
- 1第11章 Tkinter 概述_51:/##y6h6ubdyl##1:/$wbsmkqt$11:/¥ubsd5akboofpxgpk
- 2记录在项目中引用本地的npm包
- 3html 列表标签 ul ol dl_html中dl自动编号
- 4ELF文件结构描述_、简述elf 文件的内部层次结构。
- 5Spring6详解-概述,入门
- 6flutter图片预览photo_view_flutter photo_view
- 7xcode6(ios8) 编译出现 CodeSign error_codesign error with: 2
- 8华为三层交换机 VLANIF 配置_vlanif的ip地址给谁配置的
- 9超详细的 K8s 高频面试题,绝对实用篇
- 10SAP ADM100-2.3 系统启动:AS ABAP和AS ABAP+JAVA_sap netweaver java administrator console
好久不见!OneFlow 1.0全新版本上线
赞
踩

好久不见。今天是 OneFlow 开源的第 1320 天。
与 OneFlow 框架的创作者们一样,过去一年,它也经历了过山车般的命运。好在,即使在下坡潜伏期依然被社区用户关注和使用,作为它的创作者,我们为此感到欣慰——这也是它还在更迭的价值和意义所在。
终于,OneFlow 迎来了一个新的里程碑。距离上一次版本发布一年后,我们很高兴发布全新的 OneFlow v1.0.0 版本。
本次更新共 447 个 commits,包括新特性 80+ 项,功能改进与问题修复共 130+ 项。性能方面,无论是深度学习编译后使用 Graph 模式运行,还是 Eager 模式运行,在典型模型上 OneFlow 相比 PyTorch 都有明显的领先优势。
我们希望,新版本不仅仅是一个数字上的里程碑,更成为用户在模型的生产和应用中的价值高地。
欢迎体验新版本,期待你的反馈。完整更新列表及性能详情请查看:https://github.com/Oneflow-Inc/oneflow/releases/tag/v1.0.0![]() https://github.com/Oneflow-Inc/oneflow/releases/tag/v1.0.0
https://github.com/Oneflow-Inc/oneflow/releases/tag/v1.0.0
OneFlow v1.0.0 主要包括以下新增亮点特性、功能和优化:
compile_from_torch接口在共享参数显存的情况下,将 PyTorch 的 Module 实例转化成 OneFlow 的 Module 实例,支持直接 Eager 运行或者转化为静态图 nn.Graph 并进一步使用 MLIR 编译加速。
该接口仍在快速演进中,目前支持了动态形状编译并在ResNet50、Faster RCNN、Stable Diffusion三个典型模型上做了验证。
接口签名及参数介绍:
- compile_from_torch(torch_module: torch.nn.Module, \*, use_graph=True, options={})
- * torch_module:需要被转换的 Torch Module 实例。
- * use_graph:是否转化为静态图 nn.Graph 并使用 MLIR 编译加速,默认为 True。
- * options:
- * size: 使用静态图 nn.Graph 后会根据输入的 shape 计算 hash 值缓存相应的 graph ,size 表示静态图缓存的最大容量,超过最大容量会根据 LRU 策略对 graph 进行清理,默认值为 9。
- * dynamic:对于动态 shape 的输入第一次会完整编译 graph,之后的对于不同 shape 的输入当 dynamic 为 True 时会启用共享图进行编译加速,dynamic 为 False 时每次都会重新进行编译,默认为 True。
- * debug:调试模式和日志级别设置,-1 禁用调试模式,0 输出警告和静态图构建信息,1 额外输出每个子模块的构图信息,2 额外输出每个算子的进度,3 输出更详细的算子信息,默认为 -1。
使用示例:
- import torch
- from torchvision import models
- import oneflow
- from oneflow.framework.infer_compiler import compile_from_torch
- DEVICE = torch.device("cuda")
- WEIGHT = models.ResNet50_Weights.DEFAULT
- model = models.resnet50(weights=WEIGHT).to(DEVICE)
- compile_model = compile_from_torch(model, options={"dynamic": True})
对 Eager 运行时做了一系列优化与重构,包括统一系统内存池、对接 CUDA 原生接口、优化指令调度机制、引入指令融合机制、优化 Autograd 构图速度、优化 Op 推导过程、解耦 Instruction 与 Stream 等。
用户可以通过一些环境变量设定 Eager 运行时行为:
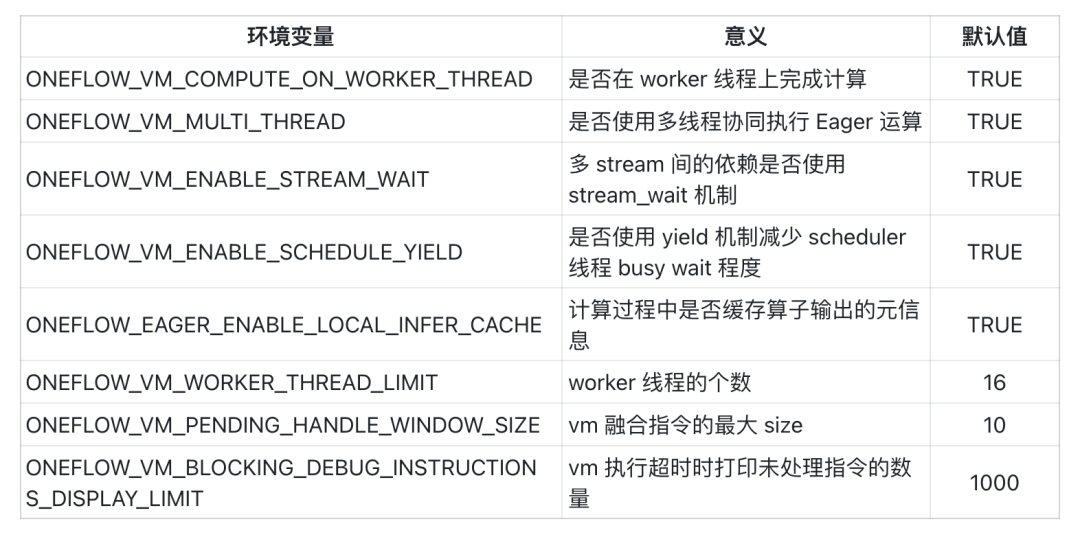
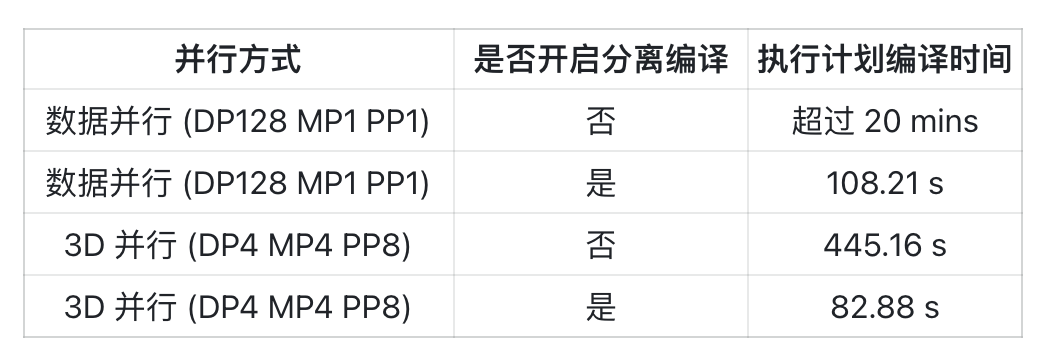
静态图分布式物理执行计划支持分离编译功能,每个进程独立编译自己所需的执行计划,使得编译时间不再随 GPU 规模线性增长。分离编译功能支持 3D 混合并行(数据并行+模型并行+流水并行)场景,可与大规模模型训练开源工具箱 LiBai 一同使用,打开方式为:export ONEFLOW_ENABLE_LAZY_SEPARATE_COMPILE=1。
以下是在 128 卡 A100-PCIE-40GB 设备上,配合 LiBai 在 GPT2 模型上的测试结果:
OneFlow compile_from_torch VS PyTorch compile
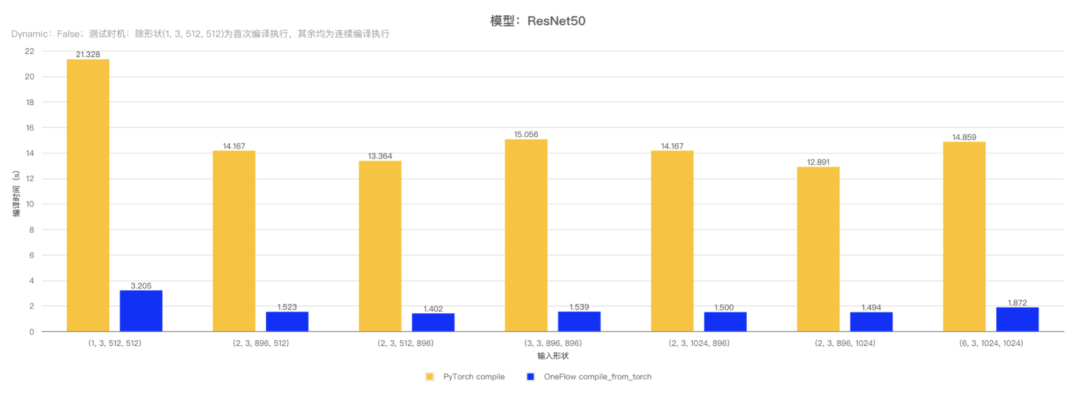
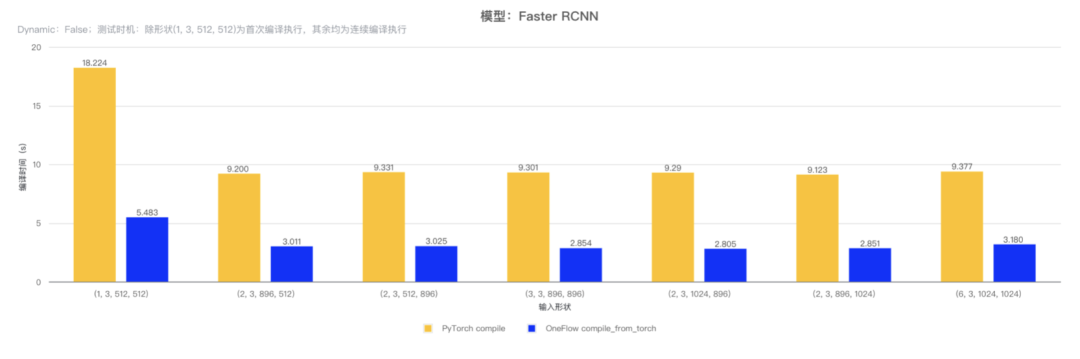
相对 PyTorch compile 接口的编译时间,使用 OneFlow compile_from_torch 接口的编译时间更短,另外得益于 OneFlow 框架中极致的算子优化,在 Stable Diffusion 模型上有更优的执行性能(github.com/siliconflow/onediff)。
具体而言,对 ResNet50 模型和 Faster RCNN 模型的 backbone 部分使用 OneFlow compile_from_torch 和 PyTorch compile 接口进行编译并执行,测试不同形状输入时的编译时间,结果如下表:
(注:测试使用 GPU 型号为 3090,PyTorch 版本为 v2.1.2,CUDA 版本为 12.2。)
对 Stable Diffusion 模型的 unet 部分使用 OneFlow compile_from_torch 和 PyTorch compile 接口进行编译并执行,测试不同形状输出时的编译时间与执行时间,结果如下表:
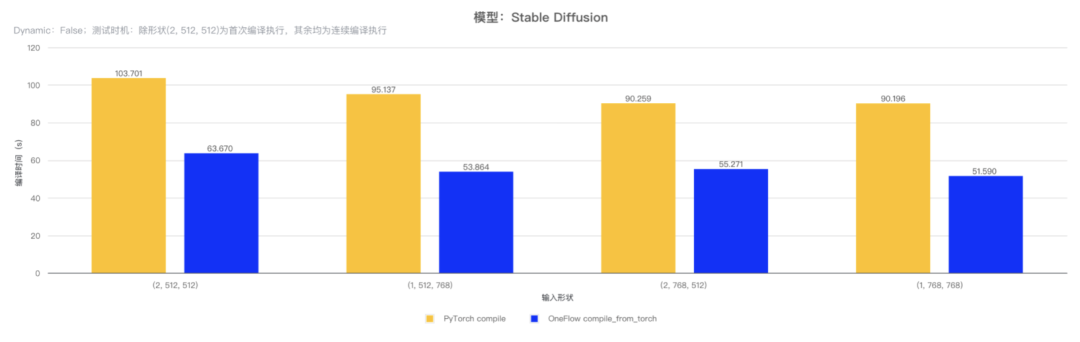
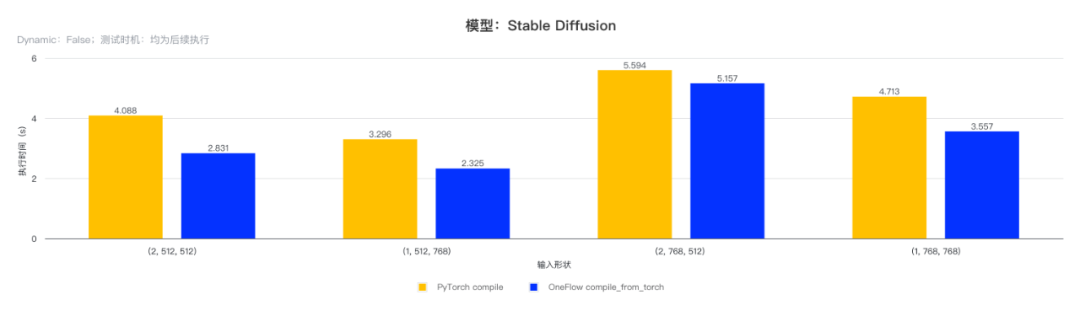
(注:测试使用 GPU 型号为 3090,PyTorch 版本为 v2.1.2,CUDA 版本为 12.2。)
OneFlow Eager vs PyTorch Eager
在 ResNet50 和 Bert 模型的小 batch 场景下,OneFlow Eager 相对于 PyTorch Eager 有明显性能优势。
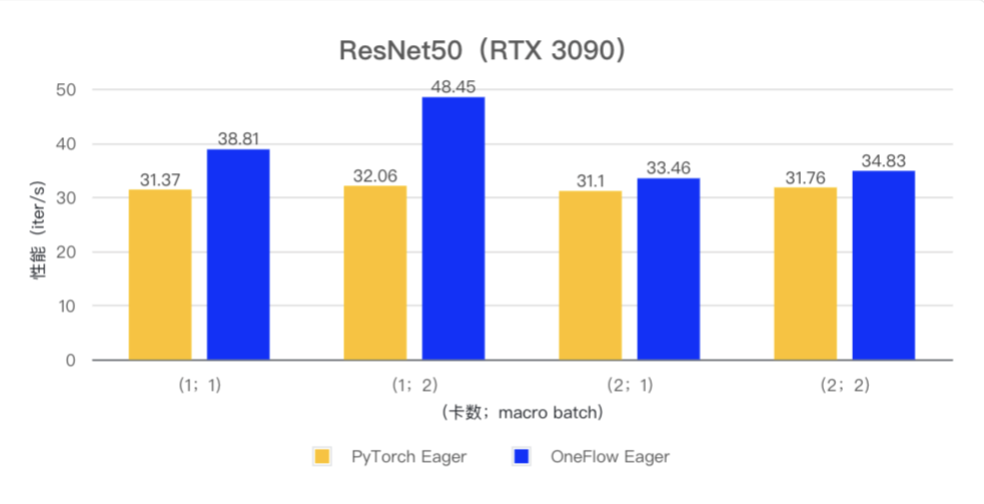
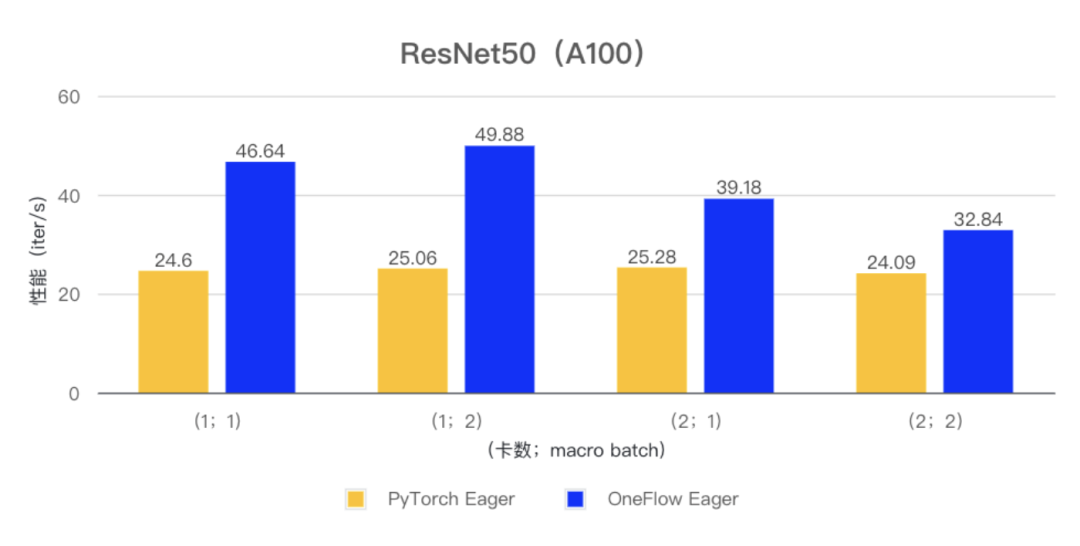
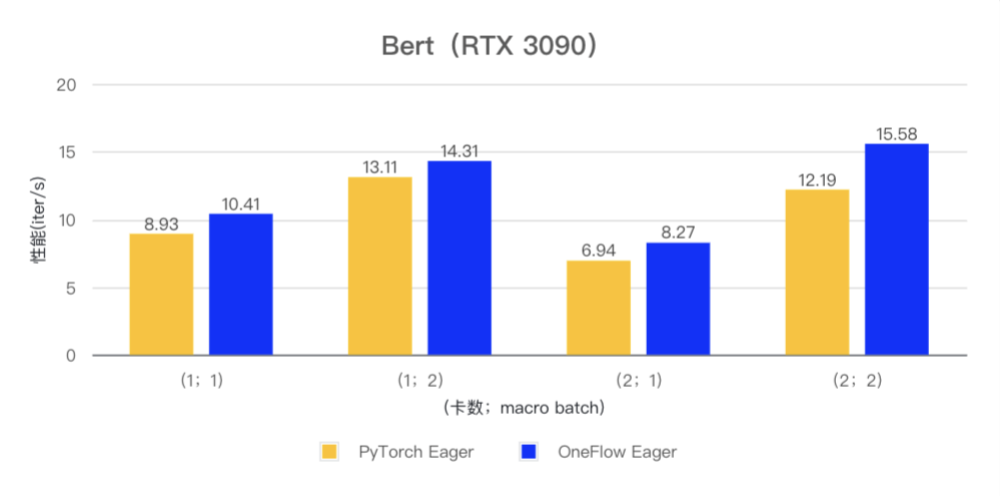
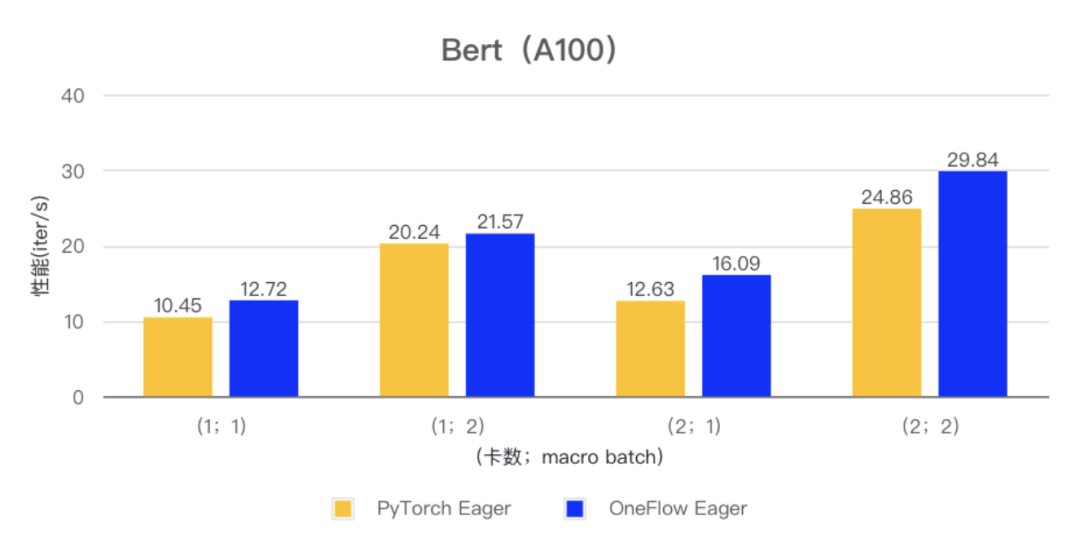
(注:测试使用 PyTorch 版本为 v2.1.0,CUDA 版本为 12.1)
新增一系列函数式自动微分相关接口支持,包括 jvp、vjp、hvp、vhp、jacobian、hessian。(github.com/Oneflow-Inc/oneflow/pull/10412;github.com/Oneflow-Inc/oneflow/pull/10428)
使用示例:
- import oneflow as flow# jacobian exampledef exp_reducer(x):
- return x.exp().sum(dim=1)
-
-
- input = flow.rand(2, 2)
- jac_rslt = flow.autograd.functional.jacobian(exp_reducer, input)
-
-
- # vhp exampledef pow_reducer(x):
- return x.pow(3).sum()
-
-
- input = flow.rand(2, 2)
- v = flow.ones(2, 2)
- vhp_rslt = flow.autograd.functional.vhp(pow_reducer, input, v)
Insight 模块支持可视化地展示埋点区间内 kernel 调用、执行时间、速度等信息。(github.com/Oneflow-Inc/oneflow/pull/10370)
使用方法如下:
-
步骤一:使用 OneFlow Profiler 模块在代码中设置埋点区间。
-
步骤二:运行代码并使用 NVIDIA Nsight Systems 生成 sqlite 后缀文件。
-
步骤三:使用 OneFlow Insight 模块生成 json 文件。
-
步骤四:在网址 chrome://tracing/ 或 edge://tracing/ 中打开 json 文件得到可视化界面。
更详细的介绍可参考:https://github.com/Oneflow-Inc/oneflow/tree/master/python/oneflow/utils/insight#usage
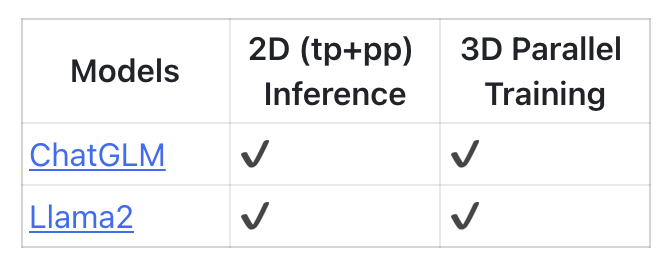
大规模模型训练开源工具箱 LiBai v0.3.0 新版本发布 ,原生支持大语言模型 Llama2 和 ChatGLM2 的 finetune 和分布式推理,支持 full finetune、adapter finetune、lora finetune,可使用 lm-eval-harness 对语言模型进行评测验证。
ChatGLM 和 Llama2 的分布式训练和推理支持情况如下:
使用示例:
- # full finetune
- bash tools/train.sh projects/Llama/train_net.py projects/Llama/configs/llama_sft.py 8
-
-
- # adapter finetune
- bash tools/train.sh projects/Llama/adapter/train_net.py projects/Llama/adapter/adapter_sft.py 8
-
-
- # inference
- bash tools/infer.sh projects/Llama/pipeline.py 8
-
-
- # eval
- python projects/Llama/utils/eval_adapter.py
OneFlow Serving 功能升级,在原有支持 OneFlow Cpp 后端的基础上,新增支持 OneFlow Python 后端和 OneFlow Lite 后端。
-
使用 OneFlow Cpp 后端可以在脱离 Python 的环境中部署以达到最高的性能。
-
使用 OneFLow Lite 后端可以实现在端侧设备上的部署。
-
使用 OneFlow Python 后端可以以极小的迁移代价完成复杂模型的部署。
使用方法参考:
https://github.com/Oneflow-Inc/serving/blob/main/README.md
感谢以下贡献者:
@10170309,@BBuf,@Flowingsun007,@L-Xiafeng,@MARD1NO,@MarioLulab,@ShawnXuan,@Yipeng1994,@akeeei,@ccssu,@chengtbf,@clackhan,@crazy-JiangDongHua,@daquexian,@doombeaker,@fpzh2011,@hanwen-sun,@haoyang9804,@hjchen2,@hu-1996,@jackalcooper,@leaves-zwx,@levi131,@lihuizhao,@linzs148,@liujuncheng,@lixiang007666,@loxs123,@lucky9-cyou,@marigoold,@mosout,@ofhwei,@ouyangyu,@pingzhuu,@shangguanshiyuan,@strint,@wyg1997,@xiezipeng-ML
==招贤纳士==
AGI时代,有能力、激情和抱负的工程师不会停留在风平浪静的海滩,而是会选择去新的潮头迎风搏击,驶向新的未知。
如果你是这样的工程师,欢迎加入我们这艘航船。简历投递地址:talent@oneflow.org


