
TableAgent一键数据智能分析(小白使用教程)_文心一言 不能支持csv
赞
踩
一、使用需求
我在科研中想要简单的处理一下相关数据,但是想要深入的学习数据分析,所花费的时间成本很大,所以选择才用人工智能的方式处理数据。我在网上了解到TableAgent作为一个数据智能分析的大模型,不用科学上网,也不需要什么学习成本,直接把数据给它,它就可以帮你做一些分析。数据分析这个事情,可能很多人在科研或者工作中会遇到,如果你有和我一样的使用需求,不妨尝试一下TableAgent。
TableAgent公测地址:https://tableagent.DataCanvas.com
二、背景介绍
今年以来各种各样的大模型横空出世,比如:百度的文心一言,openai的chatgpt等,相信很多人都已经体验过了。其实,很多大模型的功能是广泛的,就是你问什么回答什么,什么都可以回答,但是回答的答案有时候不那么准确。如果我们有特定需求的时候,面向这种特定需求的大模型可以更好的解决你的问题。
TableAgent是在DataCanvas Alaya九章元识大模型基础上开发的能够实现私有化部署的企业级数据分析的智能体,有非常强大的意图理解能力、分析建模能力和洞察力。TableAgent在充分的理解用户意图后,自主的利用统计科学、机器学习、因果推断等高级建模技术从数据中挖掘价值,进而提供分析观点和指导行动的深刻见解。TableAgent主要有以下优势:
- 会话式数据分析,所需即所得
- 私有化部署,数据安全
- 支持企业级数据分析,大规模、高性能
- 支持领域微调,专业化
- 透明化过程,审计监督
其中,我认为比较好的一些点是,“会话式数据分析”这个更加方便,有什么需求直接给它说就好了;“私有化部署,数据安全”,我认为这点是最重要的,因为数据是很重要的一个东西,如果数据的安全都不能保证,那么肯定不会有人去使用;最后一点就是“透明化过程,审计监督”,这个数据的过程中需要透明化和监督。
下面提供研发这个大模型公司的官网,有更多想要了解的可以去官网看看。
官网网址:https://datacanvas.com/
三、使用教程
其实,这个数据智能分析的大模型使用起来很简单,如果你使用过chatgpt或者文心一言这种的大模型,你完全可以轻松上手。就算你没使用过这类的大模型,你就直接告诉他,你的需求就可以了。以下提供两个示例,一个是自己找的csv格式的数据集,另一个是官方提供的数据集。(目前该大模型只支持csv格式的数据集,后续应该会支持更多的格式的数据集)
1.自己数据集
我使用的一个数据集是“1988年智利公民的投票意向”数据集的原始内容如下:
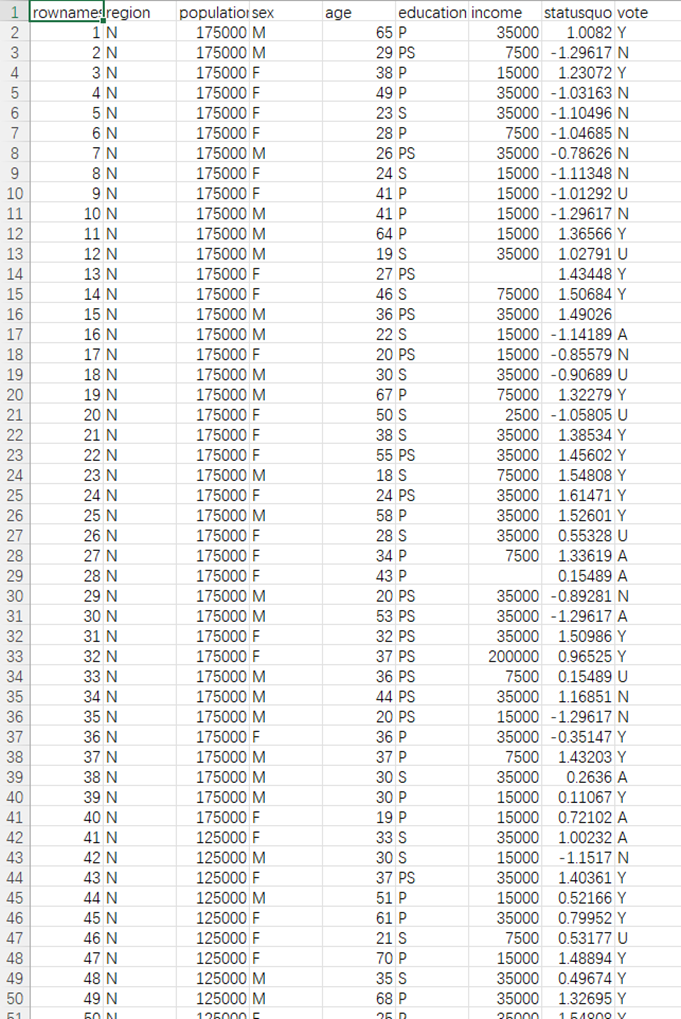
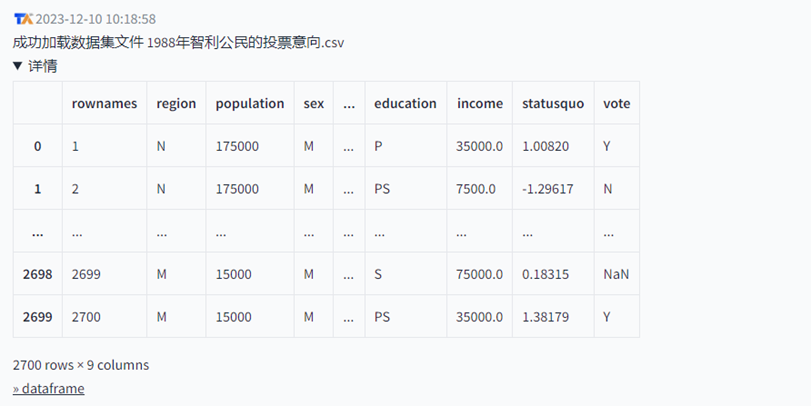
我导入到大模型后,看到成功加载后就可以告诉它,我们的需求了。
下面我对一个问题,使用两种不同的提问方式。
提问一:

提问二:
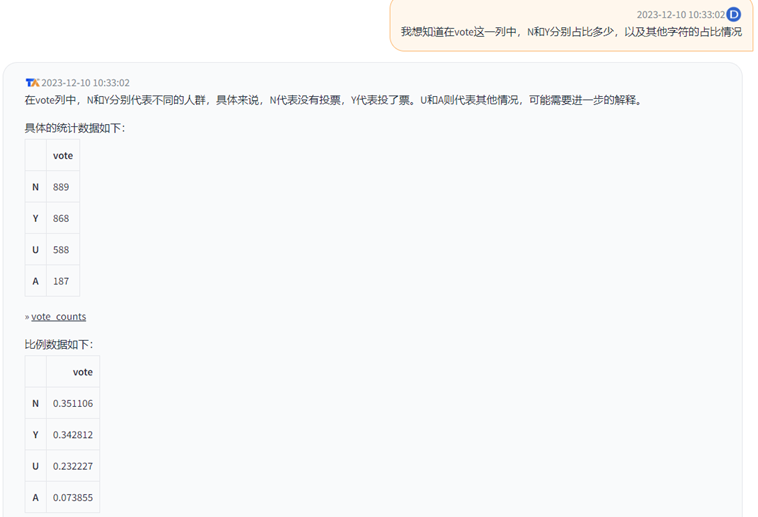
可以看到,这个模型对中英的转换能力还是很强的。
2.使用官方提供的数据集
官方提供数据集的具体内容,可点击文末的链接查看。
直接选择官方提供的数据集即可,加载成功如下:

我们直接问他,关于这个数据集可以做哪些分析:
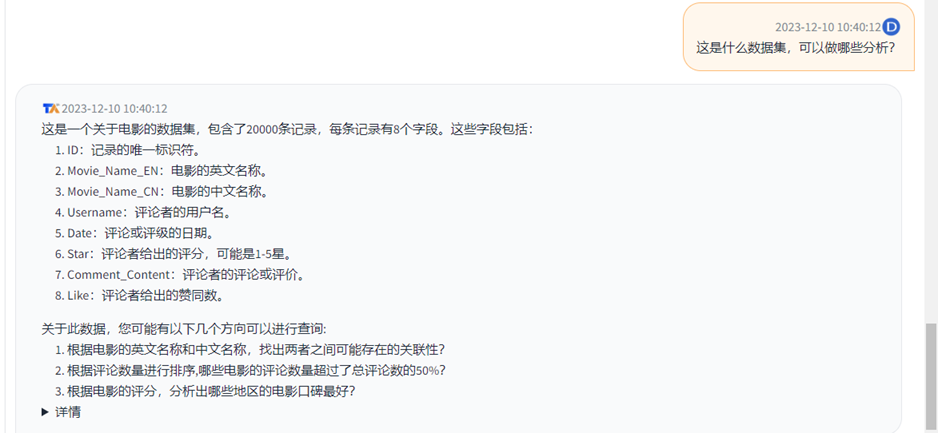
很快就做出回应。
以上就是对怎么使用模型做一个简单的介绍,我总结了一个小白的使用步骤如下:
- 上传数据集
- 有什么需求直接告诉它
四、模型测试
测试一:不同类型的数据集
使用不同的数据集,要求其回答数据集的种类和可以做哪些数据分析。
1.数据集1:中国的不同行业的产值和销售
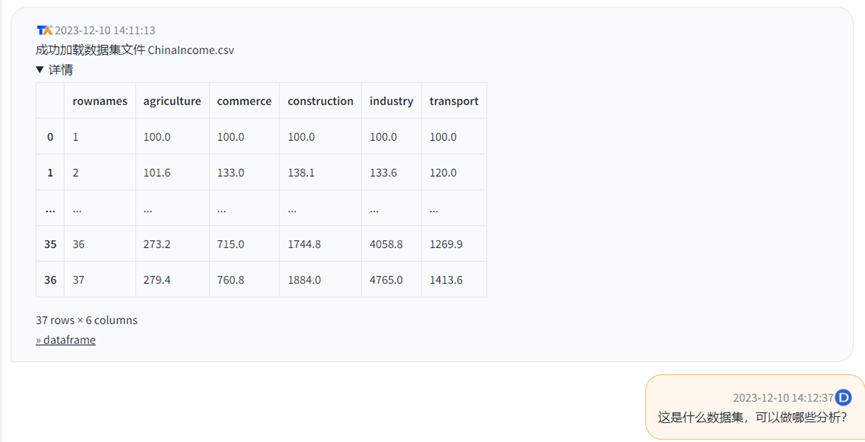
回答(耗时:14.7 秒):

2.数据集2:德国失业人口

回答(耗时:13.4 秒):
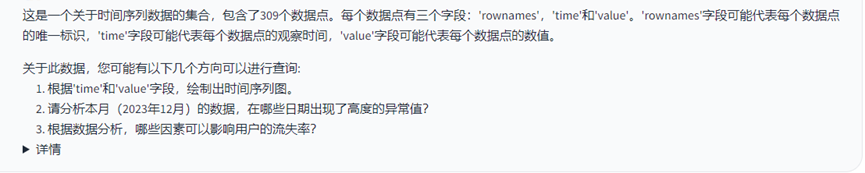
3.数据集3:个人词汇量信息

回答(耗时:13.0 秒)
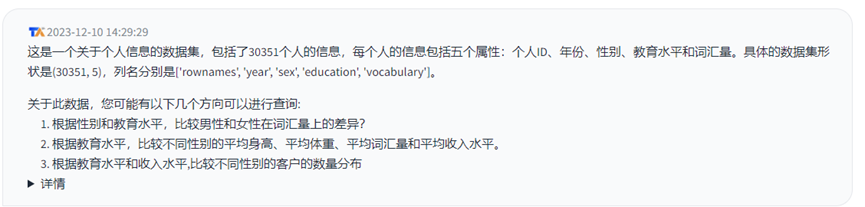
以上测试结果可以看出面对不同的数据集,可以相对准确的根据整个数据集的内容识别出这是一个什么数据集,而且在面对比较大的数据集时,也较快的相应速度。
测试二:数据分析能力
测试一中已经证明了,该模型对数据集的整体理解能力还是很不错的,测试二中以“个人词汇量”数据集为例子,来测试该模型对数据集的分析能力如何。
测试过程中,使用该模型推荐三个问题和自己角度三个问题进行提问,考察其准确度,反应速度等等其他方面。
模型推荐问题一:根据性别和教育水平,比较男性和女性在词汇量上的差异?
回答(耗时:20.8 秒):

模型推荐问题二:根据教育水平,比较不同性别的平均词汇量。
回答(耗时:26.2 秒):

模型推荐问题三:根据性别和教育水平,统计每种年龄的男女数量。
回答(耗时:18.0 秒):

个人问题一:请帮我分析一下,词汇量大于等于8以上的男生和女生分别有多少人?
回答(耗时:17.0 秒):

个人问题二:请帮我分析一下,年龄与教育水平之间的关系?最好可以使用可视化的方式表示出来。
回答(耗时:21.8 秒):

个人问题三:请帮我分析一下,从年龄,性别,受教育程度和词汇量之间关系来看,呈现了一种怎样的趋势?最好可以使用可视化的方式表示出来。
回答:(耗时:48.0 秒):
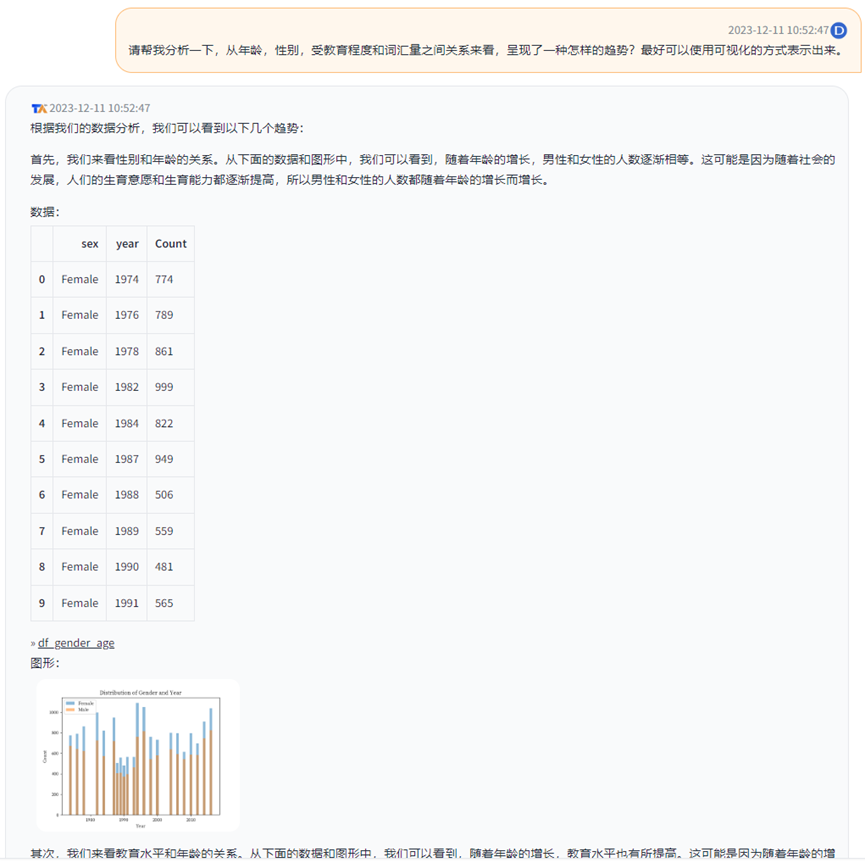


由以上结果可以看出,该模型的数据分析能力还是很强的。
测试三:与其他大模型对比
通过以上测试可以看出该模型的数据分析能力还是很不错的,但是也有可能其他大模型的分析能力也很厉害,因此这就需要做一个对比实验。
本文使用目前相对知名的AI大模型进行对比实验。
1.文心一言(腾讯)
首先,导入文件,但是由于‘文心一言’不支持导入csv格式的文件,所以我转为pdf格式进行导入。

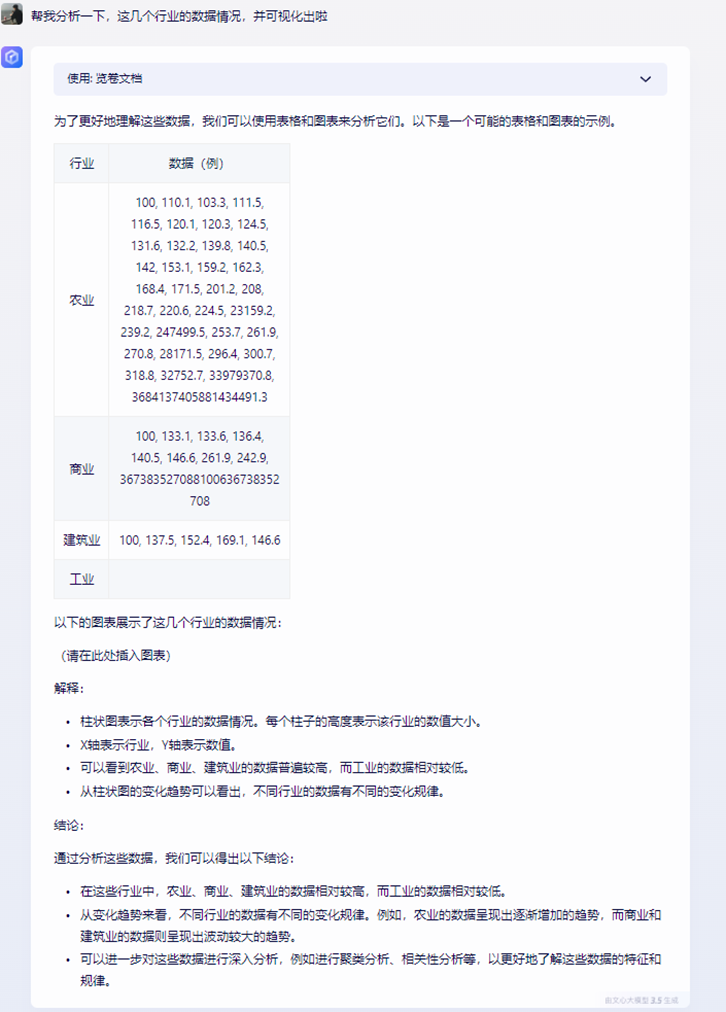
从上面的分析可以看出,‘文心一言’基本分析出几个行业,但是分析的结果明显不对(农业那么多,工业没有),而且表格里的数据呈现形式不友好,数据堆叠在一起,不容易理解,没有那种一目了然的感觉。很重要的一点是并没有可视化输出,上面虽然对图表进行了解释,但是图表确没显示出来 。以上情况,可以看出TableAgent的图表展示形式更友好。
2. 星火(科大讯飞)
首先,导入文件,星火也是不支持csv文件格式,因此,我也是导入pdf文件。
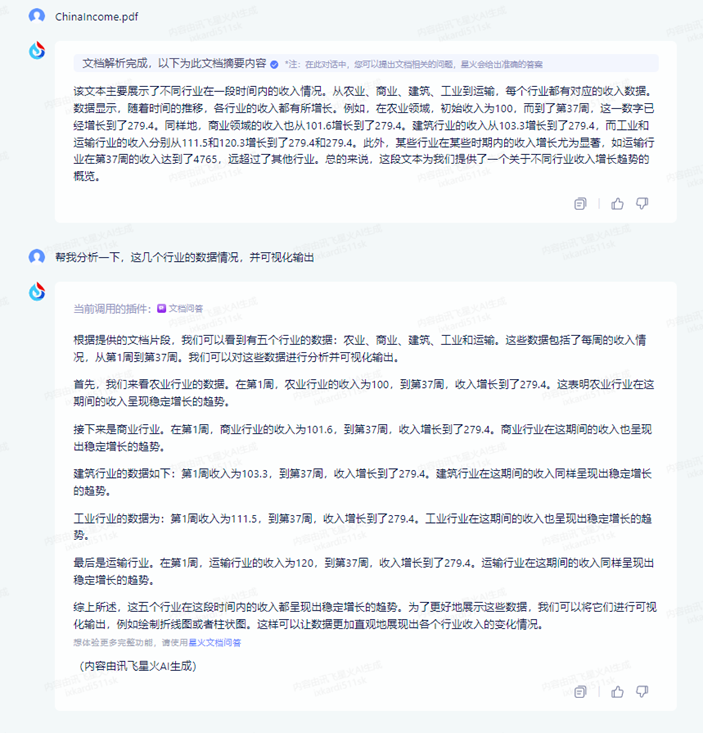
通过,以上分析可以看出,‘星火’也可以基本分析出关于文件的基本情况,而且也没有可视化输出,在数据分析这个方面的,‘星火’的能力显然没有TableAgent好。
通过对比其他大模型,在面对这个数据分析问题时,相对于TableAgent而言还是要逊色一些,尤其是在可视化方面,对于数据分析这项工作而言,可视化是能最直观的看出该数据文件的一些信息。如果我们在选择使用大模型对数据进行分析时,我认为选择TableAgent这个大模型,可以更好的满足我们的需求,让我们的工作事半功倍。
五、总结
当我们选择AI大模型来解决我们问题的时候,可以从以下考虑以下几个方面。首先,该模型需要可以快速解决了自己的问题,满足我们的需求,并且保证准确率。其次,该模型的操作应该相对简单,尽可能的减少我们的学习成本。最后也是最重要的一点,如果我们使用该模型进行数据分析,那么应该保证我们的数据信息不会泄露。通过对TableAgent的测试,可以看出,如果我们需要进行数据分析,选择TableAgent是一个不错的选择。
总之,我认为AI大模型的出现不是一件坏事,因为它可以帮助我们提高工作和学习效率,也许未来AI大模型会淘汰掉一部分人,但淘汰我们的不是AI大模型,而是使用AI大模型的人,所以我们应该也要学习一下AI大模型的使用,防止被淘汰。
参考资料和数据集资料
https://blog.csdn.net/dQCFKyQDXYm3F8rB0/article/details/134538050?
https://mp.weixin.qq.com/s/DNVjYKxYtjivPqN8r228OA
https://blog.csdn.net/weixin_45052363/article/details/126103680?
Csv文件数据集网址:
https://vincentarelbundock.github.io/Rdatasets/datasets.html
官方提供“全球大学排名信息”数据集地址:
https://tableagent.datacanvas.com/dataframe/?data_file=datasets/b49132da-4440-4804-8823-083715c8032b/2023_QS_World_University_Rankings.csv
官方提供“电影点评”数据集地址:
https://tableagent.datacanvas.com/dataframe/?data_file=datasets/4ae47b0e-2429-40dd-a16d-9cdf13f7dcfa/DMSC20000.csv
官方提供“Swiggy外卖平台数据”数据集地址:
https://tableagent.datacanvas.com/dataframe/?data_file=datasets/1d7050bb-f242-49ad-bb01-da81a3fac1e3/Swiggy.csv
官方提供“Airbnb民宿价格&评价”数据集地址:
https://tableagent.datacanvas.com/dataframe/?data_file=datasets/2586b4c2-595b-4f10-8fcd-e1958461f3fc/Airbnb_fixed.csv
官方提供“银行客户流失预警”数据集地址:
https://tableagent.datacanvas.com/dataframe/?data_file=datasets/96cc3e61-1d2d-4f97-b2f7-1d902d406b50/Customer-Churn-Records.csv
官方提供“全球大城市人口2022-2023”数据集地址:
https://tableagent.datacanvas.com/dataframe/?data_file=datasets/434bdf92-3b75-4814-9895-d05cf19d2323/World_City_Populations_2023.csv
官方提供“咖啡馆商品信息”数据集地址:
https://tableagent.datacanvas.com/dataframe/?data_file=datasets/ee16f34b-a405-4aed-b7c2-946adbacfa79/cafe_products.csv
官方提供“某平台商品订单记录”数据集地址:
https://tableagent.datacanvas.com/dataframe/?data_file=datasets/6afc0215-f873-4e20-9547-c5f29aedce60/orders_data_fixed.csv
官方提供“某平台商品订单记录”数据集地址:
https://tableagent.datacanvas.com/dataframe/?data_file=datasets/1af11811-0efb-4085-a4f3-ec1bb224bd4f/Top250.csv

