
- 1pytorch_pretrained_bert库报错: Model name ‘pretrained\chinese_L-12_H-768_A-12‘ was not found in model
- 2关于监控摄像头小程序直播使用流程及主要应用_雄迈摄像头如何在微信小程序使用
- 3面试题:Java虚拟机JVM的组成
- 4python+离散小波变换+不同系数的波形_librosa 小波
- 5XSS一-WEB攻防-XSS跨站&反射型&存储型&DOM型&标签闭合&输入输出&JS代码解析
- 6CentOS 安装Cursor --- Draft
- 7机器学习领域中各学派划分——符号主义、频率主义、贝叶斯主义、连接主义核心思想和理论_符号主义与连接主义的优势与缺陷分别是什么
- 8curl 通过代理服务器访问外网的接口_curl通过代理访问接口
- 9Nvidia Jetson AGX Xavier 安装 Swin-Transformer-Object-Detection_mmcv-full jetson
- 10SSE通信方式 使用流信息向浏览器推送信息_浏览器如何查看到sse返回的信息内容
消息队列原理和选型:RabbitMQ、Kafka、RocketMQ和ActiveMQ_rabbitmq 和 rocketmq 选型
赞
踩

RabbitMQ、Kafka、RocketMQ和ActiveMQ,肝了我一个月,原理是什么,如何选型,本文会告诉你答案。
往期精选:
消息队列中间件重要吗?面试必问问题之一,你说重不重要。我有时会问同事,为啥你用RabbitMQ,不用Kafka,或者RocketMQ呢,他给我的回答“因为公司用的就是这个,大家都这么用”,如果你去面试,直接就被Pass,今天这篇文章,告诉你如何回答。
这篇文章纯理论,主要整理网络资料,肝了我整整一个月!文章依然延续上几篇的风格,很长,长到我只整理排版,手都整麻了。全文2.5万字,建议先收藏,后续面试、或者技术选型,再拿出来喵喵,不BB,上思维导图!

什么?你不想看“八股文”,只想实操,直接看《入门RabbitMQ,这一篇绝对够!》,给你开个快速通道。
消息队列
消息队列模式
消息队列目前主要2种模式,分别为“点对点模式”和“发布/订阅模式”。
点对点模式
一个具体的消息只能由一个消费者消费。多个生产者可以向同一个消息队列发送消息;但是,一个消息在被一个消息者处理的时候,这个消息在队列上会被锁住或者被移除并且其他消费者无法处理该消息。需要额外注意的是,如果消费者处理一个消息失败了,消息系统一般会把这个消息放回队列,这样其他消费者可以继续处理。

发布/订阅模式
单个消息可以被多个订阅者并发的获取和处理。一般来说,订阅有两种类型:
-
临时(ephemeral)订阅,这种订阅只有在消费者启动并且运行的时候才存在。一旦消费者退出,相应的订阅以及尚未处理的消息就会丢失。
-
持久(durable)订阅,这种订阅会一直存在,除非主动去删除。消费者退出后,消息系统会继续维护该订阅,并且后续消息可以被继续处理。

衡量标准
对消息队列进行技术选型时,需要通过以下指标衡量你所选择的消息队列,是否可以满足你的需求:
-
消息顺序:发送到队列的消息,消费时是否可以保证消费的顺序,比如A先下单,B后下单,应该是A先去扣库存,B再去扣,顺序不能反。
-
消息路由:根据路由规则,只订阅匹配路由规则的消息,比如有A/B两者规则的消息,消费者可以只订阅A消息,B消息不会消费。
-
消息可靠性:是否会存在丢消息的情况,比如有A/B两个消息,最后只有B消息能消费,A消息丢失。
-
消息时序:主要包括“消息存活时间”和“延迟/预定的消息”,“消息存活时间”表示生产者可以对消息设置TTL,如果超过该TTL,消息会自动消失;“延迟/预定的消息”指的是可以延迟或者预订消费消息,比如延时5分钟,那么消息会5分钟后才能让消费者消费,时间未到的话,是不能消费的。
-
消息留存:消息消费成功后,是否还会继续保留在消息队列。
-
容错性:当一条消息消费失败后,是否有一些机制,保证这条消息是一种能成功,比如异步第三方退款消息,需要保证这条消息消费掉,才能确定给用户退款成功,所以必须保证这条消息消费成功的准确性。
-
伸缩:当消息队列性能有问题,比如消费太慢,是否可以快速支持库容;当消费队列过多,浪费系统资源,是否可以支持缩容。
-
吞吐量:支持的最高并发数。
消息队列比较
下图是从网上摘抄过来的,可以看到主流MQ的对比:
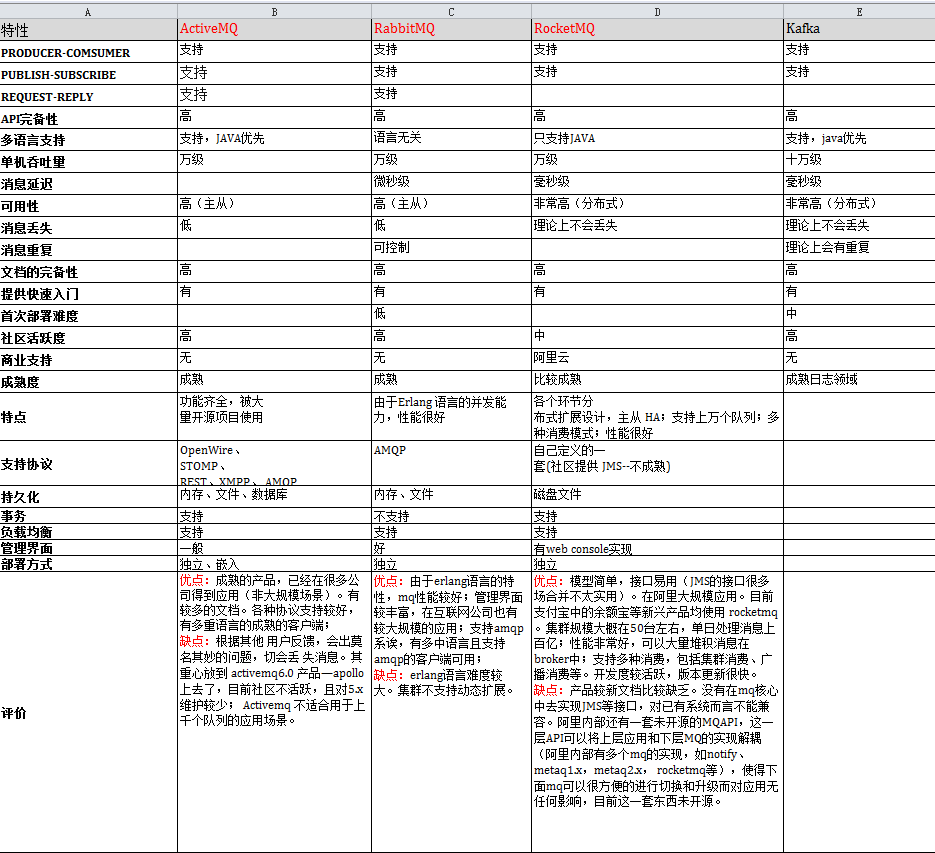
下面简单介绍常用的消息队列:
-
Kafka:Apache Kafka它最初由LinkedIn公司基于独特的设计实现为一个分布式的提交日志系统( a distributed commit log),之后成为Apache项目的一部分。号称大数据的杀手锏,谈到大数据领域内的消息传输,则绕不开Kafka,这款为大数据而生的消息中间件,以其百万级TPS的吞吐量名声大噪,迅速成为大数据领域的宠儿,在数据采集、传输、存储的过程中发挥着举足轻重的作用。
-
RabbitMQ:RabbitMQ 2007年发布,是使用Erlang语言开发的开源消息队列系统,基于AMQP协议来实现。AMQP的主要特征是面向消息、队列、路由(包括点对点和发布/订阅)、可靠性、安全。AMQP协议更多用在企业系统内,对数据一致性、稳定性和可靠性要求很高的场景,对性能和吞吐量的要求还在其次。
-
RocketMQ:是阿里开源的消息中间件,它是纯Java开发,具有高吞吐量、高可用性、适合大规模分布式系统应用的特点。RocketMQ思路起源于Kafka,但并不是Kafka的一个Copy,它对消息的可靠传输及事务性做了优化,目前在阿里集团被广泛应用于交易、充值、流计算、消息推送、日志流式处理、binglog分发等场景。
-
ActiveMQ:是Apache出品,最流行的,能力强劲的开源消息总线。官方社区现在对ActiveMQ 5.x维护越来越少,较少在大规模吞吐的场景中使用,所以该消息队列也不是我们文章中重点讨论的内容。
优缺点
Kafka
优点:
-
高吞吐、低延迟:kakfa 最大的特点就是收发消息非常快,kafka 每秒可以处理几十万条消息,它的最低延迟只有几毫秒;
-
高伸缩性: 每个主题(topic) 包含多个分区(partition),主题中的分区可以分布在不同的主机(broker)中;
-
持久性、可靠性: Kafka 能够允许数据的持久化存储,消息被持久化到磁盘,并支持数据备份防止数据丢失,Kafka 底层的数据存储是基于 Zookeeper 存储的,Zookeeper 我们知道它的数据能够持久存储;
-
容错性: 非常高,kafka是分布式的,一个数据多个副本,某个节点宕机,Kafka 集群能够正常工作;
-
消息有序:消费者采用Pull方式获取消息,消息有序,通过控制能够保证所有消息被消费且仅被消费一次;
-
有优秀的第三方Kafka Web管理界面Kafka-Manager,在日志领域比较成熟,被多家公司和多个开源项目使用;
-
功能支持:功能较为简单,主要支持简单的MQ功能,在大数据领域的实时计算以及日志采集被大规模使用。
缺点:
-
Kafka单机超过64个队列/分区,Load会发生明显的飙高现象,队列越多,load越高,发送消息响应时间变长;
-
使用短轮询方式,实时性取决于轮询间隔时间;
-
消费失败不支持重试;
-
支持消息顺序,但是一台代理宕机后,就会产生消息乱序;
-
社区更新较慢。
总结:
-
Kafka主要特点是基于Pull的模式来处理消息消费,追求高吞吐量,一开始的目的就是用于日志收集和传输,适合产生大量数据的互联网服务的数据收集业务。
-
大型公司建议可以选用,如果有日志采集功能,肯定是首选kafka。
RabbitMQ
优点:
-
异步消息传递:支持多种消息协议,消息队列,传送确认,灵活的路由到队列,多种交换类型;
-
支持几乎所有最受欢迎的编程语言:Java,C,C +

