
- 1生成Git ssh公钥和私钥(ppk)文件_ppk文件
- 2Mybatis之批处理流式查询_mybatis流查询
- 3关于AndroidStudio中如何将文件拷贝至SD卡根目录问题的解决方法
- 4YoloV8改进策略:BackBone改进|GCNet(独家原创)|附结构图
- 5Vue 前端笔记 | MVVM、MVC 关系与区别_为什么angular是mvc vue是mvvm
- 6python获取cookie值的方法_Python获取Cookie、设置Cookie的N种方法
- 7图的概念以及常见的图论问题介绍_完全子图定义
- 8【YOLOv5改进系列(11)】高效涨点----添加soft-nms(IoU,GIoU,DIoU,CIoU,EIoU,SIoU)到yolov5中_yolo调整极大值抑制
- 9为什么浮点数运算的时候会有精度丢失的风险?如何解决浮点数运算的精度丢失问题?_浮点数 转为cstring 精度丢失
- 10Mysql 搭建MHA高可用架构,实现自动failover,完成主从切换_mysql的mga高可用
3、动手学深度学习——多层感知机:多层感知机的实现(从零实现+内置函数实现)_spss多层感知器中输出层函数
赞
踩
1、多层感知机基础知识
1. 简述
加入隐藏层和激活函数,可以将线性模型变成非线性模型,引入了非线性拟合能力。
我们通过在网络中加入一个或多个隐藏层来克服线性模型的限制,使其能处理更普遍的函数关系类型。要做到这一点,最简单的方法是将许多全连接层堆叠在一起。每一层都输出到上面的层,直到生成最后的输出。
我们可以把前 L − 1 L-1 L−1层看作表示,把最后一层看作线性预测器。这种架构通常称为多层感知(multilayer perceptron),通常缩写为MLP。下面,我们以图的方式描述了多层感知机
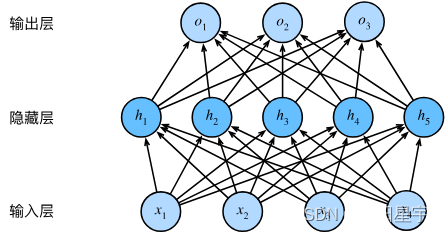
这个多层感知机有4个输入,3个输出,其隐藏层包含5个隐藏单元。输入层不涉及任何计算,因此使用此网络产生输出只需要实现隐藏层和输出层的计算。因此,这个多层感知机中的层数为2。
注意,这两个层都是全连接的。每个输入都会影响隐藏层中的每个神经元,而隐藏层中的每个神经元又会影响输出层中的每个神经元。然而,具有全连接层的多层感知机的参数开销可能会高得令人望而却步。即使在不改变输入或输出大小的情况下,可能在参数节约和模型有效性之间进行权衡。
2. 从线性到非线性
我们通过矩阵 X ∈ R n × d \mathbf{X} \in \mathbb{R}^{n \times d} X∈Rn×d来表示 n n n个样本的小批量,其中每个样本具有 d d d个输入特征。对于具有 h h h个隐藏单元的单隐藏层多层感知机,用 H ∈ R n × h \mathbf{H} \in \mathbb{R}^{n \times h} H∈Rn×h表示隐藏层的输出,称为隐藏表示(hidden representations)。
在数学或代码中, H \mathbf{H} H也被称为隐藏层变量(hidden-layer variable)或隐藏变量(hidden variable)。因为隐藏层和输出层都是全连接的,所以我们有隐藏层权重 W ( 1 ) ∈ R d × h \mathbf{W}^{(1)} \in \mathbb{R}^{d \times h} W(1)∈Rd×h和隐藏层偏置 b ( 1 ) ∈ R 1 × h \mathbf{b}^{(1)} \in \mathbb{R}^{1 \times h} b(1)∈R1×h以及输出层权重 W ( 2 ) ∈ R h × q \mathbf{W}^{(2)} \in \mathbb{R}^{h \times q} W(2)∈Rh×q和输出层偏置 b ( 2 ) ∈ R 1 × q \mathbf{b}^{(2)} \in \mathbb{R}^{1 \times q} b(2)∈R1×q。形式上,我们按如下方式计算单隐藏层多层感知机的输出 O ∈ R n × q \mathbf{O} \in \mathbb{R}^{n \times q} O∈Rn×q:
H
=
X
W
(
1
)
+
b
(
1
)
,
O
=
H
W
(
2
)
+
b
(
2
)
.
注意在添加隐藏层之后,模型现在需要跟踪和更新额外的参数。可我们能从中得到什么好处呢?在上面定义的模型里,我们没有好处!原因很简单:上面的隐藏单元由输入的仿射函数给出,而输出(softmax操作前)只是隐藏单元的仿射函数。仿射函数的仿射函数本身就是仿射函数,但是我们之前的线性模型已经能够表示任何仿射函数。
我们可以证明这一等价性,即对于任意权重值,我们只需合并隐藏层,便可产生具有参数 W = W ( 1 ) W ( 2 ) \mathbf{W} = \mathbf{W}^{(1)}\mathbf{W}^{(2)} W=W(1)W(2)和 b = b ( 1 ) W ( 2 ) + b ( 2 ) \mathbf{b} = \mathbf{b}^{(1)} \mathbf{W}^{(2)} + \mathbf{b}^{(2)} b=b(1)W(2)+b(2)的等价单层模型:
O = ( X W ( 1 ) + b ( 1 ) ) W ( 2 ) + b ( 2 ) = X W ( 1 ) W ( 2 ) + b ( 1 ) W ( 2 ) + b ( 2 ) = X W + b . \mathbf{O} = (\mathbf{X} \mathbf{W}^{(1)} + \mathbf{b}^{(1)})\mathbf{W}^{(2)} + \mathbf{b}^{(2)} = \mathbf{X} \mathbf{W}^{(1)}\mathbf{W}^{(2)} + \mathbf{b}^{(1)} \mathbf{W}^{(2)} + \mathbf{b}^{(2)} = \mathbf{X} \mathbf{W} + \mathbf{b}. O=(XW(1)+b(1))W(2)+b(2)=XW(1)W(2)+b(1)W(2)+b(2)=XW+b.
为了发挥多层架构的潜力,我们还需要一个额外的关键要素:
在仿射变换之后对每个隐藏单元应用非线性的激活函数(activation function)
σ
\sigma
σ。激活函数的输出(例如,
σ
(
⋅
)
\sigma(\cdot)
σ(⋅))被称为活性值(activations)。一般来说,有了激活函数,就不可能再将我们的多层感知机退化成线性模型:
H
=
σ
(
X
W
(
1
)
+
b
(
1
)
)
,
O
=
H
W
(
2
)
+
b
(
2
)
.
由于 X \mathbf{X} X中的每一行对应于小批量中的一个样本,出于记号习惯的考量,我们定义非线性函数 σ \sigma σ也以按行的方式作用于其输入,即一次计算一个样本。本节应用于隐藏层的激活函数通常不仅按行操作,也按元素操作。这意味着在计算每一层的线性部分之后,我们可以计算每个活性值,而不需要查看其他隐藏单元所取的值。对于大多数激活函数都是这样。
为了构建更通用的多层感知机,我们可以继续堆叠这样的隐藏层,例如 H ( 1 ) = σ 1 ( X W ( 1 ) + b ( 1 ) ) \mathbf{H}^{(1)} = \sigma_1(\mathbf{X} \mathbf{W}^{(1)} + \mathbf{b}^{(1)}) H(1)=σ1(XW(1)+b(1))和 H ( 2 ) = σ 2 ( H ( 1 ) W ( 2 ) + b ( 2 ) ) \mathbf{H}^{(2)} = \sigma_2(\mathbf{H}^{(1)} \mathbf{W}^{(2)} + \mathbf{b}^{(2)}) H(2)=σ2(H(1)W(2)+b(2)),一层叠一层,从而产生更有表达能力的模型。
3. 激活函数
激活函数(activation function)通过计算加权和并加上偏置来确定神经元是否应该被激活, 它们将输入信号转换为输出的可微运算。 大多数激活函数都是非线性的。 由于激活函数是深度学习的基础,下面简要介绍一些常见的激活函数。
先导入包
%matplotlib inline
import torch
from d2l import torch as d2l
- 1
- 2
- 3
(1)Sigmoid函数
对于一个定义域在 R \mathbb{R} R中的输入,sigmoid函数将输入变换为区间(0, 1)上的输出]。因此,sigmoid通常称为挤压函数(squashing function):它将范围(-inf, inf)中的任意输入压缩到区间(0, 1)中的某个值:
sigmoid ( x ) = 1 1 + exp ( − x ) . \operatorname{sigmoid}(x) = \frac{1}{1 + \exp(-x)}. sigmoid(x)=1+exp(−x)1.
在最早的神经网络中,科学家们感兴趣的是对“激发”或“不激发”的生物神经元进行建模。因此,这一领域的先驱可以一直追溯到人工神经元的发明者麦卡洛克和皮茨,他们专注于阈值单元。阈值单元在其输入低于某个阈值时取值0,当输入超过阈值时取值1。
当人们逐渐关注到到基于梯度的学习时,sigmoid函数是一个自然的选择,因为它是一个平滑的、可微的阈值单元近似。当我们想要将输出视作二元分类问题的概率时,sigmoid仍然被广泛用作输出单元上的激活函数(sigmoid可以视为softmax的特例)。然而,sigmoid在隐藏层中已经较少使用,它在大部分时候被更简单、更容易训练的ReLU所取代。在后面关于循环神经网络的章节中,我们将描述利用sigmoid单元来控制时序信息流的架构。
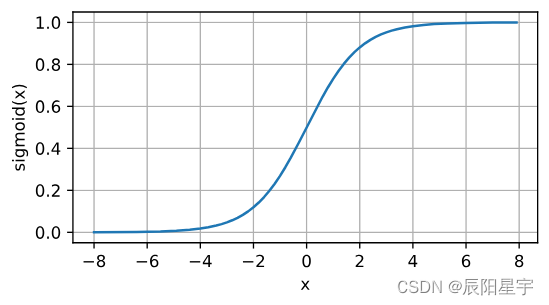
下面,我们绘制sigmoid函数。注意,当输入接近0时,sigmoid函数接近线性变换。
y = torch.sigmoid(x)
d2l.plot(x.detach(), y.detach(), 'x', 'sigmoid(x)', figsize=(5, 2.5))
- 1
- 2
sigmoid函数的导数为下面的公式:
d d x sigmoid ( x ) = exp ( − x ) ( 1 + exp ( − x ) ) 2 = sigmoid ( x ) ( 1 − sigmoid ( x ) ) . \frac{d}{dx} \operatorname{sigmoid}(x) = \frac{\exp(-x)}{(1 + \exp(-x))^2} = \operatorname{sigmoid}(x)\left(1-\operatorname{sigmoid}(x)\right). dxdsigmoid(x)=(1+exp(−x))2exp(−x)=sigmoid(x)(1−sigmoid(x)).
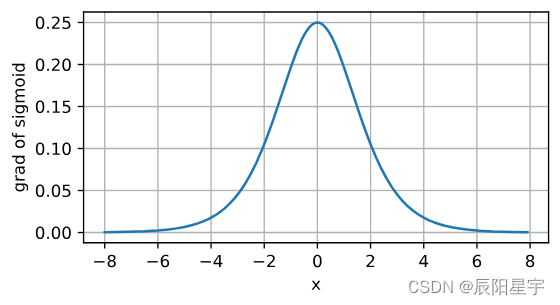
sigmoid函数的导数图像如下所示。注意,当输入为0时,sigmoid函数的导数达到最大值0.25;而输入在任一方向上越远离0点时,导数越接近0。
# 清除以前的梯度
x.grad.data.zero_()
y.backward(torch.ones_like(x),retain_graph=True)
d2l.plot(x.detach(), x.grad, 'x', 'grad of sigmoid', figsize=(5, 2.5))
- 1
- 2
- 3
- 4
(2)tanh函数
与sigmoid函数类似,tanh(双曲正切)函数也能将其输入压缩转换到区间(-1, 1)上。
tanh函数的公式如下:
tanh ( x ) = 1 − exp ( − 2 x ) 1 + exp ( − 2 x ) . \operatorname{tanh}(x) = \frac{1 - \exp(-2x)}{1 + \exp(-2x)}. tanh(x)=1+exp(−2x)1−exp(−2x).
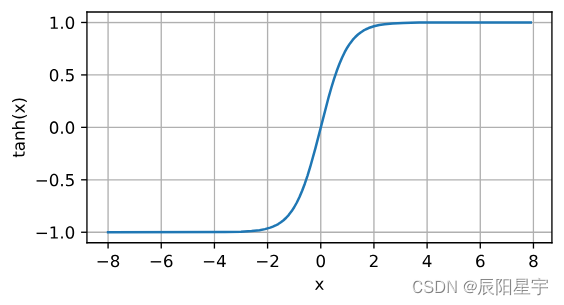
下面我们绘制tanh函数。注意,当输入在0附近时,tanh函数接近线性变换。函数的形状类似于sigmoid函数,不同的是tanh函数关于坐标系原点中心对称。
y = torch.tanh(x)
d2l.plot(x.detach(), y.detach(), 'x', 'tanh(x)', figsize=(5, 2.5))
- 1
- 2
tanh函数的导数是:
d d x tanh ( x ) = 1 − tanh 2 ( x ) . \frac{d}{dx} \operatorname{tanh}(x) = 1 - \operatorname{tanh}^2(x). dxdtanh(x)=1−tanh2(x).
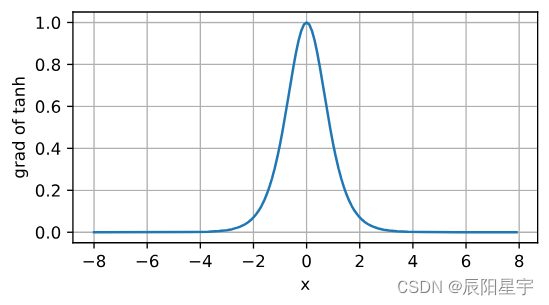
tanh函数的导数图像如下所示。当输入接近0时,tanh函数的导数接近最大值1。与我们在sigmoid函数图像中看到的类似,输入在任一方向上越远离0点,导数越接近0。
# 清除以前的梯度
x.grad.data.zero_()
y.backward(torch.ones_like(x),retain_graph=True)
d2l.plot(x.detach(), x.grad, 'x', 'grad of tanh', figsize=(5, 2.5))
- 1
- 2
- 3
- 4
(3)ReLU函数
最受欢迎的激活函数是修正线性单元(Rectified linear unit,ReLU),因为它实现简单,同时在各种预测任务中表现良好。ReLU提供了一种非常简单的非线性变换。给定元素 x x x,ReLU函数被定义为该元素与 0 0 0的最大值:
ReLU ( x ) = max ( x , 0 ) . \operatorname{ReLU}(x) = \max(x, 0). ReLU(x)=max(x,0).
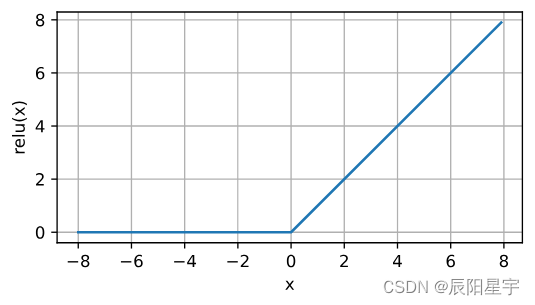
通俗地说,ReLU函数通过将相应的活性值设为0,仅保留正元素并丢弃所有负元素。为了直观感受一下,我们可以画出函数的曲线图。正如从图中所看到,激活函数是分段线性的。
x = torch.arange(-8.0, 8.0, 0.1, requires_grad=True)
y = torch.relu(x)
d2l.plot(x.detach(), y.detach(), 'x', 'relu(x)', figsize=(5, 2.5))
- 1
- 2
- 3
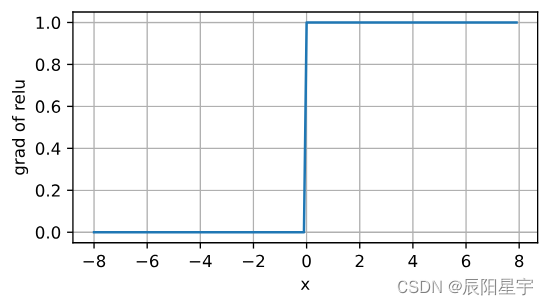
当输入为负时,ReLU函数的导数为0,而当输入为正时,ReLU函数的导数为1。 注意,当输入值精确等于0时,ReLU函数不可导。 在此时,我们默认使用左侧的导数,即当输入为0时导数为0。 我们可以忽略这种情况,因为输入可能永远都不会是0。 这里引用一句古老的谚语,“如果微妙的边界条件很重要,我们很可能是在研究数学而非工程”, 这个观点正好适用于这里。 下面我们绘制ReLU函数的导数。
y.backward(torch.ones_like(x), retain_graph=True)
d2l.plot(x.detach(), x.grad, 'x', 'grad of relu', figsize=(5, 2.5))
- 1
- 2
使用ReLU的原因是,它求导表现得特别好:要么让参数消失,要么让参数通过。这使得优化表现得更好,并且ReLU减轻了困扰以往神经网络的梯度消失问题(稍后将详细介绍)。
注意,ReLU函数有许多变体,包括参数化ReLU(Parameterized ReLU,pReLU)该变体为ReLU添加了一个线性项,因此即使参数是负的,某些信息仍然可以通过:
pReLU ( x ) = max ( 0 , x ) + α min ( 0 , x ) . \operatorname{pReLU}(x) = \max(0, x) + \alpha \min(0, x). pReLU(x)=max(0,x)+αmin(0,x).
总结一下,我们现在了解了如何结合非线性函数来构建具有更强表达能力的多层神经网络架构。 顺便说一句,这些知识已经让你掌握了一个类似于1990年左右深度学习从业者的工具。 在某些方面,你比在20世纪90年代工作的任何人都有优势, 因为你可以利用功能强大的开源深度学习框架,只需几行代码就可以快速构建模型, 而以前训练这些网络需要研究人员编写数千行的C或Fortran代码。
参考文章:4.1. 多层感知机
2、多层感知机的从零开始实现
为了与之前softmax回归获得的结果进行比较,我们将继续使用Fashion-MNIST图像分类数据集。
导入包
import torch
from torch import nn
from d2l import torch as d2l
- 1
- 2
- 3
1. 获取数据集
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
- 1
- 2
2. 初始化模型参数
回想一下,Fashion-MNIST中的每个图像由 28×28=784个灰度像素值组成。 所有图像共分为10个类别。 忽略像素之间的空间结构, 我们可以将每个图像视为具有784个输入特征 和10个类的简单分类数据集。 首先,我们将实现一个具有单隐藏层的多层感知机, 它包含256个隐藏单元。 注意,我们可以将这两个变量都视为超参数(层数、每层单元个数)。 通常,我们选择2的若干次幂作为层的宽度。 因为内存在硬件中的分配和寻址方式,这么做往往可以在计算上更高效。
我们用几个张量来表示我们的参数。 注意,对于每一层我们都要记录一个权重矩阵和一个偏置向量。 跟以前一样,我们要为损失关于这些参数的梯度分配内存。
num_inputs, num_outputs, num_hiddens = 784, 10, 256
W1 = nn.Parameter(torch.randn(
num_inputs, num_hiddens, requires_grad=True) * 0.01)
b1 = nn.Parameter(torch.zeros(num_hiddens, requires_grad=True))
W2 = nn.Parameter(torch.randn(
num_hiddens, num_outputs, requires_grad=True) * 0.01)
b2 = nn.Parameter(torch.zeros(num_outputs, requires_grad=True))
params = [W1, b1, W2, b2]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
(1)torch.randn(n, m):生成均值为0,方差为1符合正态分布的矩阵/向量/标量,其中n代表行数,m代表列数。
(2)nn.Parameter:声明tensor为参数parameter。(在代码里也可以不用加)。
(3)乘上0.01是为了缩小张量,避免梯度爆炸。
2. 激活函数
我们将采用ReLU激活函数
def relu(X):
a = torch.zeros_like(X)
return torch.max(X, a)
- 1
- 2
- 3
3. 模型
含有一层隐藏层的神经网络
def net(X):
X = X.reshape((-1, num_inputs))
H = relu(X @ W1 + b1) # 这里“@”代表矩阵乘法
return (H @ W2 + b2)
- 1
- 2
- 3
- 4
4. 损失函数
采用softmax作为损失函数
loss = nn.CrossEntropyLoss(reduction='none')
- 1
5. 训练
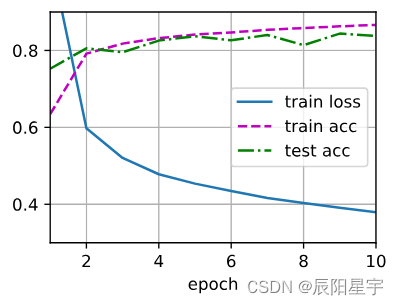
num_epochs, lr = 10, 0.1
updater = torch.optim.SGD(params, lr=lr)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, updater)
- 1
- 2
- 3
6. 预测评估
d2l.predict_ch3(net, test_iter)
- 1

* 完整代码
import torch from torch import nn from d2l import torch as d2l # 获取数据集 batch_size = 256 train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size) # 设置参数 num_inputs, num_outputs, num_hiddens = 784, 10, 256 W1 = nn.Parameter(torch.randn( num_inputs, num_hiddens, requires_grad=True) * 0.01) b1 = nn.Parameter(torch.zeros(num_hiddens, requires_grad=True)) W2 = nn.Parameter(torch.randn( num_hiddens, num_outputs, requires_grad=True) * 0.01) b2 = nn.Parameter(torch.zeros(num_outputs, requires_grad=True)) params = [W1, b1, W2, b2] # 激活函数 def relu(X): a = torch.zeros_like(X) return torch.max(X, a) # 设置模型 def net(X): X = X.reshape((-1, num_inputs)) H = relu(X @ W1 + b1) # 这里“@”代表矩阵乘法 return (H @ W2 + b2) # 损失函数 loss = nn.CrossEntropyLoss(reduction='none') # 设置超参数、优化算法 num_epochs, lr = 10, 0.1 updater = torch.optim.SGD(params, lr=lr) # 训练 d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, updater) # 预测 d2l.predict_ch3(net, test_iter)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
参考文章:多层感知机的从零开始实现
3、多层感知机的简洁实现
导入包
import torch
from torch import nn
from d2l import torch as d2l
- 1
- 2
- 3
1. 获取数据集
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
- 1
- 2
2. 模型
与softmax回归的简洁实现相比, 唯一的区别是我们添加了2个全连接层(之前我们只添加了1个全连接层)。 第一层是隐藏层,它包含256个隐藏单元,并使用了ReLU激活函数。 第二层是输出层。
# 设置模型
net = nn.Sequential(nn.Flatten(), # Flatten():让28×28展成784,最后将数据变成(batch_size, 784)形式
nn.Linear(784, 256), # 引入线性层
nn.ReLU(), # 对该层加一个激活函数
nn.Linear(256, 10))
# 初始化权重
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01) # 将采样得到的正态分布数据赋给权重矩阵m.weight中的每个元素
net.apply(init_weights); # 将init_weights函数应用到神经网络模型net的所有模块上,以实现对所有线性层的权重初始化。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
训练过程的实现与我们实现softmax回归时完全相同, 这种模块化设计使我们能够将与模型架构有关的内容独立出来。
3. 训练
设置超参数、损失函数、优化算法,进行训练
lr, num_epochs = 0.1, 10
loss = nn.CrossEntropyLoss(reduction='none')
trainer = torch.optim.SGD(net.parameters(), lr=lr)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)
- 1
- 2
- 3
- 4
- 5
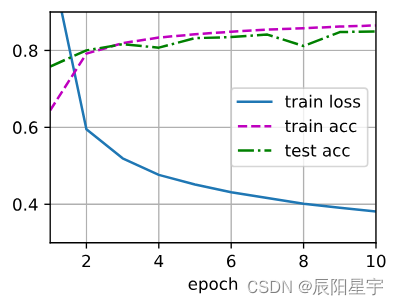
4. 预测
d2l.predict_ch3(net, test_iter)
- 1
* 完整代码
import torch from torch import nn from d2l import torch as d2l # 获取数据集 batch_size = 256 train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size) # 设置模型 net = nn.Sequential(nn.Flatten(), nn.Linear(784, 256), nn.ReLU(), nn.Linear(256, 10)) # 初始化权重 def init_weights(m): if type(m) == nn.Linear: nn.init.normal_(m.weight, std=0.01) net.apply(init_weights) # 设置超参数、损失函数、优化算法 lr, num_epochs = 0.1, 10 loss = nn.CrossEntropyLoss(reduction='none') trainer = torch.optim.SGD(net.parameters(), lr=lr) # 训练 d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer) # 预测 d2l.predict_ch3(net, test_iter)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
参考文章:4.3. 多层感知机的简洁实现

