
- 1spring boot的返回值里面含有net.sf.json.JSONObject 报错net.sf.json.JSONNull[“empty“])]
- 2xcode构建webdriverAgent时报错Messaging unqualified id的解决办法
- 3Notion笔记汉化
- 42019年RT-Thread开发者大会来袭,参与赢四重好礼
- 5迁移学习(Transfer)
- 6机器人3D视觉在物流仓储领域的自动化应用_快递仓储的码垛
- 7Vue3中使用vue-i18n实现多语言切换_vue3 多语言
- 8Rasa及Rasa-x官方教程及视频_rasax
- 9html超链接打开安卓应用,android html超链接文本 点击跳转的两种实现
- 10大力出奇迹——GPT系列论文学习(GPT,GPT2,GPT3,InstructGPT)_gpt论文
Windows环境下搭建chatGLM-6B-int4量化版模型(图文详解-成果案例)_chatglm3-6b 如何设置为 int4
赞
踩
目录
方式一:在Hugging Face HUb下载(挂VPN访问,建议)
一、ChatGLM-6B介绍
ChatGLM3 是智谱AI和清华大学 KEG 实验室联合发布的对话预训练模型。ChatGLM-6B 是一个开源的、支持中英双语的对话语言模型,基于 General Language Model (GLM) 架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。 ChatGLM-6B 使用了和 ChatGPT 相似的技术,针对中文问答和对话进行了优化。经过约 1T 标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62 亿参数的 ChatGLM-6B 已经能生成相当符合人类偏好的回答,更多信息请参考我们的博客。欢迎通过 chatglm.cn 体验更大规模的 ChatGLM 模型。
为了方便下游开发者针对自己的应用场景定制模型,同时实现了基于 P-Tuning v2 的高效参数微调方法 (使用指南) ,INT4 量化级别下最低只需 7GB 显存即可启动微调。
二、环境准备
1. 硬件环境

如果需要在 cpu 上运行量化后的模型,还需要安装 gcc 与 openmp。多数 Linux 发行版默认已安装。对于 Windows ,可在安装 TDM-GCC 时勾选 openmp。 Windows 测试环境 gcc 版本为 TDM-GCC 10.3.0, Linux 为 gcc 11.3.0。
2. TDM-GCC安装
参考博客:Windows安装tdm-gcc并勾选openMP(详细图文)-CSDN博客
3.git安装
百度安装
4.Anaconda安装
三、模型安装
1.下载ChatGLM-6b和环境准备
下载地址:https://github.com/THUDM/chatglm-6B
从 Github 下载 ChatGLM-6B 仓库,然后进入仓库目录使用 pip 安装依赖,
其中 transformers 库版本推荐为 4.27.1,但理论上不低于 4.23.1 即可。
方式一:git命令
(1)在D盘打开命令提示窗口,默认下载到当前目录
git clone https://github.com/THUDM/ChatGLM-6B
(2)切换到chatGLM-6B目录
cd ChatGLM-6B
(3)创建conda的虚拟环境,指定Python的版本
conda create -n torch python=3.10
(4)激活环境
conda activate torch
(5)下载依赖包
pip install -r requirements.txt
方式二:手动下载
(1)在github地址:https://github.com/THUDM/chatglm-6B
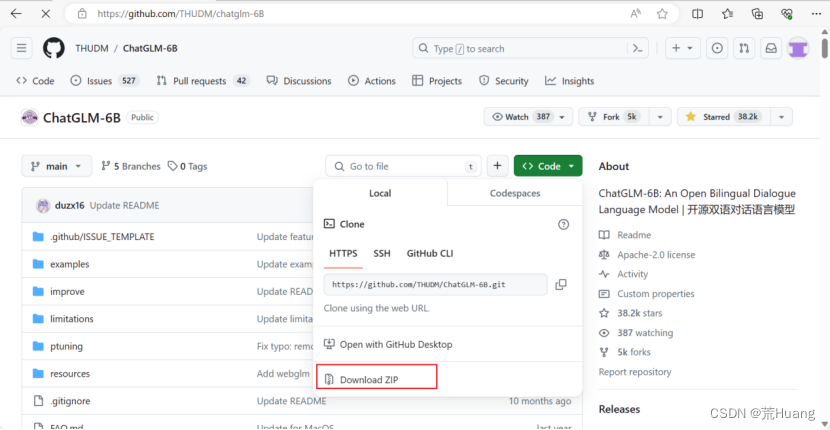
解压到你自己的目录
(2)切换到ChatGLM-6B目录
cd ChatGLM-6B
(3)创建conda的虚拟环境,指定Python的版本
conda create -n torch python=3.10
(4)激活环境
conda activate torch
(5)下载依赖包
pip install -r requirements.txt
2.下载预训练模型
方式一:在Hugging Face HUb下载(挂VPN访问,建议)
(1)git命令行下载:
从 Hugging Face Hub 下载模型需要先安装Git LFS ,若安装了Git LFS可在windows命令提示符中运行如下命令检查版本 git lfs --version

若存在Git LFS,则运行:
- git lfs install
- git clone https://huggingface.co/THUDM/chatglm-6b
(2)手动下载
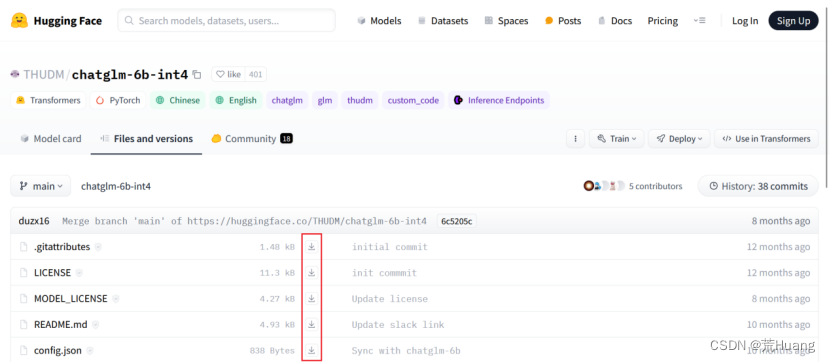
访问地址:https://huggingface.co/THUDM/chatglm-6b-int4/tree/main
把下图中所有的文件下载之后,放在ChatGLM-6B的新建的model目录下。
方式二:在魔塔社区下载(亲测速度快,不建议)
注意:亲测不建议使用,因为它的目录文件不能及时和Hugging Face上的目录文件一致,会出现各种报错,因此后续作者在遇到问题的时候更换了下载方式。
git命令行下载
访问地址:魔搭社区
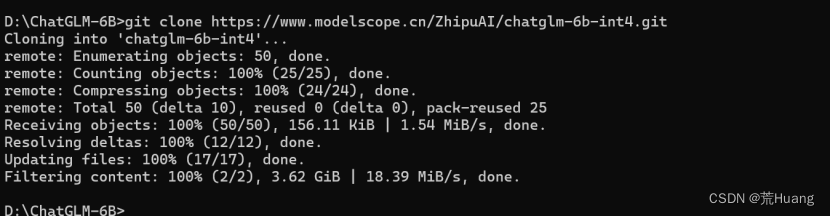
运行命令:
git clone https://www.modelscope.cn/ZhipuAI/chatglm-6b-int4.git下载截图如下:
3.模型使用
ChatGLM-6B 提供了三种使用方式:命令行 Demo,网页版 Demo 和 API 部署;在启动模型之前,需要找到对应启动方式的 python 源码文件,命令行模式(cli_demo.py),网页版(web_demo.py),API部署(api.py) 中修改代码。
ChatGLM-6B目录用到的文件:
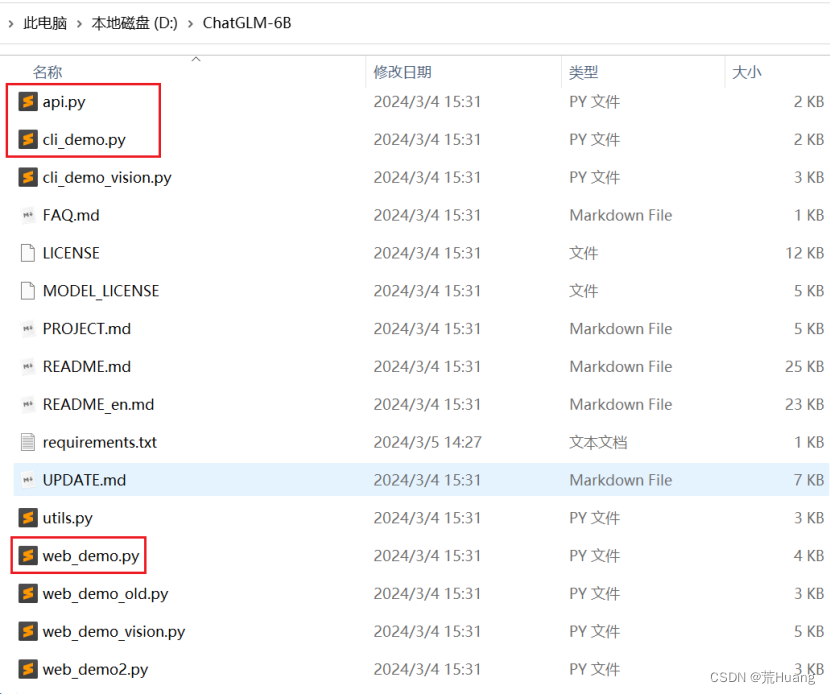
1.命令行版:cli_demo.py
(1)修改cli_demo.py的代码,根据自己目录结构修改。
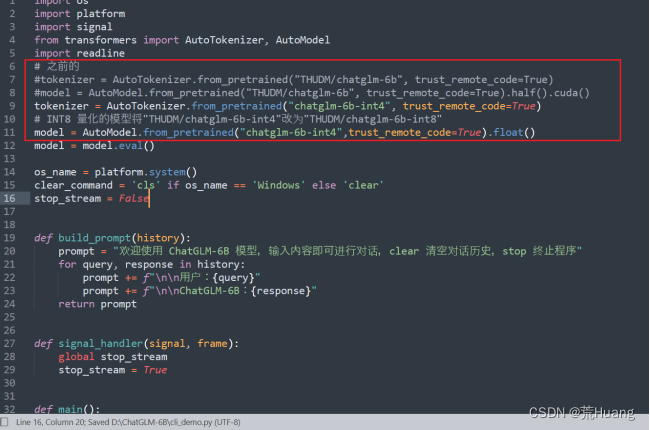
(2)运行
python cli_demo.py
注意:如果你没有 GPU 硬件的话,也可以在 CPU 上进行推理,但是推理速度会更慢。改加载模型为CPU部署,如果你的内存不足,可以直接加载量化后的模型:
- # INT8 量化的模型将"THUDM/chatglm-6b-int4"改为"THUDM/chatglm-6b-int8"
- model = AutoModel.from_pretrained("THUDM/chatglm-6b-int4",trust_remote_code=True).float()
2.Web版本:(web_demo.py)
(1)安装 Gradio:
pip install gradio
(2)修改web_demo.py的代码
根据自己的训练模型位置更改代码。

(3)启动基于 Gradio 的网页版 demo
python web_demo.py
说明:程序会运行一个 Web Server,并输出地址。在浏览器中打开输出的地址即可使用。最新版 Demo 实现了打字机效果,速度体验大大提升。注意,由于国内 Gradio 的网络访问较为缓慢,启用 demo.queue().launch(share=True, inbrowser=True) 时所有网络会经过 Gradio 服务器转发,导致打字机体验大幅下降,现在默认启动方式已经改为 share=False,如有需要公网访问的需求,可以重新修改为 share=True 启动。
3.API版本:api.py
开源模型 API 部署代码,可以作为任意基于 ChatGPT 的应用的后端。 目前,可以通过运行仓库中的 api_server.py 进行部署.
(1)安装额外的依赖
pip install fastapi uvicorn
(2)修改api.py的代码
根据自己的训练模型位置更改代码
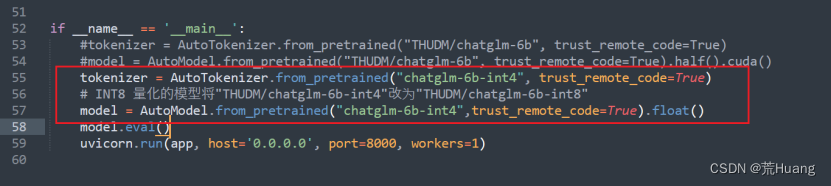
(3)启动API模型
python api.py
四、遇到的问题
问题一:在启动cli_demo的时候报错 No module named 'readline'

解决方法:下载pyreadline3
- pip: pip install pyreadline3 or python -m pip install pyreadline
- mamba: mamba install -c conda-forge pyreadline3
- conda: conda install -c conda-forge pyreadline3
作者采用的是pip install pyreadline3

问题二:
not found in your environment: configuration_chatglm. Run `pip install configuration_chatglm`
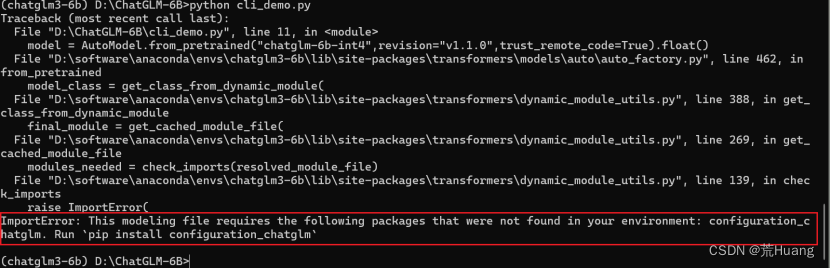 解决方法:重新下载预训练模型,不通过命令从modelScope下载,直接到hugging face找到对应chatglm-6b-int4手动下载全部文件。手动下载之后放到新建的model。之后记得修改web_demo.py、api.py、cli_demo.py对应的它们代码如图所示:
解决方法:重新下载预训练模型,不通过命令从modelScope下载,直接到hugging face找到对应chatglm-6b-int4手动下载全部文件。手动下载之后放到新建的model。之后记得修改web_demo.py、api.py、cli_demo.py对应的它们代码如图所示:

后续在运行各个web_demo.、api.py、cli_demo.py,虽然有报错但是不影响运行。
问题三:FileNotFoundError: Could not find module 'nvcuda.dll' (or one of its dependencies). Try using the full path with constructor syntax.
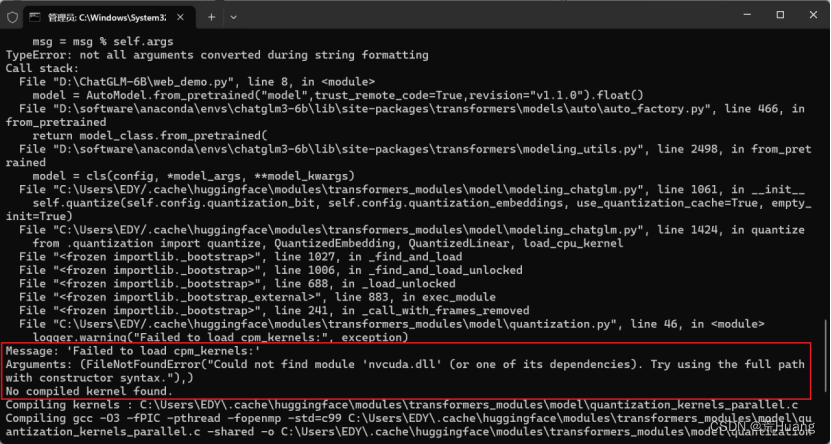
解决方法:目前不影响程序正常运行,网上的方式:在下载好的chatglm-6B-int4中找到quantization.py,修改如下:
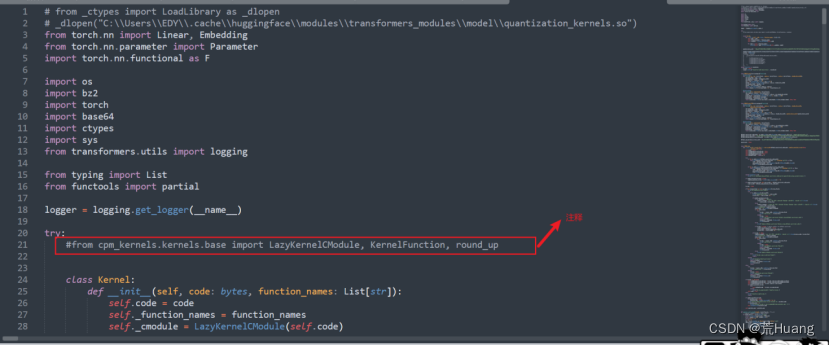
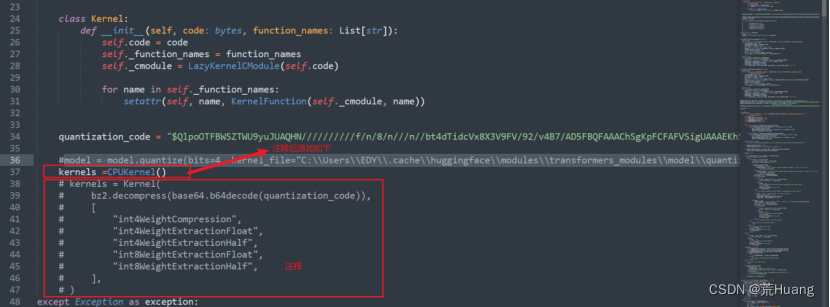
仍然报错:
Message: 'Failed to load cpm_kernels:'
Arguments: (NameError("name 'CPUKernel' is not defined"),)

也不影响程序继续运行。
问题四:
FileNotFoundError: Could not find module 'C:\...\model\quantization_kernels_parallel.so' (or one of its dependencies). Try using the full path with constructor syntax.
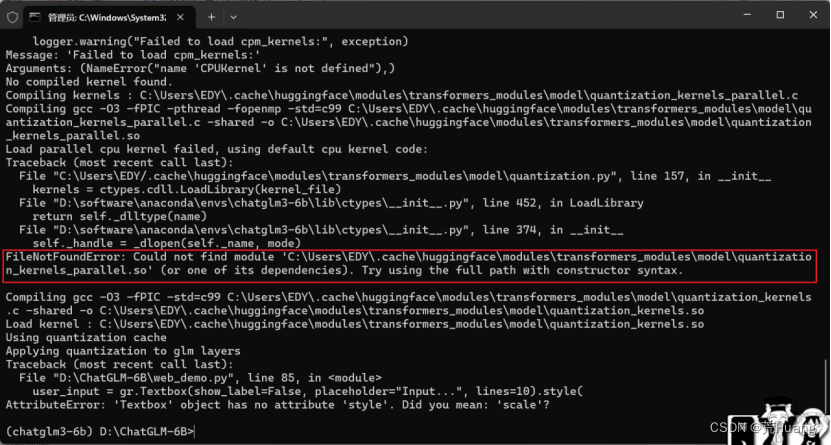
解决方法:无影响可以运行 。
问题五:在运行web_demo.py的时候报错如下:
Traceback (most recent call last):
File "D:\ChatGLM-6B\web_demo.py", line 85, in <module>
user_input = gr.Textbox(show_label=False, placeholder="Input...", lines=10).style(
AttributeError: 'Textbox' object has no attribute 'style'. Did you mean: 'scale'?

解决方法:pip默认安装最新版本,降低版本即可。
卸载gradio
pip uninstall gradio
安装指定版本
pip install gradio==3.50.0
五、成果展示
1.命令行版:cli_demo.py

亲测:回复时间比较久,可能是与电脑的CPU硬件环境有关。
2.Web版:web_demo.py
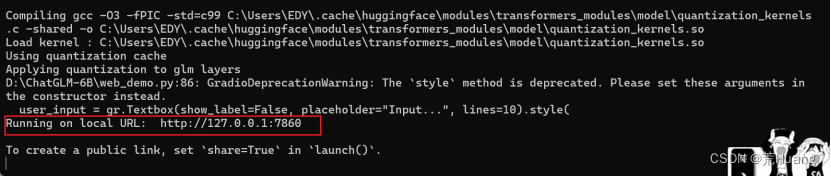
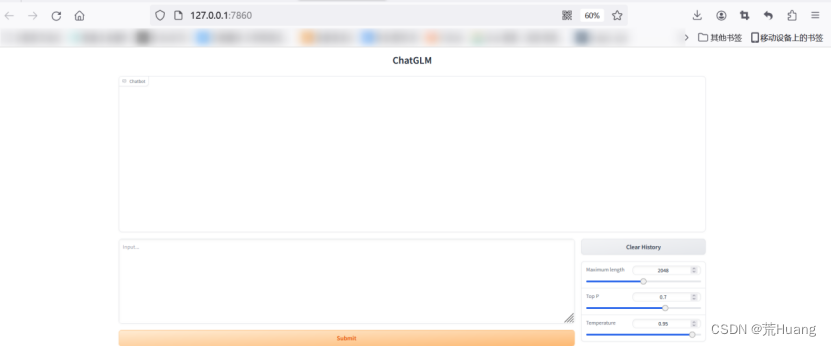
3.API版:api.py

到此,部署ChatGLM-6B-int4结束。

