
评价机器学习系统是的指标同样适用于图像或者视频描述领域。BELU、Meteor、ROUGE、CIDEr和SPICE。前两个是评测机器翻译的,第三个是评测自动摘要的,最后两个应该是为caption定制的。
1、BLEU
Bilingual Evaluation Understudy用于分析候选译文(待评价的译文)和参考译文中N元组共同出现的程度,IBM于2002年提出的。
对于一个待翻译的句子,候选译文用Ci表示,而对应的一组参考译文表示为Si={Si1,Si2,Si3,...,Sim}€S
N-gram表示N个单词长度的词组集合,另Wk表示第k组可能的n-grams
hk(Ci)表示Wk在候选译文Ci中出现的次数,hk(Sij)表示Wk在参考译文Sij中出现的次数
BLEU则根据计算对应语句中的语料库层面上的重合精度
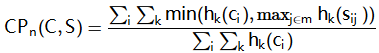
其中k表示可能存在的n-gram序号
容易看出CPn(C,S)是一个精确度度量,在语句较短时表现更好,并不能评价翻译的完整性,所以我们引入一个惩罚因子BP(Brevity Penalty):
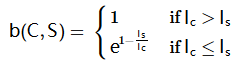
其中Ic表示候选译文Ci的长度,Is表示参考译文Sij的有效长度(当存在多个参考译文时,选取和Ic最接近的长度)
本质上,BLEU是一个n-gram精确度的加权几何平均,按照下式计算:

其中,N可取1,2,3,4,而Wh一般对所有n取常值,即1/n
BLEU在语料库层级上具有很好匹配的语句上表现很好,但随着n的增加,在句子层级上的匹配越来越差。
BLEU的优点是它考虑的粒度是 n-gram 而不是词,考虑了更长的匹配信息;BLEU的缺点是不管什么样的 n-gram 被匹配上了,都会被同等对待。比如说动词匹配上的重要性从直觉上讲应该是大于冠词的。
例子:
待评价译文:1:It is a guide to action which ensures that the military always obeys the commands of the party
2: It is to insure the troops forever hearing the activity guidebook that party direct
参考译文1:It is a guide to action that ensures that the military will forever heed Party commands
2: It is the guidingprinciple which guarantees the military forces always being under the command of the Party
3: It is the practical guide for the army always to heed the directions of the party
当n=1时,待评价译文1的 修正过的精确度值是17/18,待评价译文2的 修正过的精确度值是8/14
当n=2时,待评价译文1的 修正过的精确度值是10/17,待评价译文2的 修正过的精确度值是1/13
2、METEOR
METEOR标准于2004年由lavir发现在评价指标中召回率的意义后提出的
他们的研究表明,召回率基础上的标准相比于那些单纯基于精度的标准(如BLEU),其结果和人工判断的结果有较高相关性
METEOR测度基于单精度的加权调和平均数和单字召回率,其目的是解决一些BLEU标准中固有的缺陷
METEOR也包括其他指标没有发现一些其他功能,如同义词匹配等
计算METEOR需要预先给定一组校准(alignment)m,
其中α、γ和θ均为用于评价的默认参数
式中的
类似于BLEU的做法:
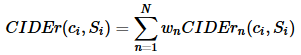
这个指标的motivation之一是刚才提到的BLEU的一个缺点,就是对所有匹配上的词都同等对待,而实际上有些词应该更加重要。

