
- 1EHCI和OHCI,UHCI的比较和区别_ehci ohci uhci
- 2YOLOv3,YOLOv4学习_yolov3_cspdarknet_fpn
- 3自然语言处理NLP知识结构_自然语言处理功能模块结构图
- 4六何时适合使用蜻蜓优化算法?_蜻蜓优化算法应用领域
- 5【LSTM分类】基于鲸鱼算法优化空间注意力机制的卷积神经网络结合长短记忆神经网络KOA-CNN-LSTM-SAM-attention实现数据分类附matlab代码
- 6关于Clang
- 7【Phase One SDK】飞思相机SDK的环境配置及调用_phase one linux sdk
- 8小程序源码免费html5,微信小程序静态页面案例(附源码)
- 9Python数据分析,pandas对日期的处理_python记录不同年相同月份的数据
- 10分类和标注词汇(基于nltk)_nltk区分场景类名词和目标类名词
基于attention的seq2seq机器翻译实践详解_attention seq2seq中文翻译
赞
踩
理理思路
-
文本处理,这里我是以eng_fra的文本为例,每行是english[tab]french,以tab键分割。获取文本,清洗。
-
分别建立字典,一个english,一个french。
-
根据字典写好seq2id的函数(文本序列->数字序列),并调用将文本序列化。
-
初始化Encoder,Decoder模型;选择合适的优化器;设置lr,epochs等参数;
-
开始循环迭代:
1.因为文本太大,这里是随机选择某句进行训练。
2.句子通过Encoder,Encoder产生新的隐层和每层的输出;再将开始标志<SOS>通过传给Decoder结合Encoder的隐层和每层的输出(期间用到attention,下面详细讲解)产生新的预测值;这个预测值将循环替代刚才的<SOS>也就是作为上一轮的输入,继续预测,直到预测出现结束符<EOS>或者达到自己规定预定长度结束。
3.对损失链式求导,更新参数。
-
评估模型:因为Encoder和Decoder是训练好的,将选取的数据像上面的循环中的一样产生结果序列,对结果序列和真实序列进行比较。
文本处理,建立字典,seq2id就不用说了,这个是一般的神经网络自然语言处理必须经过的步骤。下面我来根据我的理解讲下剩下的部分,其中着重讲解Encoder,Attention,Decoder模型及过程。
Encoder
这个其实简单,我们先回忆下这个流程图:
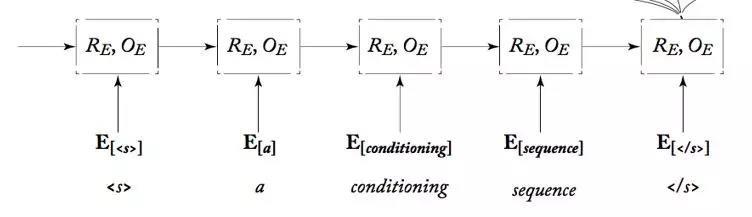
可以看出这个就是简单的RNN,和平常的RNN做的分类任务是一样的,只不过之前的RNN我们需要的只是最后隐层,而这次我们需要它的每一个时间点的输出,即:
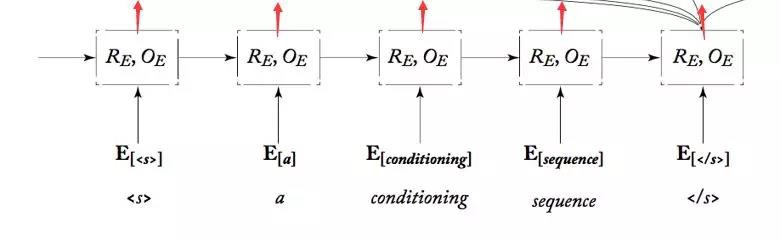
红色箭头所标。原因是为了实现attention机制,下面会讲具体的attention实现。现在该看我们的Encoder模型的代码啦!
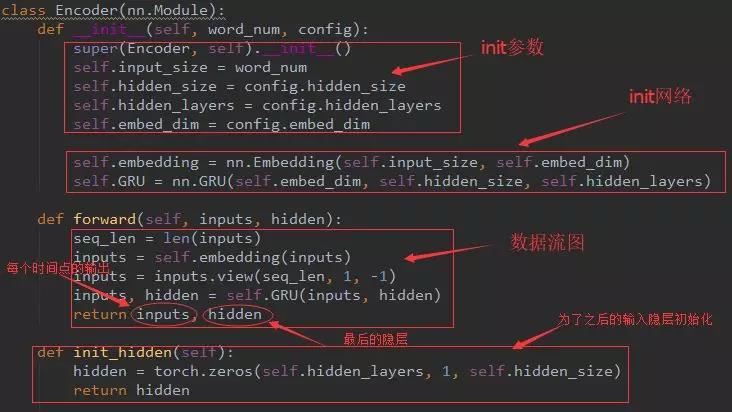
细节如图所示。这里网络就两个一个Embeddng层,一个网络GRU。forward的数据流图也就是输入的是词和上一次的隐层hidden如果当前是第一次,则通过下面的init_hidden函数初始化一个hidden。然后词经过Embedding后,通过GRU产生一个每个时间点的输出列表inputs和最后的隐层hidden。
train运行代码为:

然后就是Decoder了,Decoder暂时我知道的有两种,分别为Bahdanau et al. model和Luong et al. model。下面按照难易理解顺序我先讲Bahdanau et al. model,然后讲Luong et al. model。
Bahdanau et al. model
这个就是我之前刚讲的那个模型,我们先来看图:
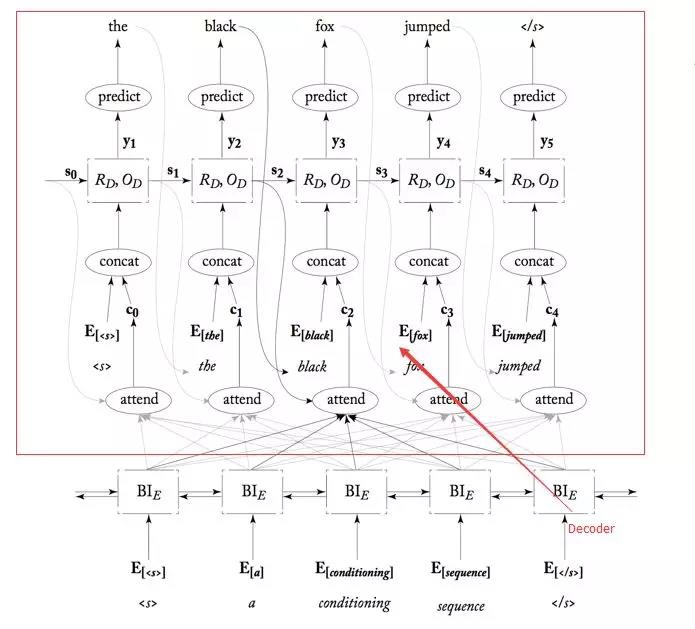
上面的这个就是基于attention的Decoder模型。我们先根据模型来慢慢的梳理我们的网络模型。
首先得需要Embedding层来完成数据输入;然后很明显需要一个GRU网络来预测词和产生接下来的隐层;而GRU由图来看得需要attention网络来评分;而GRU预测词又需要有线性层来映射到分类上,因此又多了两个网络层。总共4个网络。我们来看下代码:
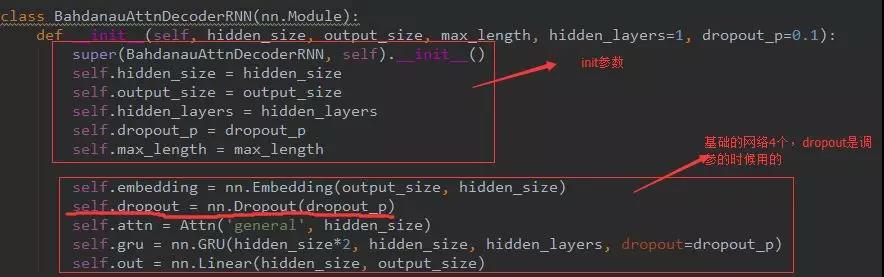
这里的attention网络我一会说的。继续,我们看着下面这个图来说接下来的数据流图。
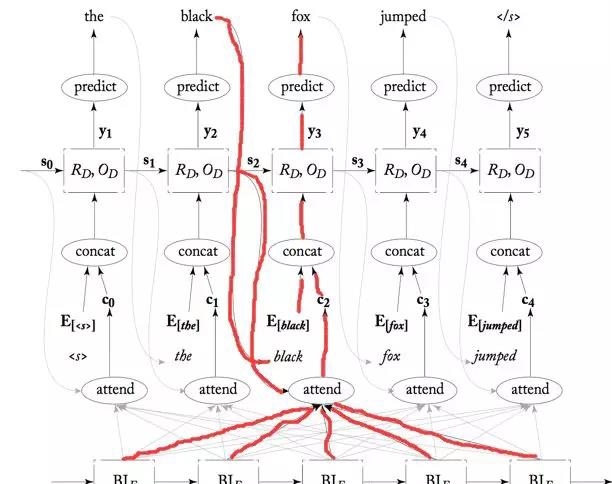
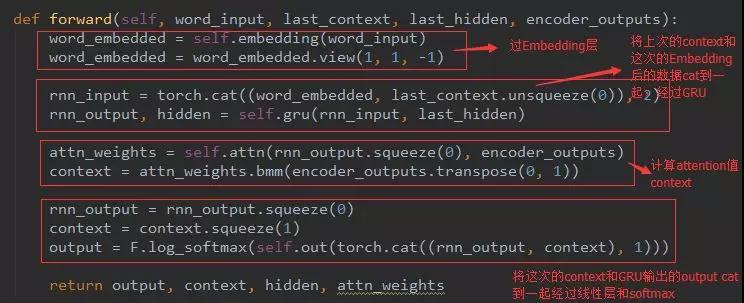
从下往上看,首先是attention根据每个Encoder输出和Decoder的上一次隐层给出每个边的得分,然后和上一次训练的预测值Embedding后cat到一起,和Decoder它的上一个时刻的隐层作为输入进入此刻的GRU,然后输出的时候就跟这个图有点差异了(应该是地方太小,图的主人画不下了吧):这个时候产生的output像我们那样,应该直接把output经过线性层输出分类了;而这个是讲output和刚才的那个attention又cat到了一起再经过线性层映射到目标语言的词典上。(应该是这样会是准确度更高吧,只是猜测。)最后再将线性层softmax下,得到具体的词。就是这么个结果,我们来看下代码吧:
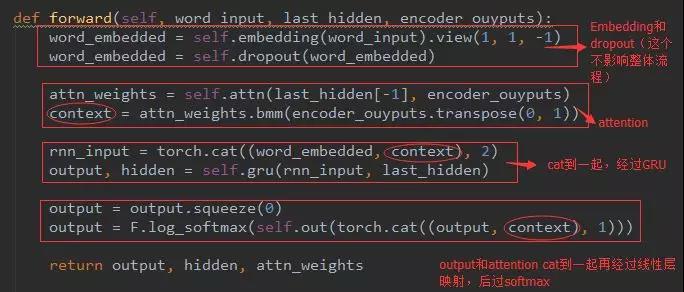
context的命名来源是上下文的意思,因为attention就是为了关系到上下文而又不缺失本身的侧重点。
而我用的是接下来的这个Decoder,听我详细讲解,其实和上面的这个Decoder基本相似。
Luong et al. model
这个模型和上面的差不多,就是数据流通顺序有点差异和context使用有点不同。
首先这个网络和上面的是一样的。都是4个,分别为:Embedding层,attention层,GRU层,线性层。
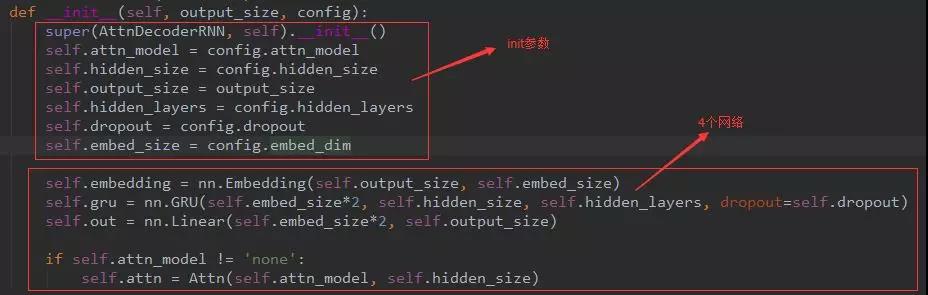
不同的是下面的流程:
这里是用到了上一时刻的context(attention值)和上一次预测的词Embedding后cat到一起,经过GRU的。然后和上面的一样了,再计算此次的context(attention值)并和此次的GRU输出的output cat到一起经过线性层然后softmax得出预测值。
代码为:
我们来看看这个在train的运行过程:

这个过程首先它的结束标志是标准预测序列的长度,但也可以是遇到结束符<EOS>。其次,我们看出这里用的loss评价指标是我们的最普通的那种和target比较得出loss,而没有用到BLEU评价算法。
attention
终于到了我们的attention了,坚持住!
首先我们要知道这个是为了给每个Encoder的output计算权重。其中计算每个权重的score有三种方法:
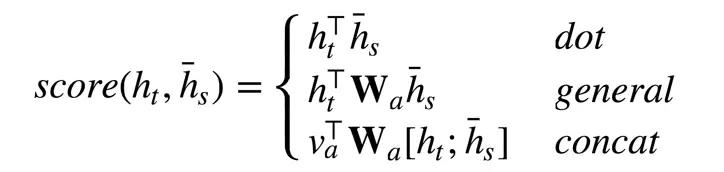
分别为:dot方法,general方法,concat方法。其中h_t是Encoder第t个output,此时的目标是预测Decoder的第t个词。h_s是Encoder的当前隐层。
很明显通过这个公式,我们知道:
如果是dot方法,只需要参数encoder_hidden和output_t即可;如果是general方法,就需要output_t经过一个线性层(因为线性层里只有个W,当然b另说,无伤大雅)和encoder_hidden dot下就行了;下面的cat方法就也很明显了,重点是哪个v_a,这个是一个参数,可以进行更新的参数,刚开始可随机初始化。无论用哪个方法,我们最后都得softmax下,算出相对的权重。
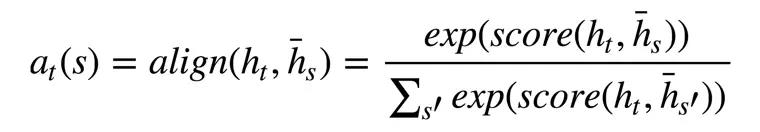
这个的整个流程图是这样的:

我们来看看这个代码:
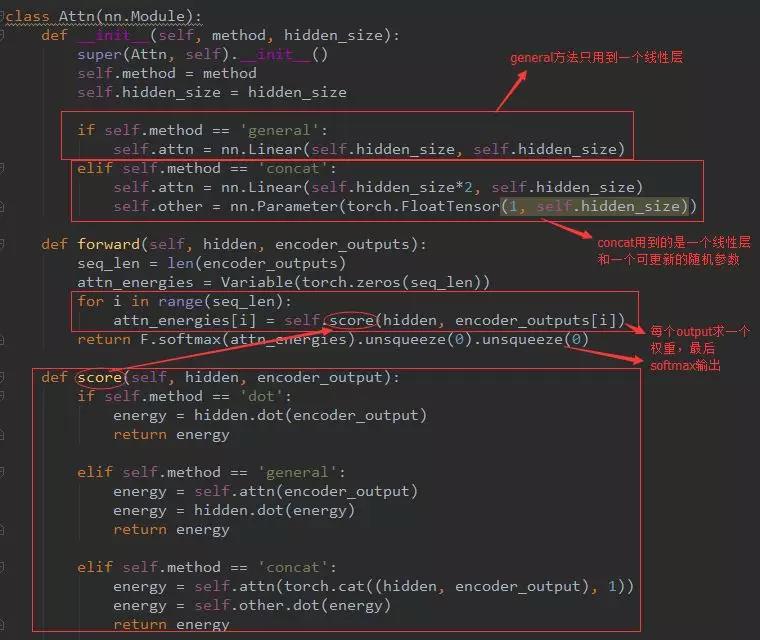
上面解释很详细,应该能看懂的。
下面来介绍一个teacher_forcing方法以及teacher_forcing_ratio的用途。
teacher_forcing
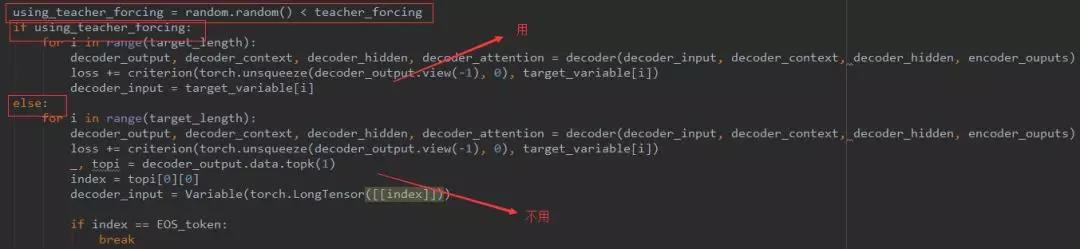
我们在Decoder预测的时候,都是用到上一次预测的结果,一般情况下,在预测的前几轮都是不正确的,也就是说前面的预测本来就不正确,后面根据前面的结果再预测就是错上加错了。所以,为了加快模型训练的速度,我们引入teacher_forcing方法。很简单,就是在前几轮不管之前预测的结果,此次要用到的前面的词为真正的target词,代码为:

然而,我们有时候并不知道到底前面多少轮用到teacher_forcing,又是从什么时候开始不用的呢?后来我们又提出了teacher_forcing_ratio比率{0-1之间}。就是有teacher_forcing_ratio的几率我们用到teacher_forcing方法。实现为:
更新
这就没什么好讲的了,上代码吧:
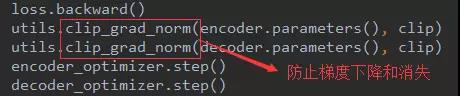
上面的懂了,评估的也就不用讲了。
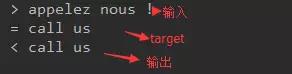
结果显示
不足以及今后的安排
不足:
-
Encoder应该用到的是biGRU,而我的是单向GRU
-
loss计算方法没有用到BLEU
-
没有将另一种Decoder放入train中
安排:
-
将上面的不足实现了
-
调参得出最佳精确度
-
得出不加attention的精确度,作对比
感谢哈工大的资料以及实验室余南师兄和宋阳师姐的指点!
更多精彩内容,请关注 深度学习自然语言处理 公众号,就是下方啦!跟随小博主,每天进步一丢丢!哈哈!


