
热门标签
热门文章
- 1【自然语言处理三-self attention自注意是什么】
- 22021-CVPR-图像修复论文导读《TransFill: Reference-guided Image Inpainting by Merging Multiple Color and ~~~》
- 3数智化转型中的零售餐饮行业_餐饮的数据化转型分析
- 4Langfuse标注数据集
- 5【雕爷学编程】MicroPython手册之 ESP32-CAM 人脸跟踪机器人_用python获取esp-32 cam的blinker视频流
- 6【基础】1031- 前端也要懂编译:AST 从入门到上手指南
- 7有用的win11小技巧
- 8WEB电子藏书总览_css世界pdf 百度网盘
- 9第一节 docker介绍_docker的镜像可以实现 一次构建,到处运行 ,使用非常方便,我们以官方提供的基础cen
- 10Spring Boot框架介绍_springboot框架介绍
当前位置: article > 正文
扩散模型U-Net可视化理解_基于u-net结构的扩散模型
作者:AllinToyou | 2024-03-30 11:16:14
赞
踩
基于u-net结构的扩散模型
简介
U-Net是生成式扩散模型的核心。它的输入有三个:(1)带噪声的图片 (2)时间标签 (3)其他条件变量。经过层层运算,得到一个噪声输出。该噪声输出可用于给图片去噪。
这里推荐一个diffusion实现手写数字的源代码https://github.com/TeaPearce/Conditional_Diffusion_MNIST,适合新手入门。本文主要讲解其中U-Net的工作过程。
U-net结构
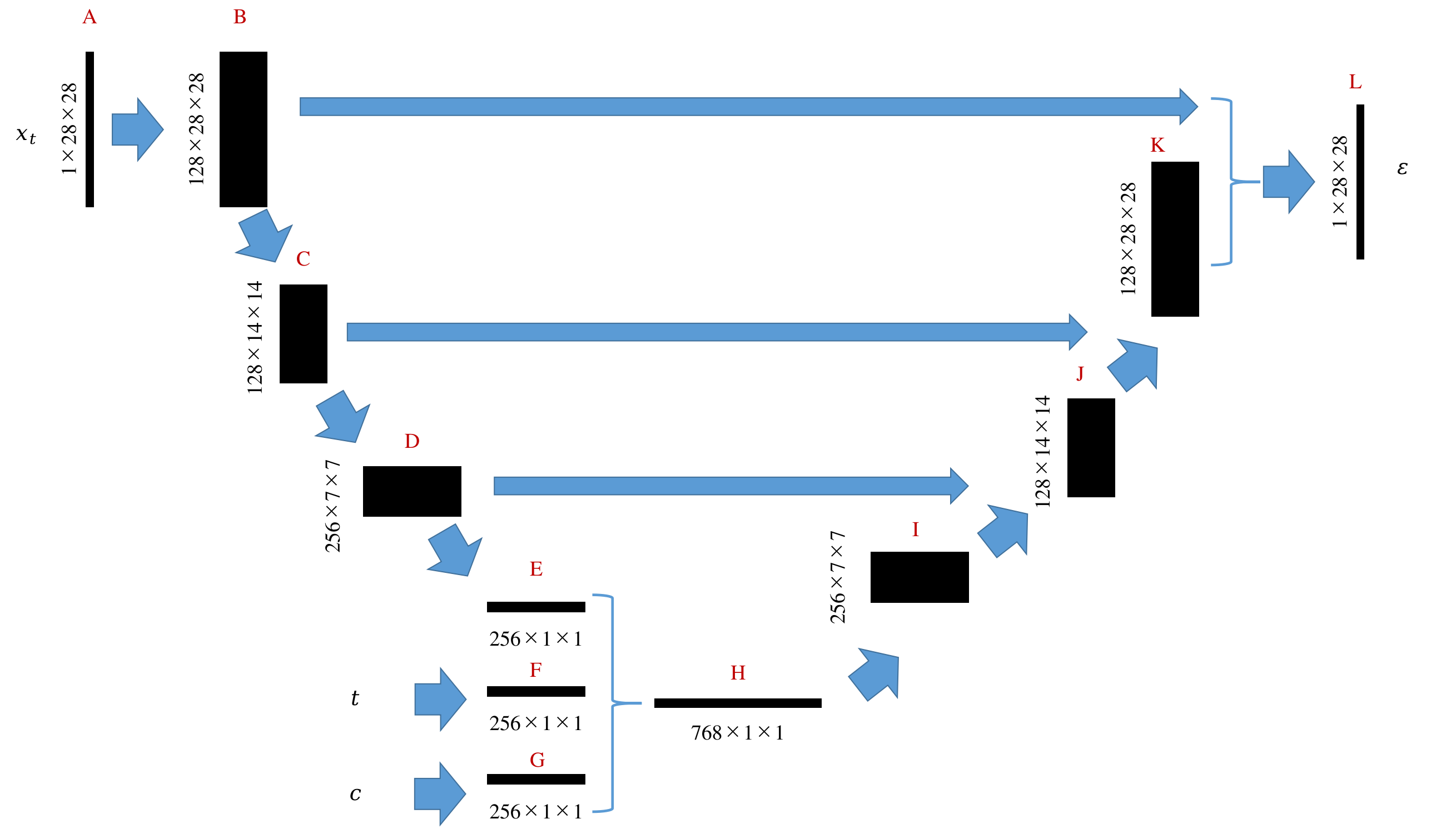
扩散模型中的U-net结构如下图所示,1X28X28表示通道数为1,长宽为28的图片。在实际训练中不是一个三阶张量而是一个四阶张量128X1X28X28,其中128表示批处理数,即128张图片同时在GPU上完成一次训练迭代。
整个计算流程如下:输入图片(A)被提取出128张特征图(B),经过第一次下采样图像缩小一半(C),经过第二次下采样图像进一步缩小为一半(D),经过平均池化得到一个向量(E),这个向量包含了图片中的所有必要特征信息。至此,输入图片已被编码。除了图片以外,时间标签、其他条件变量也可使用全链接网络进行编码,得到两个向量(F和G),为了确保后续上采样顺利,E、F、G的长度应当相同。接下来,将E、F、G合并为一个更长的向量H。H经过上采用不断恢复出I、J、K直到L。L即为最终期望输出的噪声图。用这个噪声图即可实现对图片的去噪。
可视化
接下来以一个batch size=128来说明上述过程。
A

B(第一个通道)

C(第一个通道)

D(第一个通道)

E(batch中的第一个图片的所有通道)

F

G

H

I(第一个通道)

J(第一个通道)

K(第一个通道)

L

声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/AllinToyou/article/detail/340413
推荐阅读
相关标签

