
Sora - 探索AI视频模型的无限可能-官方报告解读与思考_在训练过程中,sora先将视频数据压缩至一个低维潜在空间,然后利用扩散模型和变换神
赞
踩
一、引言
最近SORA火爆刷屏,我也忍不住找来官方报告分析了一下,本文将深入探讨OpenAI最新发布的Sora模型。Sora模型不仅仅是一个视频生成器,它代表了一种全新的数据驱动物理引擎,能够在虚拟世界中模拟现实世界的复杂现象。本文将重点分析Sora模型的创新之处,以及它是如何通过大规模数据训练和先进的算法技术,实现对视频内容的高质量生成。
Sora模型的出现,标志着AI在视频生成领域的一次重大飞跃。它不仅能够生成逼真的视频内容,还能够模拟物理世界中的物体运动和交互,这对于电影制作、游戏开发、虚拟现实以及未来可能的通用人工智能(AGI)研究都有着深远的影响。
文中将根据官方报告详细介绍Sora模型的架构、关键技术特点以及它在模拟数字世界中的应用。还将讨论Sora模型的训练过程,以及根据最近的一些论文推测一下可行性。

二、Sora模型概述
Sora模型是由OpenAI开发的一种先进的视频生成模型,它采用了扩散型变换器(diffusion transformer)架构,这是一种基于深度学习的模型,能够将随机噪声逐渐转化为有意义的图像或视频内容。Sora模型的核心在于其能够处理和生成具有复杂动态和空间关系的高质量视频,这在以往的视频生成技术中是难以实现的。
与传统的视频生成模型相比,Sora模型在以下几个方面展现出了显著的优势:
多模态输入处理:Sora能够理解和处理文本提示,将用户的描述转化为视频内容,这使得模型能够生成与用户意图高度一致的视频。
空间和时间的统一表示:通过将视频分解为时空补丁(Spacetime Patches),Sora模型能够在一个统一的框架下处理不同分辨率、持续时间和宽高比的视频,这大大增强了模型的灵活性和可扩展性。
大规模训练数据:Sora模型的训练基于大规模的视频数据集,这使得它能够学习到丰富的视觉和运动模式,从而生成更加逼真和多样化的视频内容。
物理世界模拟:Sora模型展现出了模拟物理世界的能力,例如,它能够生成具有连贯三维空间运动的视频,以及模拟物体之间的物理交互。
长期依赖关系处理:Sora模型能够有效地处理视频中的长期依赖关系,这对于生成连贯且具有逻辑性的视频内容至关重要。
三、关键技术特点
Sora模型的技术特点体现了其在视频生成领域的创新和突破。以下是Sora模型的一些关键技术亮点:
三维空间连贯性
动态相机运动:Sora能够生成包含动态相机运动的视频,这意味着视频中的人物和场景元素能够在三维空间中保持连贯的运动。例如,当相机移动或旋转时,视频中的物体会相应地改变位置,就像在现实世界中一样。
空间一致性:Sora能够确保视频中的物体在空间上保持一致性,即使在复杂的场景变换中也能保持正确的相对位置和运动轨迹。
模拟数字世界
Minecraft游戏模拟:Sora能够模拟人工过程,如视频游戏。通过提及“Minecraft”的提示,Sora能够零样本地激发其模拟游戏世界的能力,包括控制游戏中的角色和渲染游戏环境。
高保真渲染:Sora在模拟数字世界时,能够实现高保真的渲染效果,使得生成的视频内容看起来就像真实游戏画面一样。
长期连续性和物体持久性
角色和物体的一致性:Sora能够在视频中保持角色和物体的长期一致性,即使在视频中出现遮挡或离开画面的情况,Sora也能保持其存在和外观。
视频内容的连贯性:Sora能够生成具有连贯故事线的视频,确保视频中的事件和动作在时间上是连续的,没有突兀的跳跃。
与世界互动
简单影响行为模拟:Sora能够模拟一些简单的与世界互动的行为,如画家在画布上留下笔触,或者人物在吃食物时留下痕迹。这些行为不是预设的规则,而是模型通过学习大量数据后自然涌现的能力。
这些技术特点不仅展示了Sora模型在视频生成方面的高级能力,也预示着AI在理解和模拟复杂物理世界方面的巨大潜力。
四、训练过程与方法
Sora模型的训练过程是其技术实现的核心部分,涉及多种创新方法和策略,以确保模型能够学习和生成高质量的视频内容。以下是Sora模型训练的关键步骤和方法:
扩散型变换器模型(Diffusion Transformer)
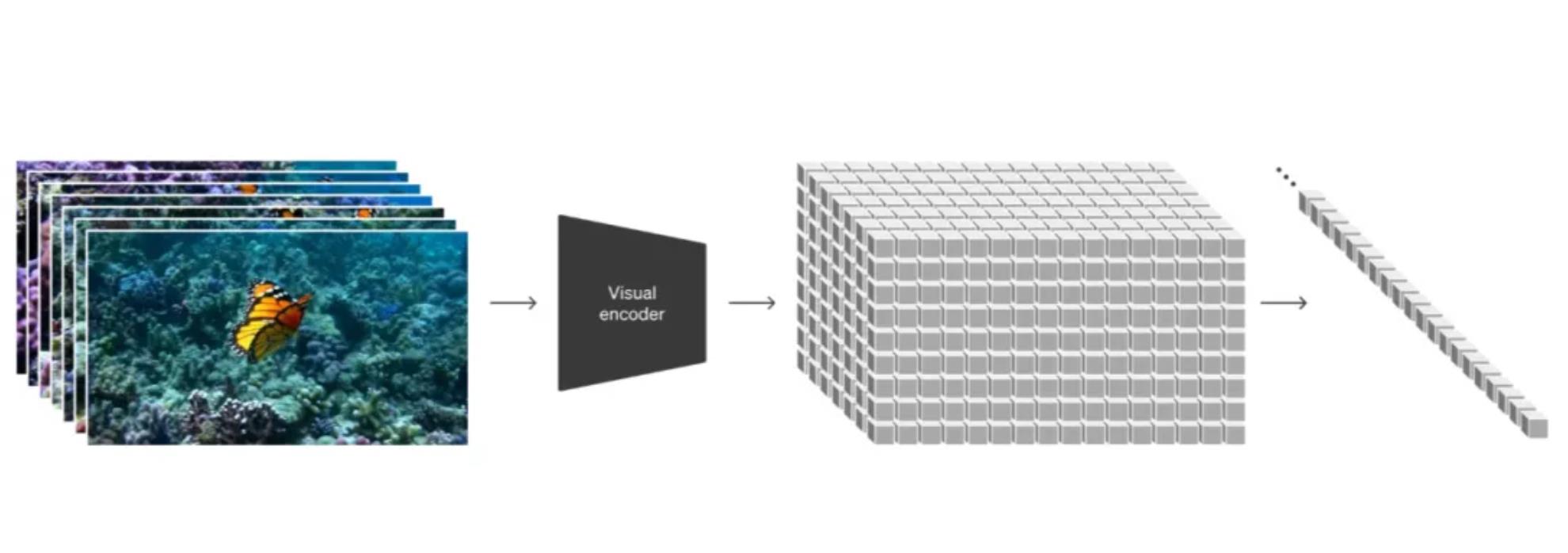
视频压缩与潜在空间:Sora模型首先将视频数据压缩到一个低维潜在空间,这个空间包含了视频的基本信息。在这个空间中,模型通过学习如何从噪声中恢复出清晰的视频内容,从而实现视频生成。
时空补丁(Spacetime Patches):视频被分解为一系列时空补丁,这些补丁在变换器模型中充当标记(tokens)。这种表示方法允许模型处理不同分辨率、持续时间和纵横比的视频和图像。
训练网络与解码器
视觉数据维度降低:Sora训练了一个网络,该网络将原始视频输入并输出在时间和空间上压缩的潜在表示。同时,还训练了一个解码器模型,将生成的潜在表示映射回像素空间,从而生成视频。
大规模训练:Sora模型在大规模数据集上进行训练,这些数据集包含了多样化的视频内容和相应的文本描述。这种大规模训练使得模型能够学习到丰富的视觉和运动模式。
语言理解与字幕生成
重字幕技术:Sora利用了DALL·E 3中的重字幕技术,为训练集中的所有视频生成高度描述性的文本字幕。这提高了视频内容的文本保真度,使得生成的视频更加符合用户的描述。
GPT技术应用:Sora还利用了GPT技术,将用户的简短提示转换成更详细的字幕,然后发送给视频模型。这使得Sora能够更准确地遵循用户的意图生成视频。
可变持续时间与分辨率训练
原生纵横比支持:Sora在训练时没有对素材进行裁剪,而是直接在原始大小的数据上进行训练。这使得Sora能够直接为其原生纵横比为不同设备创建内容,提高了构图和取景的质量。
涌现模拟能力
大规模训练的成果:随着训练计算量的增加,Sora展现出了三维一致性、长序列连贯性和物体持久性等新能力。这些能力是模型在大规模训练后自然涌现的,而非通过预设规则实现。
这些内容是根据官方报告给出的,但是事实上的这些描述并没有细化到可以作为方法论层面的操作解释。最多只能作为一个方向性的阐述,有点像大概描述的步骤。颇有售前工程师忽悠甲方的味道。不过,OpenAI的牌子在,还是让人不得不仔细地思考与讨论。正好最近扫过一篇论文,标题是《WORLD MODEL ON MILLION-LENGTH VIDEO AND LANGUAGE WITH RINGATTENTION》,作者是Hao Liu、Wilson Yan、Matei Zaharia和Pieter Abbeel,来自加州大学伯克利分校。详细地阐述了一个7B参数的长视频与环形注意力的多模态大模型训练方法。如果Sora能够有这样的论文披露,那么可能我们的讨论与思考会更有效一些。
五、应用场景与潜力
Sora模型的应用场景广泛,其潜力在于能够为多个行业带来革命性的变化。以下是Sora模型的一些潜在应用:
电影与娱乐产业:
特效制作:Sora可以用于生成逼真的特效场景,减少对实际拍摄和后期制作的依赖,降低成本。
故事板与预览:导演和制片人可以利用Sora快速生成电影场景的预览,帮助决策和创意发展。
游戏开发:
游戏内容生成:Sora能够为游戏开发者提供丰富的视觉素材,加速游戏内容的创作过程。
交互式故事讲述:在角色扮演游戏(RPG)中,Sora可以生成与玩家互动的动态视频,增强游戏体验。
教育与培训:
模拟训练:Sora可以生成各种模拟场景,用于医学、军事、航空等领域的专业培训。
语言学习:通过生成与语言学习相关的视频内容,Sora可以帮助学习者更好地理解和记忆新词汇和语法。
广告与营销:
创意内容生成:Sora可以快速生成吸引人的广告视频,帮助品牌在竞争激烈的市场中脱颖而出。
个性化营销:利用Sora生成定制化的视频内容,满足不同用户群体的需求。
虚拟现实(VR)与增强现实(AR):
虚拟环境构建:Sora可以为VR和AR应用生成逼真的虚拟环境,提供沉浸式体验。
交互式内容:在AR应用中,Sora可以生成与现实世界互动的视频内容,增强用户体验。
科学研究与模拟:
物理模拟:Sora可以用于模拟复杂的物理现象,如流体动力学、天体运动等,辅助科学研究。
历史重现:通过生成历史事件的视频,Sora可以帮助学者和公众更好地理解历史。
Sora模型的潜力在于其能够模拟和生成多样化、高质量的视频内容,这为创意产业、教育、科研等领域提供了新的可能性。随着技术的不断进步,Sora模型的应用范围将不断扩大,为人类社会带来更多的便利和创新。
六、局限性与未来展望
Sora模型虽然在视频生成领域取得了显著的进展,但它仍然存在一些局限性,这些局限性主要体现在以下几个方面:
物理交互的准确性:尽管Sora能够模拟一些基本的物理交互,如物体的运动和相机的移动,但它在处理更复杂的物理现象时可能会遇到困难。例如,模型可能无法准确模拟玻璃破碎、液体流动等复杂物理过程。
长期依赖关系的处理:在生成长视频时,Sora可能在保持时间上的一致性和逻辑性方面存在挑战。这可能导致视频中出现不连贯的事件或者物体状态的突变。
空间细节的精确性:Sora在处理空间细节方面可能不够精确,例如在区分左右或者描述随时间变化的事件时可能会出现错误。这可能影响到视频内容的准确性和可信度。
模型的可解释性:Sora模型的内部工作机制相对复杂,这使得理解模型如何生成特定视频内容变得困难。提高模型的可解释性对于其在关键领域的应用至关重要。
计算资源的需求:Sora模型的训练和运行需要大量的计算资源,这限制了其在资源有限环境下的应用。特别是在实时视频生成或移动设备上的应用,计算资源的需求可能成为一个瓶颈。
数据偏差和伦理问题:Sora模型的训练数据可能存在偏差,这可能导致生成的视频内容反映出这些偏差。此外,生成的视频可能被用于不道德或有害的目的,如制造虚假新闻或误导性内容。
创意和艺术表达的限制:虽然Sora能够根据文本提示生成视频,但它可能无法完全捕捉到人类艺术家的创意和情感表达。在艺术创作领域,AI生成的内容可能缺乏深度和个性化。
交互性和反馈:Sora模型目前主要侧重于单向的视频生成,缺乏与用户交互和根据反馈进行调整的能力。这限制了模型在需要实时互动和个性化定制的应用场景中的潜力。
为了克服这些局限性,未来的研究需要在提高物理模拟的准确性、增强长期依赖关系的处理能力、优化计算效率、提高模型可解释性、处理数据偏差以及增强交互性等方面进行深入探索。随着技术的不断进步,Sora模型有望在视频生成领域实现更多的突破。
七、结论与分析
Sora模型作为OpenAI在视频生成领域的一次重要尝试,展示了AI在理解和模拟复杂视觉内容方面的巨大潜力。它的出现不仅为视频内容创作提供了新工具,也为AI技术在其他领域的应用提供了新思路。随着技术的不断进步,可以期待Sora模型能够克服现有局限性,为人类社会带来更多的创新和价值。
根据官方报告展示出来的Sora特性,尤其是对于三维空间连贯性,延伸思考一下就会有些问题。
报告解读中Sora模型确实展现出了三维空间连贯性的能力,这意味着它能够生成具有正确空间关系和动态相机运动的视频内容。然而,这并不意味着Sora模型可以直接生成三维建模软件中使用的参数。Sora模型的主要目标是生成二维视频帧,而不是直接创建三维模型的参数。
尽管Sora能够模拟三维空间中的物体运动和相机视角变化,但它生成的仍然是视频序列,这些视频序列在视觉上呈现出三维效果,但实际上仍然是二维图像序列。在这些视频中,物体和场景元素的三维位置和运动是通过二维图像的连续变化来模拟的,而不是通过实际的三维模型数据。要生成三维建模的参数,通常需要使用专门的三维建模软件,如Blender、Maya或3ds Max等,这些软件能够创建和编辑三维对象、场景和动画。在这些软件中,用户可以精确地定义物体的形状、纹理、材质以及在三维空间中的位置和运动轨迹。
当然,Sora模型的三维空间连贯性能力还是为未来可能的三维内容生成提供了有趣的研究方向。例如,研究者可以探索如何将Sora模型与三维建模软件结合,利用Sora生成的二维视频帧作为参考,辅助三维模型的创建和动画制作。这样的结合可能会简化三维内容的创作过程,提高效率,并为艺术家和设计师提供新的创作工具。
但是对于二维视频的仿3D形态,这又需要进行复杂的真实性校验。就好像盗梦空间里的视角无法平移到真实世界中去一样。所以这个世界模拟器的局限性还是挺明显的。这一点,单纯依赖视频和语料的模态组合可能很难有突破,如果采用真三维的点云数据也许是个不错的方向。
还有,就是关于世界模拟器和世界模型的辨析。世界模型的设计需要有客观的角度,将大模型作为具身形态在其中进行交互,进而形成接近于真实的训练学习过程。而世界模拟器,仅仅是模拟视频反馈,并通过大量语料结合反馈闭环。这样的体系也许还需要像我之前列出的那篇世界模型多模态训练的论文一样,做出更多的基础工作。但不管怎样,我都不希望Sora像Gemini的官方报告一样事后出现反转。这是OpenAI的一小步,却真的有可能是人类的一大步……
参考文献
SORA的官方报告解读与思考:SORA的官方报告解读与思考_风闻
以上内容仅代表个人的一些看法与观点。

