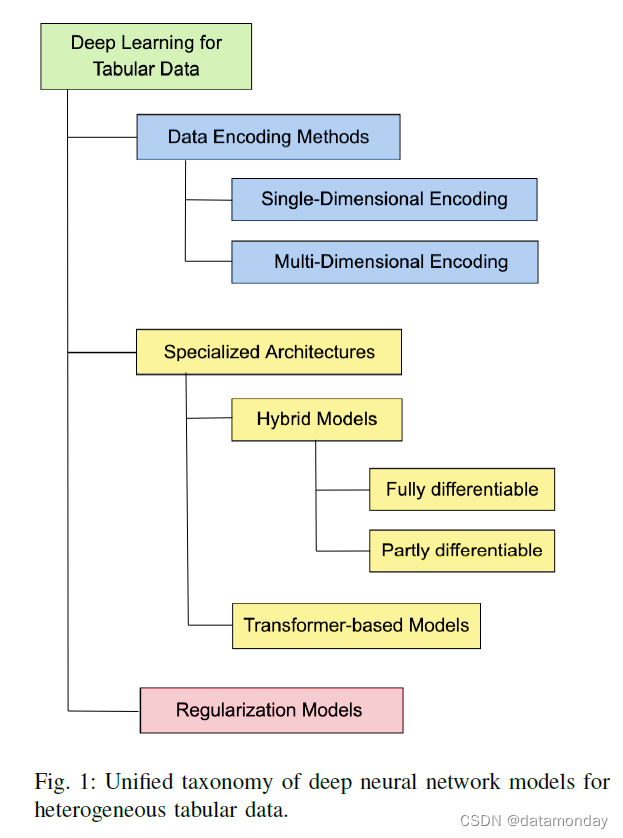
最大份额的工作调查了专门的架构,并表明表格数据需要不同的深度神经网络架构。两种类型的架构特别重要:混合模型将经典机器学习方法(例如决策树)与神经网络融合在一起,而基于 Transformer 的模型则依赖于注意力机制。
最后,正则化模型组声称,深度学习模型在表格上表现中等的主要原因之一是它们的极端非线性和模型复杂性。因此,提出了强正则化方案作为解决方案。它们主要以专用损失函数的形式实现。
我们相信我们的分类法可以帮助从业者找到选择的方法,这些方法可以很容易地集成到他们现有的工具链中。例如,数据转换可以在保持当前模型架构的同时提高性能。使用专门的架构,数据预处理管道可以保持完整。
IV. DEEP NEURAL NETWORKS FOR TABULAR DATA
在本节中,我们将根据上一节中介绍的分类,讨论在表格数据上使用深度神经网络进行分类或回归任务。
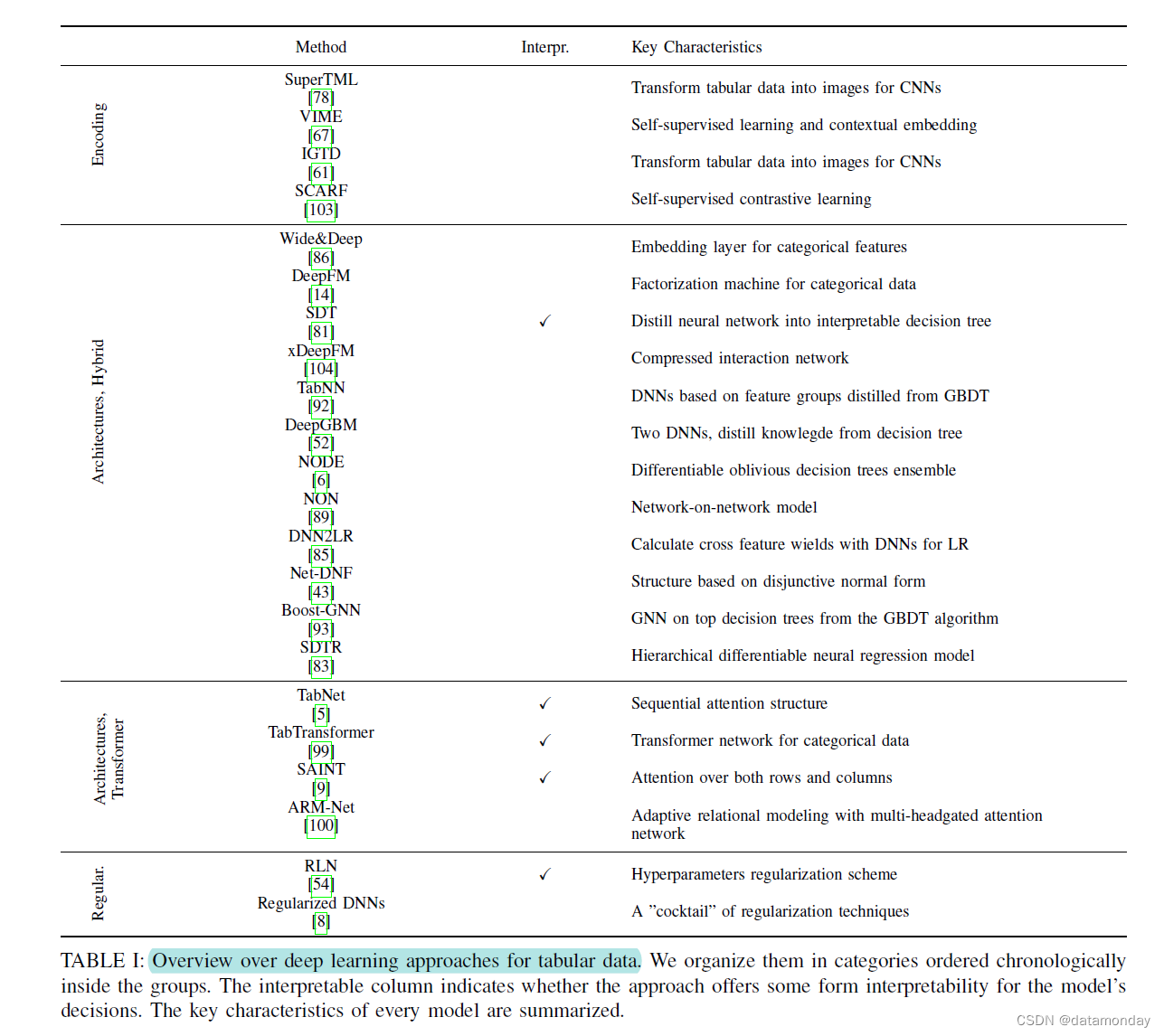
我们在表 I 中概述了该研究领域中现有的深度学习方法,并详细讨论了三个方法类别:数据转换方法(第 IV -A 小节)、基于架构的方法(第 IV -B1 小节)和正则化 -基于模型(第 IV -C 小节)。
A. Data Transformation Methods
用于表格数据的深度神经网络的大多数传统方法都属于这一组。有趣的是,数据预处理在计算机视觉中的作用相对较小,尽管该领域目前由深度学习解决方案主导。 [4]。转换表格数据有许多不同的可能性,每一种都可能对学习结果产生影响[40]。
1)单维编码:使用表格数据进行深度学习的关键障碍之一是分类变量。由于神经网络只接受实数向量作为输入,因此必须先转换这些值,然后模型才能使用它们。因此,该组的方法尝试以适合深度学习模型的方式对分类变量进行编码。
正如 [40] 在他们的调查中所说,该方法分为确定性技术,可以在训练模型之前使用,以及更复杂的自动技术,这些技术是模型架构的一部分。确定性数据编码有很多方法,因此我们将自己限制在最常见的方法上,而不要求完整性。
最简单的数据编码技术可能是序数或标签编码。每个类别都只是映射到一个离散的数值,例如,{‘‘Apple’’, ‘‘Banana’’} 被编码为 {0, 1}。不幸的是,这种方法向以前无序的类别引入了人为的顺序。另一种不包含任何顺序的直接方法是 one-hot 编码。每个唯一类别的一列将添加到数据中。只有与观察到的类别对应的列被赋值为 1,其他值为零。在我们的示例中,“Apple”可以编码为 (1,0),“Banana”可以编码为 (0,1)。由于数据中有多种类别,这种方法当然会导致高维稀疏特征向量(“维度灾难”问题)。
二进制编码通过将定性数据转换为数字表示(如标签编码所做的那样)并使用数字的二进制格式来限制新列的数量。同样,数字被分成不同的列,但如果 c 是唯一分类值的数量,则只有 log© 新列。如果我们将示例扩展到三个水果,例如 {‘‘Apple’’, ‘‘Banana’’, ‘‘Pear’’},我们只需要两列来表示它们:(01), (10), (11)。
一种不需要额外列且不包含任何人工顺序的方法是所谓的留一法编码(leave-one-out encoding)。它基于 [75] 在工作中提出的目标编码技术,其中每个类别都替换为该类别的目标变量的平均值。留一法编码在计算目标变量的均值时会排除当前行以避免过拟合。这种方法非常通用,也用于 CatBoost 框架 [76],这是一个基于梯度提升算法 [77] 的用于异构表格数据的最先进的机器学习库。
一种不同的策略是基于哈希的编码。每个类别都通过确定性哈希函数转换为固定大小的值。输出大小不直接取决于输入类别的数量,而是可以手动选择。
2)多维编码:VIME方法[67]使用了一种自动编码的方法。作者提出了一种用于表格数据的自监督和半监督深度学习框架,该框架通过使用两个代理任务(pretext tasks 或者 surrogate task,也称为前置任务)以自监督方式训练编码器。这两个代理任务是独立于预测器而必须解决的具体下游任务的任务。VIME 的第一个任务称为掩码向量估计;它的目标是确定样本中的哪些值已损坏。第二个任务,即特征向量估计,是恢复样本的原始值。编码器本身是一个简单的多层感知器。这种自动编码利用了未标记数据通常比标记数据多得多的事实。编码器学习如何构建原始输入数据的信息同质表示。在半监督步骤中,使用编码器转换的标记和未标记数据训练预测模型(也是深度神经网络模型)。对于后者,使用了一种新的数据增强方法,使用不同的掩码多次破坏一个(未标记的)数据点。根据来自一个原始数据点的所有增强样本的预测,可以计算出奖励相似输出的一致性损失 Lu。结合来自标记数据的监督损失 Ls,预测模型最小化最终损失 L = Ls + β · Lu。总而言之,VIME 网络训练了一个编码器,该编码器负责将分类(以及数字)特征转换为新的同质且信息丰富的表示。这个变换的特征向量被用作预测模型的输入。对于编码器本身,可以通过简单的 one-hot 编码和二进制编码来转换分类数据。
另一个研究流旨在将表格输入转换为更同质的格式。自深度学习复兴以来,卷积神经网络在计算机视觉任务中取得了巨大成功。因此,[78] 的工作提出了 SuperTML 方法,这是一种将表格数据转换为可视数据格式(二维矩阵)的数据转换技术,即等效于黑白图像。
[61] 的表格数据图像生成器(IGTD)遵循类似于 SuperTML 的想法。 IGTD 框架将表格数据转换为图像,以利用经典的卷积架构。由于卷积神经网络依赖于空间依赖性,因此通过最小化表格数据的特征距离排序与生成图像的像素距离排序之间的差异来优化图像转换。每个特征对应一个像素,这导致具有相似特征的紧凑图像靠近相邻像素。因此,IGDT 可以在没有领域知识的情况下使用。作者对具有强特征关系的数据显示了相对可靠的结果,但如果特征独立或特征相似性不能表征关系,则该方法可能会失败。在他们的实验中,作者只使用了药物的基因表达谱和分子描述符作为数据。这种数据可能会导致有利的归纳偏差,因此该方法的总体可行性仍不清楚。
归纳偏差:是一个关于机器学习算法的目标函数的假设。这个指的就是目标函数评分的标准。参考:link
B. Specialized Architectures
专门的架构构成了深度表格数据学习的最大方法组。因此,在这个小组中,重点是开发和研究专门为异构表格数据设计的新型深度神经网络架构。根据可用模型的类型,我们将此组分为两个子组:混合模型(在 IV -B1 中介绍)和基于 Transformer 的模型(在 IV -B2 中讨论)。
1)混合模型:大多数用于表格数据的深度神经网络方法都是混合模型。他们转换数据并将成功的经典机器学习方法(通常是决策树)与神经网络融合在一起。我们区分完全可微模型,可以根据其所有参数和部分可微模型进行区分。
Fully differentiable Models
此类别中的完全可微模型提供了一个有价值的属性:它们允许通过梯度下降优化器进行端到端深度学习以进行训练和推理。因此,它们允许在整个代码中利用 GPU 或 TPU 加速的现代深度学习框架中进行高效实现。
[6] 的作者提出了一组可微的遗忘决策树 [79]——用于表格数据深度学习的 NODE 框架。不经意的决策树(Oblivious decision trees)对同一级别的所有节点使用相同的拆分函数,因此可以轻松并行化。 NODE 概括了成功的 CatBoost [76] 框架。为了使整个架构完全可区分并从端到端优化中受益,NODE 利用了 entmax 变换 [80] 和软拆分。在他们的实验中,NODE 框架在许多数据集上的表现优于 XGBoost 和其他 GBDT 模型。由于 NODE 基于决策树集成,因此无需对分类数据进行预处理或转换。众所周知,决策树可以很好地处理离散特征。在官方实现中,字符串使用留一法编码方案转换为整数。 NODE 框架被广泛使用,并提供了可以轻松部署的良好实现。
[81] 的作者贡献了另一个依赖软决策树 (SDT) 的模型,以使神经网络更具可解释性。他们首先研究了训练深度神经网络,然后在第二步中使用其输出和真实标签的混合来训练 SDT 模型。这也允许使用由深度神经网络标记的未标记样本进行半监督学习,并用于训练更稳健的决策树以及标记数据。作者表明,训练神经模型首先会提高直接从数据中学习的 SDT 的准确性。然而,他们的蒸馏树仍然表现出与初始步骤中拟合的神经网络的性能差距。然而,模型本身以分层方式显示了不同类之间的清晰关系。它根据常见模式对不同的分类值进行分组,例如 MNIST 数据集 [82] 中的数字 8 和 9。总而言之,所提出的方法允许高可解释性和高效推理,但代价是略微降低了准确性。
后续工作 [83] 将这一研究领域扩展到异构表格数据和回归任务,并提出了软决策树回归器 (SDTR) 框架。 SDTR 是一个试图模仿二元决策的神经网络。因此,所有神经元,就像树中的所有节点一样,从数据中获得相同的输入,而不是从前一层获得输出。在深度网络的情况下,SDTR 无法击败其他最先进的模型,但在比较单树模型和浅层架构的低内存设置中显示出良好的结果。
[43] 提出了一个有趣的想法。他们的 Net-DNF 考虑到每个决策树只是布尔公式的一种形式,更准确地说是一种析取范式(disjunctive normal form)。他们使用这种归纳偏差来设计神经网络的架构,该架构能够模仿梯度提升决策树算法的特性。生成的 Net-DNF 在没有缺失值的数据集上进行了分类任务测试,结果与 XGBoost [84] 的结果相当。然而,没有提到如何处理高基数的分类数据,因为使用的数据集主要包含数字特征和少量二元特征。
线性模型(例如,线性和逻辑回归)提供全局可解释性,但不如复杂的深度神经网络。通常,需要手工特征工程来提高线性模型的准确性。 [85] 使用深度神经网络以可能的非线性方式组合特征;然后得到的组合用作线性模型的输入。这增强了简单模型,同时仍提供可解释性。
[86] 的作者的工作提出了一种混合架构,由线性和深度神经网络模型 Wide&Deep 组成。通过深度神经网络增强了将单个特征和多种手工逻辑表达式作为输入的线性模型,以提高泛化能力。此外,Wide&Deep 为每个分类特征学习一个 n 维嵌入向量。所有嵌入都被连接起来,从而产生一个密集向量,用作神经网络的输入。最终的预测可以理解为两个模型的总和。 [87] 的作者的一项类似工作提出了使用深度神经网络对分类变量进行嵌入。
对 Wide&Deep 模型领域的另一个贡献是 [14] 的作者 DeepFM。作者证明,可以用学习的因子分解机(FM)[88]代替手工制作的特征转换,从而提高整体性能。 FM 是线性模型的扩展,旨在有效地捕获高维和稀疏数据中特征之间的交互。与原始的 Wide&Deep 模型类似,DeepFM 的“宽”和“深”部分也依赖相同的嵌入向量。然而,与原始的 Wide&Deep 模型相比,DeepFM 减轻了对手动特征工程的需求。
最后,Network-on-Network (NON) [89] 是一种表格数据的分类模型,专注于有效地捕获特征内信息。它由三个组件组成:一个由一个独特的深度神经网络组成的字段网络,用于每列捕获特定于列的信息,一个跨字段网络,它根据数据集选择最佳操作,以及一个操作融合网络,连接所选择的操作,允许非线性。由于选择了针对特定数据的最佳操作,因此性能明显优于其他深度学习模型。然而,作者并没有在他们的基线中包括决策树,这是当前最先进的表格数据模型。此外,训练与列一样多的神经网络并动态选择操作可能会导致计算时间过长。
Partly differentiable Models
这个混合模型子组旨在将不可微方法与深度神经网络相结合。通常,该组中的模型将决策树用于不可微部分。
DeepGBM 模型 [52] 将深度神经网络的灵活性与梯度提升决策树的预处理能力相结合。 DeepGBM 由两个神经网络——CatNN 和 GBDT2NN 组成。CatNN 专门用于处理稀疏的分类特征,而 GBDT2NN 专门用于处理密集的数字特征。
在 CatNN 网络的预处理步骤中,分类数据通过序数编码(将潜在字符串转换为整数)进行转换,并且数字特征被离散化,因为该网络专门用于分类数据。 GBDT2NN 网络通过访问决策树的叶索引,从基于梯度提升决策树的模型中提取有关基础数据集的知识。这种基于决策树叶的嵌入首先由[90]提出,用于随机森林算法。后来,梯度提升决策树采用了相同的知识蒸馏策略[91]。
使用提出的两个深度神经网络的组合,DeepGBM 对分类和数值特征都有很强的学习能力。该网络的独特之处在于作者明确实施并测试了在线预测性能,其中 DeepGBM 显着优于梯度提升决策树。不利的一面是,叶子索引可以看作是元分类特征,因为我们不能直接比较这些数字。此外,尚不清楚其他与数据相关的问题,例如缺失值、数值特征的不同比例和噪声,如何影响模型产生的预测。
[92] 引入的 TabNN 架构基于两个原则:明确利用表达性特征组合和降低模型复杂性。它从梯度提升决策树中提取知识以检索特征组,对它们进行聚类,然后基于这些特征组合构建神经网络。来自树的结构知识也被转移以提供有效的初始化。然而,网络的构建已经采取了不同的广泛计算步骤(其中一个只是避免 NP-hard 问题的启发式方法)。此外,鉴于构建方面的挑战,并且由于没有提供 TabNN 的实现,该网络的实际使用似乎有限。
与 DeepGBM 和 TabNN 类似,[93] 中的工作建议在数据预处理步骤中使用梯度提升决策树。作者表明,决策树结构具有有向图的形式。因此,所提出的框架利用图神经网络[94]利用决策树的拓扑信息。由此产生的架构被称为增强图神经网络(BGNN)。在多个实验中,BGNN 证明所提出的架构在预测性能和训练时间方面优于现有的可靠竞争对手。
2)基于 Transformer 的模型:基于 Transformer 的方法形成了另一个用于表格数据的基于模型的深度神经方法的子组。受最近对基于 Transformer 的方法的爆炸式兴趣及其在文本和视觉数据上的成功 [57]、[95] 的启发,研究人员和从业者提出了多种方法,将深度注意力机制 [2] 用于异构表格数据。
TabNet [5] 是最早的基于Transformer的表格数据模型之一。与决策树类似,TabNet 架构包含多个以顺序分层方式处理的子网络。根据[5],每个子网络对应一个特定的决策步骤。为了训练 TabNet,每个决策步骤(子网络)都接收当前数据批次作为输入。 TabNet 聚合所有决策步骤的输出以获得最终预测。在每个决策步骤,TabNet 首先应用稀疏特征掩码 [96] 来执行软实例特征选择。 [5] 声称特征选择可以节省宝贵的资源,因为网络可能专注于最重要的特征。决策步骤的特征掩码使用来自前一个决策步骤的注意力信息进行训练。为此,特征Transformer模块决定哪些特征应该传递到下一个决策步骤,哪些特征应该用于在当前决策步骤获得输出。特征Transformer的某些层在所有决策步骤中共享。得到的特征掩码对应于局部特征权重,也可以组合成全局重要性分数。因此,TabNet 是为数不多的通过设计提供不同级别可解释性的深度神经网络之一。事实上,实验表明 TabNet 的每个决策步骤都倾向于关注学习问题的特定子域(即,一个特定的特征子集)。这种行为类似于卷积神经网络。 TabNet 还提供了一个解码器模块,该模块能够以无监督的方式预处理输入数据(例如,替换缺失值)。因此,TabNet 可用于两阶段自监督学习过程,从而提高整体预测质量。最近,TabNet 也在公平机器学习的背景下进行了研究 [97]、[98]。
[99] 介绍了一种监督和半监督方法。他们的 TabTransformer 架构使用基于自注意的Transformer将分类特征映射到上下文嵌入中。这种嵌入对丢失或嘈杂的数据更加稳健,并具有可解释性。然后将嵌入的分类特征与数字特征一起输入一个简单的多层感知器。此外,如果有额外数量的未标记数据,无监督预训练可以改善结果,使用掩码语言建模或替换标记检测。大量实验表明 TabTransformer 与基于树的集成技术的性能相匹配,在处理丢失或嘈杂的数据时也显示出成功。 TabTransformer 网络将重点放在分类特征上。它将这些特征的嵌入转换为上下文嵌入,然后用作多层感知器的输入。这种嵌入是由不同的基于多头注意力的Transformer实现的,这些Transformer在训练期间进行了优化。
由 [100] 引入的 ARM-net 是一种自适应神经网络,用于为表格数据量身定制的关系建模。 ARM-net 框架的关键思想是通过首先将输入特征转换为指数空间,然后自适应地确定每个特征交叉的交互顺序和交互权重,选择性地和动态地对具有组合特征(特征交叉)的特征交互进行建模。此外,作者提出了一种新颖的稀疏注意力机制,可以在给定输入数据的情况下动态生成交互权重。因此,用户可以显式地对任意阶的特征交叉进行建模,并选择性地过滤噪声特征。
SAINT(Self-Attention and Intersample Attention Transformer)[9] 是一种混合注意方法,将 self-attention [2] 与多行的样本间注意相结合。在处理缺失或噪声数据时,该机制允许模型从相似样本中借用相应信息,从而提高模型的鲁棒性。该技术让人想起最近邻分类。此外,所有特征都嵌入到一个组合的密集潜在向量中,从而增强了来自一个数据点的值之间的现有相关性。为了利用未标记数据的存在,自监督的对比预训练可以进一步改善结果,最小化同一样本的两个视图之间的距离并最大化不同视图之间的距离。与 VIME 框架(第 IV -A1 节)类似,SAINT 使用 CutMix [101] 来增加输入空间中的样本,并在嵌入空间中使用 mixup [102]。基于注意力的架构提供了可解释性机制,这是优于许多混合模型的重要优势。图 2 显示了 MNIST [82] 和 volkert [29] 数据集上的注意力图,可以使用不同的注意力机制找到它们。

C. Regularization Models
第三组方法认为,表格数据的深度学习模型的极端灵活性是主要的学习障碍之一,学习参数的强正则化可能会提高整体性能。此类中的第一个方法是 [54] 的作者提出的正则化学习网络 (RLN),它使用可学习的正则化方案。主要思想是将可训练的正则化系数
λ
i
λ_i
λi 应用于神经网络中的每个权重
w
i
w_i
wi,从而降低高灵敏度:

为了有效地确定相应的系数,作者提出了一种新的损失函数,称为“反事实损失 (Counterfactual Loss)”,LC (Z, W, λ)。正则化系数导致网络非常稀疏,这也提供了剩余输入特征的重要性。
在他们的实验中,RLN 的性能优于深度神经网络,并获得了与梯度提升决策树算法相当的结果,但他们只使用了一个主要是数值数据的数据集来比较模型。 RLN 论文没有解决分类数据的问题。对于实验和示例实现数据集,仅使用数字数据(性别属性除外)。 [105] 中提出了类似的想法,其中正则化系数仅在第一层中学习,目的是提取特征重要性。
[8] 指出,如果深度学习网络得到适当的正则化,简单的多层感知器可以在表格数据上优于最先进的算法。这项工作的作者提出了一种正则化的“cocktail”,它使用了 13 种不同的技术,这些技术共同应用。从这些中,选择最佳子集及其附属超参数。他们在广泛的实验中证明,“cocktail”正则化不仅可以提高多层感知器的性能,而且这些简单的模型也优于基于树的架构。不利的一面是,与梯度提升决策树算法相比,广泛的每个数据集正则化和超参数优化需要更多的计算时间。
还有其他几项工作 [106]-[108] 表明深度神经网络的强正则化有利于表格数据。
V. TABULAR DATA GENERATION
对于许多应用程序,生成真实的表格数据是基础。其中包括使用数据插补(填充缺失值)[111]、[112] 和重新平衡 [113]-[116] 的数据增强 [110]。另一个高度相关的主题是隐私感知机器学习 [117]-[119],其中生成的数据可用于克服隐私问题。
A. Methods
虽然图像和文本的生成得到了高度探索 [120]-[122],但生成合成表格数据仍然是一个挑战。必须管理离散和连续特征的混合结构及其不同的值分布。
数据生成任务的经典方法包括 Copulas [123]、[124] 和贝叶斯网络 [125],对于后者而言,基于 [126] 的作者提出的近似值的方法特别受欢迎。在深度学习时代,生成对抗网络 (GAN) [127] 已被证明在图像生成方面非常成功 [120]、[128]。
GANs 最近被引入作为训练生成深度神经网络模型的原始方法。它们由两个独立的模型组成:一个从数据分布生成样本的生成器 G,以及一个估计样本来自真实分布的概率的鉴别器 D。 G 和 D 通常都选择为非线性映射函数,例如多层感知器。为了在数据 x 上学习生成器分布 pg,生成器 G(z; θg) 将样本从噪声分布 pz(z)(通常是高斯分布)映射到输入数据空间。判别器 D(x; θd) 输出数据点 x 来自训练数据分布 pdata 而不是来自生成器输出分布 pg 的概率。来自真实数据和生成器的样本都被馈送到鉴别器。
G 和 D 一起训练:调整 G 的参数以最小化 log(1 - D(G(z)) ,并调整 D 的参数以最小化 log D(x),就好像它们遵循具有价值函数 V (G, D) 的两人 最小-最大 游戏:
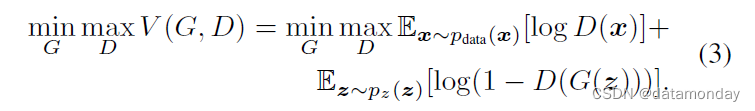
有关 GAN 的更多详细信息,我们将感兴趣的读者推荐给原始论文 [127]。
尽管注意到 GAN 在生成离散输出(如自然语言 [122])方面落后,它们经常被选择用于表格数据生成任务。普通 GAN 或衍生品,例如 Wasserstein GAN (WGAN) [129]、具有梯度惩罚的 WGAN (WGANP) [130]、Cramer GAN [131] 或专门使用离散数据设计的边界搜索 GAN [132]记在文献中很常见。此外,VeeGAN [133] 经常用于表格数据。除了 GAN,还研究了自动编码器——尤其是 [134] 的作者提出的变分自动编码器 (VAE)——[135]、[136]。
我们在表 II 中提供了使用深度学习技术的表格生成方法的概述。请注意,由于方法数量众多,我们只列出了解决数据生成问题的最有影响力的作品,尤其是关注表格数据。此外,我们排除了针对高度特定领域任务的作品。在 [113] 中还可以找到对现有方法的广泛综述。
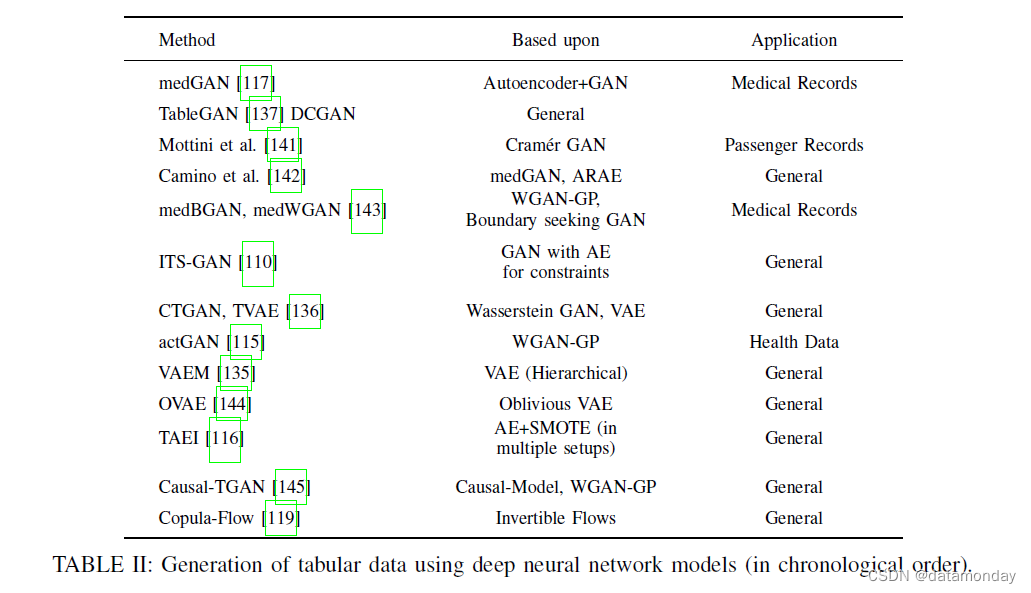
在下一节中,我们将简要讨论有助于塑造领域的最相关的方法。 [117] 的 MedGAN 是最早的作品之一,它提供了一个深度学习模型来生成患者记录。由于所有的特征都是离散的,这个模型不能轻易地转换为一般的表格数据。 [137] 的 table-GAN 方法将深度卷积 GAN 用于表格数据。具体来说,将一条记录的特征转换为矩阵,以便它们可以通过卷积神经网络的卷积滤波器进行处理。然而,尚不清楚用于图像的归纳偏差在多大程度上适用于表格数据。
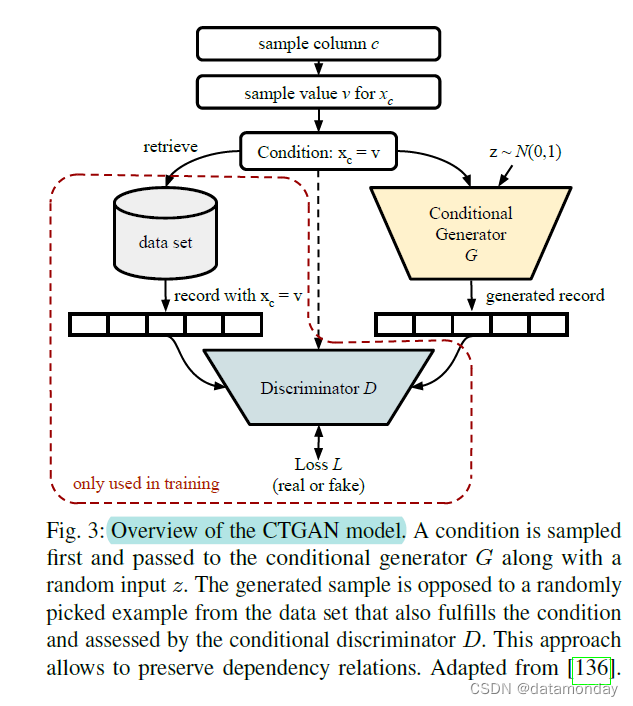
[136] 的作者提出的一种整体方法侧重于一个数据点的特征之间的相关性。作者首先提出了用于数据预处理的特定于模式的归一化技术,该技术允许在连续列中转换非高斯分布。它们根据混合成分编号和与该成分中心的偏差来表示数值。这允许表示多峰偏态分布。他们的生成解决方案 CTGAN 使用图 3 中描述的条件 GAN 架构来强制学习每列的适当条件分布。为了获得分类值并允许在存在分类值的情况下进行反向传播,使用了所谓的 gumbel-softmax 技巧 [138]。作者还提出了一种基于变分自动编码器的模型,名为 TVAE(用于表格变分自动编码器),其性能甚至优于 GAN 方法。这两种方法都可以被认为是最先进的。
虽然 GAN 和 VAE 很普遍,但最近提出的其他架构包括机器学习的因果模型 [139] 和可逆流(Invertible Flows) [119]。当隐私是主要关注因素时,PATE-GAN [140] 等模型为生成模型提供了一定的差分隐私保证。尽管对于实际应用非常有趣且相关,但此类隐私保证和使用表格数据的相关联合学习方法不在本次审查的范围内。
Fan et al. [118] 比较了用于表格数据合成的各种不同的 GAN 架构,并建议使用简单的全连接架构和普通 GAN 损失,并进行微小的更改以防止模式崩溃。他们还使用 [136] 提出的归一化。在他们的实验中,Wasserstein GAN 损失或在表格数据上使用卷积架构确实提高了生成性能。
B. Assessing Generative Quality
为了评估生成数据的质量,使用了几种性能指标。最常见的方法是定义一个代理分类任务,并在真实训练集上训练一个模型,在人工生成的数据集上训练另一个模型。借助功能强大的生成器,人工数据模型在真实数据测试集上的预测性能应该几乎与其对应的真实数据相当。这种度量通常被称为机器学习效率,并在 [117]、[136]、[141] 中使用。在非显而易见的分类任务中,可以将任意特征用作标签并预测 [117]、[142]、[143]。另一种方法是目视检查每个特征的建模分布,例如,累积分布函数 [110] 或比较散点图中的预期值 [117]、[142]。一种更定量的方法是使用统计检验,例如 Kolmogorov-Smirnov 检验 [146],来评估分布差异 [143]。在合成数据集上,可以将输出分布与真实值进行比较,例如就对数似然而言[136],[139]。因为过拟合模型也可以获得很好的分数,[136] 建议在估计 GAN 的输出分布的情况下评估测试集的可能性。特别是在保护隐私的情况下,可以计算到最近记录的距离 (DCR) 的分布,并将其与测试集上的相应距离进行比较 [137]。
VI. EXPLANATION MECHANISMS FOR DEEP LEARNING WITH TABULAR DATA
可解释的机器学习涉及为复杂的机器学习模型提供解释的问题。为实现这一目标,各种研究流遵循不同的可解释性范式,可大致分为特征突出(feature highlighting)和反事实解释(counterfactual explanations)[147]、[148]。
A. Feature Highlighting Explanations
本地输入归因技术试图逐个解释机器学习模型的行为。这些方法旨在了解如何使用模型可用的所有输入来得出某个预测。一些流行的模型解释方法旨在构建可通过设计解释的分类模型[149]-[151]。这通常是通过将深度神经网络模型强制为局部线性来实现的。此外,如果模型的参数是已知的并且可以访问,那么解释技术可以使用这些参数来生成模型解释。对于这样的设置,已经提出了基于相关传播的方法,例如 [152]、[153] 和基于梯度的方法,例如 [154]-[156]。在无法访问神经网络参数的情况下,与模型无关的方法可以证明是有用的。这组方法试图通过应用代理模型 [109]、[157]-[160] 在本地解释模型的行为,这些模型可以通过设计来解释,并用于解释黑盒机器学习模型的个体预测。为了测试这些黑盒解释技术的性能,[161] 的作者提出了一个基于 python 的基准测试库。
B. Counterfactual Explanations
从算法资源的角度来看,反事实解释的主要目的是建议对深度神经网络的输入进行建设性干预,以便输出改变为最终用户的优势。通过同时强调特征重要性和推荐方面,反事实解释方法可以进一步分为两类:基于独立性和基于依赖的方法。
在基于独立性的方法中,假设预测模型的输入特征是独立的,一些方法使用组合求解器在存在可行性约束的情况下生成资源[162]-[165]。另一项研究部署基于梯度的优化,以在存在可行性和多样性约束的情况下找到低成本的反事实解释 [166]-[168]。这些方法的主要问题是它们从输入相关性中抽象出来。
为了缓解这个问题,研究人员建议在生成模型上构建资源建议[169]-[174]。主要思想是将干预空间的几何形状更改为较低维的潜在空间,该潜在空间在捕获输入依赖关系的同时编码不同的变化因素。为此,这些方法主要使用(表格数据)变分自动编码器[134]、[175]。特别是,[172] 的作者演示了如何将各种可行性约束编码到此类模型中。
对于关于反事实解释的文献的更细粒度的概述,我们将感兴趣的读者推荐给最近的调查 [176]、[177]。最后,[178] 的作者实现了一个开源 python 库,它为许多上述反事实解释模型提供支持。
VII. EXPERIMENTS
尽管近年来已经发表了几项实验研究 [7]、[8],但仍然缺少对异构表格数据的现有深度学习方法的详尽比较。例如,没有讨论深度学习模型的重要方面,例如训练和推理时间、模型大小和可解释性。
为了填补这一空白,我们在本节中对机器和深度学习方法在具有不同特征的真实数据集上进行了广泛的经验比较。我们讨论了数据集选择 (VII-A)、结果 (VII-B),并比较了本调查中考虑的所有机器学习模型 (VII-C) 的训练和推理时间。我们还讨论了深度学习模型的大小。最后,据我们所知,我们首次对表格数据 (VII-D) 的可解释深度学习方法进行了比较。我们发布了我们实验的完整源代码,以实现最大的透明度。
A. Data Sets
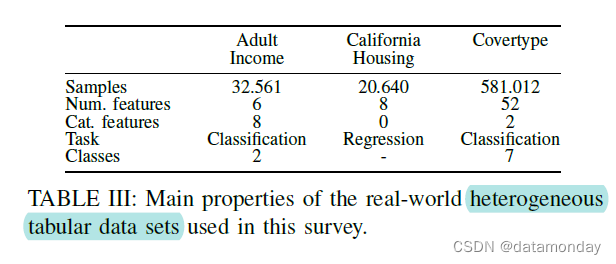
在计算机视觉领域,有许多标准数据集可用于评估新的深度学习架构,例如 MNIST [82]、CIFAR [179] 和 ImageNet [180]。相反,没有建立标准的异构数据集。
我们故意选择具有不同特征的数据集,例如数据域(金融、电子商务、地理)、分类变量的数量和样本量(从小到大)。此外,大多数选定的数据集以前曾在多项研究中出现过。
我们研究的第一个数据集是成人收入数据集 [181]。它包括关于个人的基本信息,例如:年龄、性别、教育程度等。目标变量是二元的;它代表高收入和低收入。
我们进一步使用加利福尼亚住房数据集 [182],其中包含有关许多属性的信息。目标(回归)是估计相应房屋的价格。
Covertype 数据集 [181] 是多分类数据集,其中包含有关陆地单元的制图信息(例如,高程、坡度)。目标是预测单元格中存在七种森林覆盖类型中的哪一种。
所选数据集的基本特征总结在表 V 中。(PS:这里作者应该写错了,应该是表 III)
B. Open Performance Benchmark on Tabular Data
1)超参数选择:为了进行公平的评估,我们使用 Optuna 库 [191] 对每个模型进行 100 次迭代来调整超参数。每个超参数配置都经过五次交叉验证。使用的超参数范围与我们的代码一起在网上公开可用。我们根据相应论文中给出的信息和框架作者的建议来布局搜索空间。
2)数据预处理:我们通过对数字特征应用零均值、单位方差归一化和对分类特征应用序数编码,以相同的方式为每个机器学习模型预置数据。对于线性回归和基于纯神经网络的模型,缺失值被零替换,因为这些方法不能接受它们。我们还对深度学习模型的分类值进行了独热编码,因为基于决策树的模型能够直接处理分类数据。
3)可重复性:为了获得最大的可重复性,我们使用 docker 容器 [192] 来运行我们所有的实验。我们再次强调,我们的完整代码已公开发布,以便可以复制实验并用作新方法的可靠基准。我们也希望数据科学界能够扩展现有的评估数量。
4)结果:我们的实验结果如表 IV 所示。他们绘制的图片与许多最近的研究论文可能暗示的不同:最好的分数仍然是通过增强决策树集成获得的,特别是 LightGBM。在我们实验中使用的三个数据集上,XGBoost 和 CatBoost 也优于所有基于深度学习的方法。与在各种 kaggle 表格数据竞赛中观察到的基于决策树集成的方法相比,我们的结果与深度学习方法的较差性能一致。大多数获胜模型都基于梯度提升决策树 [193]。
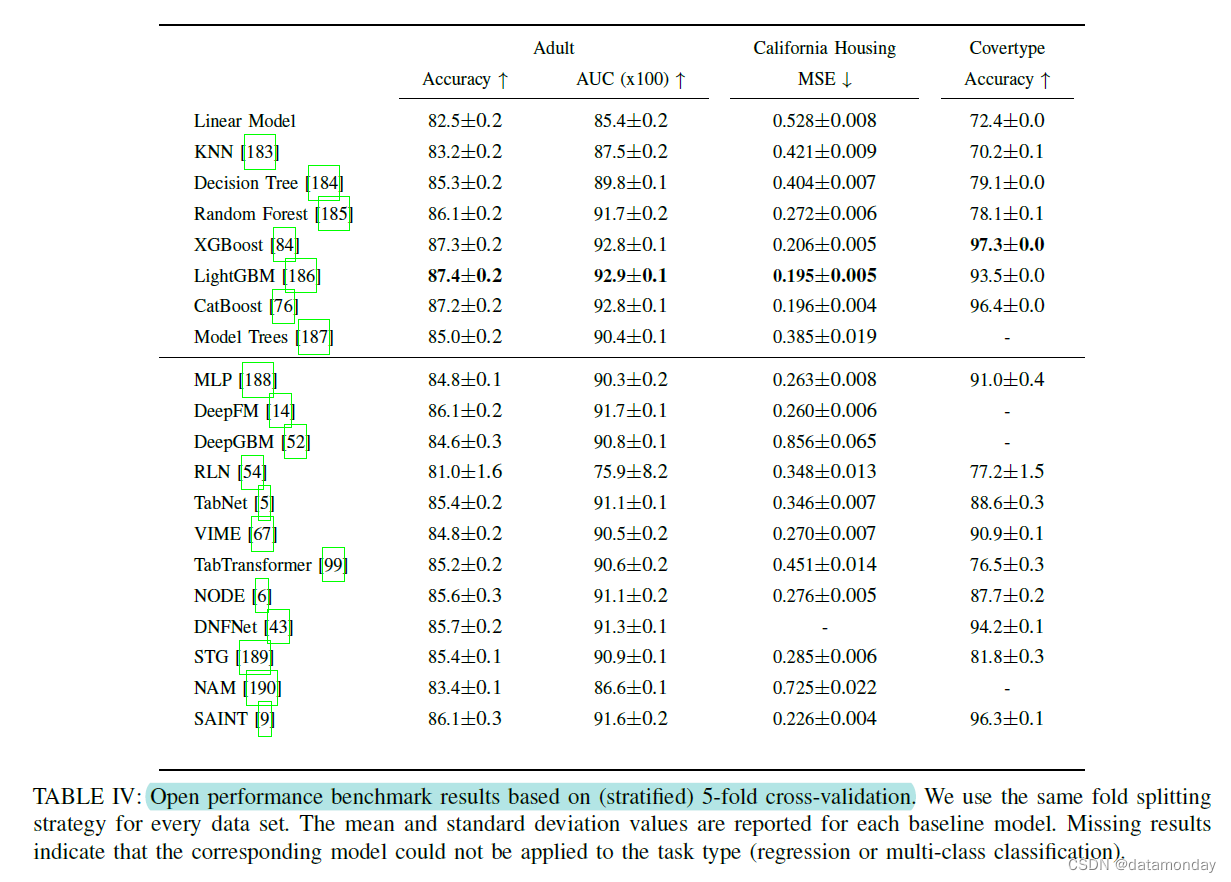
仅考虑深度学习方法,我们观察到 DeepFM 和 SAINT 提供了强大的结果。尽管他们仍然无法击败树集成,但在更大的 Covertype 数据集上,我们观察到 SAINT 的性能几乎与 CatBoost 相当,并且优于 LightGBM。我们假设深度学习模型可能对更大的数据集具有优势,但是在表格数据的上下文中很少见。
C. Run Time Comparison
我们还分析了基线模型的训练和推理时间,并与它们的性能进行了比较。我们在图 4 和图 5 中绘制了模型的时间性能特征。具有最佳训练时间性能特征的模型(对于给定的性能,没有更好的训练时间更短的模型)包括线性模型、决策树、随机森林和 XGBoost。对于推理时间与性能比,决策树、DeepFM、CatBoost 和 LightGBM 具有最佳特性。
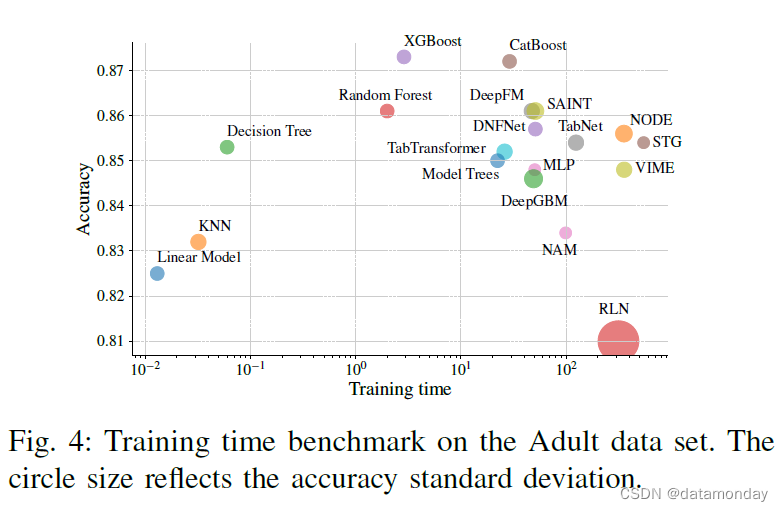
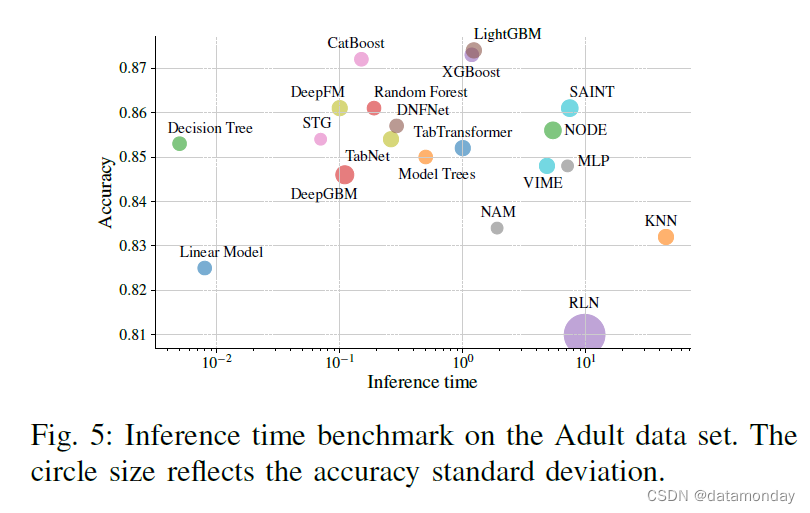
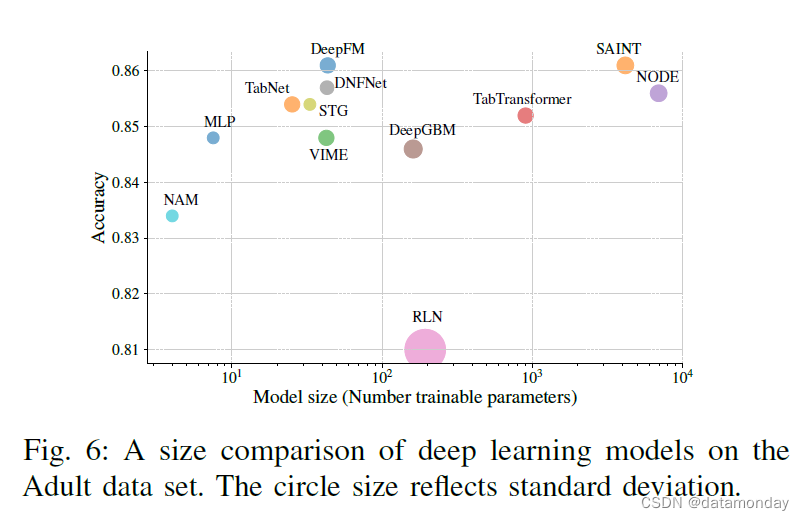
D. Interpretability Assessment
与纯粹的任务性能相反,模型的可解释性正成为一个越来越重要的特征。因此,我们以对某些方法声称的可解释性属性的独特评估结束本节。诚然,可以以非常不同的格式提供解释,每种格式都有自己的用例。因此,我们只能考虑具有共同形式的解释。在这项工作中,我们选择特征属性作为解释格式,因为它们是这项工作中考虑的模型的事后可解释性的普遍形式。值得注意的是,建立在Transformer架构上的模型(第 IV -B2 节)通常通过注意力图 [9] 声称具有一定程度的可解释性。为了验证这一假设并评估某些框架在实践中提供的属性,我们使用在所有样本中被赋予最高重要性的特征进行消融测试。此外,由于缺乏基本真实属性值,我们将个人属性与众所周知的 KernelSHAP 值进行比较 [109]。
众所周知,特征属性质量的评估是一个不平凡的问题[194]。我们通过从数据集中(Most Relevant First,MoRF)连续删除模型分配的具有最高平均重要性的特征来测量属性的保真度 [195]。然后,我们重新训练模型以规避由于插补引起的分布变化。预测准确性的快速下降表明最重要的特征已被成功删除。我们对相反的顺序执行相同的操作,即最不相关优先 (LeRF),它删除了被认为不重要的特征。在这种情况下,精度应尽可能保持高。对于 TabTransformer 和 SAINT 的注意力图,我们要么使用特征内注意力图的整个列的总和作为重要性估计,要么只将对角线(特征自注意力)作为属性。
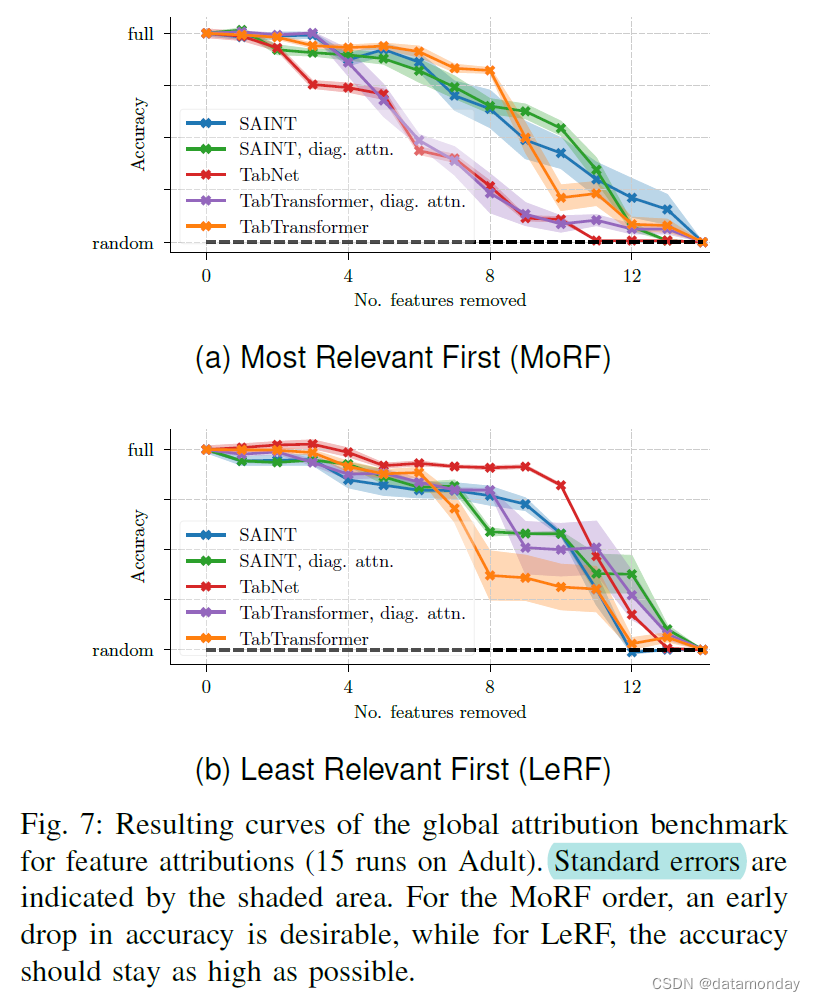
获得的曲线在图 7 中可视化。对于 MoRF 顺序,TabNet 和 TabTransformer 与注意力头的对角线作为属性看到表现最好。对于 LeRF,TabNet 是唯一明显优于其他方法的方法。对于 TabTransformer,取注意力矩阵的对角线似乎可以提高性能,而对于 SAINT,几乎没有区别。我们还将获得的属性值与来自 KernelSHAP 属性方法的值进行比较。不幸的是,没有可比较的基本事实属性。然而,SHAP 框架在博弈论中有坚实的基础,并被广泛部署 [45]。我们只比较属性的绝对值,因为注意力图被限制为正数。作为一致性的衡量标准,我们计算了 SHAP 框架的属性与表格数据模型之间的 Spearman 等级相关性。我们观察到的相关性在所有模型中都非常低,有时甚至是负数,这意味着较高的 SHAP 归因可能会导致模型的归因较低。
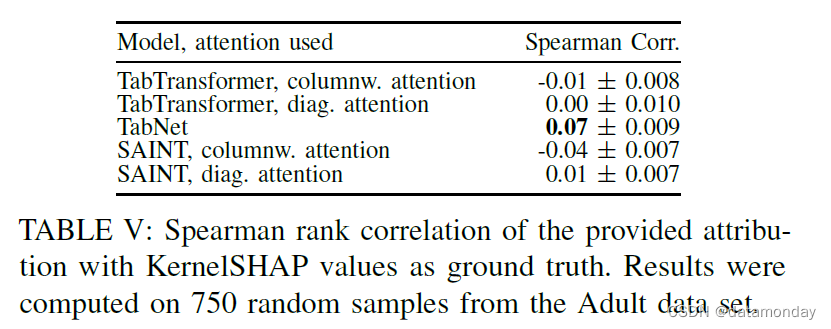
在这两个简单的基准测试中,transformer 模型无法立即生成令人信服的特征属性。我们得出的结论是,对所声称的可解释性特征及其在实践中的有用性进行更深刻的基准测试是必要的。
VIII. DISCUSSION AND FUTURE PROSPECTS
在本节中,我们总结了我们的发现并讨论了表格数据深度学习方法的当前和未来趋势(第 VIII-A 节)。此外,我们确定了几个开放的研究问题,可以解决这些问题以推进表格深度神经网络领域(第 VIII-B 节)。
A. Summary and Trends
决策树集成仍然是最先进的。在多个数据集的公平比较中,我们证明了基于树集成的模型,例如 XGBoost、LightGBM 和 CatBoost,在我们考虑的三个数据集上仍然优于深度学习模型,并且具有显着的额外优势训练时间少。尽管 XGBoost 发表 [84] 已有六年,而原始梯度提升论文 [77] 发表已有二十多年,但我们可以说,尽管在深度学习方面付出了很多研究努力,但表格数据的最新技术一直保持不变。因此,我们认为有必要对领域进行根本性的重新定位。对表格数据使用深度学习是否有好处的问题仍未得到解答。与其提出越来越复杂的模型,不如退后一步,专注于使用表格数据进行深度学习的信息保存表示机制可能是有益的。
统一基准测试。此外,我们的结果强调了统一基准的必要性。机器学习社区对于如何进行公平有效的比较没有达成共识。 [8] 的作者使用大约 40 个不同的表格数据集来评估机器学习算法的预测性能。 [7] 的作者表明,基准数据集的选择可以对绩效评估产生不可忽视的影响。虽然我们为我们的实验选择了具有不同特征的通用数据集,但数据集或超参数的不同选择,例如编码使用(例如,使用 one-hot 编码)可能会导致不同的结果。由于数据集的数量过多,因此需要标准化的基准测试程序,它可以识别与现有技术水平相关的重大进展。因此,通过这项工作,我们为表格数据的深度学习模型提出了一个开放基准。对于表格数据生成任务,[136] 的作者提出了一个具有人工和真实世界数据集的合理评估框架(Sec. V -B),但研究人员也需要就该子领域的通用基准达成一致。
表格数据预处理。深度神经网络在表格数据上的许多挑战都与数据的异质性有关(例如,分类值和稀疏值)。因此,一些深度学习解决方案将它们转换为更适合神经网络的同质表示。虽然额外的开销很小,但这种转换可以显著提高性能,因此应该是在现实世界场景中应用的首批策略之一。
表格数据深度学习的架构。在架构方面,近年来基于Transformer的解决方案(第 IV -B2 节)出现了明显的趋势。与标准神经网络架构相比,这些方法提供了多种优势,例如,在分类和数值特征上都关注学习。此外,利用未标记的表格数据来训练部分深度学习模型的自监督或无监督预训练越来越受欢迎,不仅在基于Transformer的方法中。
在性能方面,多个独立评估表明,与各种数据集上的普通深度神经网络相比,混合(Sec. IV -B1)和基于转换器(Sec. IV -B2)组的深度神经网络方法表现出更好的预测性能[ 9]、[41]、[52]、[92]。这强调了表格数据专用架构的重要性。
表格数据的正则化模型。还表明,正则化降低了深度神经网络模型的超敏感性并提高了整体性能 [8]、[54]。我们认为,正则化是深度神经网络在表格数据上更稳健、更准确的表现的关键方面之一,并且正在获得动力。
表格数据的深度生成模型。强大的表格数据生成对于开发高质量模型至关重要,尤其是在隐私环境中。有了合适的数据生成器,开发人员可以使用大型、合成且真实的数据集来开发更好的模型,同时不受隐私问题的影响 [140]。不幸的是,生成任务与预测模型中的推理一样困难,因此这两个领域的进展可能会齐头并进。
表格数据的可解释深度学习模型。可解释性无疑是可取的,特别是对于经常应用于个人数据的表格数据模型,例如在医疗保健和金融领域。越来越多的方法提供了开箱即用的方法,但大多数当前的深度神经网络模型仍然主要关注所选误差度量的优化。可解释的深度表格学习对于理解模型决策和结果至关重要,尤其是对于生命攸关的应用程序。模型解释可用于识别和减轻潜在偏见或消除对某些群体的不公平歧视[196]。
从不断发展的数据流中学习。许多现代应用程序受制于不断发展的数据流,例如社交媒体、在线零售或医疗保健。流数据通常是异构的并且可能是无限的。因此,观察结果必须一次性处理,并且不能存储。事实上,在线学习模型在每个时间步只能访问一小部分数据。此外,他们必须处理有限的资源和不断变化的数据分布(即概念漂移)。因此,深度学习中通常涉及的超参数优化和模型选择在数据流中通常是不可行的。出于这个原因,尽管深度学习在其他领域取得了成功,但在线学习应用程序中通常首选诸如增量决策树 [197]、[198] 等不太复杂的方法。
B. Open Research Questions
在未来的研究中需要解决几个未解决的问题。在本节中,我们将列出我们认为对该领域至关重要的那些。
编码的信息论分析。在处理表格数据时,编码方法非常流行。然而,大多数深度神经网络的数据预处理方法在信息内容方面都是有损的。因此,实现将异构表格数据高效、几乎无损地转换为同质数据具有挑战性。然而,关于这些转变的信息论观点仍有待详细研究,并可能阐明潜在的机制。
混合模型中的计算效率。 [7] 的作者的工作表明,梯度提升决策树和深度神经网络的结合可以提高机器学习系统的预测性能。然而,它也导致复杂性的增加。远远超过经典机器学习方法的训练或推理时间是开发混合模型的一个反复出现的问题。我们得出结论,经典机器学习和深度学习的最新技术方法的整合尚未最终解决,未来的工作应该是如何减轻预测性能和计算复杂性之间的权衡。
特殊正则化。我们赞扬最近对正则化方法的研究,我们看到了一个有希望的方向,需要进一步探索。特别是,是否可以找到表格数据的特定于上下文和体系结构的正则化,仍然是一个悬而未决的问题。此外,更深入地探索控制表格数据正则化成功的理论约束是相关的。
表格数据生成的新过程。对于表格数据生成,修改后的生成对抗网络和变分自动编码器很普遍。然而,依赖关系和分类分布的建模仍然是关键挑战。该领域的新架构(例如扩散模型)尚未适应表格数据领域。此外,特别关注表格数据的全新生成过程的定义可能值得研究。
可解释性。展望未来,深度表格学习的反事实解释可用于提高人机交互场景中的感知公平性并实现个性化决策[177]。然而,表格数据的异质性给反事实解释方法在实践中的可靠部署带来了问题。设计旨在在存在可行性约束的情况下有效处理异构表格数据的技术仍然是一项未解决的任务[178]。
将深度学习方法转移到数据流。最近的工作表明,神经网络在不断发展的数据流中的一些限制是可以克服的 [24]、[199]。相反,神经网络参数的变化可以有效地用于衡量输入特征随时间的重要性[200]或检测概念漂移[201]。因此,我们认为流数据的深度学习——特别是处理不断变化的异构表格数据的策略——应该在未来受到更多关注。
表格数据的迁移学习。重用获得的知识解决一个问题并将其应用于不同的任务是迁移学习解决的研究问题。虽然迁移学习已成功用于计算机视觉和自然语言处理应用程序 [65],但没有有效且普遍接受的方法来对表格数据进行迁移学习。因此,一个普遍的研究问题可以是如何在多个(相关)表格数据集之间有效地共享知识。
表格数据的数据增强。数据增强已被证明可以非常有效地防止过度拟合,尤其是在计算机视觉中 [202]。虽然存在一些用于表格数据的数据增强技术,例如 SMOTE-NC [203],但简单的模型无法捕获数据的依赖结构。因此,在连续的潜在空间中生成额外的样本是一个很有前途的方向。 [116] 的作者对此进行了调查,以进行少数过采样。然而,报告的改进只是微不足道的。因此,未来的工作需要找到简单但有效的随机变换来增强表格训练集。
自监督学习。训练深度神经网络通常需要大规模的标记数据,但是,数据标记是一项昂贵的任务。为了避免这个昂贵的步骤,自我监督方法建议从可用的未标记数据中学习一般特征表示。这些方法在计算机视觉和自然语言处理 [204]、[205] 中显示出惊人的结果。在这个方向上只有少数最近的工作 [67]、[103]、[206] 处理异构数据。因此,专门用于表格数据的新型自我监督学习方法可能值得研究。
IX. CONCLUSION
这项调查是第一项系统地探索异构表格数据的深度神经网络方法的工作。在这种情况下,我们强调了建模、解释和生成表格数据方面的主要挑战和研究进展,并提供了经验证据,证明决策树集成仍然代表了使用表格数据进行学习的最新技术。我们还引入了一个统一的分类法,将表格数据的深度学习方法分为三个分支:数据编码方法、专用架构模型和正则化模型。我们相信我们的分类法将有助于对未来的研究进行分类,并更好地理解和解决将深度学习应用于表格数据的剩余挑战。我们希望它能帮助研究人员和从业者找到最适合他们应用的策略和方法。
此外,我们还在多个真实世界的数据集上对最先进的深度学习方法进行了公平的评估。基于深度神经网络的异构表格数据方法仍然不如基于决策树集成的机器学习方法。此外,我们评估了具有自注意力机制的深度学习模型的解释属性。尽管 TabNet 模型显示出有希望的解释解释能力,但深度学习方法的解释之间的不一致仍然是一个悬而未决的问题。
由于表格数据对工业界和学术界的重要性,这一领域的新想法需求量很大,并可能产生重大影响。通过这篇综述,我们希望为感兴趣的读者提供他们需要的参考资料和见解,以应对开放的挑战并更有效地推进该领域。

