
首先需要说明一下推荐系统数据中的几个类别:
Item: 即我们要推荐的东西,如产品、电影、网页或者一条信息片段
User:对item进行评分以及接受推荐系统推荐的项目的人
Rating:用户对item的偏好的表达。评分可以是二分类的(如喜欢和不喜欢),也可以是整数(如1到5星)或连续(某个间隔的任何值)。 另外,还有一些隐反馈,只记录一个用户是否与一个项目进行了交互。
在文章 The Nine Must-Have Datasets for Investigating Recommender Systems 中介绍了推荐系统研究中的九大数据集。
1. MovieLens 【数据地址:https://grouplens.org/datasets/movielens/】(1M、10M、20M 共三个数据集)
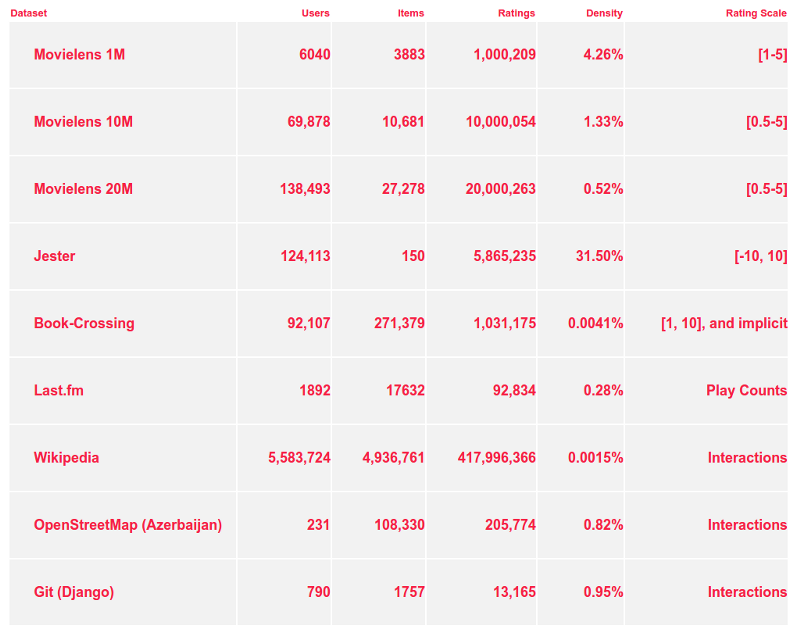
MovieLens数据集由GroupLens研究组在 University of Minnesota — 明尼苏达大学中组织的。MovieLens是电影评分的集合,有各种大小。 数据集命名为1M,10M和20M,是因为它们包含1,10和20万个评分。MovieLens数据集中,用户对自己看过的电影进行评分,分值为1~5。MovieLens包括两个不同大小的库,适用于不同规模的算法.小规模的库是943个独立用户对1682部电影作的10000次评分的数据;大规模的库是6040个独立用户对3900部电影作的大约100万次评分。
2. Jester 【数据地址:http://eigentaste.berkeley.edu/dataset/】
Jester是由Ken Goldberg和他在加州大学伯克利分校的小组发展的,包含150个笑话大约600万的评分。 像MovieLens一样,Jester评分由互联网上的用户提供。与其他数据集相比,Jester有两个方面是特殊的:它使用-10到10的连续等级,并且在量级上具有最高的评分密度。评分密度的意思是大概“平均每个用户评价多少个项目”?如果每个用户都对每个项目进行了评分,那么评级密度将为100%。 如果没有人评价过任何东西,那将是0%。 Jester的密度约为30%,这意味着一个用户平均对30%的笑话进行了评分。 作为比较,MovieLens 1M的密度为4.6%(其他数据集的密度低于1%)。当然不是那么简单。 不是每个用户都评价相同数量的项目。 相反,一些用户对许多项目进行评分,大多数用户只评价一些。
3. Book-Crossings 【数据地址:http://www2.informatik.uni-freiburg.de/~cziegler/BX/】
Book-Crossings是由Cai-Nicolas Ziegler根据 bookcrossing.com 的数据编写的图书评分数据集。 它包含90000个用户的270000本书的110万个评分。评分范围从1到10,包括显式和隐式的评分。Book-Crossings数据集是最不密集的数据集之一,也是具有明确评分的最不密集的数据集。
4. Last.fm 【数据地址:https://grouplens.org/datasets/hetrec-2011/】
Last.fm提供音乐推荐的数据集。 对于数据集中的每个用户,包含他们最受欢迎的艺术家的列表以及播放次数。它还包括可用于构建内容向量的用户应用标签。Last.fm的数据聚合aggregated)后,有些信息(关于特定的歌曲,或某人正在听音乐的时间)会丢失。 然而,它是这些样本中唯一具有用户的社交网络的信息的数据集。
5. Wikipedia 【数据地址:https://en.wikipedia.org/wiki/Wikipedia:Database_download#English-language_Wikipedia】
维基百科是其用户撰写的协作百科全书。维基百科除了为最后一刻拼写学期论文的学生提供信息外,还为每个用户提供每篇文章的每个编辑的数据转储。该数据集已广泛用于社交网络分析,图形和数据库实现测试,以及维基百科用户行为研究。还可以将用户采取的编辑操作,作为隐性评分,表明他们因某些原因关心该页面,并允许我们使用数据集来提出推荐。
由于维基百科不是为了提供推荐者数据集而设计的,所以它确实存在一些挑战。其中一个是从页面中提取有意义的内容向量,但是幸运的是,大多数页面被很好地分类,为每个页面提供了一种类型。构建维基百科的内容向量的挑战与现实世界数据集的推荐面临的挑战相似。所以我们认为这是建立一些这样做的专门知识的好机会。
6. OpenStreetMap 【数据地址:http://planet.openstreetmap.org/planet/full-history/】
OpenStreetMap是一个协作的地图项目,类似于维基百科。 像维基百科一样,OpenStreetMap的数据由用户提供,整个编辑历史的完整转储也是可用的。 数据集中的对象包括道路,建筑物,兴趣点,以及您可能在地图上找到的任何其他内容。 这些对象由键值对标识,因此可以从中创建一个基本的内容向量。 然而,键值对是自由的,所以选择正确的设置是一个挑战。 一些键值对由编辑软件(例如“highway =住宅”)进行标准化和相同的使用,但通常它们可以是用户决定进入的任何内容 - 例如“FixMe !! = Exact location unknown”。
7. Python Git Repositories
收集的最终数据集,也许最不传统的,基于Git存储库中包含的Python代码。 我们写了几个脚本(在Hermes GitHub repo中 在此获取)从互联网上下载存储库,提取其中的信息,并将其加载到Spark中。 从那里我们可以从用户编辑中构建一组隐含的评分。目前通过查看所有导入的库并调用函数从每个Python文件中提取内容向量。 将来我们计划将库和函数本身作为建议的项目。
以上9个数据集在其关键指标方面的比较:
其他一些数据集:
1. EachMovie
HP/Compaq的DEC研究中心曾经在网上架设EachMovie电影推荐系统对公众开放.之后,这个推荐系统关闭了一段时间,其数据作为研究用途对外公布,MovieLens的部分数据就是来自于这个数据集的.这个数据集有72916个用户对l628部电影进行的2811983次评分。早期大量的协同过滤的研究工作都 是基于这个数据集的。2004年HP重新开放EachMovie,这个数据集就不提供公开下载了。
2. Netflix
这个数据集来自于电影租赁网址Netflix的数据库。Netflix于2005年底公布此数据集并设立百万美元的奖金(netflix prize),征集能够使其推荐系统性能上升10%的推荐算法和架构。这个数据集包含了480189个匿名用户对大约17770部电影作的大约lO亿次评分。
3. Usenet Newsgroups
这个数据集包括20个新闻组的用户浏览数据。最新的应用是在KDD2007上的论文。新闻组的内容和讨论的话题包括计算机技术、摩托车、篮球、政治等。用户们对这些话题进行评价和反馈。
4. UCI知识库
UCI知识库是Blake等人在1998年开放的一个用于机器学习和评测的数据库,其中存储大量用于模型训练的标注样本。
5. LibRec 开源工具提供的数据集【数据地址:https://www.librec.net/datasets.html】
6. Datasets For recommender system 博客中总结提供的数据集
Amazon Product Data:
Mobile Recommendation:
- Data Set for Mobile App Retrieval link
- frappe link
- Ali_Mobile_Rec link1 ; link2
- Mobile App User Dataset link
Movies Recommendation:
- MovieLens - Movie Recommendation Data Sets link
- Yahoo! - Movie, Music, and Images Ratings Data Sets link
- Cornell University - Movie-review data for use in sentiment-analysis experiments link
- Netflix Prize Dataset link
- MovieTweetings - link
Joke Recommendation:
- Jester - Movie Ratings Data Sets (Collaborative Filtering Dataset) link
Music Recommendation:
- Last.fm - Music Recommendation Data Sets link
- Yahoo! - Movie, Music, and Images Ratings Data Sets link
- Audioscrobbler - Music Recommendation Data Sets link
- Amazon - Audio CD recommendations link
Books Recommendation:
- Institut für Informatik, Universität Freiburg - Book Ratings Data Sets link
Food Recommendation:
- Chicago Entree - Food Ratings Data Sets link
Merchandise Recommendation:
- Amazon - Product Recommendation Data Sets link
Healthcare Recommendation:
- Nursing Home - Provider Ratings Data Set link
- Hospital Ratings - Survey of Patients Hospital Experiences link
Dating Recommendation:
- www.libimseti.cz - Dating website recommendation (collaborative filtering) link
Scholarly Paper Recommendation:
- National University of Singapore - Scholarly Paper Recommendation link
【Reference】
1. gab41.lab41: The Nine Must-Have Datasets for Investigating Recommender Systems
2. zhihu:推荐系统研究中的九大数据集
3. cnblogs:开放的数据集整理
4. Datasets For recommender system
5. 还没准备好数据呢,为什么要着急用算法呢 (将显式数据与隐式数据分类)


