
- 1Wget命令详解_wget --spider
- 2[附源码]JAVA+ssm辖区重点人口情报采集与管理系统(程序+Lw)_城市基础设施信息采集系统 java
- 3Django笔记-Cache
- 4【Flutter】顶部导航栏实现 ( Scaffold | DefaultTabController | TabBar | Tab | TabBarView )_flutter defaulttabcontroller
- 5【centos】【vsftpd】FTP本地用户登录配置_vsftpd配置用户登录目录
- 6java相关软件(ieda,jdk8)及配置(环境变量)
- 74.GraphPad常见统计分析方法_multiple t tests和t test的区别
- 8小程序搜索排名优化二三事
- 9数仓项目拉链表_拉链表用sql如何实现?用调度工具如何实现?
- 10软件测试 | 试用期总结万能模板_软件测试试用期总结
万字心路历程:从十年老架构决定重构开始
赞
踩
作者:笃敏
概述
走近iLogtail
iLogtail是一款高性能的轻量级可观测数据采集器,由阿里云SLS团队官方提供,可以运行在包括服务器、容器和嵌入式等多种环境中,其宗旨在于帮助开发者构建统一的数据采集层,助力可观测平台打造各种上层应用场景。iLogtail多年来一直稳定服务阿里集团、蚂蚁集团以及众多公有云上的企业客户,目前已经有千万级的安装量,每天采集数十PB的可观测数据,广泛应用于线上监控、问题分析/定位、运营分析、安全分析等多种场景。
iLogtail架构发展历程
早在2013年,iLogtail作为阿里巴巴集团飞天5K项目中负责机器监控及日志收集的核心组件,已经被广泛地应用于集团内部机器。如今,10多年过去了,伴随着云原生和可观测性概念的逐步推广,iLogtail在商业化和开源的过程中也经历了一系列的架构迭代。
单一文件采集阶段
该阶段是iLogtail的起步阶段,也是iLogtail的命名由来,其主要能力是采集和解析日志文件并发送至日志服务后端进行存储。功能上,这一阶段的iLogtail具有如下特点:
- 只能采集日志文件;
- 假定日志为单一格式,每种格式的日志仅支持一种处理方式(如正则解析、Json解析等);
- 只能将日志发送至日志服务;

基于上述功能需求,这一阶段的iLogtail架构及实现具有如下特点:
- 完全由C++实现,在日志采集方面具有显著优势;
- 由于需求单一,因此整体架构偏向于单体架构,代码设计以面向过程为主,类的功能划分不明确,多个模块使用同一个类对象,导致类间依赖严重,可扩展性较差;
- 功能实现与日志服务相关概念(如LogGroup和Logstore等)强绑定,普适性较差;
Golang插件扩展阶段
随着可观测性概念的提出,iLogtail不再停留于单一的日志采集场景,逐步向更普适的可观测数据采集器领域发展。显然,要成为顶流的可观测数据采集器,必须至少满足以下几个条件:
- 多样化的数据输入输出选项
- 个性化的数据处理能力组合
- 高性能的数据处理吞吐能力
由于C++的开发生态有限,为了在短期内能够快速实现上述目标,iLogtail在起步阶段的基础上引入了基于Golang语言开发的插件系统,其整体架构演变为了如下所示的结构:
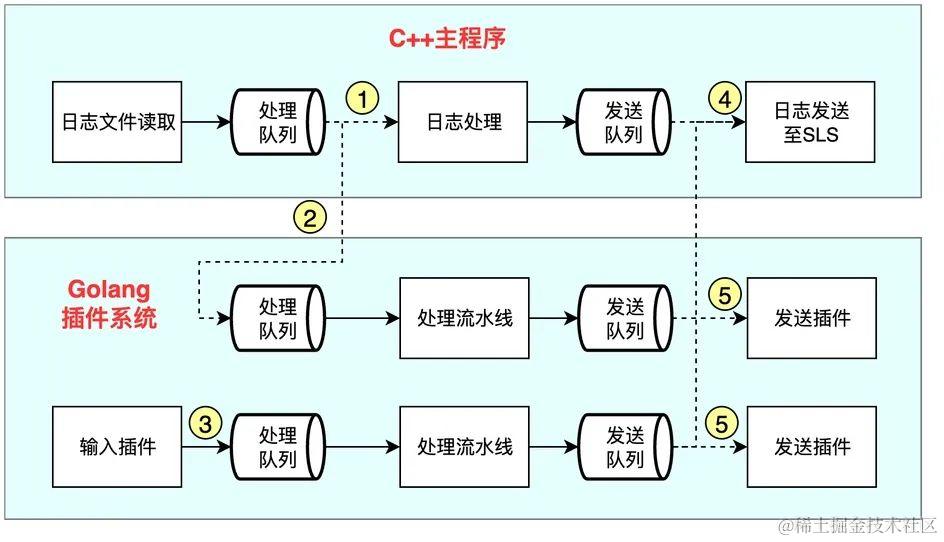
Golang插件系统是基于现代可观测处理流水线的思想进行设计的,具有如下特点:
- 每个采集配置对应一条完整的流水线,各个流水线之间的资源互相独立,互不影响;
- 每条流水线支持多个输入和输出,同时支持从C++主程序中接收数据及向C++主程序发送数据;
- 每条流水线支持多个处理插件级联,有效提升处理能力;
- 插件系统本身具备配置管理能力,支持配置的热加载,可独立于C++主程序进行工作。
可以看到,Golang插件系统的引入极大地扩展了iLogtail的输入输出通道,且一定程度提升了iLogtail的处理能力。然而,囿于C++部分的实现,输入输出与处理模块间的组合能力仍然是受限的,仅支持以下几种数据通路:
-
采集日志文件并使用C++的处理能力,最后将数据投递至日志服务SLS(1和4号组合);
-
采集日志文件并使用Golang插件进行处理,最后将数据投递至日志服务SLS(2和4号组合);
-
采集日志文件并使用Golang插件进行处理,最后将数据投递至第三方存储(2和5号组合);
-
采集其它输入(如syslog)并使用Golang插件进行处理,最后将数据投递至日志服务SLS(3和4号组合);
-
采集其它输入(如syslog)并使用Golang插件进行处理,最后将数据投递至第三方存储(3和5号组合)。
由此可见,相比于起步阶段的iLogtail,该阶段的iLogtail架构具备如下特点:
- C++和Golang多语言实现,C++部分拥有性能优势,Golang部分拥有功能优势;
- 支持多样化输入和输出选项;
- 数据处理能力有一定提升,但输入输出与处理模块间的组合能力存在多种限制:
- C++部分原生的高性能处理能力仍然局限于采集日志文件并投递至日志服务的场景使用;
- C++部分的高性能处理能力无法与插件系统的多样化处理能力相结合,二者只能选其一,从而降低了复杂日志处理场景的性能。
为什么要重构?
从前面的描述可知,原有iLogtail架构最大的问题在于输入输出与处理模块间的组合能力受限,这直接影响了商业版iLogtail在解析复杂日志场景中的性能。然而,随着iLogtail的开源,这一问题的矛盾变得更加突出:开源社区绝大多数用户都选择将数据投递至第三方存储,这意味着绝大多数社区用户将无法享受到iLogtail原生的高性能处理能力!除此之外,iLogtail的开源还将原本并不显著的问题暴露出来:
-
由于C++主程序代码存在错综复杂的类间依赖关系,导致开发难度极大,加之C++的处理能力无法被社区所使用,因此C++主程序的开发几乎无人问津。
-
不论是C++主程序还是Golang插件系统,其内部的数据交互模型只适用于可观测数据中的Log,而无法表达Metric和Trace。除此以外,这些数据结构均针对SLS而设计,导致在向第三方存储系统投递数据时,必须进行额外的数据结构转换,从而降低整体的性能。
-
碍于C++主程序代码错综复杂的类间依赖关系,商业版代码与开源版的剥离只能采用非常原始和丑陋的文件替换方式。这种操作直接导致如下两个结果:
- 开源版代码中存在大量意义不明的无用空函数;
- 在进行商业版代码开发时,首先需要进行文件替换,从而容易引入开源版和商业版代码的不一致,对联调联测带来诸多不便,影响开发和发布效率。
综上所述,不论是从产品演进,还是从开发体验,原有iLogtail架构已经严重制约了其快速发展。因此,对iLogtail的架构进行升级已经迫在眉睫。
目标
《重构:改善既有代码的设计》一书中对重构的意义和方法论有详细的阐述。对于iLogtail而言,本次重构的主要目标不仅仅停留于工程层面的优化,更重要的是通过对原有架构的升级来支撑产品未来的快速发展。具体来说,本次架构升级可以分为如下几个目标:
-
将iLogtail的内部数据模型更换为通用数据模型,以减少数据投递时不必要的数据结格式转换;
-
将C++主程序的输入、处理和输出能力全面插件化,便于从产品侧统一C++部分和Golang部分的插件概念;
-
在C++主程序中增加可观测流水线的概念,强化C++主程序的流水线配置管理能力,以支持C++处理能力间的级联和C++处理能力与Golang处理能力的组合,从而增强C++的主体地位;
-
统一商业版和开源版的采集配置格式,均采用流水线模式的配置结构,以适应最新的iLogtail架构;
-
优化采集配置热加载的方式,提升配置容错能力;
-
优化商业版代码嵌入开源版代码的路径,通过仅追加文件而非切换文件的方式来实现,提升开发效率。
实践
数据模型通用化
在原有iLogtail架构中,输入、处理和输出模块之间交互的数据模型是基于SLS后端的数据结构LogGroup,其protobuf定义如下:
message Log { required uint32 Time = 1; message Content { required string Key = 1; required string Value = 2; } repeated Content Contents= 2; repeated string values = 3; optional fixed32 Time_ns = 4; } message LogTag { required string Key = 1; required string Value = 2; } message LogGroup { repeated Log Logs= 1; optional string Category = 2; optional string Topic = 3; optional string Source = 4; optional string MachineUUID = 5; repeated LogTag LogTags = 6; }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
可以看到,每个LogGroup包含若干Log以及LogTag,以及其他一些元信息。显然,使用这个数据结构作为iLogtail内部的数据模型是有所不足的:
- 如LogGroup这个名字所示,该数据结构仅适用于表达可观测数据中的Log,而无法表达Metric和Trace,缺乏普适性;
- LogGroup是一个PB,应当只是在最终发送数据时使用,而不适合作为通用的内存数据模型。另一方面,这个PB只适用于SLS,并不适用于其他第三方存储。因此,在往第三方存储发送数据时,需要额外进行数据格式转换,降低采集效率。
因此,在新的架构中,我们需要将线程间的交互数据模型改成通用数据结构,这样做的好处在于:
- 支持表达可观测数据的所有类型,包括Log、Metric和Trace,提升数据结构的普适性;
- 发送模块可根据自身需要,选择不同的协议对通用数据结构进行序列化,提升发送协议的灵活性和性能。
为此,我们定义如下的数据模型层次:
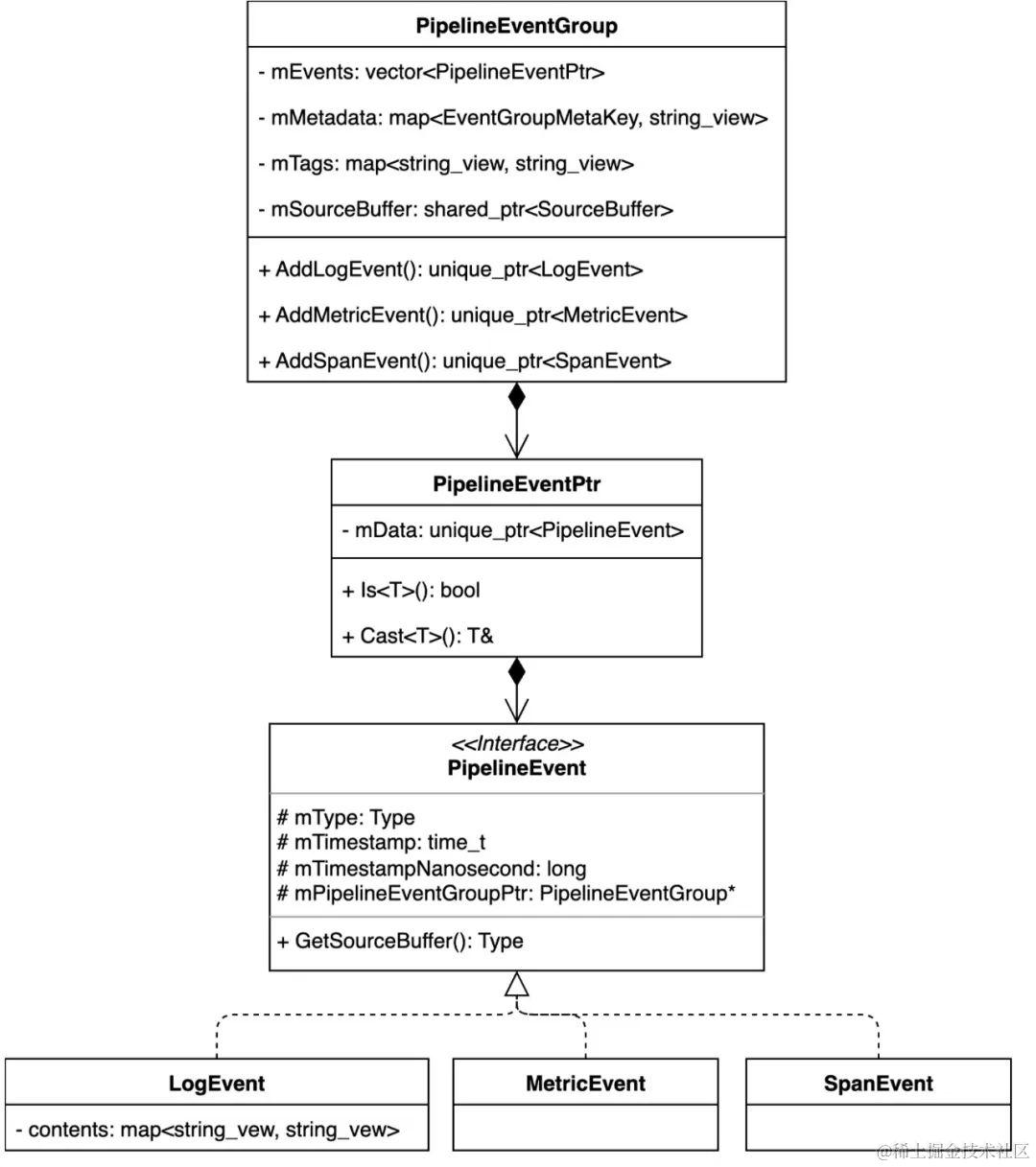
PipelineEventGroup
PipelineEventGroup是新架构中输入、处理和输出模块间的交互数据结构,与原有架构中的LogGroup相对应,它包含以下的成员变量:
- mEvents:一组事件;
- mMetadata:EventGroup共享的元信息,例如机器ip、容器名称、日志路径等;仅在生成EventGroup时可写,且保存于内存中,不用于最终输出;
- mTags:EventGroup共享的tag,与原有架构中的LogTag相对应,用于保存mMetadata中用户需要实际输出的信息,仅在tag处理插件中可写;
- mSourceBuffer:EventGroup共享的内存分配器,所有成员变量涉及的内存分配均需由该分配器分配。
PipelineEvent
PipelineEvent是一个抽象基类,表示一个事件,它的成员变量包含事件类型、当前事件的采集时间以及该事件所在的EventGroup。它的子类包括LogEvent、MetricEvent和SpanEvent,它们分别代表可观测数据中的Log、Metric和Trace。
需要强调的是,考虑到内存分配的问题,PipelineEvent不能独立于PipelineEventGroup存在,必须依附于某一PipelineEventGroup。因此,PipelineEvent的建立只能通过PipelineEventGroup的AddLogEvent、AddMetricEvent和AddSpanEvent函数来进行。
PipelineEventPtr
PipelineEventPtr是PipelineEvent的包装类,它包含一个指向PipelineEvent的指针,对外提供模板函数Is和Cast函数。这样做的目的主要是为了支持更高效的PipelineEvent与子类之间的转换,而无需调用效率相对较低的dynamic_cast函数,具体转换细节可参见源码。
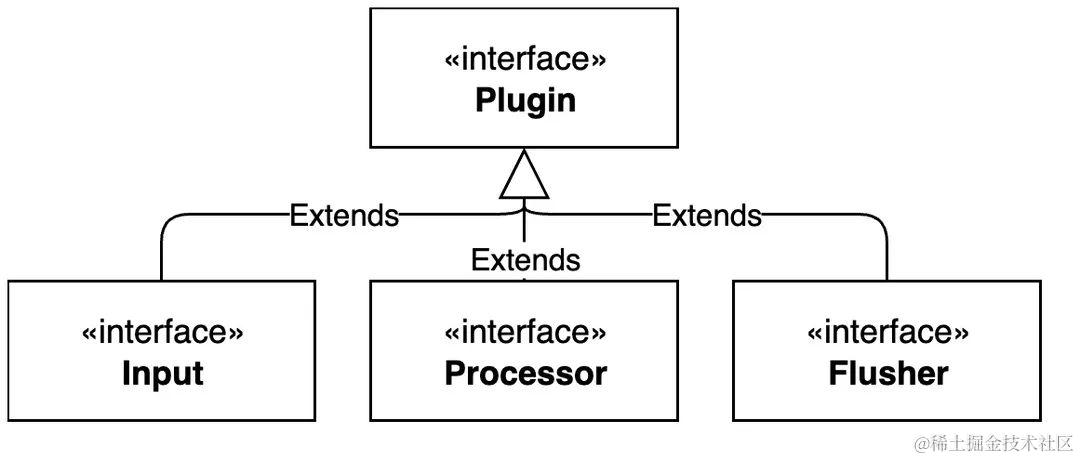
插件抽象
可观测流水线是现代可观测数据采集器的必要元素,而可观测流水线的核心组成是插件,包括输入、处理和输出插件。在原有架构中,只有Golang插件系统存在插件概念,C++主程序中缺乏相关概念。因此,为了能够建立统一的流水线,必须在C++主程序中新增插件的概念。
为了统一所有插件的共有行为,我们首先定义所有类型插件的抽象基类Plugin:
class Plugin {
public:
virtual ~Plugin() = default;
virtual const std::string& Name() const = 0;
// other setters && getters
protected:
PipelineContext* mContext = nullptr;
};
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
其中,成员变量mContext指向插件所属流水线(Pipeline)的上下文信息(具体含义将在下文介绍),成员函数Name()返回该插件的名字。
输入、处理和输出插件均为Plugin的继承类:
处理插件
接口定义
处理插件的抽象基类Processor的定义如下:
class Processor : public Plugin {
public:
virtual ~Processor() {}
virtual bool Init(const Json::Value& config) = 0;
virtual void Process(std::vector<PipelineEventGroup>& logGroupList);
protected:
virtual bool IsSupportedEvent(const PipelineEventPtr& e) const = 0;
virtual void Process(PipelineEventGroup& logGroup) = 0;
};
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
其中,公有成员函数的说明如下:
- Init函数:负责根据采集配置实例化插件,并返回是否成功实例化;
- Process函数:负责对输入的每一个PipelineEventGroup进行处理,并将处理结果通过同一变量返回。
原有能力抽象
在原有架构中,由于假定日志文件仅存在一种格式且只能进行一次格式解析,并且针对某些特定格式的日志有特殊的读取逻辑(实际没必要),因此在代码层面采用了一种强耦合的设计模式。具体来说,所有格式的日志共享一个基类LogFileReader,其主要负责读取日志。对于每一种格式的日志,都单独设置一个类继承LogFileReader,其成员函数主要用于对文本日志进行行切分和解析。除此以外,对于一些工具函数,还专门设置一个LogParser类,该类只包含静态成员,本质上是面向过程的包装。
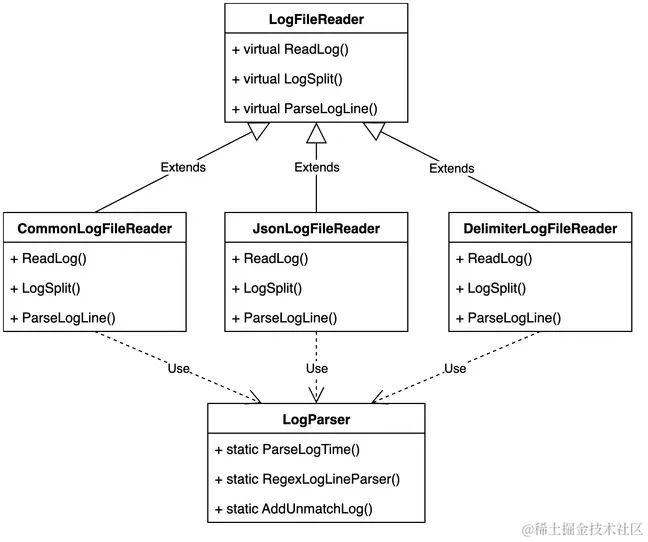
显然,将日志文件读取和日志解析的能力统一放到一个类中是一个不太合理的设计,完全缺乏可扩展性。为此,我们需要将日志切分(LogSplit函数)和日志解析(ParseLogLine函数)的能力从LogFileReader类中剥离开来,同时和LogParser类中相关的函数进行重新组合,从而形成多个独立的处理插件。
由于Golang和C++可能在某些方面会提供相同的处理能力,为了区分二者,我们称C++的处理插件为“原生处理插件”,而Golang的处理插件则称为“扩展处理插件”。据此,我们可以在C++部分抽象出如下几个原生处理插件:
-
ProcessorSplitLogStringNative:日志切分处理插件,用于对日志块按照指定分隔符进行切分生成多个事件;
-
ProcessorSplitRegexNative:日志切分处理插件,用于对日志块按照正则表达式进行切分生成多个事件;
-
ProcessorParseRegexNative:正则解析插件,通过正则匹配解析事件指定字段内容并提取新字段;
-
ProcessorParseJsonNative:Json解析插件,解析事件中Json格式字段内容并提取新字段;
-
ProcessorParseDelimiterNative:分隔符解析插件,解析事件中分隔符格式字段内容并提取新字段;
-
ProcessorParseTimestampNative:时间解析插件,用于解析事件中记录时间的字段,并将结果置为事件的__time__字段;
除了上述处理能力外,原有iLogtail还提供了字段过滤和脱敏的处理能力,它们均属于LogFilter类的能力,在日志发送前被调用(调用点也不合理)。为此,我们也将这两种处理能力抽象成原生处理插件:
-
ProcessorFilterRegexNative:事件过滤插件,用于根据事件字段内容来过滤事件;
-
ProcessorDesensitizeNative:脱敏插件,用于对事件的字段内容进行脱敏;
最后,我们在前文提到,PipelineEventGroup的mTag成员是从mMetadata成员中获取的,而这一过程也需要新增如下的原生处理插件来完成:
- ProcessorTagNative:tag处理插件,用于将PipelineEventGroup的mMetadata成员选择性地加入mTag成员用于最终输出,同时支持对tag的key进行重命名。
至此,我们已经将C++主程序的处理能力抽象成9个独立的原生处理插件,同时简化LogFileReader类使其专注于文件读取功能,并删去LogFileReader类的所有继承类、LogFilter类和LogParser类。
输入插件
接口定义
输入插件的抽象基类Input的定义如下:
class Input : public Plugin {
public:
virtual ~Input() = default;
virtual bool Init(const Json::Value& config, Json::Value& optionalGoPipeline) = 0;
virtual bool Start() = 0;
virtual bool Stop(bool isPipelineRemoving) = 0;
};
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
其中,公有成员函数的说明如下:
- Init函数:负责根据采集配置实例化插件,并返回是否成功实例化以及可能的Golang流水线组件;
- Start函数:启动输入插件;
- Stop函数:根据流水线是否即将被移除,采取不同的策略停止输入插件;
原有能力抽象
C++部分的采集输入能力包括日志文件采集和eBPF指标采集。出于篇幅和典型性的考虑,本文仅以日志文件采集的能力抽象为例说明输入能力的插件抽象,eBPF指标采集的插件抽象可直接参考代码。
我们在前文提到,对于iLogtail的Golang插件系统,每一条流水线都拥有完全独立的资源。具体来说,每条流水线的输入、处理和发送模块都各自有一个独立的线程在工作,线程之间通过流水线独享的缓冲队列来交换数据。这种设计非常直观,可以保证流水线之间互不影响。然而,此种模式的最大问题在于资源消耗,即整个客户端所消耗的线程数量与流水线的数量成正比。对于资源受限场景,这种资源无限增长的特性会对服务器产生较大压力,甚至产生负面影响。
相比于Golang,性能是C++的优势。因此,在原有的C++部分,文件采集采用的是总线模式,即只用一个线程来轮流采集每个配置指定的日志文件(实际不止一个线程,但是数量固定,不与配置数量相关)。显然,从性能角度考虑,即便我们要将文件采集抽象成输入插件,我们仍然应该保持原有的总线模式,即所有文件输入插件共享一个线程。但这种“一对多”的模式就会产生一个矛盾点:输入插件的接口语义是独立启动和停止的,但是采用总线模式显然必须所有的文件输入插件统一启动和停止,而非每条流水线独立启停。
那如何解决这种“一对多”引入的矛盾呢?我们可以借鉴设计模式中的代理模式(Proxy)思想,新增一个全局管理文件读取的类FileServer,该类拥有一个线程负责依次轮流读取所有文件输入插件指定的文件。而文件输入插件的Start和Stop函数只是将当前插件的配置注册到FileServer类中和从类中删除,并视情况调用FileServer类的Start和Stop函数执行真正的采集启停。
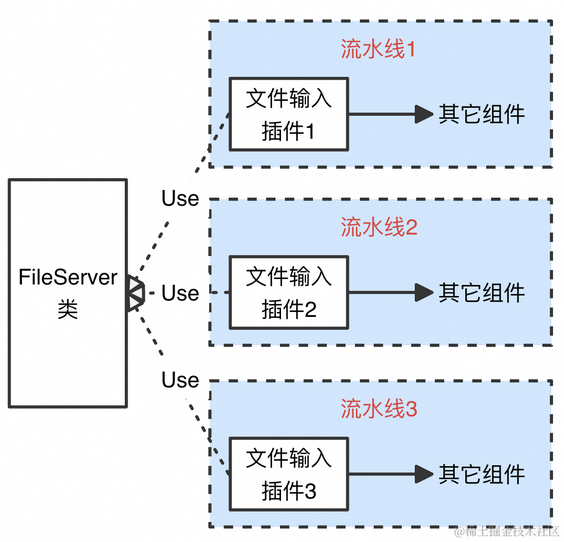
据此,文件输入插件的Start和Stop函数分别如下所示:
bool InputFile::Start() { if (!FileServer::GetInstance()->IsRunning()) { FileServer::GetInstance()->Start(); } if (mEnableContainerDiscovery) { mFileDiscovery.SetContainerInfo( FileServer::GetInstance()->GetAndRemoveContainerInfo(mContext->GetPipeline().Name())); } FileServer::GetInstance()->AddFileDiscoveryConfig(mContext->GetConfigName(), &mFileDiscovery, mContext); FileServer::GetInstance()->AddFileReaderConfig(mContext->GetConfigName(), &mFileReader, mContext); FileServer::GetInstance()->AddMultilineConfig(mContext->GetConfigName(), &mMultiline, mContext); FileServer::GetInstance()->AddExactlyOnceConcurrency(mContext->GetConfigName(), mExactlyOnceConcurrency); return true; } bool InputFile::Stop(bool isPipelineRemoving) { if (!FileServer::GetInstance()->IsPaused()) { FileServer::GetInstance()->Pause(); } if (!isPipelineRemoving && mEnableContainerDiscovery) { FileServer::GetInstance()->SaveContainerInfo(mContext->GetPipeline().Name(), mFileDiscovery.GetContainerInfo()); } FileServer::GetInstance()->RemoveFileDiscoveryConfig(mContext->GetConfigName()); FileServer::GetInstance()->RemoveFileReaderConfig(mContext->GetConfigName()); FileServer::GetInstance()->RemoveMultilineConfig(mContext->GetConfigName()); FileServer::GetInstance()->RemoveExactlyOnceConcurrency(mContext->GetConfigName()); return true; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
可以看到,文件输入插件InputFile类的Start函数只做了如下两件事:
- 如果文件采集总线程未启动,则调用FileServer类的Start函数启动线程;
- 将插件相关配置注册到FileServer类中。
类似的,InputFile类的Stop函数也只做了两件事:
- 如果文件采集线程未暂停,则调用FileServer类的Stop函数暂停全局文件采集;
- 将插件相关配置从FileServer类中删除。
通过这种代理模式,我们巧妙地将文件采集的具体实现隐藏在文件输入插件InputFile背后,从而对外提供了统一的接口描述,提升了代码的可扩展性和可维护性。
可扩展性
尽管原有的C++输入插件仅有2个,但是在完成了本次架构升级后,新增C++输入不再是一个难题。尽管文件输入插件采用了总线模式,但这并不意味着新的框架不支持类似于Golang输入插件那样的独立运行模式。对于某些输入源,如果已经有包装较好的SDK,那采用总线模式来采集显然会非常麻烦,采用每个插件独立运行可能是一个更方便的实现方式。但不论怎样,从性能角度出发,我们仍然推荐所有输入插件都采用类似文件采集的总线模式来节省资源和提升效率。
输出插件
接口定义
输出插件的抽象基类Flusher的定义如下:
class Flusher : public Plugin {
public:
virtual ~Flusher() = default;
virtual bool Init(const Json::Value& config, Json::Value& optionalGoPipeline) = 0;
virtual bool Start() = 0;
virtual bool Stop(bool isPipelineRemoving) = 0;
};
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
其中,公有成员函数的说明如下:
- Init函数:负责根据采集配置实例化插件,并返回是否成功实例化以及可能的Golang流水线组件;
- Start函数:启动输出插件;
- Stop函数:根据流水线是否即将被移除,采取不同的策略停止输出插件;
原有能力抽象
C++部分的数据发送能力只包括往日志服务(SLS)发送数据,因此只需将该能力抽象成SLS输出插件FlusherSLS即可。与文件采集类似,原有的SLS发送能力也采用的是总线模式。因此,在实现SLS输出插件时,我们也采用类似文件输入插件的方式,保留总线模式,即有一个全局管理发送的类SLSSender,该类拥有一个线程负责依次轮流发送所有SLS输出插件的数据。与文件采集不同的是,在流水线变更期间,发送线程是无需停止的。因此,SLS输出插件的Start和Stop函数只是将当前插件的配置注册到SLSSender类中和从类中删除,并不涉及真正的发送启停。
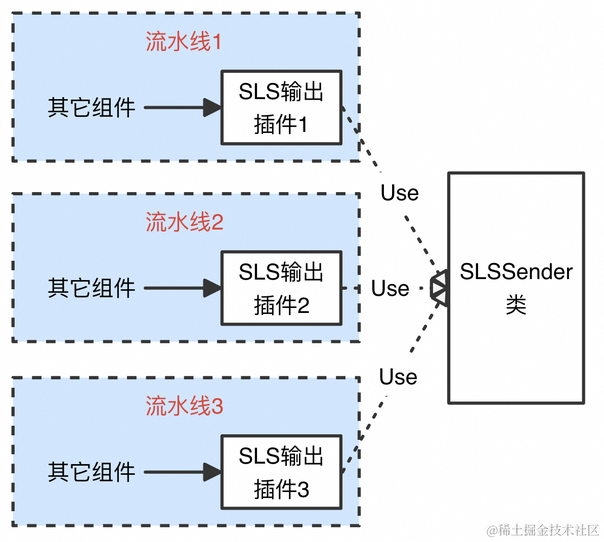
据此,SLS输出插件的Start和Stop函数分别如下所示:
bool FlusherSLS::Start() {
SLSSender::Instance()->IncreaseProjectReferenceCnt(mProject);
SLSSender::Instance()->IncreaseRegionReferenceCnt(mRegion);
SLSSender::Instance()->IncreaseAliuidReferenceCntForRegion(mRegion, mAliuid);
return true;
}
bool FlusherSLS::Stop(bool isPipelineRemoving) {
SLSSender::Instance()->DecreaseProjectReferenceCnt(mProject);
SLSSender::Instance()->DecreaseRegionReferenceCnt(mRegion);
SLSSender::Instance()->DecreaseAliuidReferenceCntForRegion(mRegion, mAliuid);
return true;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
可以看到,SLS输出插件flusherSLS类的Start和Stop函数只是将插件相关配置注册到SLSSender类中或从类中删除。显然,通过这种代理模式,我们也将SLS发送的具体实现隐藏在SLS输出插件背后,从而对外提供了统一的接口描述。
可扩展性
与输入插件类似,框架对于输出插件也同时支持总线模式和独立运行模式。但同样,从性能角度出发,我们仍然推荐所有输出插件都采用总线模式来节省资源和提升效率。
流水线抽象
与插件类似,在原有架构中,仅Golang插件系统存在流水线的概念,C++主程序中仅有采集配置而缺乏流水线的概念。因此,需要在C++主程序中新增流水线概念,这样做的好处在于:
- 统一C++主程序和Golang插件系统的流水线,加强C++主程序的主体地位;
- 支持C++处理能力的级联,极大地提升C++部分对于复杂日志的处理能力;
- 便于C++插件和Golang插件的组合,从而提供更灵活的插件编排能力,同时从产品层面提供更加统一的视图。
插件编排
我们定义iLogtail的流水线Pipeline为如下形态:

可以看到,每条流水线可包含任意个输入、处理和输出插件,插件类型既可以是C++插件,也可以是Golang插件,但存在如下的唯一限制:原生处理插件仅可出现在扩展处理插件之前,即不允许在使用扩展处理插件后再使用原生处理插件! 增加此项限制主要基于如下考量:
- 从产品层面,扩展处理插件仅起到辅助作用,仅在单纯使用原生处理插件无法满足处理需求时使用。因此,扩展处理插件相对于原生处理插件而言是补充和追加关系,而非对等关系。
- 从架构层面,毕竟原生处理插件和扩展处理插件分别由不同的语言实现,二者之间的交互必须通过CGO接口来完成。从性能角度,应当尽可能避免频繁的CGO接口调用,因此在处理阶段,只允许数据单向地从C++主程序流向Golang插件系统。
| ⚠️ 以上插件编排限制描述针对的是最终架构,由于架构升级实际是分阶段进行的,故不同版本的实际限制请参见源码和配套的说明文档。 |
|---|
根据以上描述,在新架构中,数据的可能通路如下所示:
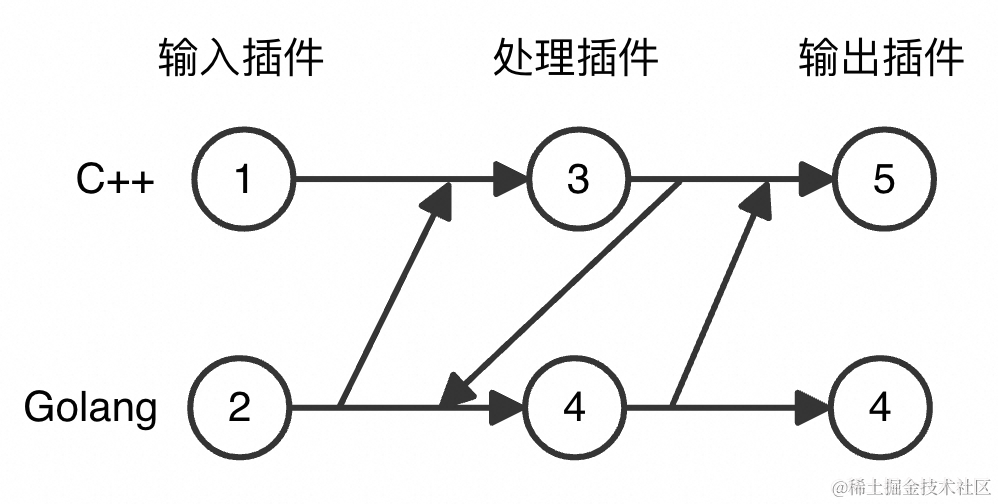
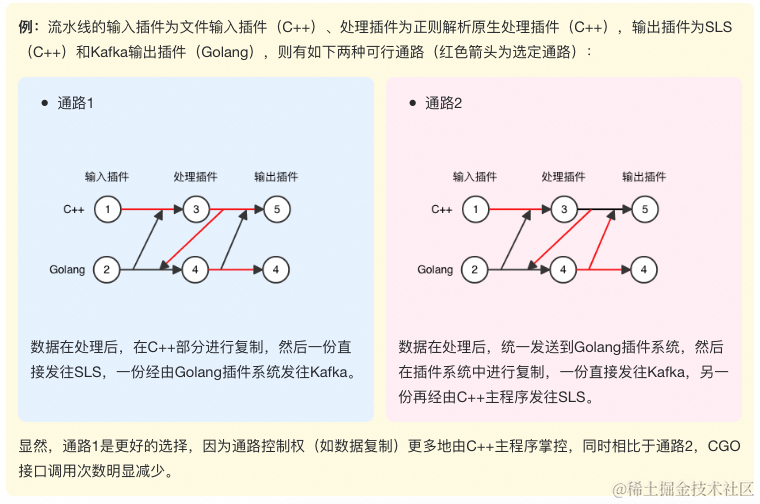
在流水线初始化阶段,根据不同的插件组合,选定最终的数据通路。对于有多条通路可供选择的插件组合,我们以如下原则选定最终通路:
- 数据通路应尽可能多地经过C++组件;
- 数据通路应当尽可能减少CGO接口;
由于Golang插件系统的运行也是以流水线的形式进行的,并不能以插件的形式单独存在,因此我们重新定义Golang流水线为流水线的子流水线。从上图中也能看到,Golang子流水线可能有两种形式:
- 包含输入插件:如2、3、5组合或者2、4组合;
- 不包含输入插件:如1、3、4组合。
因此,对于任意一条流水线,其可能不含Golang子流水线,也可能包含多条Golang子流水线,但最多只可能存在两条(如插件组合2、3、4),具体情况视插件编排结果而定。
插件实例
显然,一条流水线中可以存在多个相同的插件。为了区分同名插件,以及方便插件运行状态的可观测,我们需要额外在插件之上增加一层封装——插件实例。对于流水线而言,它管理的只是插件实例,对插件本身无感。所有对插件实例的操作实际上是在操作插件本身,因此这实际上也是设计模式中代理模式(Proxy)在iLogtail新架构中的又一次应用。
与插件类似,为了统一所有插件实例的共有行为,我们也会首先定义所有类型插件实例的抽象基类PluginInstance,然后在此基础上派生出不同类型的插件实例:InputInstance、ProcessInstance和FlusherInstance。整个类层次如下图所示:
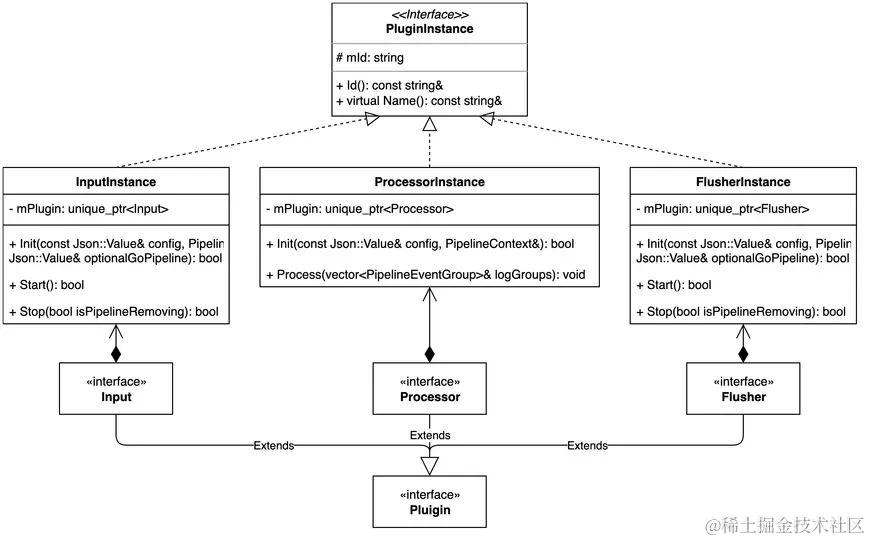
可以看到,每个插件实例都有一个mId成员用于唯一标识一个插件实例,以及一个mPlugin成员指向真正的插件。
反馈队列
除了插件实例,流水线中另一个重要的组成部分是连接各模块的缓冲队列,它在资源管控和处理突发流量方面起到着重要作用。
在原有架构中,C++部分的缓冲队列都是以LogStore为粒度的,即每个Logstore一个队列。显然,以Logstore作为队列的颗粒度是不合适的,原因包括:
- LogStore是SLS特有的概念,对于往第三方存储发送数据的场景(例如开源场景),没有Logstore的概念,只能默认所有的配置共用一个Logstore,即所有配置共用一个缓冲队列。这显然是不合理的。
- 即便是往日志服务投递数据的场景,由于一个Logstore包含多个采集配置,因此难以通过反馈队列实现配置级的资源管控。
另一方面,对于Golang插件系统,由于天然的流水线资源独立性,缓冲队列自然是流水线级别的。相比于原有C++的实现,这显然更符合配置级别资源管控的实际需求。但是与线程资源一样,缓冲队列的数量也是与流水线数量直接成正比的,也意味着内存使用会显著高于C++原有的实现方式。
那有没有什么方法既可以实现配置级别的资源管控,又能尽可能少地占用资源呢?
答案自然是肯定的,我们可以采用如下图所示的架构:

说明如下:
- 与Golang插件系统类似,每个流水线拥有一个独立的处理队列;
- 对于发送队列,从Process线程的角度看,每个发送插件拥有一个发送队列。但实际上这个发送队列内部可进一步包含多个子队列,例如SLS输出插件仍然保持每个Logstore一个发送队列;
- 发送队列与处理队列之间的反馈不再是一对一的关系,而是改成多对一的关系。
使用这样的架构有如下好处:
- 由于流水线的资源管控往往只需要对流水线的源头进行控制即可,因此处理队列保持以流水线为粒度能够保证流水线资源控制的正常进行,同时还便于对流水线进行优先级的区分。
- 由于不同的发送服务端有着不同的资源管控粒度(例如SLS对Logstore的流量有限制),但这些细节对于Process线程来说没有意义。因此,通过设计模式中的代理模式(Proxy)保持一个发送插件实例一个逻辑上的发送队列能够最大程度简化类间交互,增强可扩展性,同时降低内存使用。
- 运用设计模式中的观察者模式(Observer)有助于提升反馈队列交互的可扩展性。
流水线定义
至此,我们可以给出流水线Pipeline的定义:
class Pipeline { public: bool Init(Config&& config); void Start(); void Process(std::vector<PipelineEventGroup>& logGroupList); void Stop(bool isRemoving); // other getters & setters private: std::string mName; std::vector<std::unique_ptr<InputInstance>> mInputs; std::vector<std::unique_ptr<ProcessorInstance>> mProcessorLine; std::vector<std::unique_ptr<FlusherInstance>> mFlushers; Json::Value mGoPipelineWithInput; Json::Value mGoPipelineWithoutInput; FeedbackQueue<PipelineEventGroup> mProcessQueue; mutable PipelineContext mContext; std::unique_ptr<Json::Value> mConfig; // other private members };
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
其中的公有成员函数说明如下:
- Init函数:根据采集配置进行插件编排,实例化所有的C++插件,并加载可能存在的Golang子流水线;
- Start函数:按照从输出到输出的顺序(即数据通路图中的5至1顺序)依次启动各个组件;
- Process函数:按顺序使用C++插件对输入的PipelineEventGroup列表进行处理;
- Stop函数:按照从输入到输出的顺序(即数据通路图中的1至5顺序)依次停止各个组件。
成员变量主要包括:
- mName:流水线的名字,与采集配置名相同;
- mInputs:C++输入插件实例列表;
- mProcessors:原生处理插件实例列表;
- mflushers:C++输出插件实例列表;
- mGoPipelineWithInput:包含输入插件的Golang子流水线,可选;
- mGoPipelineWithoutInput:不包含输入插件的Golang子流水线,可选;
- mContext:流水线上下文;
- mProcessQueue:当前流水线的处理队列;
- mConfig:采集配置的原始内容。
其中需要说明的是mContext成员,它属于PipelineContext类,该类主要用于记录流水线的一些信息,便于流水线中的插件获取。PipelineContext类的成员主要包括:
- mConfigName:流水线的名称;
- mGlobalConfig:流水线级别的配置,由采集配置给出;
- mPipeline:指向当前流水线的指针;
- mLogger和mAlarm:用于打印日志和发送告警的全局组件。
采集配置管理优化
原有代码中的采集配置管理模块基本由ConfigManager类来负责,但实现极为混乱,没有任何设计思想可言,和其它模块的耦合严重,在开源社区面临“一改就错”的尴尬境地。因此,在新架构中,原有的采集配置管理模块将全部废弃,在保证兼容性的前提下,重新设计相关功能。
配置格式
限于历史原因,iLogtail可识别的采集配置格式包含两种:
商业版配置:采用平铺结构,没有任何层次,且仅支持JSON格式
{ "aliuid": "1234567890", "category": "test_logstore", "create_time": 1693370409, "defaultEndpoint": "cn-shanghai-intranet.log.aliyuncs.com", "delay_alarm_bytes": 0, "delay_skip_bytes": 0, "discard_none_utf8": false, "discard_unmatch": true, "docker_exclude_env": {}, "docker_exclude_label": {}, "docker_file": false, "docker_include_env": {}, "docker_include_label": {}, "enable": true, "enable_tag": false, "file_encoding": "utf8", "file_pattern": "*.log", "filter_keys": [], "filter_regs": [], "group_topic": "aaaaaaab", "keys": [ "k1,k2" ], "local_storage": true, "log_begin_reg": ".*", "log_path": "/home", "log_type": "common_reg_log", "log_tz": "", "max_depth": 10, "max_send_rate": -1, "merge_type": "topic", "preserve": true, "preserve_depth": 1, "priority": 0, "project_name": "test-project", "raw_log": false, "regex": [ "(\\d+)x(.*)" ], "region": "cn-shanghai", "send_rate_expire": 0, "sensitive_keys": [], "tail_existed": false, "timeformat": "", "topic_format": "none", "tz_adjust": false, "version": 3 }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
开源版配置:采用流水线结构,有较好的层次,但只支持YAML格式
inputs:
- Type: file_log
LogPath: /home
FilePattern: '*.log'
MaxDepth: 10
processors:
- Type: processor_regex_accelerate
Regex: '(\\d+)x(.*)'
Keys: ["k1", "k2"]
flushers:
- Type: flusher_sls
ProjectName: test-project
LogstoreName: test_logstore
Endpoint: cn-shanghai-intranet.log.aliyuncs.com
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
为了匹配新架构,iLogtail 2.0启用全新的采集配置结构:
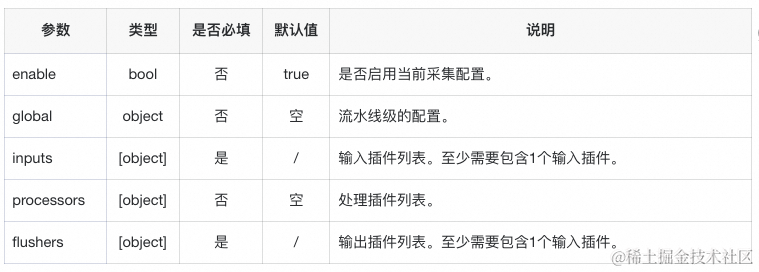
其中,inputs、processors、aggregators和flushers中可包含任意数量的插件,包括C++插件和Golang插件。
配置文件组织
在原有架构中,配置文件的组织没有统一的规范,包括文件格式不统一和存放位置不统一:
- 商业版管控端下发的配置为一个文件存放所有的采集配置,文件格式仅支持JSON,默认位置为/usr/local/ilogtail/user_log_config.json;
- 本地商业版配置既支持一个文件一个采集配置,也支持一个文件多个采集配置,文件格式仅支持JSON,默认存放位置为/etc/ilogtail/user_config.d目录和user_local_config.json;
- 本地开源版配置仅支持一个文件一个采集配置,文件格式仅支持YAML,默认存放位置为/etc/ilogtail/user_yaml_config.d目录;
- 开源版管控端下发的配置为一个文件一个采集配置,文件格式仅支持YAML,默认存放位置为/etc/ilogtail/remote_yaml_config.d目录;
为了统一上述混乱的情况,同时提供可扩展性,在新架构中,统一采用下述规则来组织文件:
- 每个文件存放一个采集配置,文件名即为采集配置名;
- 文件名后缀标识文件格式,支持json和yaml(或yml);
- 同一来源的采集配置放在同一个目录下,默认存放位置为/etc/ilogtail/config/,其中代表来源,目前包括:
-
- 商业版管控端下发的配置:enterprise
- 开源版管控端下发的配置:common
- 本地:local
配置热加载
在新架构中,对采集配置变更的监控全部通过监控磁盘配置文件是否变更来完成,相关工作统一由 ConfigWatcher 类来负责:
class ConfigWatcher {
public:
static ConfigWatcher* GetInstance();
ConfigDiff CheckConfigDiff();
void AddSource(const std::string& dir, std::mutex* mux = nullptr);
private:
std::vector<std::filesystem::path> mSourceDir;
std::map<std::string, std::pair<uintmax_t, std::filesystem::file_time_type>> mFileInfoMap;
// other members
};
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
可以看到,ConfigWatcher类对外提供两个方法:
- AddSource函数:向mSourceDir注册新的需要监控的存放采集配置的目录;
- CheckConfigDiff函数:检查所有被监控目录的采集配置文件是否有改变,返回新增、删除和存在修改的配置(记录在ConfigDiff结构体中),并在mFileInfoMap中更新最新的文件状态。
这里重点关注一下CheckConfigDiff函数,该函数不仅仅判断采集配置文件的状态是否有变化,还会解析配置并检查配置的合法性,整个流程如下所示:
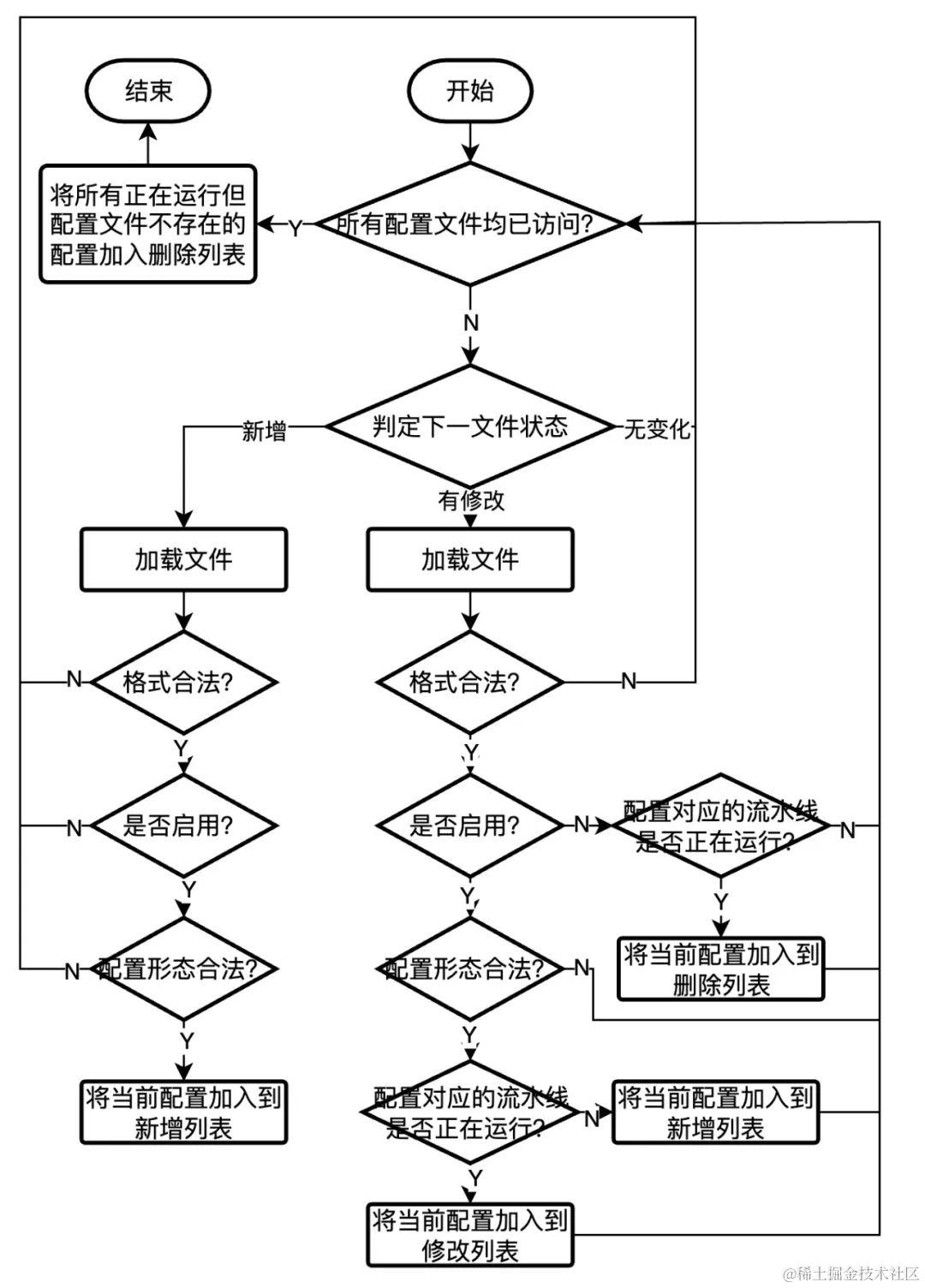
当CheckConfigDiff函数返回非空,则会进一步调用PipelineManager类的UpdatePipelines函数将配置加载成实际的流水线:
void logtail::PipelineManager::UpdatePipelines(ConfigDiff& diff) { for (const auto& name : diff.mRemoved) { mPipelineNameEntityMap[name]->Stop(true); mPipelineNameEntityMap.erase(name); } for (auto& config : diff.mModified) { auto p = BuildPipeline(std::move(config)); if (!p) { continue; } mPipelineNameEntityMap[config.mName]->Stop(false); mPipelineNameEntityMap[config.mName] = p; p->Start(); } for (auto& config : diff.mAdded) { auto p = BuildPipeline(std::move(config)); if (!p) { continue; } mPipelineNameEntityMap[config.mName] = p; p->Start(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
可以看到,采用上述两步走的配置热加载方法,可以最大程度提升流水线的容错能力,即仅当采集配置对应的流水线完全合法时才会进行加载。对于正在运行的流水线,如果因为某些原因导致对应的采集配置文件非法,则目前正在运行的流水线仍会继续正常运行,不会被非法的采集配置影响。
远程配置下发
在原有架构中,所有的远程配置下发功能(包括商业版和开源版管控端)都由ConfigManager类来负责,完全不具备可扩展性。为了解决这一问题,在新架构中,我们定义抽象基类ConfigProvider类用于统一所有拉取远程配置的行为:
class ConfigProvider {
public:
virtual void Init(const std::string& dir);
virtual void Stop() = 0;
protected:
std::filesystem::path mSourceDir;
mutable std::mutex mMux;
};
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
其中,各成员函数的说明如下:
- Init函数:执行初始化操作,创建mSourceDir目录并调用ConfigWatcher类的AddSource函数注册目录,同时启动线程定时拉取远端配置。
- Stop函数:停止ConfigProvider。
对于不同的配置来源,可以从ConfigProvider类派生不同的子类,目前包括:
- 商业版管控端配置拉取:EnterpriseConfigProvider类;
- 开源版管控端配置拉取:CommonConfigProvider类。
进程配置管理优化
在原有架构中,非采集配置级(即进程级和模块级)参数统一由AppConfig类进行管理,由此带来的后果包括:
- AppConfig类无限增长,内部缺乏有效组织,时间一久便难以维护;
- 几乎所有模块都要通过AppConfig类来获取参数,因此代码中存在大量的AppConfig::GetInstance()函数,造成代码冗余和阅读不便。
- 有一些参数仅在商业版中使用,导致AppConfig类需要维护开源版和商业版两份,增加出现不一致的概率。
为了解决这一问题,在新架构中,AppConfig类仅维护进程级别的参数(如内存上限等)和多个模块共用的参数。对于其他仅在单个模块中使用的参数,统一在相应的模块中维护,从而有效解决上述问题。
商业版代码嵌入方式优化
在原有架构中,由于类的功能界限模糊,各个类之间存在严重的依赖和耦合,因此商业版特有的功能代码散落在各个文件中,导致无法从代码库中干净剥离,只能通过文件替换的方式来完成开源和商业版代码的切换,严重影响开发效率。
为了彻底解决这一问题,需要将商业版功能进行归类和重新整合。然后,针对不同的需求和场景,使用不同的嵌入策略:
商业版独有的功能:
- 组成单独的类放在单独的文件中,直接追加到开源版的目录中;
- 对于公共文件中的调用点,使用__ENTERPRISE__宏来控制开源和商业版的编译行为;
| 例: 商业版代码中使用ShennongManager类来采集特定指标,该类包含一个线程资源,需要在配置变更时暂停和启动线程。因此,在PipelineManager类中存在如下调用点: |
|---|
#ifdef __ENTERPRISE__
ShennongManager::GetInstance()->Pause();
#endif
// ...
#ifdef __ENTERPRISE__
ShennongManager::GetInstance()->Resume();
#endif
- 1
- 2
- 3
- 4
- 5
- 6
- 7
商业版和开源版行为存在差异:
- 尽可能使用单例模式;
- 将开源版的类作为基类,然后将类中行为不同的方法声明为虚函数;
- 将商业版的类作为开源类的派生类,并重写虚函数;
- 在GetInstance函数中使用__ENTERPRISE__宏和指向基类的指针来控制实际生效的类;
- 将商业版文件直接追加到开源版的目录中;
例:商业版和开源版在发送可观测数据方面存在差异,因此定义开源版的ProfileSender类如下: |
|---|
class ProfileSender { public: static ProfileSender* GetInstance(); virtual void SendToProfileProject(const std::string& region, sls_logs::LogGroup& logGroup); // other members }; ProfileSender* ProfileSender::GetInstance() { #ifdef __ENTERPRISE__ static ProfileSender* ptr = new EnterpriseProfileSender(); #else static ProfileSender* ptr = new ProfileSender(); #endif return ptr; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
为了实现上述能力,需要对原有代码进行重组织,主要工作如下:
- 将与商业版配置拉取相关的代码从ConfigManager类和EventDispatcher类中剥离出来,重新组成EnterpriseConfigProvider类;
- 将与商业版鉴权相关的代码从ConfigManager类中剥离出来,移动到EnterpriseSLSControl类中;
- 将与商业版可观测数据发送相关的代码从ConfigManager类中剥离出来,移动到EnterpriseProfileSender类中;
- 将商业版特殊的指标监控代码从EventDispatcher类中剥离出来,重新组成ShennongManager类;
- 将与商业版相关的非配置级参数从AppConfig类中剥离出来,分别移动到上述新建立的类中。
除此以外,由于主文件中没有类的概念,因此将与配置管理相关的内容从主文件logtail.cpp剥离出来,和原EventDispatcher类中的Dispatch函数进行重组,形成Application类,尽量实现开源版和商业版的代码复用。
在完成上述所有工作之后,最后修CMakeLists.txt文件,增加如下逻辑:
option(ENABLE_ENTERPRISE "enable enterprise feature")
if (ENABLE_ENTERPRISE)
add_definitions(-D__ENTERPRISE__)
include(${CMAKE_CURRENT_SOURCE_DIR}/enterprise_options.cmake)
else ()
include(${CMAKE_CURRENT_SOURCE_DIR}/options.cmake)
endif ()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
至此,商业版代码与开源版代码的分离工作全部完成,商业版代码文件以纯追加的方式嵌入到开源版代码中,再也不用替换文件,极大地提升了开发效率。
思考
从决定重构之初到iLogtail 2.0形态初现,前后至少经历了大半年的时间。在传统认知里,重构是一件吃力不讨好的事情,稍不留神就会引发各种兼容性问题,甚至故障。尤其是对于iLogtail这种已有10年历史,历史包袱非常重的产品而言,进行架构升级可以说是如履薄冰。但即便如此,为什么还要坚持去做重构?一句话,长痛不如短痛。10年前的需求与现行产品定位之间的差异日益增大,强行在原有架构上继续演进只会带来更多潜在的问题,甚至于无法演进。因此,想要在可观测数据采集领域继续引领行业,在开源社区扩大影响,架构升级是一个必经的途径。
话虽如此,对原有的iLogtail进行架构升级绝非易事。从决定重构到最终成型,在此期间遇到了诸多挑战和困难,也走了不少的弯路,这里简单总结一下:
1. 新架构应该如何设计?
虽然知道原有架构不合理,且对发展方向有一个大概的认知,但是新架构究竟如何设计却是一个值得商榷的问题。显然,对于任何领域,没有输入自然就不会有输出。得益于日常对其他主流可观测数据采集器架构的持续调研和学习,笔者对现代可观测流水线的基本理念和设计思想有了一个基本的认知。在设计iLogtail的新架构时,主要采用如下原则:
- 对于可观测流水线的通用概念(如数据类型和流水线定义等),iLogtail要尽量做到和领域内其它竞品保持一致,避免独树一帜给用户迁移带来不便和困惑;
- 对于架构实现,不能简单照搬其他主流可观测数据采集器的架构,而是在吸收其设计思想的前提下,针对iLogtail自身的特点(如双语言实现)进行原创设计,适合自己的才是最好的。
- 对于iLogtail的自身优势(如C++的高性能和配置热加载),在完整保留的同时,还需要将原本阻止优势发挥的限制尽可能地去除,使得自身优势能够在更多的场景中发挥作用,提升产品的核心竞争力。
2. 确定好新架构后,如何分阶段来完成架构升级?
从前文的介绍可以看到,新架构与原有架构的区别较大,升级涉及到的模块众多,工作量大。显然,一口气完成架构升级是不可行的,必须分阶段分模块进行,在CI的配合下确保每一个模块的重构都是符合预期的。
那怎么分阶段呢?这里就走过一些弯路,因为从架构设计的角度,我们会习惯性地从外往里进行思考(即按照上文实践一节从后往前的顺序),但这会陷入一个层层依赖的问题。例如,在重构配置管理模块的时候,会依赖Pipeline类和PipelineManager类。为此,需要优先重构这两个类。但是重构这两个类的时候,又会依赖各种插件类的实现。按照这个顺序进行下去,最终的依赖便是PipelineEvent类。显然,按照这个顺序进行下去,相当于一口气完成架构升级,因此根本不可行。
正确的做法是由里向外进行重构,先重构PipelineEvent类,再重构插件类,以此类推最后重构Application类,即按照上文介绍的顺序。借助这个顺序,就可以将整个架构升级过程分成至少6个大阶段,每个阶段都可以单独CI而不会影响既有功能的正常工作。但是,想要正确执行这种顺序,就必须要求对目标架构有一个完整清晰的认知和详细的设计。如果对目标架构的认识只停留在粗框架的层面,那必然无法准确得到各个模块的依赖关系,从而得到并非完全正确的阶段划分,最终影响实际重构的进度和效率。
任何时候,想清楚了再做永远是事半功倍的基本前提,对于架构升级来说尤甚。
3. iLogtail原有的测试体系不健全,如何保证重构后的代码不引入兼容性问题?
这或许是iLogtail重构最头疼的问题,原有的iLogtail UT代码覆盖率不高,回归测试只覆盖主流场景,对于小众功能基本属于监控盲区。为此,只能对原有代码进行完整的梳理和阅读,重点关注如下几个点:
- 每个类具体负责的功能,为后续类合并和重构奠定基础;
- 类间依赖,尤其是相关参数在多个类内使用的情况;
- 不常用的功能点,了解其预期行为,从而为补充UT作准备。
当然,上述方法也只能尽可能避免重构引发的不兼容问题,但是在现有的条件和时间允许范围内,这已经是最佳策略。事实上,在整个架构升级过程中,有大约2个月左右的时间是在执行上述操作的,这也为后续实际重构奠定了坚实的基础。
4. 如何保证代码质量?
在决定进行架构升级时,笔者才从业一年,虽说有一定的C++开发经验,但是对于重构这么大的事确实没有经历过。如何保证新写的代码符合通用规范,同时又保证运行效率,是一个亟需解决的问题。
为此,在设计新架构的间隙,笔者又重新翻阅了一些经典著作,例如设计模式相关的《Design Patterns: Elements of Reusable Object-Oriented Software》,C++开发相关的《Effective C++》系列、《C++ Concurrency in Action》等书籍,同时也通过一些博客和官方文档学习C++17的新特性。与之前抱着学习的态度去阅读不同,当你带着问题和需求去重新阅读这些著作时,会更能领悟到书中一些总结性经验的实际含义。凭借着这些消化吸收后的经验,笔者一步一步打磨自己的代码,并适时对新代码进行小范围的二次重构以增强代码的复用和可扩展性。
总结
回想整个架构升级的过程,从接受任务时的迷茫,到最后升级基本完成时的喜悦,半年多的时间经历了很多,也成长了很多。对于iLogtail而言,经历本次架构升级,也算是浴火重生,向着现代顶流可观测数据采集器的目标又迈进了一大步。不论对于用户,还是对于社区开发者,相信所有人都会从本次架构升级中受益。让我们一起期待iLogtail在未来继续蓬勃发展,提供更快更强的数据采集能力!

