
- 1树莓派配置环境变量,解决No such file or directory的错误提示_树莓派vncunable to open i2c device: no such file or d
- 2洛谷p3817 小A的糖果
- 3C语言easyx飞机大战源码+素材(大屏版)_易语言 飞机大战
- 4基于SpringBoot的农产品销售小程序平台的设计与实现_基于springboot粮食加工订单
- 5Word Tokenization
- 6浅析自动编码器(自编码器 Autoencoder)_深度学习 coding decoding
- 7抖音商品详情数据接口python_python 获取抖音商户信息
- 8MATLAB非线性规划优化问题_带约束的非线性优化算法代码
- 9毕业设计:基于卷积神经网络的图像分类系统 python人工智能_基于卷积神经网络的图像分类系统研究研究或设计的目的和意义:
- 10Dual Contrastive Learning: Text Classification via Label-Aware Data Augmentation 阅读笔记_dual-pool contrastive learning
2020年美赛C题(数据分析题)O奖论文笔记 (2)_2020美赛c题优秀论文
赞
踩
前言
题目可参见这里:C题
下面简单做一下另外一篇O奖论文的笔记,上一篇O奖论文较难,这篇相对来说比较好读。
论文
题目: 《在线销售战略:融合深度学习和差分模型的评论跟踪系统》

作者用少量的语言介绍了一下background,接着讲述了解决问题的一个overview.
- 首先基于star rating和review text设定了5个指标:average star rating,favorable rate,number of reviews,average number of review words,average review sentiment value. 使用TF-IDF算法提取关键词,使用BP神经网络计算评论情感得分。通过这种方式,探索出了review sentiment和star rating之间的特定关系,并提出三种产品的设计焦点所在。
- 接着,建立差分模型,探索每个评价指标随时间和其他指标的变化模式
- 最后,根据PCA,提出success index(成功指数),来评价三种产品成功与否,给出企业建议
接着,作者在第三段列举出了4个建模得到的重要结论,这里不多说了,详见原文。
倒数第二段说还给企业写了一封信,此处也列出了信件的3个核心要点.
最后一段用两句话,夸了一下自己的模型(simple,effective,practical)

谈了一下用户购买数据对商家的潜在价值,简单重述了一下问题,并挂出建模框架总图

- 亚马逊给出的数据是真实可用的. 辩解(justification): 题目要求只能使用提供的数据集,因此,在数据来源唯一的情况下,需要假设这些数据是available和reliable的!
- 外部环境影响因素不考虑进来. 辩解: 认为这三样东西都是生活必需品,受外部环境因素的影响可以忽略。
- Amazon的内部系统不考虑进来. 辩解: 因为数据来源唯一,缺少Amazon内部如监控环境等的数据,因此必须忽略Amazon的内部系统才能继续建模。

4.1 数据清洗:
- 缺失值和异常值
- 只有一条评论的产品
- 2010年前交易数据(因为这些数据存在不连续,占的比例也太多,尽管清洗吧~)
4.2 数据观察:
4.2.1 产品生命周期观察
定义产品的lifecycle为观测到的第1条评论和最后1条评论的时间段

这幅图讲的大概是这么一个意思(以hair_dryer为例):活跃评论在3个月内的hair_dryer品牌数有3个,活跃评论在 3个月 ~ 1年内的品牌数有11个,如此下去… (笔者番外:就直觉来讲,一个品牌的评论能够活跃越长的时间,这个品牌口碑好的可能性较大)
从上图还能提取到的一个重要信息是:所有商品数据的时间跨度至少在3个月以上,也就是说,可以 以季度为单位 做时间序列。
4.2.2 星级和文本指标 变化趋势

论文作者认为helpfulness ratings对销售的影响大,单独抽出来。结果如上图,每类商品都有两条曲线,一条是 star rating-时间曲线,一条是 helpfulness ratings-时间曲线。
作者在计算评论对应的星级时,发现hair_dryer和pacifier的平均星级处于稳定趋势,没有什么显著的变化;而microwave处于上升趋势。但作者同时发现,如果只计算helpful votes,那么三件产品的趋势都是下降的。此外,作者认为必须关注helpfulness ratings更多的reviews,helpfulness更多,对顾客的吸引力越大,能够更好地预测未来商品走势。

对于review文本,作者计算了review的总量和每条review平均的词数,发现三种商品的reviews数都是处于上升状态,而每条review平均的词数都是下降趋势。

对于文本的情感,鉴于目前尚未建立起一套完整的分析系统,作者先定义满足下面两个要求的是情感倾向good的评论:
- 包含褒义词
- 没有贬义词
附录A举出了这样的词语:

有了这个评价手段,就可以计算每个季度里三类产品的好评率。根据下图,作者看出好评率呈现出强自相关。原文如下:


4.2.3 基于star ratings和基于文本 评价指标关系

原文写道:Obviously, there is a positive correlation between star ratings and percentage of favorable reviews – the higher the star ratings, the higher the percentage. Moreover, the numbers of reviews has no evident impacts on the percentage of favorable reviews. In addition, the average text word number does not have fixed effects on the percentage of favorable reviews.
就是说了以下三点:
- star rating和好评率存在正相关
- reviews数量和好评率没有明显相关性
- reviews平均词数和好评率没有固定相关性
4.2.4 基于star ratings和文本的评价指标
首先是star ratings 的评价指标:

Nt是在第 t 季度得到的评论数,rj是第 j 条评论的星级,vj是第 j 条评论的helpfulness,IVerified和IVined是indicator functions。
接着是文本的评价指标:
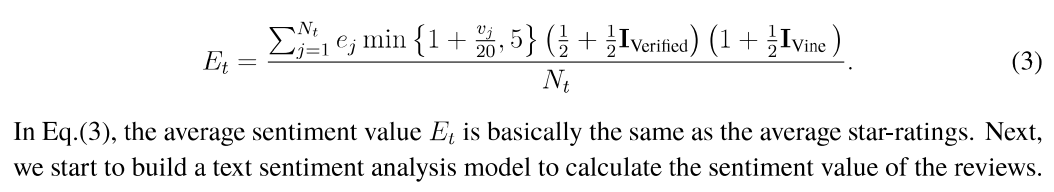
这里的ej需要接下来的模型帮助确定。
5.1 A Text Sentiment Analysis Model Based on Deep Learning
5.1.1 Steps of the Text Sentiment Analysis Model
作者首先做了关键词抽取,因为关键词是最能够代表句子情感的。但是,在进行抽取之前,先去掉所谓的停顿词(stop words),附录B记录了891个stop words:

其次,作者使用TF-IDF算法抽取关键词,TF-IDF是自然语言处理中使用的一种算法,这里不多讲,上网学习一下就可以了。
再次,作者将这些关键词转化为词向量。其实有两种方法可以判定文本的情感,本文作者选择了第2种:
- 第一种是查找情感字典,一般这些字典里面都已经预定好了情感词的参数,判定的时候只需要根据计算方法把这些指标综合即可
- 第二种是深度学习,将关键词转为数学向量,搭建并训练神经网络
首先对关键词进行计数并转化为独热编码:

但关键词一多,这些向量也会变得很长,神经网络训练的时间将会十分缓慢。所以,作者还使用了连续词袋模型,进行降维。

最后,将词向量转为句子向量,用神经网络训练。通过上面的处理,可以得到各个关键词向量。对于一个reivew,作者把这些词向量求和平均,作为review的句向量。有了句向量后,将该向量送入神经网络,最后得到一个代表review句子情感得分的值。训练需要训练数据集,作者如下处理:

整个深度学习框架用下图总结(作者高妙之处,在合适的地方做阶段总结,且总结能用图表就用图表,实在不行才用文字)

5.1.2 Analysis of Model Results
上面的深度模型精度还挺高(94%),接下来要填上面的一个坑:

现在模型已经有了,那么ej可以由模型来确定,也就是重新审视review和star rating的关系。

这张图给出的信息量其实挺大,作者从中提炼出了以下信息:
- 2010-2012,中性和正面评论文本量化值与赞同率正相关,但2012年后这种关系就不明显了
- 三种产品的差评率和负面文本量化值的相关关系明显。原文:
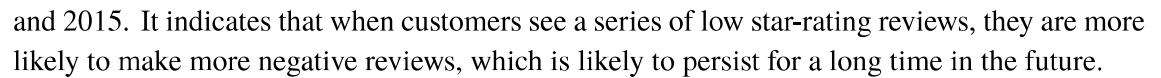
作者同时观察统计了正负面评价对应的星级高低,发现高星级会引发更多正面的评价,但很难衡量低星级和负面评价之间的关系。

作者使用经过TF-IDF算法提取之后的关键词,来给sunshine公司提供产品建议。下面图中,出现频次最多的当然是情感词,其次是描述性形容词(descriptive adjectives),然后是产品特征形容词。
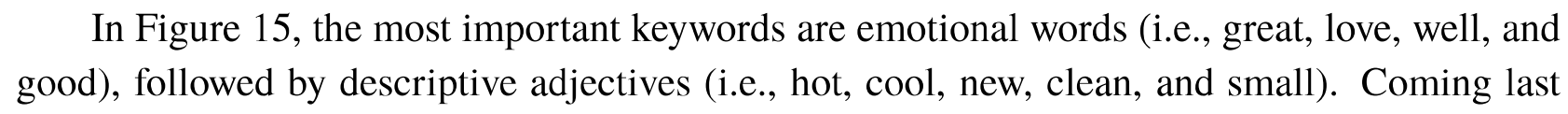
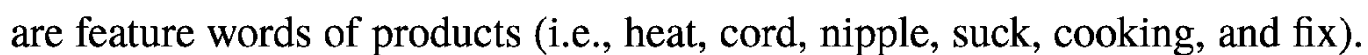

提出的建议如下(基本就是对症下药):


5.2 A Difference Equation Prediction Model
5.2.1 Correlation Analysis of Evaluation Indicators

计算ACF和PACF,以hair dryer为例,有:

如果指标的一阶ACF较大且拖尾,且一阶PACF被截断,则表明该指标具有较强的一阶自相关。结果表明,Nt在3种产品中均表现出明显的自相关,Pt和NtW在奶嘴和微波炉中表现出自相关,而Rt和Et仅在吹风机中表现出自相关。除了平均星级和平均情感值外,我们还验证了4.2.2节中其他三个指标存在自相关的结论。在对帮助度评分、验证购买、vine设置不同权重后,每个季度的平均星级和情绪值基本保持稳定。这说明这两个指标可能主要受其他指标的影响,而不是它们本身。
接着使用皮尔逊相关系数观测变量之间的相关性:

5.2.2 Construction of Difference Equation Model
上面测定了各参数的自相关性和与其他参数的相关性之后,建立如下的差分方程:

5.2.3 Results and Analysis of Parameter Fitting
作者将三种产品的参数丢进模型进行拟合:


通过分析参数的拟合结果,作者得出:
- star rating的提升与前季度star rating和情感值呈现负相关
- 好评率、reviews数量和情感值的提升也和前季度对应的值负相关
这个现象看起来挺怪诞。为了探索上面现象出现的原因,作者还找到了证据(tqlb Orz),原因是存在Amazon’s click farming现象 点击跳转论文中出现的链接。

简单来说,就是顾客看到过多的好评,反而会觉得这样不真实(可能是Amazon卖家雇佣了网络水军,在“网络农场”上“耕耘”),所以在好评率高的产品面前,可能会给出差评(有点负反馈的味道)。可以阅读这个链接加深理解。
5.3 A Principal Component Analysis Model
5.3.1 Principle Introduction
这里简要介绍了主成分分析PCA,这里就不展开说了。
5.3.2 Model Results and Construction of the Success Index
选择累积方差贡献率在90%以上的成分作为主成分,例如hair dryer的PCA结果如下:


5.3.3 Effectiveness and Application of the Success Index

success index对于区分successful的产品和unsuccessful的产品,是一个good indicator。

作者在之前训练神经网络时,200条训练集数据通过人工标注打分。为了验证深度学习的稳定性,选取了5%和10%的text出来,这次不进行人工标注,直接观察会对最终的情感分数造成多大影响。


根据上面图表,减少人工标注的text对最终结果造成了很小的影响。这就说明建立的模型具有鲁棒性,之前产生的情感分数是可信、准确的。
此外,作者还对产品success index做了灵敏度分析,发现参数的变化对模型的影响也不大。
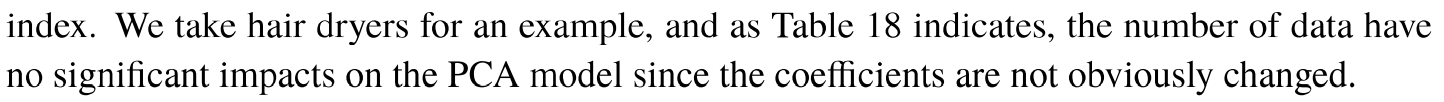

7.1 Strengths
- 通过先进深度学习模型,提高情感分析精度(参见5.1)
- 探索了基于时序的review数据,结果与真实数据一致(参见5.2)
- 提供了一个简单、有效和使用的追踪系统给公司(参见5.3)
7.2 Weaknesses
- 神经网络训练的时间长,且需要的数据集大。However, once the network is trained, it can be used for a long time, so the time cost is relatively small.
- 模型最多只到2015年,但2015年之后的评价指标可能会变。However, the patterns might change in the future, so it will be better to use the latest data.
概述了一下论文做的工作,通过模型得到的结论,阐述了一下Future work:
- 收集最新的数据
- 收集更具有代表性的reviews,从而对review文本的打分做出更精确的判断
- 引入更多review的特征,得到更多有说服力的参数,这里作者枚举了图片、评论者的信誉等等

接下去,作者阐述了建模过程中工作的概貌,但较少使用专业术语,显得通俗易懂。最后是提出一些见解,这里挑几个看看:


后记
最后推荐一些我个人觉得受用的学习或者工具链接:
[1] code-of-learn-deep-learning-with-pytorch(https://github.com/L1aoXingyu/code-of-learn-deep-learning-with-pytorch)
[2] 使用pytorch快速搭建BP神经网络(包含示例)(https://www.cnblogs.com/wangqinze/p/13424368.html)
[3] 八爪鱼采集器-免费网络爬虫软件 (https://www.bazhuayu.com/)
[4] scikit-learn-Machine Learning in Python【python机器学习库】(https://scikit-learn.org/stable/index.html)
[5] 美赛常用的建模方法 (https://blog.csdn.net/qq_45467148/article/details/104340051)
[6] nlp-pytorch-zh【自然语言处理】 (https://github.com/apachecn/nlp-pytorch-zh/tree/master/docs)
[7] LaTeX的"API"文档 (https://blog.csdn.net/Gentleman_Qin/article/details/79963396)
[8] LaTeX的使用教程 (https://liam.page/2014/09/08/latex-introduction/)
[9] Excel数据分析 (https://www.zhihu.com/question/19754722)
[10] Excel数据透视 (https://zhuanlan.zhihu.com/p/36785151)
[11] 武汉大学 - 黄正华的主页 - LaTeX的详尽用法与模板 (http://aff.whu.edu.cn/huangzh/)
[12] 时间序列-详解 (https://www.biaodianfu.com/arima.html)

