
- 1【Android Studio程序开发】常用布局--线性布局LinearLayout_android studio linearlayout布局
- 2基础课5——垂直领域对话系统架构_垂直领域问答对话实现方法
- 3WPF RichTextBox的常用方法和属性(内容的读取/导入等)_wpf richtextbox 中超链接获取输入的值
- 4SI,SIS,SIR,SEIRD模型_si模型
- 5simpleitk打开dicom文件
- 6diffusion model原理和算法伪代码_diffusion loss
- 7国产中间件概述
- 8solidity Dapp ERC20添加即空投合约_erc20代币能不能加入联盟链
- 9自动化机器学习AutoML之flaml:利用flaml框架自动寻找最优算法及其对应最佳参数python
- 10速递|AI搜索引擎Perplexity AI再获融资7000万美元,估值达5.2亿美元
CVPR 2022 | 高分论文!港科大/IDEA/清华提出DN-DETR: 加速DETR收敛的去噪训练
赞
踩
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
作者:弃之 | 已授权转载(源:知乎)编辑:CVer
https://zhuanlan.zhihu.com/p/478079763
PR一下我们在CVPR 2022上的paper DN-DETR: Accelerate DETR Training by Introducing Query DeNoising(得分112),我们对DETR收敛缓慢给出了一个深刻的理解,并第一次提出了全新的去噪训练(DeNoising training)解决DETR decoder二分图匹配 (bipartite graph matching)不稳定的问题,可以让模型收敛速度翻倍,并对检测结果带来显著提升(+1.9AP)。该方法简易实用,可以广泛运用到各种DETR模型当中,以微小的训练代价带来显著提升,3个审稿人中2个都对论文给出了满分!

DN-DETR: Accelerate DETR Training by Introducing Query DeNoising
论文:https://arxiv.org/abs/2203.01305
项目地址:github.com/FengLi-ust/DN-DETR
先看看加速收敛的效果!在ResNet50 backbone下,基于Deformable DETR的DN-Deformable-DETR在12epoch结果达到43.4AP,50epoch结果达到48.6AP,让DETR模型在12 epoch setting下也可以取得好的效果。
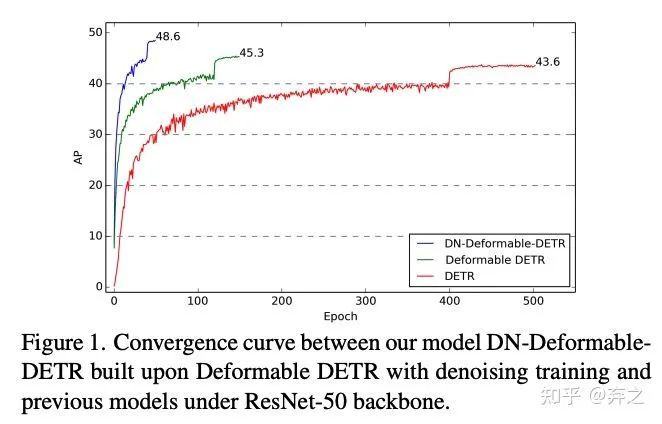
为什么DETR系列模型收敛缓慢?
这得从DETR[1]的最初设计说起。DETR把目标检测做成了一个set prediction的问题,并利用匈牙利匹配(Hungarian matching)算法来解决decoder输出的objects和ground-truth objects的匹配。因此,匈牙利算法匹配的离散性和模型训练的随机性,导致ground-truth的匹配变成了一个动态的、不稳定的过程。
要解决这个问题,我们要先理解decoder到底在做什么。如今decoder queries在很多工作中被解读为anchor坐标, 我们可以按照DAB-DETR[2]把它看作一个四维的bounding box(检测框): (x, y, w, h)
在每一层decoder中都会去预测相对偏移量 (△x, △y, △w, △h) 并去更新检测框,得到一个更加精确的检测框预测 (x', y', w', h') = (x, y, w, h) + (△x, △y, △w, △h) ,并传到下一层中。
我们可以把decoder看成在学习两个东西:
good anchors(anchor位置) (x, y, w, h)
relative offset(相对偏移) (△x, △y, △w, △h)
decoder queries可以看成是anchor位置的学习,而不稳定的匹配会导致不稳定的anchor,从而使得相对偏移的学习变得困难。因此,我们使用一个denoising task作为一个shortcut来学习相对偏移,它跳过了匹配过程直接进行学习。如果我们把query像上述一样看作四维坐标,可以通过在真实框附近添加一个微小的扰动作为噪声,这样我们的denoising task就有了一个清晰的目标--直接重建真实框而不需要匈牙利匹配。
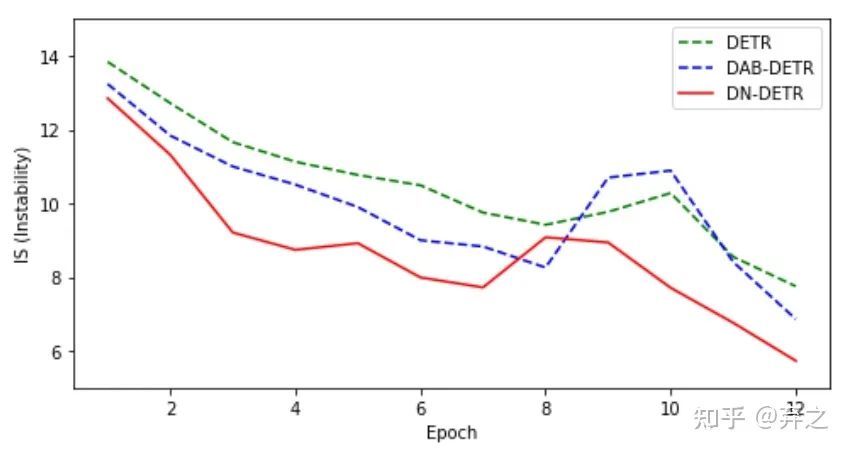
我们设计了一个指标IS(Instability)通过比较相邻epoch之间匹配的不一致性来衡量匹配的不稳定性,如下图所示。这表明DN-DETR能有效提高匹配的稳定性。
DN-DETR架构
我们建立在DAB-DETR的基础上实现DN-DETR,因为DAB-DETR是DN之前最强的模型之一,而且它显示的把decoder query表示为四维坐标很适合添加denoising training。
沿着Conditional DETR[3],之后的工作如DAB-DETR都把decoder query设计成了content query和position query。为了更大限度利用denoising training,我们把content query输入为label embedding,对label也添加噪声进行reconstruct。因为denoising只是一种training方式,不会改变模型结构,只是在输入的时候做了一些改变,如下图所示,我们把decoder embedding表示为加了noise的label, anchor表示为加了noise的bbox。对于DETR原始的匹配部分,我们可以添加一个 [Unknown] label来进行区分,anchor部分保持DETR的方式不变。
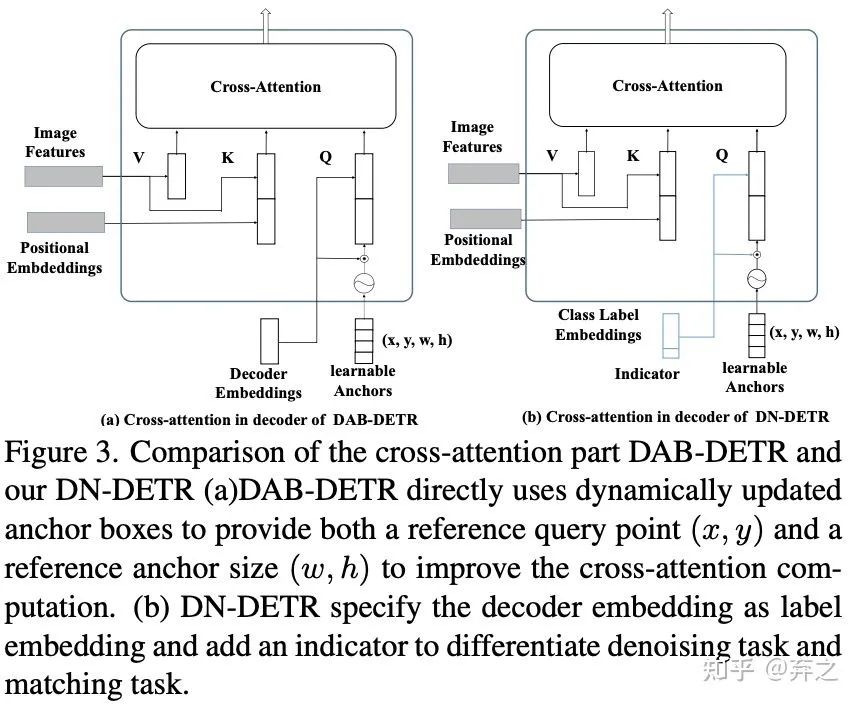
加了Denoising之后模型的输入变为下图。原始DETR的匹配部分我们命名为Matching part,新加的denosing 部分命名为denoising part。需要注意的是,denoising part只需要在训练的时候加上,在inference的时候denoising part会直接移除,和原始模型一样,因此inference的时候不会增加计算量,训练的时候也只需要加入微小的计算量(decoder 部分的denosiing part),我们在后文的实验结果会具体分析。
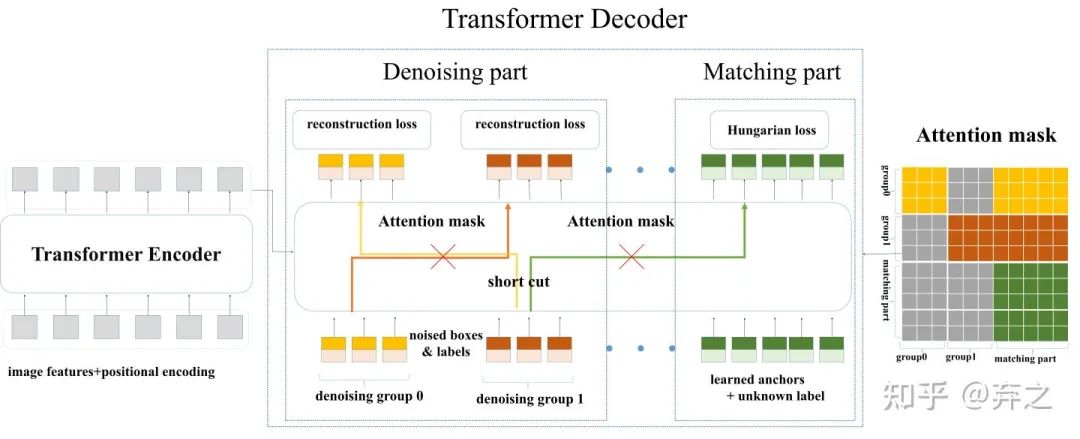
Denosing
label noise:我们以一定概率随机把真实label翻转为其余的任何一个label。如COCO中有80个类别,我们以一定概率将其翻转为80个中的其他label。加入label的方法类似NLP中的word embedding,把80个类别进行embedding即可。
box noise:box的noise可以分为两类,即中心点漂移(center shifting)和框缩放(box scaling)。对于中心点漂移,我们可以保证中心点仍然在真实框内部并进行漂移。对于框缩放,可以随机缩放框的长和宽。漂移的强度和缩放的大小控制都由超参数进行控制。
Attention mask: 除了加noise之外,在decoder的self attention我们需要加一个额外的attention mask防止信息泄露。因为denoising部分包含真实框和真实标签的信息,直接让matching part看到denoising part会导致信息泄漏。因此,训练的时候matching part不能看到denoising part,像原始模型一样训练。额外增加的denoising part看或者不看到matching part对结果影响不大,因为denosing部分含有最多的真实框和标签。
模型结果
我们基于DAB做了DN-DETR,基于Deformable DETR和DAB做了DN-Deformable-DETR来进行实验,并在COCO上进行了实验。
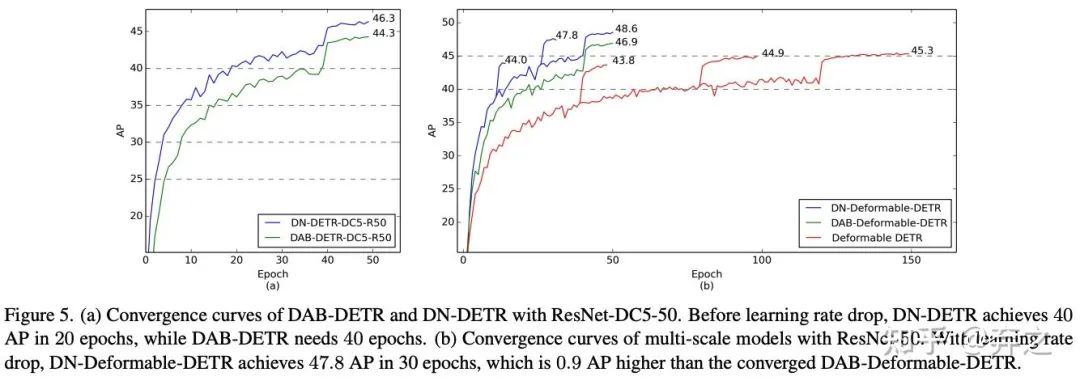
50epoch setting:为了最大程度验证denoising training的提升,我们首先在标准的50epoch训练下做了完全相同setting下相比DAB-DETR在各个不同backbone上的提升。结果如下图
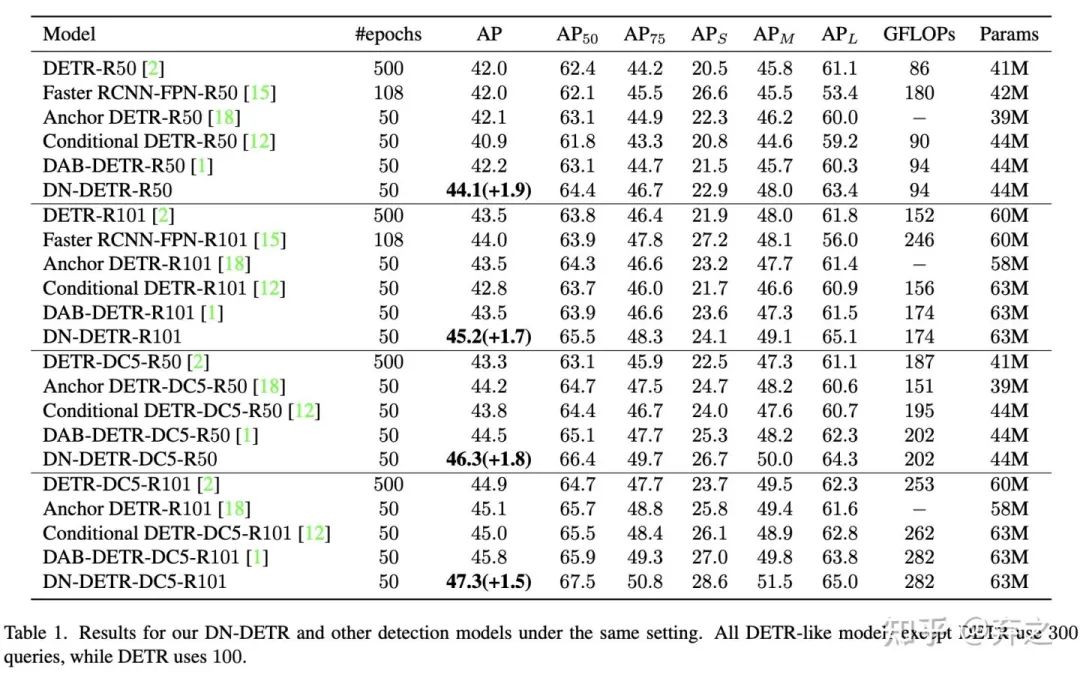
可以看到在收敛后denoising也能带来1.5-1.9的提升。
12epoch setting:为了验证denoising能够帮助模型在前期快速收敛,我们做了一个传统CNN detector经常做的实验12 epoch(在Detectron2中被称为3x)
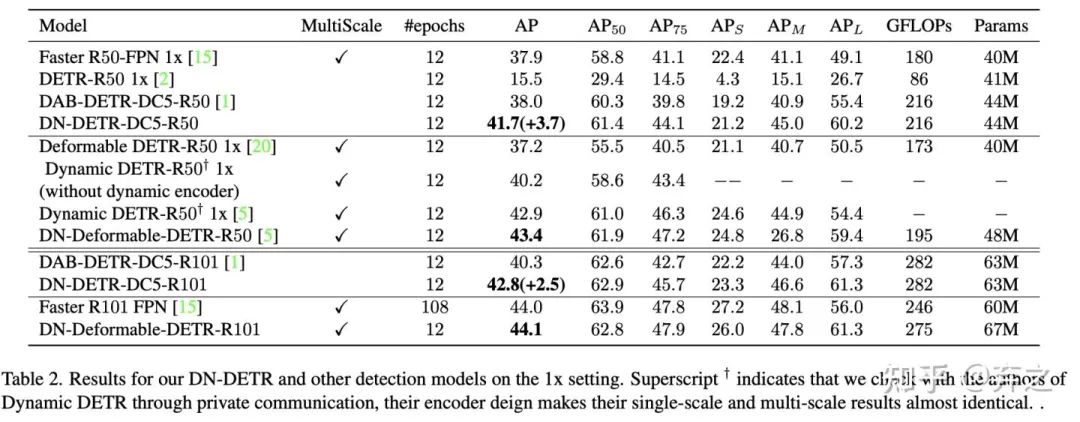
可以看到denoising在前期可以加速收敛带来巨大提升。
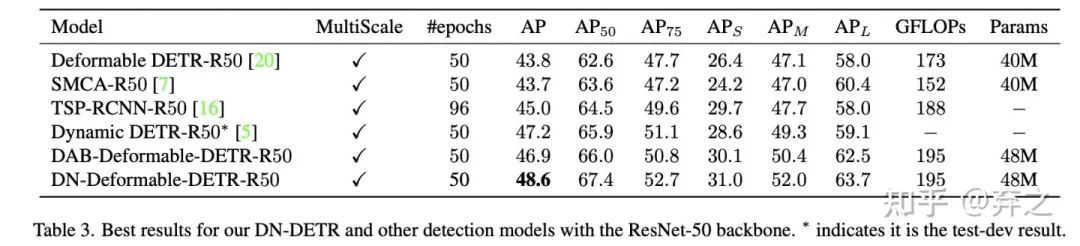
和SOAT模型相比:我们最后和SOTA模型进行了比较,提升依然显著。
Ablation分析
denoising的作用:如下图,我们可以看到box denoising提升最为显著。

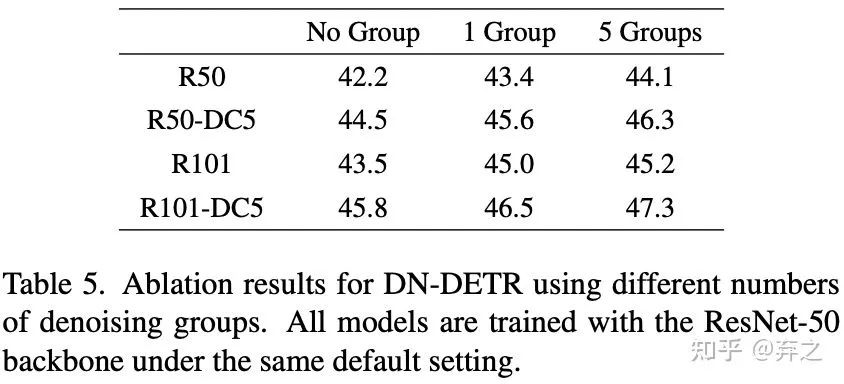
增加denoisng的数量:增加denoising的数量可以持续带来提升,同时带来提升也会随着denoising数量增多边际递减
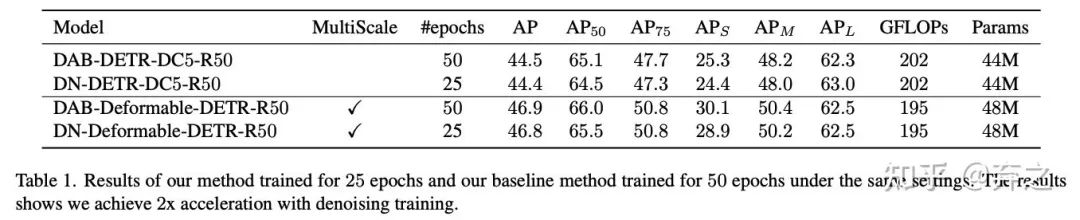
收敛加速分析:一半的训练epoch就能达到相同的效果
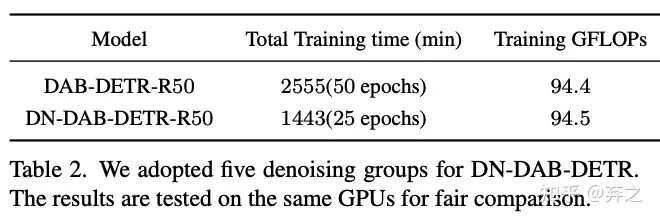
实际训练代价:可以看到实际收敛速度也接近两倍,并且训练时增加的GFLOPS很小。
额外的任务
在论文附录里面有彩蛋哦~我们的这种设计还可以进行其他任务,如知道一部分object预测另一部分,只知道label预测 box等,未来还可以考虑做few-shot、progressive prediction等,希望有兴趣的同学可以尽情探索它的潜能!
如何用denoising加速非DAB-DETR类型的模型?
对于DETR类型的模型,decoder中都有类似“box information”的信息在流动,虽然不同模型可能formulate成了不同的形式。DAB-DETR显示的表示为四维box坐标,因此很适合做denosing。
DN可以支持其他类似DETR的模型,例如带有2D anchor的Anchor DETR和不带anchor的Vanilla DETR。对于DN-Anchor-DETR,可以很容易地修改为4D anchor以获得更好的结果,我们也可以遵循Anchor DETR仅向2D anchor添加噪声。对于 DN-Vanilla-DETR,我们可以简单地使用linear embedding将噪声框嵌入到与DETR query相同的维度中。由于 Vanilla DETR 没有明确的content part和position part,两部分信息是混在一起的,因此我们可以将label embedding和box embedding加在一起一起作为 DETR query。我们的初步结果表明,这些模型的收敛速度也有提高。
参考
^https://arxiv.org/abs/2005.12872
^https://arxiv.org/abs/2201.12329
^https://arxiv.org/abs/2108.06152
上面论文PDF和代码下载
后台回复:DN,即可下载上述论文PDF
后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集
后台回复:ICCV2021,即可下载ICCV 2021论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
- CVer-目标检测交流群成立
- 扫码添加CVer助手,可申请加入CVer-目标检测微信交流群,方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
- 一定要备注:研究方向+地点+学校/公司+昵称(如目标检测+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
-
- ▲长按加小助手微信,进交流群
- CVer学术交流群(知识星球)来了!想要了解最新最快最好的CV/DL/ML论文速递、优质开源项目、学习教程和实战训练等资料,欢迎扫描下方二维码,加入CVer学术交流群,已汇集数千人!
-
- ▲扫码进群
- ▲点击上方卡片,关注CVer公众号
-
- 整理不易,请点赞和在看

