
热门标签
热门文章
- 1(Graph Theory) Adjacency Matrix_the adjacency matrix
- 2C语言mp3音乐播放_c程序播放mp3
- 3降维方法:PCA、SVD、LDA、LLE_pca不做特征分解
- 4mybatis中sqlSession的使用_mybatis sqlsession使用
- 5systemd自定义系统服务的详细配置介绍_type=notify
- 6zabbix监控交换机_zabbix添加锐捷交换机
- 7C#中静态方法与普通方法的区别、Lambda表达式
- 8Pytorch修改预训练模型时遇到key不匹配问题_pytorch中.pth模型参数keys更改
- 9C++ : 类的简单介绍(五)————— 拷贝构造函数 & 函数传参 & 运算符重载
- 10Colab白嫖指南——以训练YOLO-v5为例_有什么好的免费gpu训练yolo吗
当前位置: article > 正文
手把手教你量化网络(2)权重参数的量化_权重量化
作者:AllinToyou | 2024-03-05 11:47:58
赞
踩
权重量化
我是 雪天鱼,一名FPGA爱好者,研究方向是FPGA架构探索和数字IC设计。
关注公众号【集成电路设计教程】,获取更多学习资料,并拉你进“IC设计交流群”。
QQIC设计&FPGA&DL交流群 群号:866169462。
一、量化算法
1.1 K-Means
将一堆二维样本表示在坐标轴上,如下图左图所示:
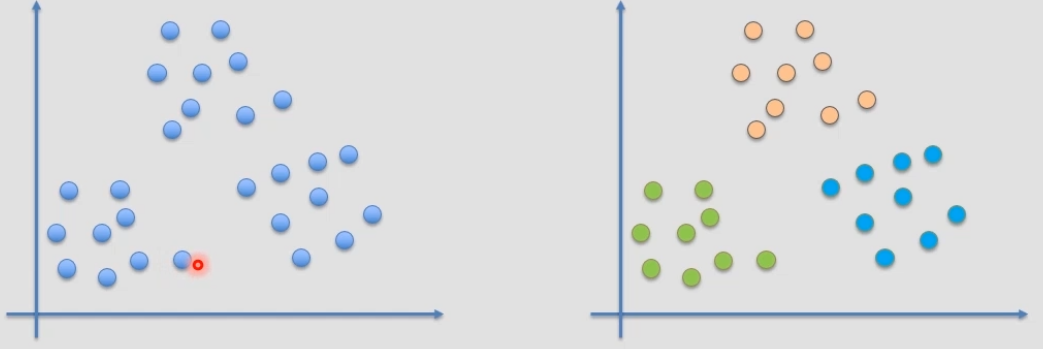
若我们将其用K-Means分为3类,如上图右侧所示,分为了绿、蓝和橙三类,还会告诉我们每类的聚类中心在哪里,这样就可以用三个数据去代替之前的多个数据,达到减少存储数据所需的内存空间大小的目的。
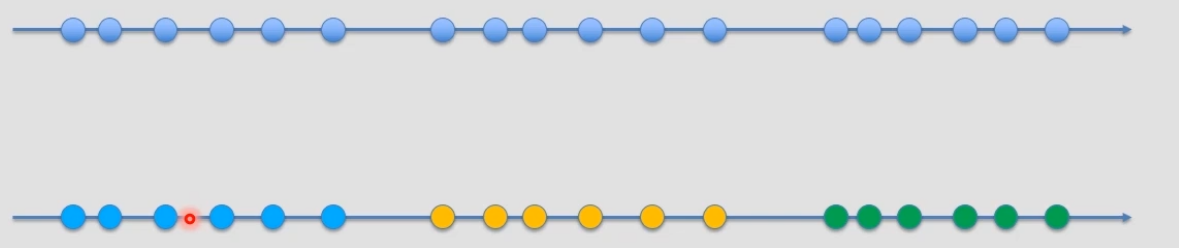
对于一维数据而言,也是一样的,会将每个数据划分到具体的类(即 label),然后也告诉我们每个类的聚类中心(center)。
二、算法代码实现
1.1 K-Means代码实现
1 安装包
pip install scikit-learn
- 1
2 导入 K-Means
from sklearn.cluster import KMeans
- 1
3. 完整代码实现
def k_means_cpu(weight, n_clusters, init='k-means++', max_iter=50): # flatten the weight for computing k-means,转为一维数据 org_shape = weight.shape weight = weight.reshape(-1, 1) # 若类别大于矩阵权重个数,则修改类别个数为矩阵权重个数。 if n_clusters > weight.numel(): n_clusters = weight.numel() # 处理数据,进行分类 k_means = KMeans(n_clusters=n_clusters, init=init, n_init=1, max_iter=max_iter) k_means.fit(weight) # 读取 “聚类中心” 和 “labels” centroids = k_means.cluster_centers_ labels = k_means.labels_ # 将 labels 还原为输入权重矩阵的形式 labels = labels.reshape(org_shape) return torch.from_numpy(centroids).cuda().view(1, -1), torch.from_numpy(labels).int().cuda()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
函数 k_means_cpu:
- weight:权重参数矩阵,tensor 数据类型。
- n_clusters:将数据分为 n 类
- return:返回两个参数,聚类中心 和 对应的 label 矩阵。
测试:
print("="*10) print("未分类前的权重矩阵") w = torch.rand(4, 5) print(w,w.shape) # print("展开") # w2 = w.reshape(-1, 1) # print(w2,w2.shape) # num = w2.numel() # print(num,type(num)) print("="*10) print("经 K-Means 算法分类后的权重矩阵") centroids, labels = k_means_cpu(w, 2) print(centroids) print(labels)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
输出结果:

可以看到这里将其分为了2类,首先输出 聚类中心,这里为 tensor([[0.7972, 0.3407]]),再输出labels矩阵。可以看到大点的权重都划分到了0.7972这一类,小点的权重都划分到了 0.3407这一类。复原即为:
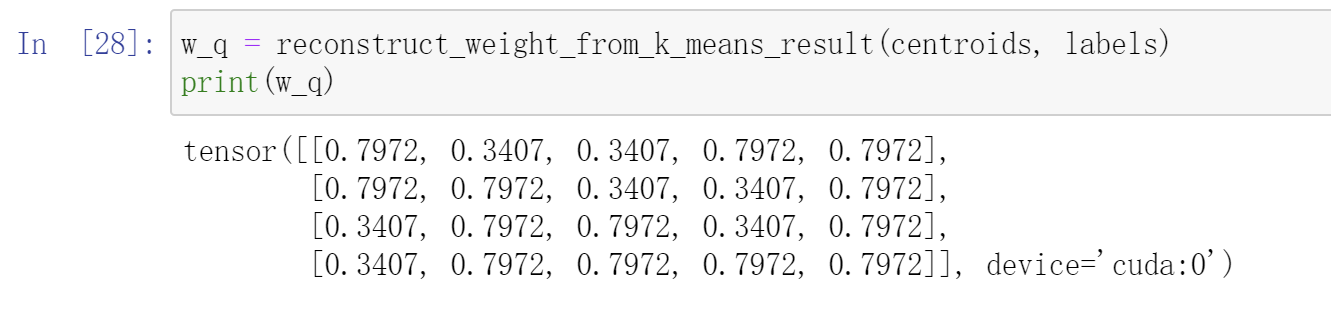
下一节将讲述如何在实际网络中量化权重参数。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/AllinToyou/article/detail/190806
推荐阅读
相关标签

