
- 1HTML简易的用户名密码登录页面_艾孜尔江撰_简单账号密码登陆页面html代码
- 2vue-router 路由跳转传参刷新页面后参数丢失问题_vue跳转后路由刷新浏览器参刷新页面参数丢失
- 3HCIA实验,华为ensp基础实验。_[r1]aaa [r1-aaa]local-user huawei password cipher
- 4微服务容器化如何实现顺序启动_微服务依次启动
- 5关于Airtest的使用探索
- 6批量更改图片名称_批量修改图片名称
- 7CentOS6上编译OpenSSH为Rpm包并升级到新版本_centos6.9 openssh rpm
- 8CHAPTER 1:Numerical Techniques 第一章:数值运算技术_ntnyn
- 9windows insightface库 人脸识别入门教程_insightface教程
- 10Linux gcc g++ 编译C++程序_g++编译c++的阶乘程序
深入玩转Playwright:高级操作解析与实践_playwright chromium 设置窗口位置
赞
踩
playwright高级操作
iframe切换
很多时候,网页可能是网页嵌套网页,就是存在不止一个html标签,这时候我们的selenium或者playwright一般来说定位不到,为什么呢?
因为默认是定位到第一个标准的html标签内部。
from playwright.sync_api import sync_playwright
p = sync_playwright().start()
browser = p.chromium.launch(headless=False)
page = browser.new_page()
page.goto("https://cdn2.byhy.net/files/selenium/sample2.html")
lcs = page.locator('.plant').all()
for lc in lcs:
print(lc.inner_text(timeout=1000))# 默认是等30s,我们修改为1s
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
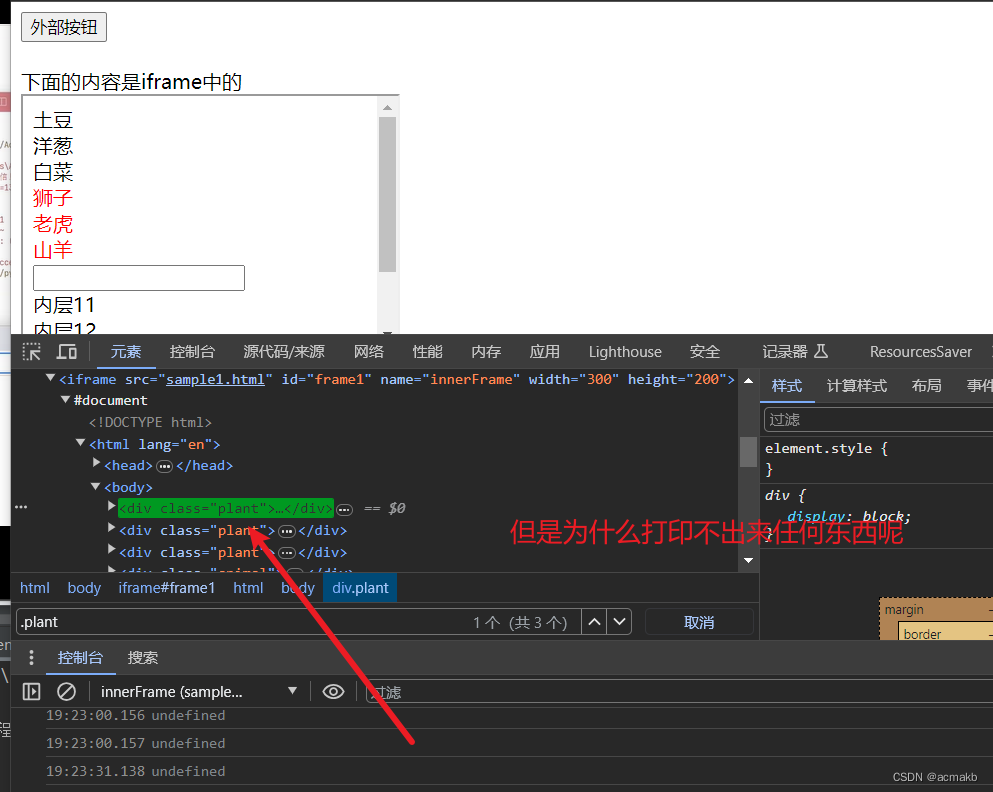
接下来我们好好分析一下这个网页结构,发现存在一个iframe标签,有过前端开发基础的同学应该能看出来了,就是实现了网页的嵌套。
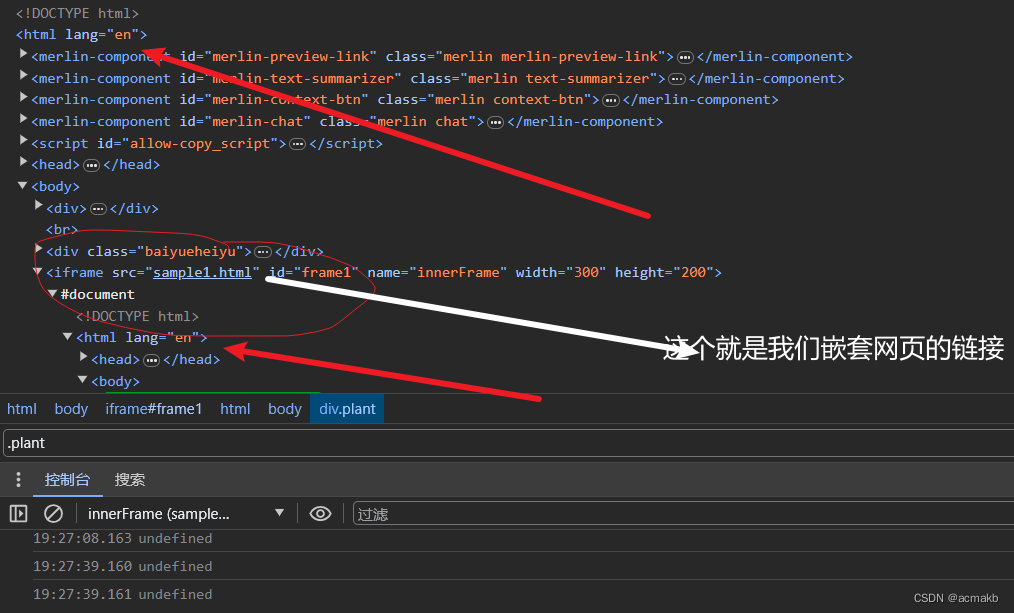
但是我们需要的内容,在 这个iframe标签中,所以需要切换到其中。
可以使用 Page 或者 Locator 对象的 frame_locator 方法定位到你要操作的frame。
- frame_locator() - 帧定位器 |剧作家 Python — FrameLocator | Playwright Python
使用 iframe 时,您可以创建一个帧定位器,该定位器将进入 iframe 并允许选择该 iframe 中的元素。
# selector 为css选择器或者xpath选择器
frame_locator.frame_locator(selector)
- 1
- 2
现在我们对上面的案例进行修改:
from playwright.sync_api import sync_playwright
p = sync_playwright().start()
browser = p.chromium.launch(headless=False)
page = browser.new_page()
page.goto("https://cdn2.byhy.net/files/selenium/sample2.html")
#------------------修改的代码------------------------------------
# 产生一个 FrameLocator 对象
frame = page.frame_locator("iframe[src='sample1.html']")
# 再 在其内部进行定位
lcs = frame.locator('.plant').all()
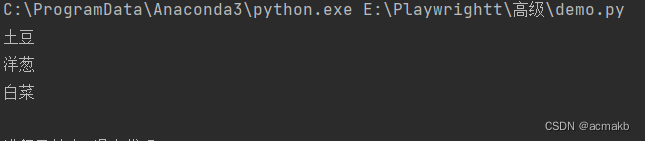
for lc in lcs:
print(lc.inner_text(timeout=2000))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
窗口切换:
在playwright的使用过程中,可能会涉及不同页面的切换,则会使用需要BrowserContext 来切换浏览器对象的上下文,不然你获取的对象还是之前的。
from playwright.sync_api import sync_playwright
p = sync_playwright().start()
browser = p.chromium.launch(headless=False)
page = browser.new_page()
page.goto("https://cdn2.byhy.net/files/selenium/sample3.html")
# 点击链接,打开新窗口 会切换到bing
page.locator("a").click()
# 打印网页窗口标题
print(page.title())
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
但是显然结果并没有发生变化,这是因为上下文对象没有变化。
from playwright.sync_api import sync_playwright pw = sync_playwright().start() browser = pw.chromium.launch(headless=False) # 创建 BrowserContext 对象 context = browser.new_context() # 通过context 创建page page = context.new_page() page.goto("https://cdn2.byhy.net/files/selenium/sample3.html") # 点击链接,打开新窗口 page.locator("a").click() # 等待2秒, 不能用 time.sleep page.wait_for_timeout(2000) # pages属性是 所有窗口对应Page对象的列表 newPage = context.pages[1] # 打印新网页窗口标题 print(newPage.title()) # 打印老网页窗口标题 print(page.title()) print(context.pages)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
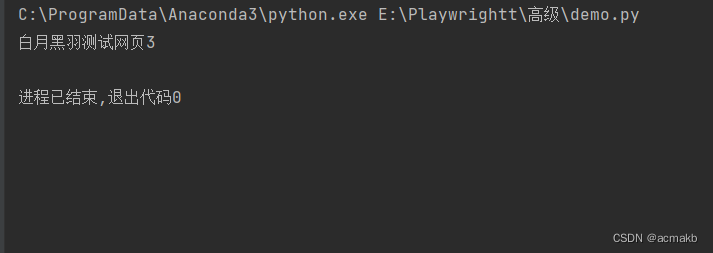
结果:
必应
白月黑羽测试网页3
[<Page url='https://cdn2.byhy.net/files/selenium/sample3.html'>, <Page url='https://cn.bing.com/'>]
- 1
- 2
- 3
BrowserContext 对象有个 pages 属性,这是一个列表,里面依次为所有窗口对应Page对象。
关闭网页:
Browser对象有close 方法,可以实现关闭整个浏览器。
如果只是要关闭某个网页窗口,可以调用该窗口对应的Page对象的 close 方法。
page.close()
page.close(**kwargs)
- 1
- 2
移动网页:
假如我们有多个网页,但是想切换某个网页到最前面,需要怎么设置呢?
将页面放在前面(TAB):
page.bring_to_front()
- 1
固定界面:
定时器+debugger 执行js代码:卡住页面
setTimeout(function(){debugger}, 5000)
- 1
截屏:
playwright和selenium都可以实现截屏,当然这个方法主要用于验证码,将图片交给第三方打码平台然后就可以实现滑块,点选等等。
网页截屏:
# 窗口大小
page.screenshot(path='ss1.png')
# 截屏完整页面,页面内容长度超过窗口高度时,包括不可见部分,包括滑动。
page.screenshot(path='ss1.png', full_page=True)
- 1
- 2
- 3
- 4
- 5
当然也可以对某个部分进行截图:
tag=page.locator('input[type=file]')
tag.screenshot(path='ss2.png')
- 1
- 2
拖拽:
- drag_and_drop()
相关参数:
- source 用于搜索要拖动的元素的选择器
- target 用于搜索要拖放到的元素的选择器
- source_position 此时单击源元素相对于元素填充框的左上角
- target_position 相对于元素填充框的左上角,在目标元素上放置
此方法将源元素拖动到目标元素。它将首先移动到源元素,执行 , mousedown 然后移动到目标元素并执行 mouseup .
page.drag_and_drop("#source", "#target")
# or specify exact positions relative to the top-left corners of the elements:
page.drag_and_drop(
"#source",
"#target",
source_position={"x": 34, "y": 7},
target_position={"x": 10, "y": 20}
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
drag_to(target)
相关参数文档:https://playwright.dev/python/docs/api/class-locator#locator-drag-to
# 选中 `span#t1` 文本内容
page.locator('#t1').select_text()
# 拖拽到 输入框 `[placeholder="captcha"]` 里面去
page.drag_and_drop('#t1', '[placeholder="captcha"]')
- 1
- 2
- 3
- 4
还有一种就是已经定位到某个对象了,这时候可以不使用page对象来进行操控:
source = page.locator("#source")
target = page.locator("#target")
source.drag_to(target)
# or specify exact positions relative to the top-left corners of the elements:
source.drag_to(
target,
source_position={"x": 34, "y": 7},
target_position={"x": 10, "y": 20}
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
# 选中 `span#t1` 文本内容
lc = page.locator('#t1')
lc.select_text()
# 拖拽到 输入框 `[placeholder="captcha"]` 里面去
lc.drag_to(page.locator('[placeholder="captcha"]'))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
总结:
在本文中,我们深入探索了Playwright的高级操作。我们学习了如何在应用中切换iframe,以及如何处理多个窗口的切换。我们还了解了如何关闭网页和移动网页位置,以及如何固定界面,以便进行更精确的测试。此外,我们还学习了如何使用Playwright进行屏幕截图和拖拽操作。
通过掌握这些高级操作,我们可以更好地利用Playwright的强大功能来自动化测试和模拟用户交互。这些技巧可以帮助我们处理各种复杂的场景,例如在应用中嵌套的iframe、多个窗口之间的切换以及拖拽操作。
Playwright的灵活性和易用性使其成为一个强大的自动化测试工具。通过学习并掌握这些高级操作,我们可以更好地利用Playwright的功能,提高测试效率和准确性。
希望本文对你了解和应用Playwright的高级操作有所帮助,并能够在你的测试工作中发挥作用。
温馨提示:
整理源于:快速上手 | 白月黑羽 (byhy.net),如有侵权,请及时联系删除!

