
- 1AI聊天伴侣的语料采集大揭秘:OpenCV如何轻松识别聊天图片?_图像识别聊天框
- 2开源项目——ROSECHO 中文ROS语音交互模块(一)_ros语音控制命令前往指定地点
- 3体感游戏开发:体感游戏常用技术
- 4Edge-TTS 语音朗读
- 5国考【行测】类比推理真题分析——2023.12.27更新_显示屏计算机手机类比
- 6【华为机试】2024年真题C卷(c++)-机器人搬砖_华为od 机器人搬砖,一共有n堆砖存放在n个不同的仓库中,第i堆砖中有bricks[i]块砖
- 7【EduCoder答案】git相关实训答案_#请在下面的begin/end内填写语句以将远程版本库clone到本地 #********** be
- 8【前沿技术杂谈:NLP技术的发展与应用】探索自然语言处理的未来
- 9正样本和无标签学习(PU Learning):使用机器学习恢复数据的标签
- 10VRRP实验(eNSP)_ensp vrrp
利用python实现Apriori关联规则算法_apriori算法python代码
赞
踩
关联规则
大家可能听说过用于宣传数据挖掘的一个案例:啤酒和尿布;据说是沃尔玛超市在分析顾客的购买记录时,发现许多客户购买啤酒的同时也会购买婴儿尿布,于是超市调整了啤酒和尿布的货架摆放,让这两个品类摆放在一起;结果这两个品类的销量都有明显的增长;分析原因是很多刚生小孩的男士在购买的啤酒时,会顺手带一些婴幼儿用品。
不论这个案例是否是真实的,案例中分析顾客购买记录的方式就是关联规则分析法Association Rules。
关联规则分析也被称为购物篮分析,用于分析数据集各项之间的关联关系。
关联规则基本概念
项集:item的集合,如集合{牛奶、麦片、糖}是一个3项集,可以认为是购买记录里物品的集合。
频繁项集:顾名思义就是频繁出现的item项的集合。如何定义频繁呢?用比例来判定,关联规则中采用支持度和置信度两个概念来计算比例值
支持度:共同出现的项在整体项中的比例。以购买记录为例子,购买记录100条,如果商品A和B同时出现50条购买记录(即同时购买A和B的记录有50),那边A和B这个2项集的支持度为50%
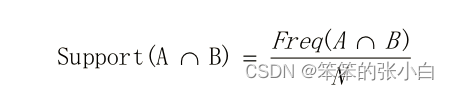
置信度:购买A后再购买B的条件概率,根据贝叶斯公式,可如下表示:
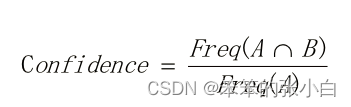
提升度:为了判断产生规则的实际价值,即使用规则后商品出现的次数是否高于商品单独出现的评率,提升度和衡量购买X对购买Y的概率的提升作用。如下公式可见,如果X和Y相互独立那么提升度为1,提升度越大,说明X->Y的关联性越强
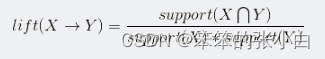
关联规则Apriori算法
1. Apriori算法的基本思想
对数据集进行多次扫描,第一次扫描得到频繁1-项集的集合L1,第k次扫描首先利用第k-1次扫描的结果Lk-1产生候选k-项集Ck,在扫描过程中计算Ck的支持度,在扫描结束后计算频繁k-项集Lk,算法当候选k-项集的集合Ck为空的时候结束。
2. Apriori算法产生频繁项集的过程
(1)连接步
(2)剪枝步
3.Apriori算法的主要步骤
(1) 扫描全部数据,产生候选1-项集的集合C1
(2) 根据最小支持度,由候选1-项集的集合C1产生频繁1-项集的集合L1
(3) 对k>1,重复步骤(4)(5)(6)
(4) 由Lk执行连接和剪枝操作,产生候选(k+1)-项集Ck+1
(5) 根据最小支持度,由候选(k+1)-项集的集合Ck+1产生频繁(k+1)-项集的集合Lk+1
(6) 若L不为空集,则k = k+1,跳往步骤(4),否则跳往步骤(7)
(7) 根据最小置信度,由频繁项集产生强关联规则
Apriori算法是经典的关联规则算法。Apriori算法的目标是找到最大的K项频繁集。Apriori算法从寻找1项集开始,通过最小支持度阈值进行剪枝,依次寻找2项集,3项集直到没有更过项集为止。
代码实现
本次算法实现我们借助了mlxtend第三方包,pip install mlxtend安装一下即可
编译工具:jupyter notebook
首先导入本次项目用到的第三方包:
- import pandas as pd
- from mlxtend.frequent_patterns import apriori
- from mlxtend.frequent_patterns import association_rules
- import warnings
- warnings.filterwarnings('ignore')
接下来我将使用两个小案例给大家示范如何使用关联规则算法
案例一
准备数据
- order = {'001': '面包,黄油,尿布,啤酒',
- '002': '咖啡,糖,小甜饼,鲑鱼,啤酒',
- '003': '面包,黄油,咖啡,尿布,啤酒,鸡蛋',
- '004': '面包,黄油,鲑鱼,鸡',
- '005': '鸡蛋,面包,黄油',
- '006': '鲑鱼,尿布,啤酒',
- '007': '面包,茶,糖鸡蛋',
- '008': '咖啡,糖,鸡,鸡蛋',
- '009': '面包,尿布,啤酒,盐',
- '010': '茶,鸡蛋,小甜饼,尿布,啤酒'}
- data_set = []
- id_set= []
- shopping_basket = {}
- for key in order:
- item = order[key].split(',')
- id_set.append(key)
- data_set.append(item)
- shopping_basket['ID'] = id_set
- shopping_basket['Basket'] = data_set
- shopping_basket

将数据转换为DataFrame类型
- data = pd.DataFrame(shopping_basket)
- data
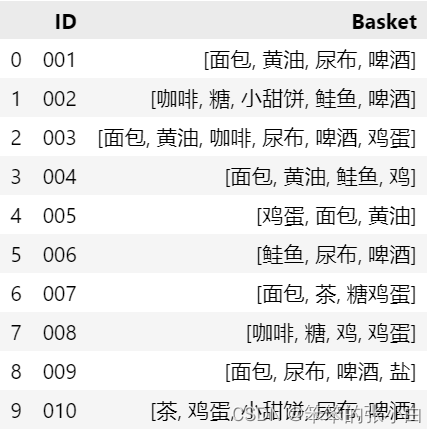
接着我们需要将Basket的数据转换为one-hot(0,1)编码
这一步主要就是对数据的ID和Basket进行划分处理,最后进行合并
- data_id = data.drop('Basket',1)
- data_basket = data['Basket'].str.join(',')
- data_basket = data_basket.str.get_dummies(',')
- new_data = data_id.join(data_basket)
- new_data
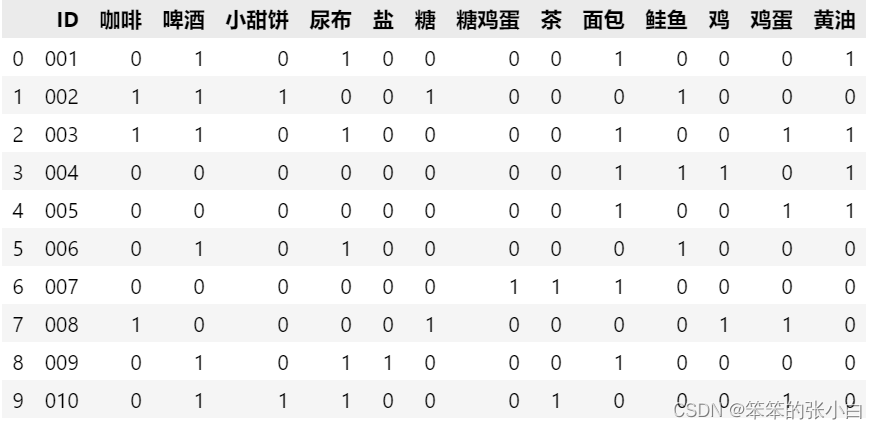
调用apriori算法
apriori()中min_support也就是最小支持度默认为0.5,所以我们要修改的话直接修改这个值
- frequent_itemsets = apriori(new_data.drop('ID',1),min_support=0.5,use_colnames=True)
- frequent_itemsets
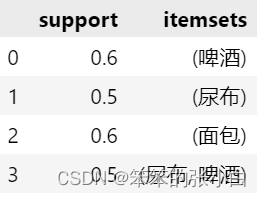
从结果中,我们发现在二项集中,出现了尿布和啤酒,说明尿布和啤酒的关联性很大。
接着我们查看其具体的关联规则
association_rules(frequent_itemsets,metric='lift')
我们看出尿布和啤酒的提升度值也很大(大于1) ,更一步说明了尿布和啤酒的关联性很强,所有在销售的时候,应该将其放在一起售卖,或者适当增加一下促销方式。
案例二
步骤跟案例一相似
准备数据
- shopping_backet = {'ID':[1,2,3,4,5,6],
- 'Basket':[['Beer','Diaper','Pretzels','Chips','Aspirin'],
- ['Diaper','Beer','Chips','Lotion','Juice','BabyFood','Milk'],
- ['Soda','Chips','Milk'],
- ['Soup','Beer','Diaper','Milk','IceCream'],
- ['Soda','Coffee','Milk','Bread'],
- ['Beer','Chips']
- ]
- }
- data = pd.DataFrame(shopping_backet)
- data
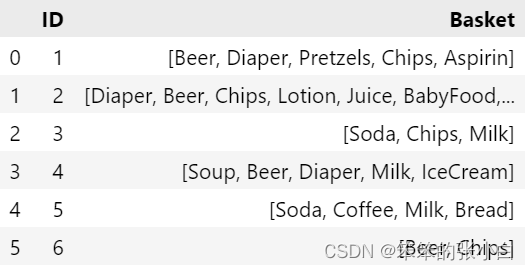
将数据转换为apriori算法要求的数据类型
- data_id = data.drop('Basket',1)
- data_basket = data['Basket'].str.join(',')
- data_basket = data_basket.str.get_dummies(',')
- new_data = data_id.join(data_basket)
- new_data
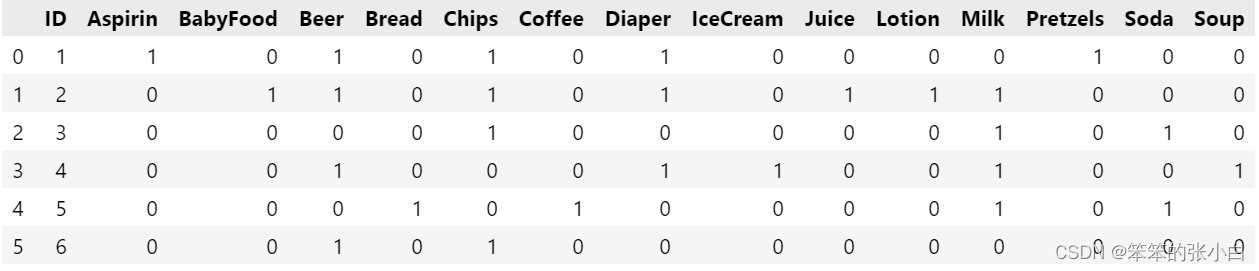
调用apriori算法
- frequent_itemsets = apriori(new_data.drop('ID',1),min_support=0.5,use_colnames=True)
- frequent_itemsets
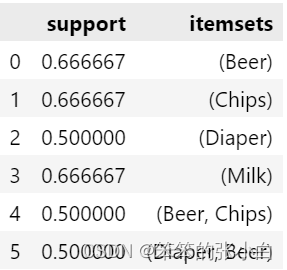
如果光考虑support支持度,那么[Beer, Chips]和[Diaper, Beer]都是很频繁的,那么哪一种组合更相关呢?
association_rules(frequent_itemsets,metric='lift')
显然[Diaper, Beer]的lift值更大,说明这个组合更相关

