
- 1Python中函数的参数定义和可变参数_python函数中的可变参数
- 2C++之最短路径算法(Dijkstra)_c++ 最短路径
- 3Android O 前期预研之二:HIDL相关介绍_export_generated_headers androidbp
- 4sqlserver 查询数据字段末尾存在空格 用等于号也会命中_sqlserver where 有空格和没空格
- 5已经会用stm32做各种小东西了,下一步学什么,研究stm32的内部吗?
- 6疲劳驾驶样本集_开车犯困怎么办?用TF机器学习制作疲劳检测系统
- 7Java实现WebSocket_java原生websocket的源码
- 8Android Studio中运行Android模拟器_android studio怎么运行模拟器
- 9android10.0(Q) 后台启动Activity白名单_background activity start [callingpackage:
- 10鸿蒙Harmony-数据持久化(Preferences)详解_鸿蒙preferences
【论文笔记】基于深度强化学习的室内视觉局部路径规划_深度强化学习 路径规划
赞
踩
摘要
【针对问题】传统的机器人局部路径规划方法多为已有先验地图的情况设计 → \rightarrow → 与视觉 SLAM 结合的导航中效果 不佳
【提出方法】一种基于深度强化学习的视觉局部路径规划策略
【具体细节】(1)使用视觉SLAM → \rightarrow → 栅格地图;全局路径规划 → \rightarrow → A ∗ A^{\ast} A∗算法(2)构建基于深度强化学习的局部路径规划策略,动作 → \rightarrow → 前进、左转、右转,作为动作集合的基本元素;状态 → \rightarrow → 视觉观测 → \rightarrow → 彩色图、深度图和特征点图,以及当前位置到局部目标点的位移矢量; (3)学习和探索 → \rightarrow → 近端策略优化算法(PPO)
【实现效果】仿真实验;成功率提高,位姿跟踪丢失率和碰撞率减小;
关键词
- 视觉导航;
- 深度学习;
- 强化学习;
- 局部路径规划;
- 避障;
- 视觉 SLAM;
- 近端策略优化;
- 移动机器人;
0 引言
(1) 路径规划
- 全局路径规划: A ∗ A^{\ast} A∗、 D ∗ D^{\ast} D∗
- 局部路径规划:动态窗口法(Dynamic Window Algorithm, DWA) → \rightarrow → 避障能力,计算量小、实时性高 → \rightarrow → ROS默认算法;复杂环境 → \rightarrow → DWA会陷入局部最小
- 局部路径规划:时间弹性带(Timed Elastic Band, TEB) → \rightarrow → 图优化,迭代求解 → \rightarrow → 较高的操作性 → \rightarrow → 调参复杂
- 局部路径规划:模型预测控制(Model Prediction Control, MPC) → \rightarrow → 根据机器人当前的运动状态 → \rightarrow → 预测其未来几个时间步的轨迹 → \rightarrow → 二次规划方法来优化 → \rightarrow → 调参复杂
- 局部路径规划:PF 算法 → \rightarrow → 一种路径跟随算法 → \rightarrow → 基于 PID 的离散控制实现机器人沿着规划出的全局路径行走
- 传统局部路径规划:传统 → \rightarrow → 调参和泛化上存在劣势;没有考虑机器人在视觉 SLAM 过程中易在低纹理区域跟踪丢失的问题 → \rightarrow → 表现较差
(2) 深度强化学习
| 学者 | 方法 | 内容 | 特点 |
|---|---|---|---|
| 张福海等 | 基于 Q-learning 的强化学习 | 以激光雷达作为环境感知器 | 提高了对未知环境的适应性 |
| Guldenring 等 | 基于 PPO 的强化学习算法 | 以激光雷达来获取动态环境信息,用环境动态数据进行路径规划 | 进行局部路径规划 |
| Balakrishnan 等 | 基于深度强化学习的一种局部路径规划策略 | A ∗ A^{*} A∗全局路径规划算法基础上,利用深度强化学习学习训练局部路径规划,达到局部目标点 | 依赖于真实先验地图 |
| Chaplot 等 | 基于深度强化学习的一种局部路径规划策略 | 与全局策略相结合,以完成视觉探索任务 | 依赖于真实先验位姿 |
(3) 提出问题和方法总述
- 问题:设计合理的局部路径规划,能与视觉SLAM更好的配合;避免碰撞和位姿跟踪丢失、提升导航成功率。
- 工作:充分考虑了机器人避障、防止视觉 SLAM 跟踪丢失以及机器人行走效率等多方面因素;
- 创新点:(1)提出方法;(2)多样奖励函数;(3)局部路径规划模型融入总体导航框架;
1 问题描述
低纹理区域 → \rightarrow → 视觉 SLAM 跟踪失败现象 → \rightarrow → 兼顾低纹理区域、障碍物等诸多不利因素影响
Habitat 仿真平台 → \rightarrow → 以实体的形式存在;能提供机器人所在位置的彩色图和深度图;实时检测是否发生碰撞;给定机器人的初始位置和全局目标点位置
视觉SLAM和三维重建 → \rightarrow → 稠密点云地图 → \rightarrow → 投影得到栅格地图 → \rightarrow → A ∗ A^{\ast} A∗算法求解
视觉SLAM模块 → \rightarrow → ORB(Oriented FAST and Rotated BRIEF, ORB)特征点图 → \rightarrow → 实时检测机器人当前位姿跟踪状态(跟踪正常/跟踪丢失)
局部路径规划:
- 目标点 → \rightarrow → 机器人当前位置作圆与全局路径的交点;
- 目标 → \rightarrow →(尽可能少的动作)达到目标点 + 避开障碍物 + 避免跟踪失败;
- 目标完成后 → \rightarrow → 进行下一个局部点生成 + 路径规划;
- 失败 → \rightarrow → 视觉SLAM跟踪失败 / 发生碰撞
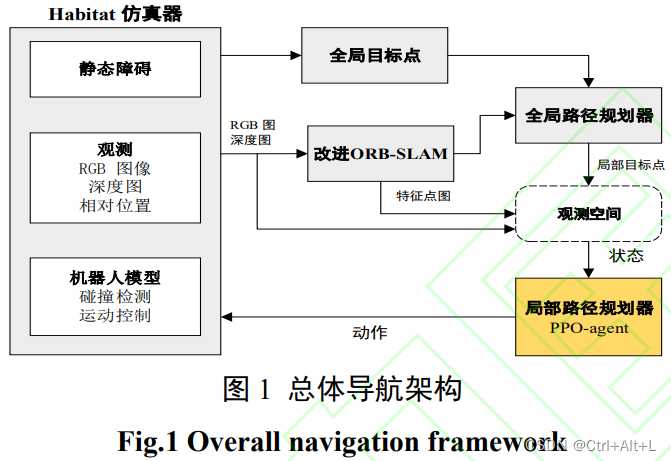
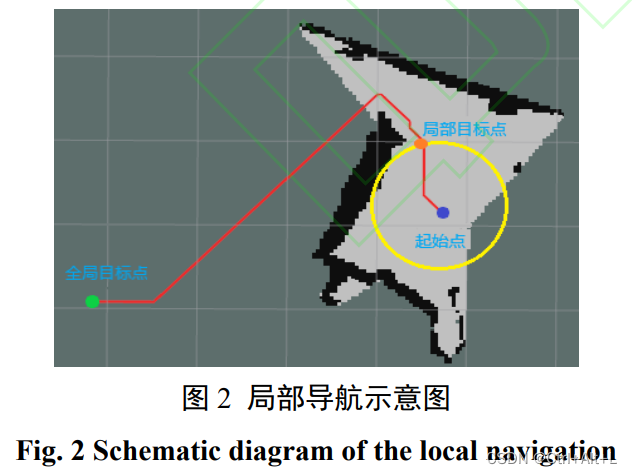
2 基于深度强化学习的路径规划
2.1 模型建立
2.2 框架设计
根据接口标准
(1) step 函数
执行
a
t
a_{t}
at,进入下一个状态
s
t
+
1
s_{t+1}
st+1,返回奖励值
r
t
r_{t}
rt,判断是否结束bool
d
o
n
e
done
done;
基本数据单元 → ( s t , a t , s t + 1 , r t , d o n e ) \rightarrow\ \big( s_{t},a_{t},s_{t+1},r_{t},done \big) → (st,at,st+1,rt,done)
(2) reset 函数
智能体与环境初始化 → \rightarrow → 新一轮交互
触发条件 → \rightarrow → 达到局部目标点、发生碰撞、跟踪失败、最大步数限制
(3) render 函数
输出可视化窗口显示机器人当前的状态及所处环境
彩色图 (RGB)、深度图(Depth)、全局地图、路径规划
2.3 可观测状态与奖励函数设计
如何描述可观测状态空间?
如何设计奖励函数?
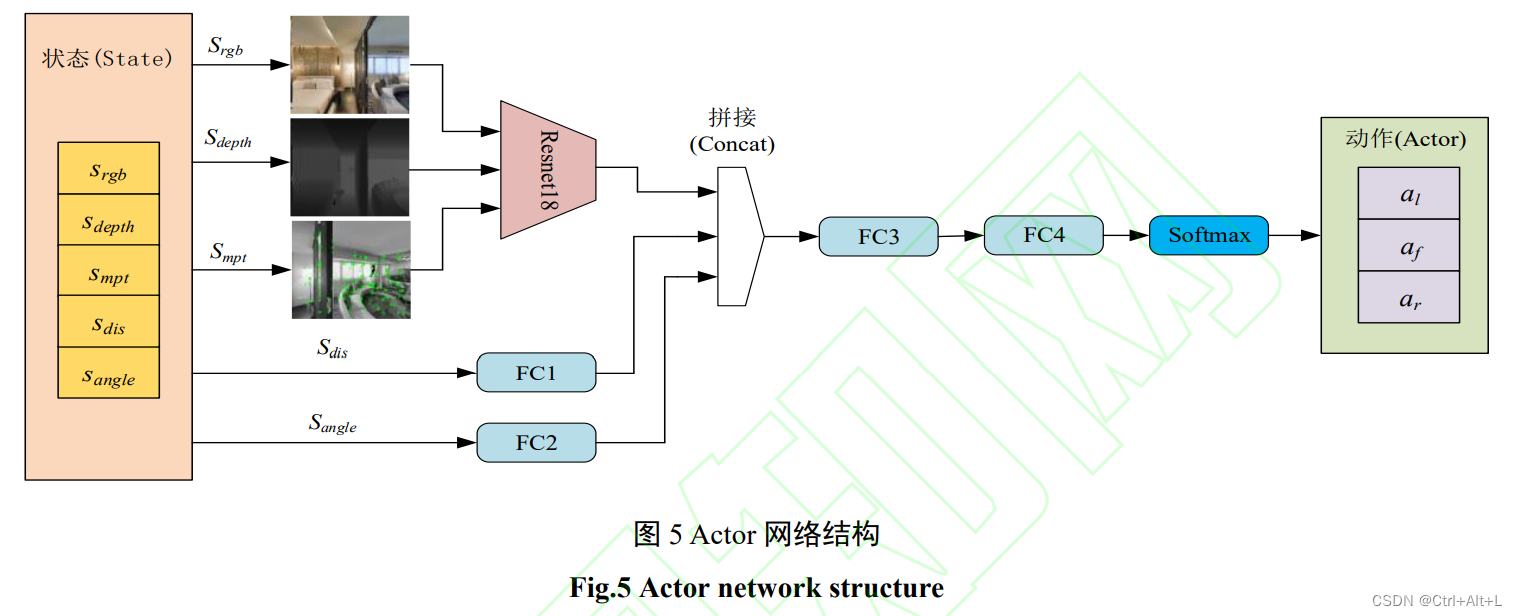
状态
S = ( S r g b , S d e p t h , S d i s , S a n g l e , S m p t ) S d i s = ( x 2 − x 1 ) 2 + ( y 2 − y 1 ) 2 ∣ S a n g l e ∣ = arctan ( cos ( β ) ( y 2 − y 1 ) + sin ( β ) ( x 2 − x 1 ) S d i s ) S=(S_{rgb},S_{depth},S_{dis},S_{angle},S_{mpt}) \\ S_{dis} = \sqrt{(x_{2}-x_{1})^{2}+(y_{2}-y_{1})^{2}} \\ |S_{angle}|=\arctan\big( \frac{\cos(\beta)(y_{2}-y_{1}) + \sin(\beta)(x_{2}-x_{1})}{S_{dis}} \big) S=(Srgb,Sdepth,Sdis,Sangle,Smpt)Sdis=(x2−x1)2+(y2−y1)2 ∣Sangle∣=arctan(Sdiscos(β)(y2−y1)+sin(β)(x2−x1))
S r g b S_{rgb} Srgb → \rightarrow → 彩色图片; S d e p t h S_{depth} Sdepth → \rightarrow →深度图片;
S d i s S_{dis} Sdis、 S a n g l e S_{angle} Sangle → \rightarrow → 机器人与局部目标点距离,机器人朝向与机器人与局部目标点连线夹角
S m p t S_{mpt} Smpt → \rightarrow → 采样时刻当前帧的特征点图的位置矩阵 → \rightarrow → 包含了特征点在图像帧上的位置和数量信息
动作
A = { a l , a r , a f } A=\{ a_{l},a_{r},a_{f} \} A={al,ar,af} $ \rightarrow$ 向左、向右和向前
每个动作执行时间 $ \rightarrow$ 1 s s s;左转/右转角速度 $ \rightarrow$ 0.3 r a d / s rad/s rad/s;前进速度 → \rightarrow → 0.1 m / s m/s m/s
奖励函数设计
$s_{sts} $ → \rightarrow → 机器人运行状态;
值域 → \rightarrow → { 1 , 2 , 3 , 4 } \{1,2,3,4\} {1,2,3,4} → \rightarrow → 机器人正常运行、 碰撞、视觉 SLAM 跟踪丢失和到达局部目标点
| 具体情况 | 奖励函数 | 备注 |
|---|---|---|
| 避障 | r o b v = ( s s t s = = 1 ) ? : λ 1 , 0 r_{obv}=(s_{sts}==1)?:\lambda_{1},0 robv=(ssts==1)?:λ1,0; | λ 1 \lambda_{1} λ1是系数 |
| 距离 | r d i s = λ 2 Δ d r_{dis}=\lambda_{2}\Delta d rdis=λ2Δd, Δ d \Delta d Δd 是上一状态和当前状态到局部目标点之间的距离差 | λ 2 \lambda_{2} λ2是系数 |
| 视觉SLAM跟踪 | r s l a m = ( s s t s = = 2 ) ? : − λ 3 , 0 r_{slam}=(s_{sts}==2)?:-\lambda_{3},0 rslam=(ssts==2)?:−λ3,0; | λ 3 \lambda_{3} λ3是系数 |
| 角度 | $r_{angle}=\lambda_{4}( | \alpha_{t} |
| 特征点数 | r N m p t = λ 5 lg ( N m p t t + 1 N m p t t ) r_{Nmpt}=\lambda_{5}\lg(\frac{Nmpt_{t+1}}{Nmpt_{t}}) rNmpt=λ5lg(NmpttNmptt+1) | λ 5 \lambda_{5} λ5是系数 |
| 达到目标点 | r b o n u s = ( s s t s = = 3 ) ? λ 6 : 3 , 0 r_{bonus}=(s_{sts}==3)?\lambda_{6}:3,0 rbonus=(ssts==3)?λ6:3,0; | λ 6 \lambda_{6} λ6是系数 |
| 综合奖励函数 | 上面的线性求和 |
ORB 特征点的匹配
ORB SLAM 2算法
前端视觉里程计的基础
特征点在图像中的位置和数量包含了视觉 SLAM 跟踪稳定的信息

2.4 PPO 算法
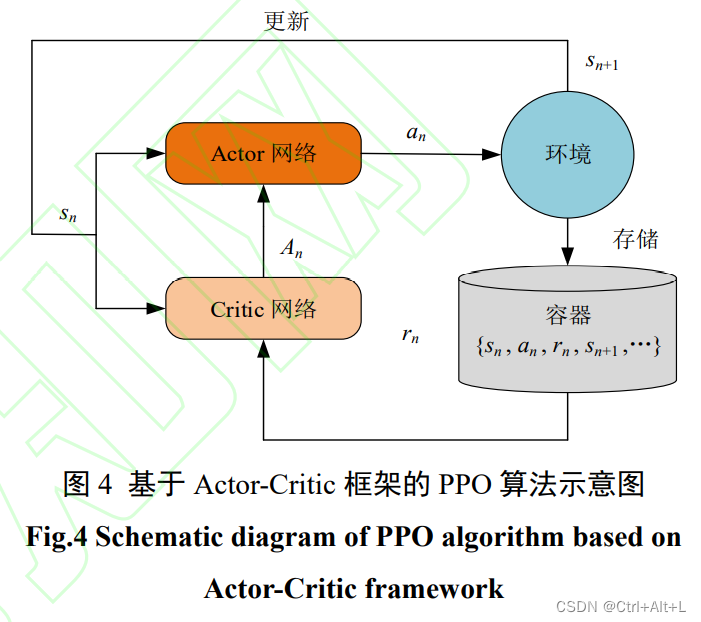
更新过程中,PPO 算法利用式(1)中的剪切函数来限制策略的更新幅度。
当新旧策略更新偏移量过大时,使用剪切项代替,这样确保新旧策略的偏离程度不至于太大,让 Actor 网络以一种相对平稳的方式进行更新,收敛速度更快。
L c l i p ( θ A ) = E n [ r θ A A n , c l i p ( r θ A , 1 − ϵ , 1 + ϵ ) A n ] (1) L^{clip}(\theta_{A})=E_{n}[ r_{\theta_{A}}A_{n},\mathbf{clip}(r_{\theta_{A}},1-\epsilon,1+\epsilon)A_{n} ] \tag{1} Lclip(θA)=En[rθAAn,clip(rθA,1−ϵ,1+ϵ)An](1)
2.5 网络结构
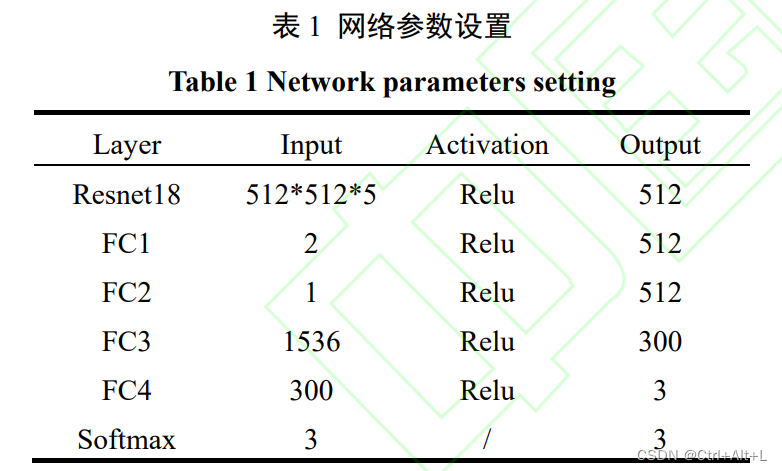
3 仿真结果与分析
3.1 实验环境及参数设置
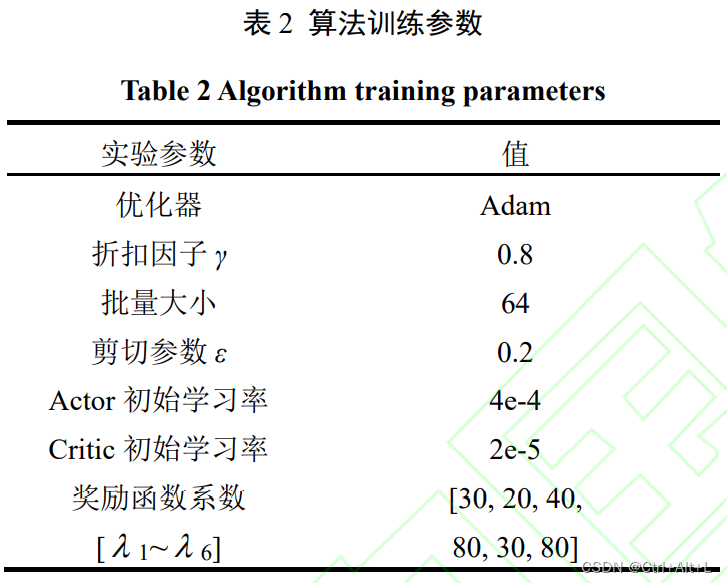
-
在实验过程中,可注意到机器人在纹理较丰富的区域时,图像帧中的特征点数变化幅度不大,大概在 850~950。
-
机器人在由纹理较丰富的区域向低纹理区域运 动时,相邻帧之间的特征点变化幅度较大,比值 N m p t t + 1 N m p t t \frac{Nmpt_{t+1}}{Nmpt_{t}} NmpttNmptt+1 大概在 1.3 到 1.8 之间
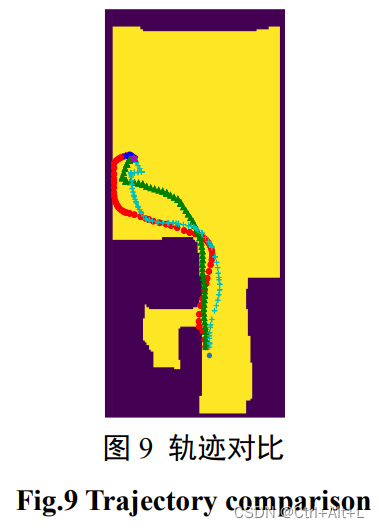
3.2 结果及分析
MPC算法是ROS系统中默认的局部路径规划算法,可作为很好的比较基准;
选取指标:成功率(Success Rate, SR)、跟踪丢失率(Tracking Failure Rate, TFR)、碰撞率 (Collision Rate, CR)
-
PF 算法在所有场景任务中表现都相对较差,这是因为该算法仅仅沿着规划出的全局路径行走,没有考虑如何避障。
-
DWA 算法、TEB 算法、MPC 算法运 行时需要载入局部地图,根据参数对行走轨迹 进行采样,选择运动代价最小的轨迹。
在三个场景的任务中均会发生较高的跟踪丢失率。
-
本文所述方法在所有场景任务中相比于传统的路径规划算法的平均成功率提高了 53.9%,位姿跟踪丢失率减小了 66.5%,碰撞率减小了 30.1%。
-
本文所提出的方法在 Edgemere 场景任务中表现最好,在 Eastville 场景任务中表现次之,在 Mosquito 场景任务中 表现相对较差。
本文所提出的方法后,机器人在行走过程中所跟踪到的特征始终维持在 580 个以上,具有较强的稳定性。
3.3 消融实验
消融实验是深度强化学习研究中确定某种方法是否有效的最直接的方式。
训练过程中每次剔除其中一部分奖励函数以查看对模型指标的影响。评价指标包括成功率、跟踪丢失率和碰撞率。
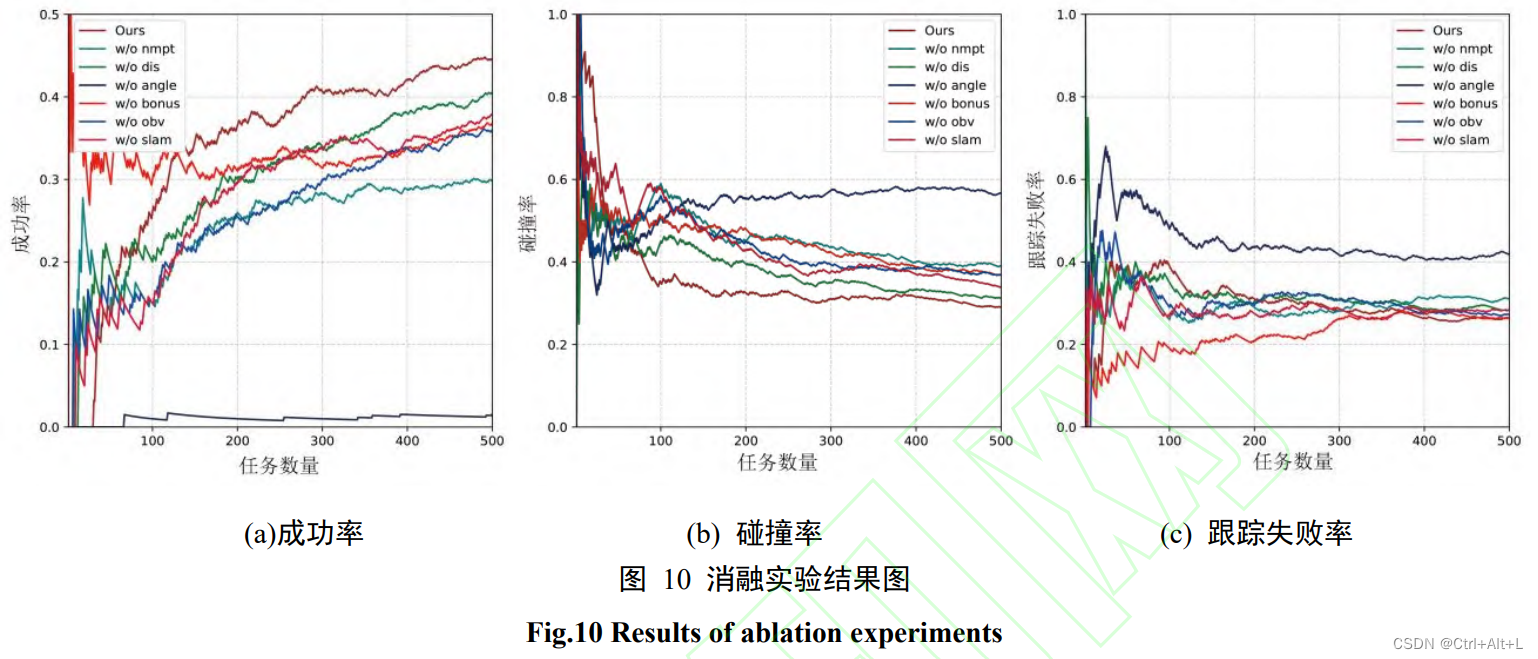
其他 6 个消融实验在各种指标上都略逊于 6 种奖励函数同时使用的效果,证明了这 6 种奖励函数在点导航任务上具有快速到达局部目标点,并降 低碰撞率和跟踪丢失率的能力。

