
- 1随身Wi-Fi刷入debian_随身wifi刷debian
- 2鸿蒙ArkUI实例:【自定义组件】
- 3云原生数据库特征
- 4别再畏惧写作了!这9款AI写作工具让你轻松驾驭文字创作 #科技#其他#知识分享
- 5Spring Boot通过@RequestParam接收前端表单传来的数据_springboot接收表单数据
- 6论文精讲 | CVPR 2022|RHFL-对抗噪声的联邦学习_fedproto: federated prototype learning across hete
- 7SOLIDWORKS® 2024 新功能 - 3D CAD
- 8Windows下运行.sh文件,可在git bash中运行,也可在cmd、pycharm 终端中运行。.sh文件中指定虚拟环境。_windows执行sh文件
- 9全面解读AI框架RAG
- 10【数据结构】什么是算法_数据结构的算法定义
特征选择python代码_features_top = intermediate_features[-1].detach().
赞
踩
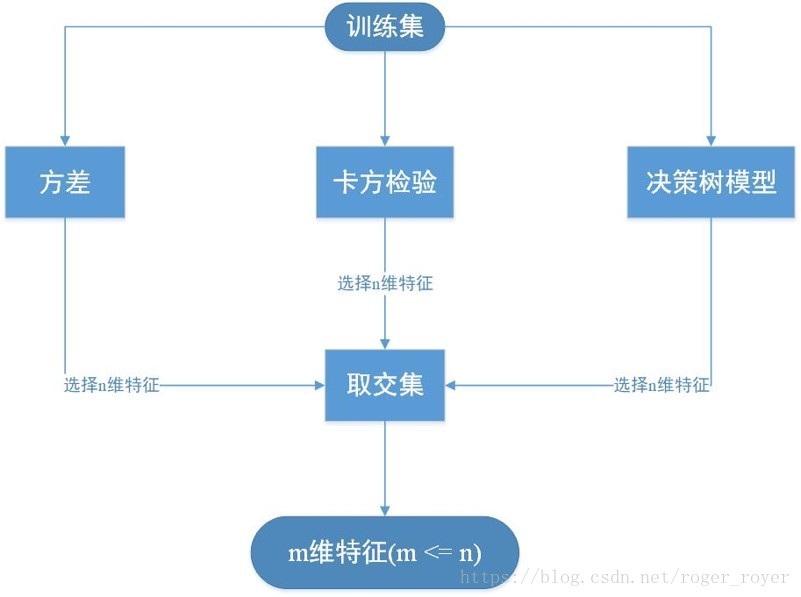
为什么不做特征之间相关性的动作呢,我理解实际上决策树模型应该可以解决绝大部分此类的工作,但是做一下也不妨,很多人不做是因为代码较为麻烦,还要区分数值型还是字符型。简洁一点也不是什么坏事。
#coding=utf-8
import numpy as np
import pandas as pd
'''单变量特征选取'''
from sklearn.feature_selection import SelectKBest, chi2
'''去除方差小的特征'''
from sklearn.feature_selection import VarianceThreshold
'''循环特征选取'''
from sklearn.svm import SVC
from sklearn.feature_selection import RFE
'''RFE_CV'''
from sklearn.ensemble import ExtraTreesClassifier
class FeatureSelection(object):
def __init__(self, feature_num):
self.feature_num = feature_num
self.train_test, self.label, self.test = self.read_data() # features #
self.feature_name = list(self.train_test.columns) # feature name #
def read_data(self):
test = pd.read_csv(r'test_feature.csv', encoding='utf-8')
train_test = pd.read_csv(r'train_test_feature.csv', encoding='utf-8')
print('读取数据完毕。。。')
label = train_test[['target']]
test = test.iloc[:, 1:]
train_test = train_test.iloc[:, 2:]
return train_test, label, test
def variance_threshold(self):
sel = VarianceThreshold()
sel.fit_transform(self.train_test)
feature_var = list(sel.variances_) # feature variance #
features = dict(zip(self.feature_name, feature_var))
features = list(dict(sorted(features.items(), key=lambda d: d[1])).keys())[-self.feature_num:]
# print(features) # 100 cols #
return set(features) # return set type #
def select_k_best(self):
ch2 = SelectKBest(chi2, k=self.feature_num)
ch2.fit(self.train_test, self.label)
feature_var = list(ch2.scores_) # feature scores #
features = dict(zip(self.feature_name, feature_var))
features = list(dict(sorted(features.items(), key=lambda d: d[1])).keys())[-self.feature_num:]
# print(features) # 100 cols #
return set(features) # return set type #
def svc_select(self):
svc = SVC(kernel='rbf', C=1, random_state=2018) # linear #
rfe = RFE(estimator=svc, n_features_to_select=self.feature_num, step=1)
rfe.fit(self.train_test, self.label.ravel())
print(rfe.ranking_)
return rfe.ranking_
def tree_select(self):
clf = ExtraTreesClassifier(n_estimators=300, max_depth=7, n_jobs=4)
clf.fit(self.train_test, self.label)
feature_var = list(clf.feature_importances_) # feature scores #
features = dict(zip(self.feature_name, feature_var))
features = list(dict(sorted(features.items(), key=lambda d: d[1])).keys())[-self.feature_num:]
# print(features) # 100 cols #
return set(features) # return set type #
def return_feature_set(self, variance_threshold=False, select_k_best=False, svc_select=False, tree_select=False):
names = set([])
if variance_threshold is True:
name_one = self.variance_threshold()
names = names.union(name_one)
if select_k_best is True:
name_two = self.select_k_best()
names = names.intersection(name_two)
if svc_select is True:
name_three = self.svc_select()
names = names.intersection(name_three)
if tree_select is True:
name_four = self.tree_select()
names = names.intersection(name_four)
print(names)
return list(names)
selection = FeatureSelection(100)
selection.return_feature_set(variance_threshold=True, select_k_best=True, svc_select=False, tree_select=True)

