
- 1Java-猜数游戏_用java设计一个猜数程序
- 2Java注解详解和自定义注解实战,用代码讲解
- 3NLP_task3特征选择_点互信息和互信息(求词语关联性)_文本分析pmi词语相似度做什么的
- 4《Helm包管理工具篇:Helm工具概述和安装》_linux helm
- 5LaTeX 数学公式(简述)_latex 模
- 6MyBatis-Plus Generator v3.5.1 最新代码自动生成器_mybatis-plus-generator
- 7使用 YOLOv5 进行图像分割的实操案例
- 8Linux服务器上配置Jupyter进行远程登入并在后台运行_linux怎么让jupyter后台运行
- 9TOP 100值得读的图神经网络----架构_discriminative graph convolutional networks for se
- 10CIKM-2016-DRMM-A Deep Relevance Matching Model for Ad-hoc Retrieval_drmm深度相关匹配模型代码
CRNN原理详解、代码实现及BUG分析
赞
踩
CRNN原理及实现
近期了解了一下文本识别,在CRNN的学习过程,包括CRNN原理、CTC Loss、代码实现、bug调试等问题也进行了一些调研,将自己的一些看法尽可能简洁地总结记录下来,如有错误,欢迎指出。
CRNN使用CNN提取图像特征,RNN进行序列推理,配合CTC的不定长字符识别,是文本和语音识别的一个重要模型。

推理过程
以测试阶段一张图像输入为例(batch_size为1),对crnn的整个过程进行输入输出的尺寸的描述,
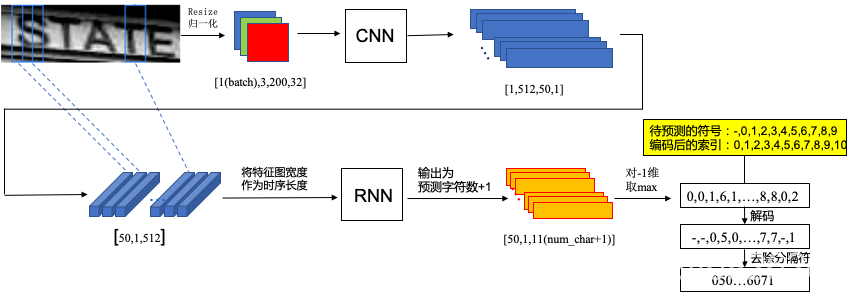
首先要将图片Resize到[200,32]大小,200为图片宽度,这个参数与我们要预测的字符长度息息相关,经过CNN提取特征,这里的CNN可以任意设置,较常用的是VGG,当然是截取VGG的一部分,要保证输出的特征图高度为1,如果原有的VGG无法保证图片输入到输入恰好使得高为1,我们可以手动加一层卷积,特征图的宽此时变为50,相应的如果我们一开始resize输入的宽较大,这里的特征图的宽也会较大;这里的维度发生了一些变化,是为了便于输入到RNN以及后续ctcloss的调用,上图虚线可以看出,特征图的这个50可以认为是对应原图的50份纵向分割,也就是这张图片要被从左到右预测的次数,将其作为一个时序输入RNN,RNN一般使用双向LSTM网络,文章认为序列的前向信息和后向信息都有助于序列的预测,输出的时候,也就是RNN最后的嵌入层的输出维度为我们总共要预测的字符数+1(blank),最后的输出可以认为是一种概率,最后进行解码即可。
编解码过程
上述说到图像resize的宽在CNN输出的特征图的宽度对应了预测的时序,也就是我们挨着图像自左向右预测多少次,显然我们分隔的次数越多,就越不会漏掉其中某个字符,当然大多数情况下是预测多了的,比如图片中写的是”book“,我们的预测可能就是“bbbbbbooooooooooooookkkk”。还有就是我们的“book”作为标签如何去在网络的输出进行表示呢?当然是要做一个码本,将我们的字符用索引0-25表示。比如我们要预测26个英文字母,那“cat”就可以表示成[2,0,19],预测(序列长度为10)就可能是[2,2,2,0,0,0,0,19,19,19]或者[2,2,0,0,0,0,0,0,0,19]。问题来了,我们预测的输出是明显是多于实际标签的,中间的重复我怎么知道最后该保留一个还是多个呢,比如"book",如果按照上述规则得到的可是"bok"。
于是人们用一个占位符"-“来处理这个问题,用于解决到底留几个重复字符,注意,如果我们的预测中有"-"这个字符,要注意与占位符区别开,这和处理空格问题一样,在实际操作中可以使用其他符号暂时代替“-”或者空格进行码本制作,以避免码本无法表示,待解码之后统一替换即可。在编码的时候,所有的重复字符都要用”-“隔开,这样编码肯定是没有疑问了,解码的时候,凡是相同字符间没有”-"的,统统只要一个。将“-”放在码本的0号位,预测26个英文字符就用索引1-26表示,如果我们有输出[2,2,0,0,0,15,15,0,15,11],则解码为“book”,如果是[0,0,2,15,15,15,15,0,0,11],则解码为“bok”。
编解码的代码实现:
#编码过程,lexicon为字符标签,character为码本
label = [self.characters.find(c) for c in lexicon]
#解码过程,只解码一个输出列表,若解码矩阵,可分解出单个样本后进行调用
char_list = []
for i in range(len(str_index)):
if str_index[i] != 0 and (not (i > 0 and str_index[i - 1] == str_index[i])):
char_list.append(characters[str_index[i]])
return ''.join(char_list)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
CTCLoss与Pytorch实现
关于ctcloss,还是https://distill.pub/2017/ctc/写得最好,也是大部分博客的参考。前面我们说过RNN的输出为[50,1,11],也就是针对batch_size个样本,我们要对11(码本大小)个字符预测50(RNN输入时序长度)次,假设我们的输入为X,对应的标签为Y,每个时刻可能预测的字符用a表示,则每个时刻t在给定样本X的情况下预测字符a的概率为 p t ( a t ∣ X ) p_t(a_t|X) pt(at∣X),t个时刻的预测概率相乘是在给定样本X情况下预测标签Y的条件概率的一部分。
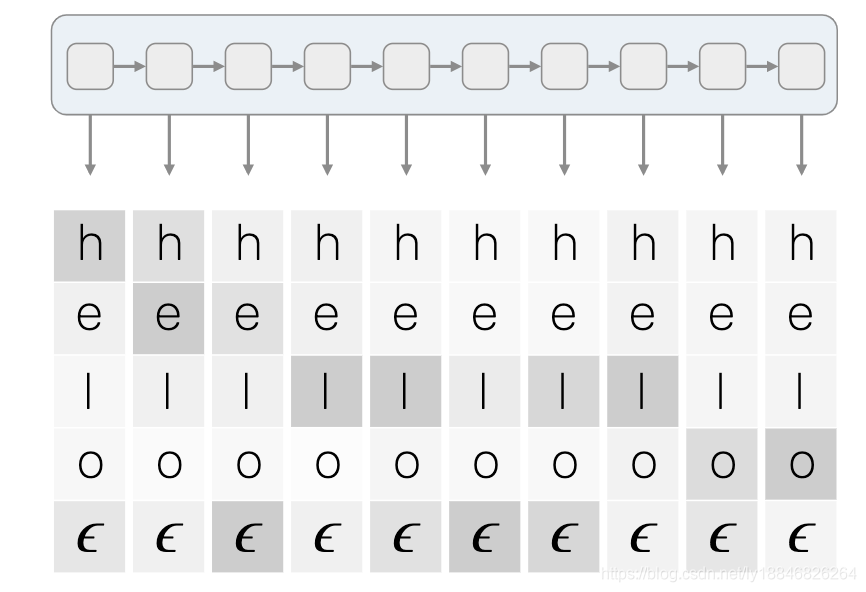
为什么说是一部分呢?因为,在这个阵列中,我们从左到右每个时刻取一个字符的话,在化简成最后的标签后,可以看到有多个path对应同一种标签,比如下面的三种路径就对应了同一个标签"hello":
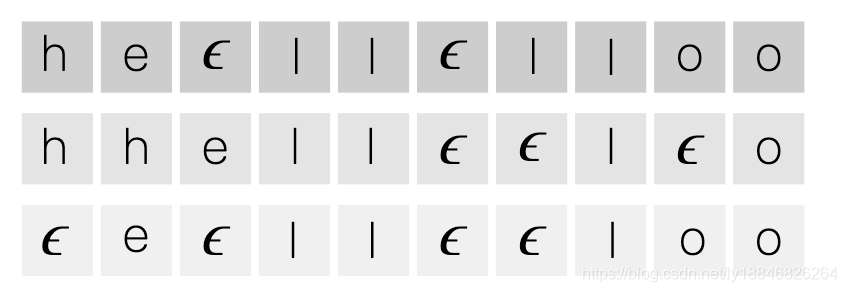
也就是说预测矩阵(概率)与标签是多对一的关系,每条路径对应了多个连乘积,要将这些连乘积加起来才能与某标签划等号,Deep System给出的示意图如下:
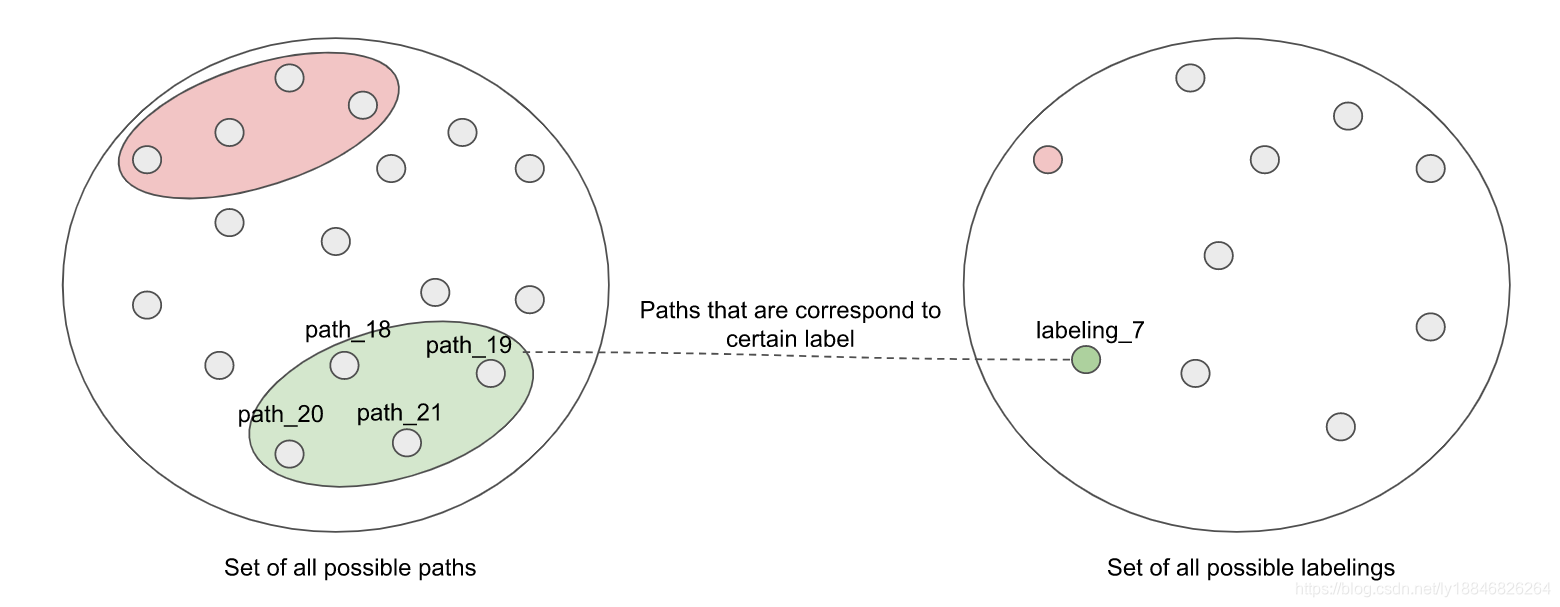
于是我们知道在给定某样本X,要得到标签Y的条件概率为
p
(
Y
∣
X
)
=
∑
A
∈
A
X
,
Y
∏
t
=
1
T
p
t
(
a
t
∣
X
)
p(Y \mid X)=\sum_{A \in \mathcal{A}_{X, Y}} \prod_{t=1}^{T} p_{t}\left(a_{t} \mid X\right)
p(Y∣X)=A∈AX,Y∑t=1∏Tpt(at∣X)
在训练时,我们当然希望输入样本X后,输出正确标签Y的概率越大越好,上式只涉及加法和乘法,显然是可导的,因此网络的损失就是
l
o
s
s
=
∑
(
X
,
Y
)
∈
D
−
log
p
(
Y
∣
X
)
loss = \sum_{(X, Y) \in \mathcal{D}}-\log p(Y \mid X)
loss=(X,Y)∈D∑−logp(Y∣X)
上图只显示了5个字符10个时间步长,我们如果罗列所有能得到“hello”的路径,也是个不小的工作量,到了更大的任务上这样直接计算概率是不现实的,因此,CTC使用了动态规划的思想来求解输出的条件概率。
这里只想简单介绍下在文本识别任务中我们的损失到底是如何得来的,关于CTC的动态规划,白话CTC算法讲解、CTC训练与公式推导、Sequence ModelingWith CTC、CTC Loss都有很好的讲解。
pytorch1.0之后自带CTCLoss,关于其使用方法,知乎大佬已有比较好的回答,但是也有童鞋在使用时遇到了一个问题,在一定epoch后nan住了,不知是不是一个bug,我在下一节附上了一个简单方法,亲测可用。pytorch给出了详细的使用方法,这里记录一下,便于日后查看。
ctc_loss = CTCLoss(blank=0, reduction='mean')
loss = ctc_loss(log_probs=out,
targets=labels,
target_lengths=target_lengths,
input_lengths=input_lengths)
- 1
- 2
- 3
- 4
- 5
- CTCLoss初始化:
blank:空白标签所在位置,默认为0,使用时根据自己的码本进行调整
Reduction:处理输出的方式,可选none ||mean || sum,默认为mean,将损失除以目标长度,然后去批次的均值
zero_infinit:是否将无限大损失和相关梯度归零,默认False
- 使用参数说明:
log_probs:[时序数,批次,含blank的类别数],这也是上图要将CNN的输出进行维度变换的主要原因,网络的输出也要先使用torch.nn.functional.log_softmax()进行处理才能送进函数中,在warp-ctc中则不必进行这一步
targets:[标签数],这里的targets使用带blank的码本编码即可,不比对重复的字符使用“-”进行隔开,batch之间首位相接即可,因为最后的参数已经标记了如何分隔开
input_lengths:[batch_size],记录网络预测的每个输出的长度,torch为了使用cudann,需要每个输入的长度等于RNN的时序数,如上图,都会是50
target_lenths:[batch_size],记录batch中每个标签的长度,用于分隔上述被串联起来的targets
可想而知,targets是没有插入“-”的,且在一个batch中是串联的,因此对一个batch而言,需要保证 i n p u t _ l e n g t h s ≥ 2 ∗ t a r g e t _ l e n g t h s + 1 input\_lengths \geq 2 * target\_lengths + 1 input_lengths≥2∗target_lengths+1,也就是要处理好RNN的时序数,也就是resize的图像的宽度。
CRNN实现
Pytorch 1.3.1 + CUDA 10.1实现
def val(net, test_iter, ctc_loss, max_iter=100, device=None): net.eval() loss_avg = 0.0 acc_val, n = 0, 0 start = time.time() for images, labels, target_lengths, input_lengths in test_iter: images = images.to(device) labels = labels.to(device) target_lengths = target_lengths.to(device) input_lengths = input_lengths.to(device) preds = net(images) cost = ctc_loss(log_probs=preds, targets=labels, target_lengths=target_lengths, input_lengths=input_lengths) loss_avg += cost n += preds.shape[1] _, preds = preds.max(2) output = decode_out(str_index=preds.transpose(1, 0), characters=args.characters) label = get_label(labels, target_lengths, args.characters) for ii in range(len(label)): assert len(output) == len(label) acc_val = acc_val + 1 if label[ii] == output[ii] else acc_val print("val loss: {} || val acc: {:.2f} || time:{:.4f}".format(loss_avg / max_iter, acc_val/n, time.time()-start)) net.train() def train(net, optimizer, train_iter, test_iter, device): ctc_loss = CTCLoss(blank=0, reduction='mean') net.train() print('Loading Dataset...') print("Begin training...") for epoch in range(args.max_epoch): start = time.time() acc_sum, n, batch_count = 0, 0, 0 for images, labels, target_lengths, input_lengths in train_iter: images = images.to(device) labels = labels.to(device) target_lengths = target_lengths.to(device) input_lengths = input_lengths.to(device) out = net(images) optimizer.zero_grad() loss = ctc_loss(log_probs=out, targets=labels, target_lengths=target_lengths, input_lengths=input_lengths) loss.backward() optimizer.step() batch_count += 1 n += out.shape[1] _, preds = out.max(2) output = decode_out(str_index=preds.transpose(1, 0), characters=args.characters) label = get_label(labels, target_lengths, args.characters) for ii in range(len(label)): assert len(output) == len(label) acc_sum = acc_sum + 1 if label[ii] == output[ii] else acc_sum print('Epoch:{}/{} || Batch:{} || Loss: {:.4f}|| Acc:{:.2f} || time: {:.4f} s'.format (epoch, args.max_epoch, batch_count, loss, acc_sum/n, time.time()-start)) val(net, test_iter, ctc_loss, device=device) torch.save(net.state_dict(), args.weights_save) print('Finished Training') if __name__ == '__main__': cudnn.benchmark = True transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225))]) trainSet = RegDataSet(dataset_root=args.dataset_root, anno_txt_path=args.train_anno, lexicon_path=args.lexicon_txt, target_size=(args.width, args.height), characters=args.characters, transform=transform) valSet = RegDataSet(dataset_root=args.dataset_root, anno_txt_path=args.val_anno, lexicon_path=args.lexicon_txt, target_size=(args.width, args.height), characters=args.characters, train=False, transform=transform) train_iter = DataLoader(trainSet, args.batch_size, shuffle=True, num_workers=args.num_workers, collate_fn=custom_collate_fn) test_iter = DataLoader(valSet, args.batch_size, shuffle=True, num_workers=args.num_workers, collate_fn=custom_collate_fn) net = CRNN(len(args.characters)) net = net.to(device) if args.pre_train: pretrained_dict = torch.load(os.path.join(args.weights_save_folder, "Final.pth")) model_dict = net.state_dict() pretrained_dict = {k: v for k, v in pretrained_dict.items() if k in model_dict} model_dict.update(pretrained_dict) net.load_state_dict(model_dict) # net.rnn[1].embedding = torch.nn.Linear(net.rnn[1].embedding.in_features, len(args.characters)) optimizer = torch.optim.Adam(net.parameters(), lr=args.initial_lr, weight_decay=args.weight_decay) train(net, optimizer, train_iter, test_iter, device)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
模型部分同Lin Yang:
class CRNN(nn.Module): def __init__(self, characters_classes, hidden=256, pretrain=True): super(CRNN, self).__init__() self.characters_class = characters_classes self.body = VGG() self.stage5 = nn.Conv2d(512, 512, kernel_size=(3, 2), padding=(1, 0)) self.hidden = hidden self.rnn = nn.Sequential(BidirectionalLSTM(512, self.hidden, self.hidden), BidirectionalLSTM(self.hidden, self.hidden, self.characters_class)) self.pretrain = pretrain if self.pretrain: import torchvision.models.vgg as vgg pre_net = vgg.vgg16(pretrained=True) pretrained_dict = pre_net.state_dict() model_dict = self.body.state_dict() pretrained_dict = {k: v for k, v in pretrained_dict.items() if k in model_dict} model_dict.update(pretrained_dict) self.body.load_state_dict(model_dict) for param in self.body.parameters(): param.requires_grad = False def forward(self, x): x = self.body(x) x = self.stage5(x) x = x.squeeze(3) x = x.permute(2, 0, 1).contiguous() x = self.rnn(x) x = F.log_softmax(x, dim=2) return x
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
CTCLoss出现nan或inf
一开始直接跑meijieru的代码,warp-ctc的输入不需要加log_softmax,因为版本问题最终还是使用了torch自带的CTCLoss,加了log_softmax,并使用自己处理的SVT数据集后,结果上来就是梯度nan,然后就是loss出现nan,导致一度怀疑torch自带的这个loss完全没有用,我真是太nan了。
后来受Lin Yang的启发,还是自己造个简单的数据集和网络从头验证比较好,数据集格式为MJSynth,一共160张合成的数字图片,足以验证CTCLoss是否收敛,在cnn或rnn预训练的情况下最后也能实现一定的准确率,数据集可以在BaiduYun下载。
后来回头验证到底为何刚开始出现上来就nan的问题时,改成使用自己制作的数据集,又遇到了loss在训练期间inf或nan的情况,但是通过强行变0解决了这一问题。二者的出现是因为某次计算的意外,因此直接置0,不影响之后的训练。
#在计算loss之后,梯度回传之前对loss进行处理,剔除坏的loss
if cost.item() == float('inf') or math.isnan(cost.item()):
cost.data = torch.tensor(0.0)
- 1
- 2
- 3
总结下来感觉一开始还是要从简单数据集和网络上进行调试,git别人的网络最好也是完全搞懂再进行个性化。
- 数据集存在脏数据,比如数据输入便存在
nan,可以开始的时候先使用简单网络进行剔除,另外最好一开始做归一化,或者在网络中加入BN - 针对CRNN来说,
CTCLoss的输入中要满足input_lengths比target_lengths的最长长度的两倍至少多1,这个可以通过调整最开始的输入图片的宽度来实现 - 学习率过大或batch_size较大,有种说法是ctcloss的学习率比平常要小很多,如果出现中间nan的时候,可以加入学习率调整或者开始的时候就设置较小的学习率,如果检查日志某层出现nan的时候,可以只调小该层的学习率
- 权重初始化如果只是简单的正态分布有时还是很容易出现这个问题的,可以尝试改用
xavier方法 - 抛开crnn的实现,nan的出现还可能是因为池化层中步长比卷积核的尺寸大,这个大家可以自己尝试一下。出处

