
tsne原理以及代码实现(学习笔记)
赞
踩
1. t-SNE的基本概念
t-SNE(t-distributed stochastic neighbor embedding) 是一种非线性降维算法,非常适用于高维数据降维到2维或者3维,并进行可视化。
2. t-SNE介绍
t-SNE是由SNE(Stochastic Neighbor Embedding, SNE; Hinton and Roweis, 2002)发展而来。
2.1 SNE(随机邻域嵌入)
SNE首先将数据点之间的高维欧几里德距离转换为表示相似性的条件概率,如(1)式。对于附近的数据点,pj|i相对较高,而对于广泛分离的数据点,pj|i几乎是无穷小的。
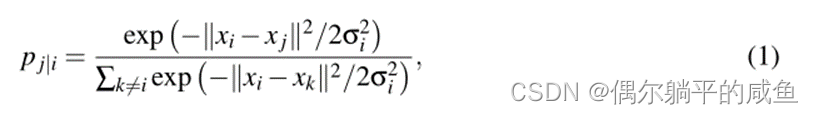
高维数据点xi和xj 的低维对应项yi和yj,可以计算类似的条件概率,我们用qj|i表示。

如果映射点yi和yj正确地建模了高维数据点xi和xj之间的相似性,则条件概率pj|i和qj|i将相等。受这一观察结果的启发,SNE的目标是找到一种低维数据表示法,以最小化pj|i和qj|i之间的不匹配。qj|i建模pj|i的信度的自然度量是KullbackLeibler散度。SNE使用梯度下降法最小化所有数据点上的Kullback-Leibler发散之和。成本函数C由下式给出:
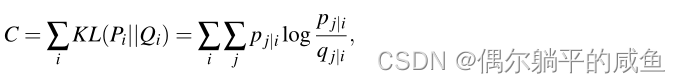
其中Pi表示给定数据点xi的所有其他数据点上的条件概率分布,Qi表示给定图点yi的所有其他地图点上的条件概率分布。由于Kullback-Leibler散度是非对称的,因此低维映射中成对距离中的不同类型的误差加权不相等。特别是,使用广泛分离的地图点来表示附近的数据点(即使用一个小的qj|i来模拟一个大的pj|i),但是使用附近的地图点来表示广泛分离的数据点的成本很小。这个小成本来自于在相关Q分布中浪费一些概率质量。换句话说,SNE成本函数侧重于在地图中保留数据的局部结构。
SNE的缺点:
尽管SNE构建了相当好的可视化效果,但它受到
①难以优化的成本函数
②拥挤问题
拥挤问题就是说各个簇聚集在一起,无法区分。比如有一种情况,高维度数据在降维到10维下,可以有很好的表达,但是降维到两维后无法得到可信映射,比如降维如10维中有11个点之间两两等距离的,在二维下就无法得到可信的映射结果(最多3个点)。
2.2 t-SNE
t-SNE旨在缓解SNE的缺点。t-SNE使用的成本函数在两个方面不同于SNE使用的成本函数:
(1)它使用了具有更简单梯度的SNE成本函数C的对称版本

(2)它使用Student-t分布而不是高斯分布来计算低维空间中两点之间的相似性。
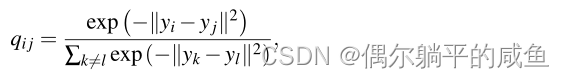
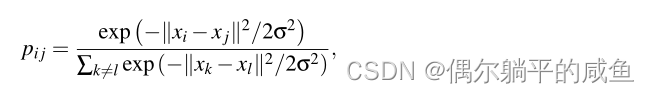
2.3 t-SNE的优缺点
2.3.1 t-SNE优点
对于不相似的点,用一个较小的距离会产生较大的梯度来让这些点排斥开来。
这种排斥又不会无限大(梯度中分母),避免不相似的点距离太远。
t-SNE在低维空间采用重尾分布,以缓解SNE的拥挤问题和优化问题。
2.3.2 t-SNE的缺点
尽管我们已经证明,t-SNE与其他数据可视化技术相比具有优势,但tSNE有三个潜在的弱点:
(1)t-SNE在一般降维任务中的表现尚不清楚,
目前尚不清楚t-SNE将如何执行更一般的降维任务(即当数据的维度不是降到两个或三个维度,而是降到d>3个维度时)。为了简化评估问题,本文只考虑使用t-SNE进行数据可视化。
(2)t-SNE的相对局部性使其对数据的固有维数的诅咒非常敏感,
而且t-SNE倾向于保存局部特征,对于本征维数(intrinsic dimensionality)本身就很高的数据集,是不可能完整的映射到2-3维的空间。(部分)解决该问题的一种可能方法是,对从模型中获得的数据表示进行t-SNE,如自编码器。这种深层体系结构可以以更简单的方式表示复杂的非线性函数,因此,学习合适的解决方案需要更少的数据点。例如,对自动编码器生成的数据表示执行t-SNE可能会提高构建的可视化的质量,因为自动编码器比局部方法(如t-SNE)更好地识别高度变化的线性。
(3)t-SNE不保证收敛到其代价函数的全局最优。
t-SNE的一个主要缺点是代价函数C不是凸的,因此需要选择几个优化参数。构造的解决方案取决于这些优化参数的选择,并且每次从映射点的初始随机配置运行t-SNE时可能会有所不同。
(4)t-SNE没有唯一最优解,且没有预估部分。
如果想要做预估,可以考虑降维之后,再构建一个回归方程之类的模型去做。但是要注意,t-sne中距离本身是没有意义,都是概率分布问题。
(5)训练太慢。
与许多其他可视化技术一样,t-SNE的计算和内存复杂性是数据点数量的二次方。这使得将标准版本的t-SNE应用于包含超过10000个点的数据集是不可行的。t-SNE的计算复杂度和内存复杂度都是O(n2),有很多基于树的算法在t-sne上做一些改进。
3. 代码实现
from sklearn.manifold import TSNE
from sklearn.datasets import load_iris
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
# 加载数据集
iris = load_iris()
# 共有150个例子, 数据的类型是numpy.ndarray
print(iris.data.shape)#(150,4)
# 对应的标签有0,1,2三种
print(iris.target.shape)#(150,)
# 使用TSNE进行降维处理。从4维降至2维。
tsne = TSNE(n_components=2, learning_rate=100).fit_transform(iris.data)
# 使用PCA 进行降维处理
pca = PCA().fit_transform(iris.data)
# 设置画布的大小
plt.figure(figsize=(12, 6))
plt.subplot(121)
plt.scatter(tsne[:, 0], tsne[:, 1], c=iris.target)
plt.subplot(122)
plt.scatter(pca[:, 0], pca[:, 1], c=iris.target)
plt.colorbar()
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
运行结果:
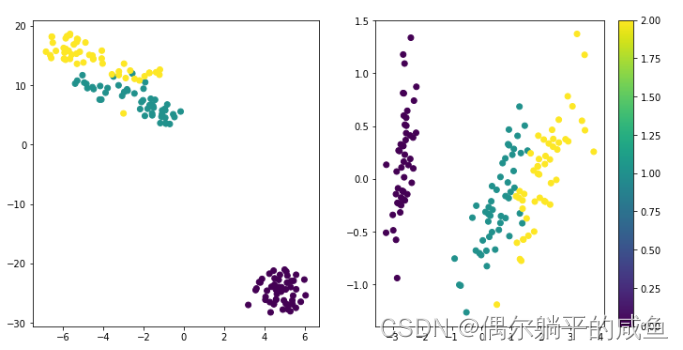
3.1 接口参数解释:
sklearn.manifold.TSNE(n_components=2, perplexity=30.0, early_exaggeration=12.0, learning_rate=200.0, n_iter=1000, n_iter_without_progress=300, min_grad_norm=1e-07, metric=’euclidean’, init=’random’, verbose=0, random_state=None, method=’barnes_hut’, angle=0.5)
参数:
n_components:int,可选(默认值:2)嵌入式空间的维度。
perplexity:float,可选(默认:30)较大的数据集通常需要更大的perplexity。考虑选择一个介于5和50之间的值。由于t-SNE对这个参数非常不敏感,所以选择并不是非常重要。
early_exaggeration:float,可选(默认值:4.0)这个参数的选择不是非常重要。
learning_rate:float,可选(默认值:1000)学习率可以是一个关键参数。它应该在100到1000之间。如果在初始优化期间成本函数增加,则早期夸大因子或学习率可能太高。如果成本函数陷入局部最小的最小值,则学习速率有时会有所帮助。
n_iter:int,可选(默认值:1000)优化的最大迭代次数。至少应该200。
n_iter_without_progress:int,可选(默认值:300,必须是50倍数)在我们中止优化之前,没有进展的最大迭代次数。
0.17新版功能:参数n_iter_without_progress控制停止条件。
min_grad_norm:float,可选(默认值:1E-7)如果梯度范数低于此阈值,则优化将被中止。
metric:字符串或可迭代的,可选,计算特征数组中实例之间的距离时使用的度量。如果度量标准是字符串,则它必须是scipy.spatial.distance.pdist为其度量标准参数所允许的选项之一,或者是成对列出的度量标准.PAIRWISE_DISTANCE_FUNCTIONS。如果度量是“预先计算的”,则X被假定为距离矩阵。或者,如果度量标准是可调用函数,则会在每对实例(行)上调用它,并记录结果值。可调用应该从X中获取两个数组作为输入,并返回一个表示它们之间距离的值。默认值是“euclidean”,它被解释为欧氏距离的平方。
init:字符串,可选(默认值:“random”)嵌入的初始化。可能的选项是“随机”和“pca”。 PCA初始化不能用于预先计算的距离,并且通常比随机初始化更全局稳定。
random_state:int或RandomState实例或None(默认)
伪随机数发生器种子控制。如果没有,请使用numpy.random单例。请注意,不同的初始化可能会导致成本函数的不同局部最小值。
method:字符串(默认:‘barnes_hut’)
默认情况下,梯度计算算法使用在O(NlogN)时间内运行的Barnes-Hut近似值。 method ='exact’将运行在O(N ^ 2)时间内较慢但精确的算法上。当最近邻的误差需要好于3%时,应该使用精确的算法。但是,确切的方法无法扩展到数百万个示例。0.17新版功能:通过Barnes-Hut近似优化方法。
angle:float(默认值:0.5)
仅当method ='barnes_hut’时才使用这是Barnes-Hut T-SNE的速度和准确性之间的折衷。 ‘angle’是从一个点测量的远端节点的角度大小(在[3]中称为theta)。如果此大小低于’角度’,则将其用作其中包含的所有点的汇总节点。该方法对0.2-0.8范围内该参数的变化不太敏感。小于0.2的角度会迅速增加计算时间和角度,因此0.8会快速增加误差。
3.2方法

这部分不用了解太多,知道几个主要的参数如n_components、n_iter、init等以及主要的方法fit_transform就好了。
#流程
tsne = TSNE(perplexity=50) #调用TSNE函数
X_embedded = tsne.fit_transform(X0) #输入数据
plt.figure(figsize=(12, 6))
plt.scatter(X_embedded[:,0], X_embedded[:,1],c=y0,cmap='Reds')# 根据y值进行可视化 选择颜色值
plt.colorbar() #显示色棒
plt.show()
tsne.embedding_ #返回二维数据点的对应的坐标
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
参考链接:https://distill.pub/2016/misread-tsne/

