
- 1pyltp安装及运行_pyltp扩展包
- 2最新ChatGPT GPT-4 自然语言理解NLU与句词分类技术详解(附ipynb与python源码及视频讲解)——开源DataWhale发布入门ChatGPT技术新手从0到1必备使用指南手册(四)_gpt nlu
- 3关于设置VMware虚拟机里的IP所在网段与主机(Windows)电脑上的Ip所在网段一致的问题_与虚机同网段
- 4Transformer_transformer神经网络
- 5放心吧!基于图灵机的AI不会超越人类
- 6QGIS常用图源(谷歌中国、mapbox、esri、天地图等)(weixin公众号【图说GIS】)_qgis地图资源
- 7CVPR2021|一个高效的金字塔切分注意力模块PSA_高效金字塔注意力分割模块(epsa)
- 8pip国内镜像源_pipjingxiangyuan
- 9三大特征提取器(RNN/CNN/Transformer)
- 10C++PrimerPlus 课后习题第四章第8题(4.8)为什么getline()接受不到数据_c++为什么getline获取不到内容
【GNN报告】ICT敖翔:图机器学习应对金融欺诈对抗攻击_敖翔 中科院计算所
赞
踩
目录
1、简介
报告主题
图机器学习应对金融欺诈对抗攻击
报告嘉宾
敖翔(中国科学院计算技术研究所)

报告摘要
近年来,图机器学习方法由于其强大的关联特征提取能力,在数字金融反欺诈应用中取得了显著成效。然而,该场景中的动态对抗成为了制约图机器学习方法取得进一步提升的重要挑战之一。如何净化图结构中已存在的对抗攻击,如何增强图机器学习的鲁棒性提升分布外样本的泛化能力,成为近期研究热点。本报告将围绕图的同异质性偏好假设、对抗攻防、可解释性等技术,介绍图机器学习方法在应对动态对抗、增强分布外泛化能力和可解释性方面的研究进展,并探讨此方向值得关注的技术趋势。
报告人简介
敖翔,博士,中国科学院计算技术研究所副研究员,硕士生导师,CCF高级会员。研究方向为智能金融、数据挖掘与自然语言处理。先后主持国家自然科学基金项目3项,CCF-腾讯犀牛鸟科研基金(获优秀奖)、腾讯广告犀牛鸟专项基金、阿里巴巴AIR计划(获优秀学术合作项目)、蚂蚁金服金融安全专项基金等10余项科研项目,在IEEE TKDE、KDD、WWW、ICDE、SIGIR、ACL、AAAI、IJCAI等国际权威期刊和会议上发表论文60余篇,其中CCF A类30余篇。入选北京市科技新星、中科院青促会、微软亚洲研究院“铸星计划”。担任SIGKDD、WWW、ACL、AAAI、IJCAI等学术会议的高级程序委员或程序委员。
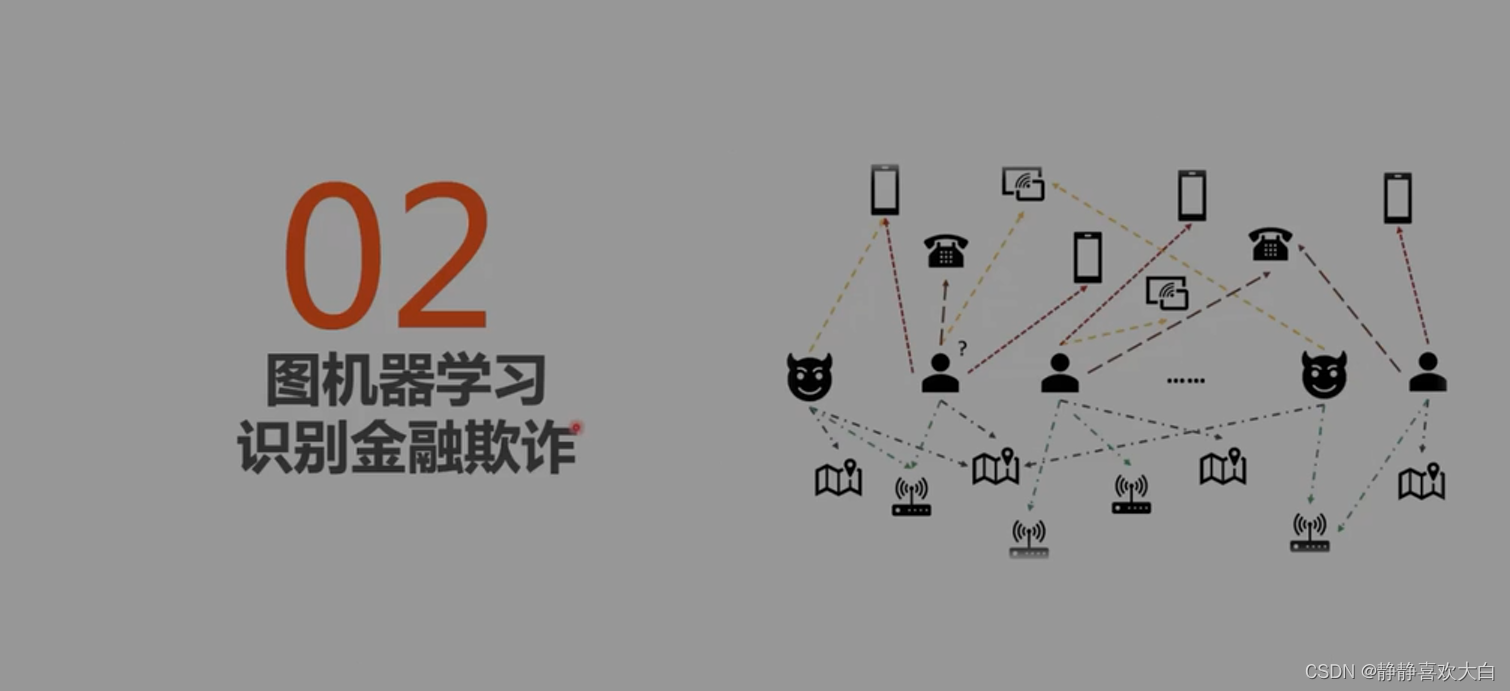
2、图机器学习应对金融欺诈对抗攻击
背景




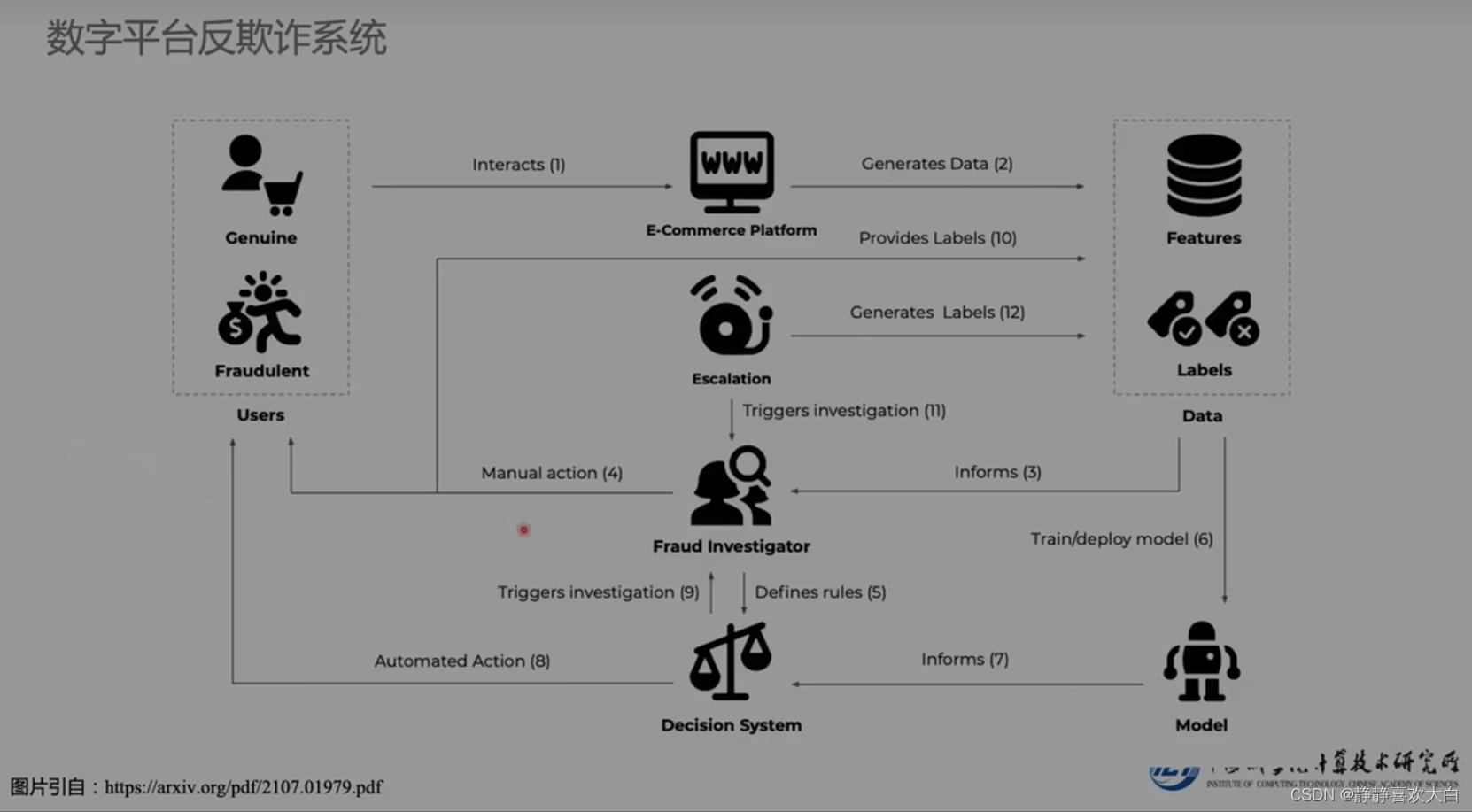
图机器学习识别金融欺诈
获取数据集

数据很多,标签也易获得(监督学习)
用户注册时+用户活动+用户关系收集
拿到数据后就可以训练模型,如下
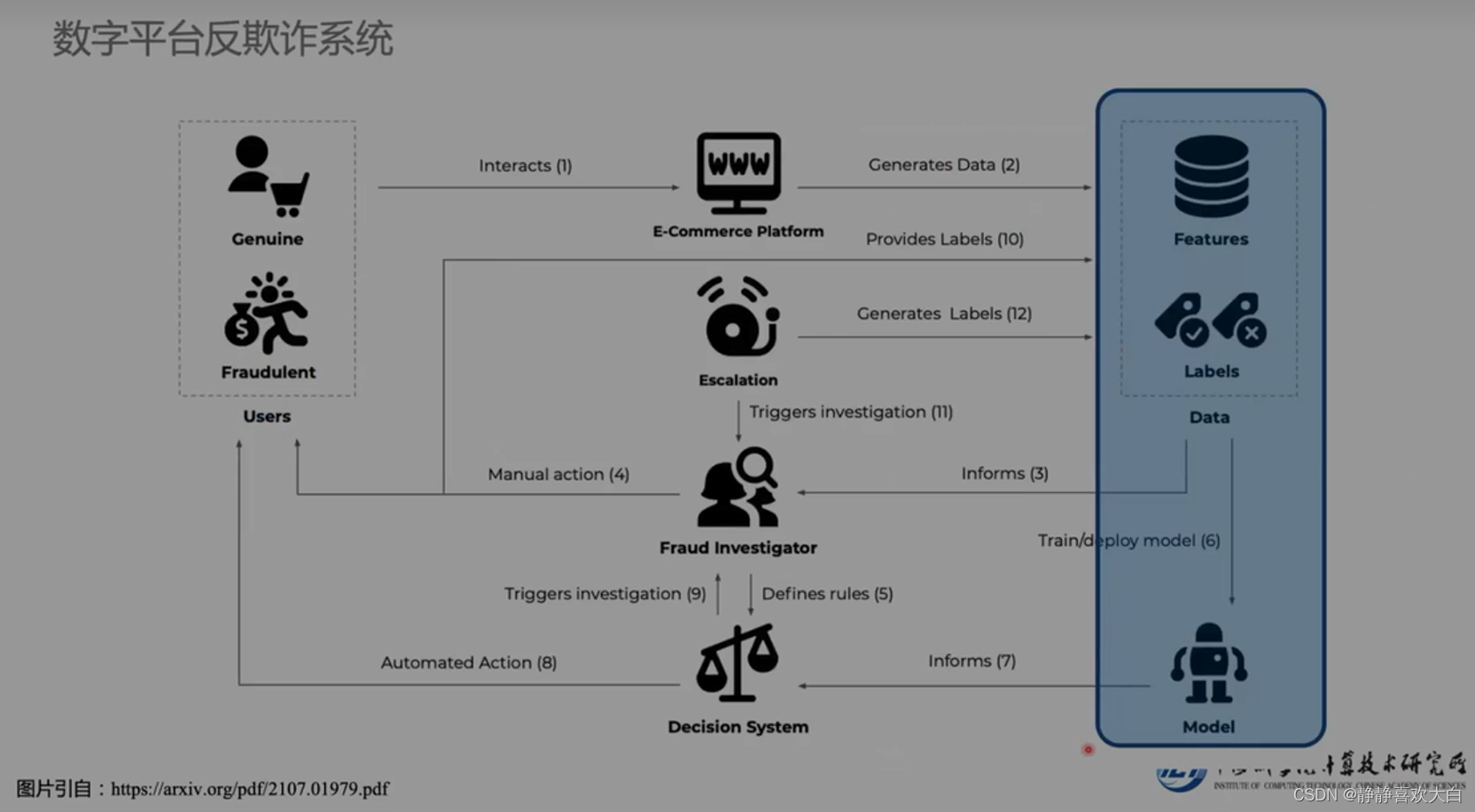
为啥使用图机器学习?

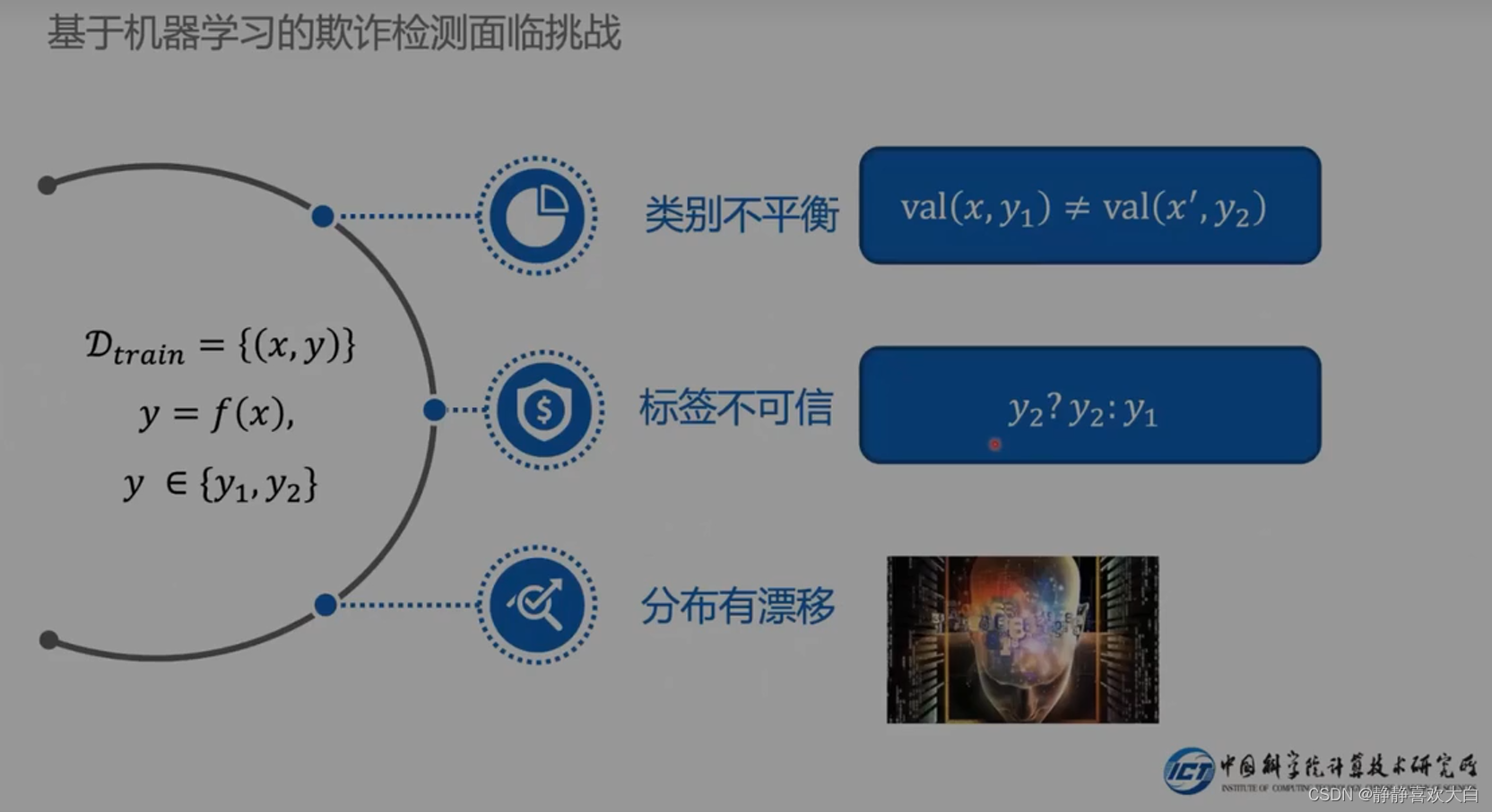
挑战
存在三个挑战

挑战1-类别不平衡的解决
类别不平衡:坏人还是少的
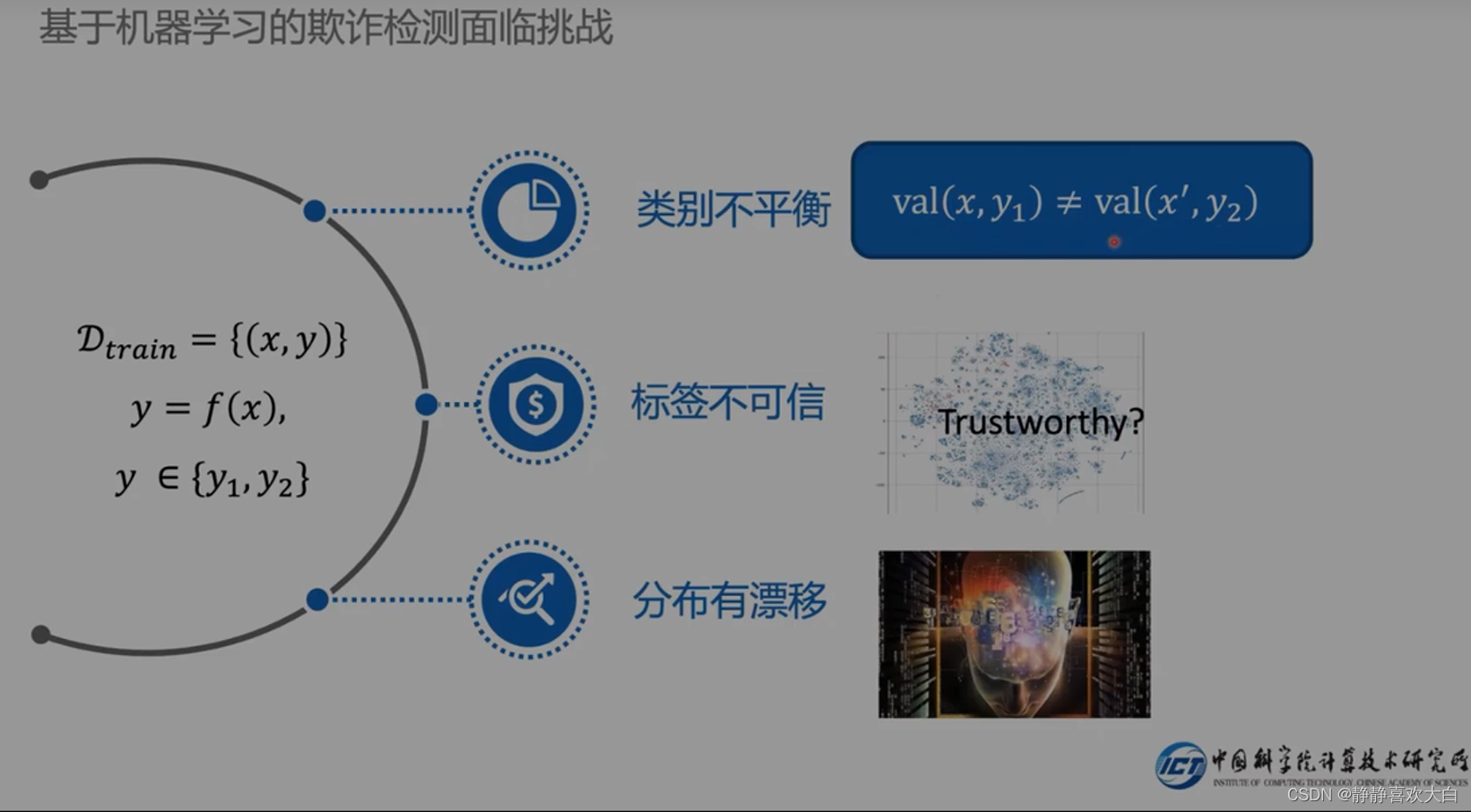
默认整个数据集都有label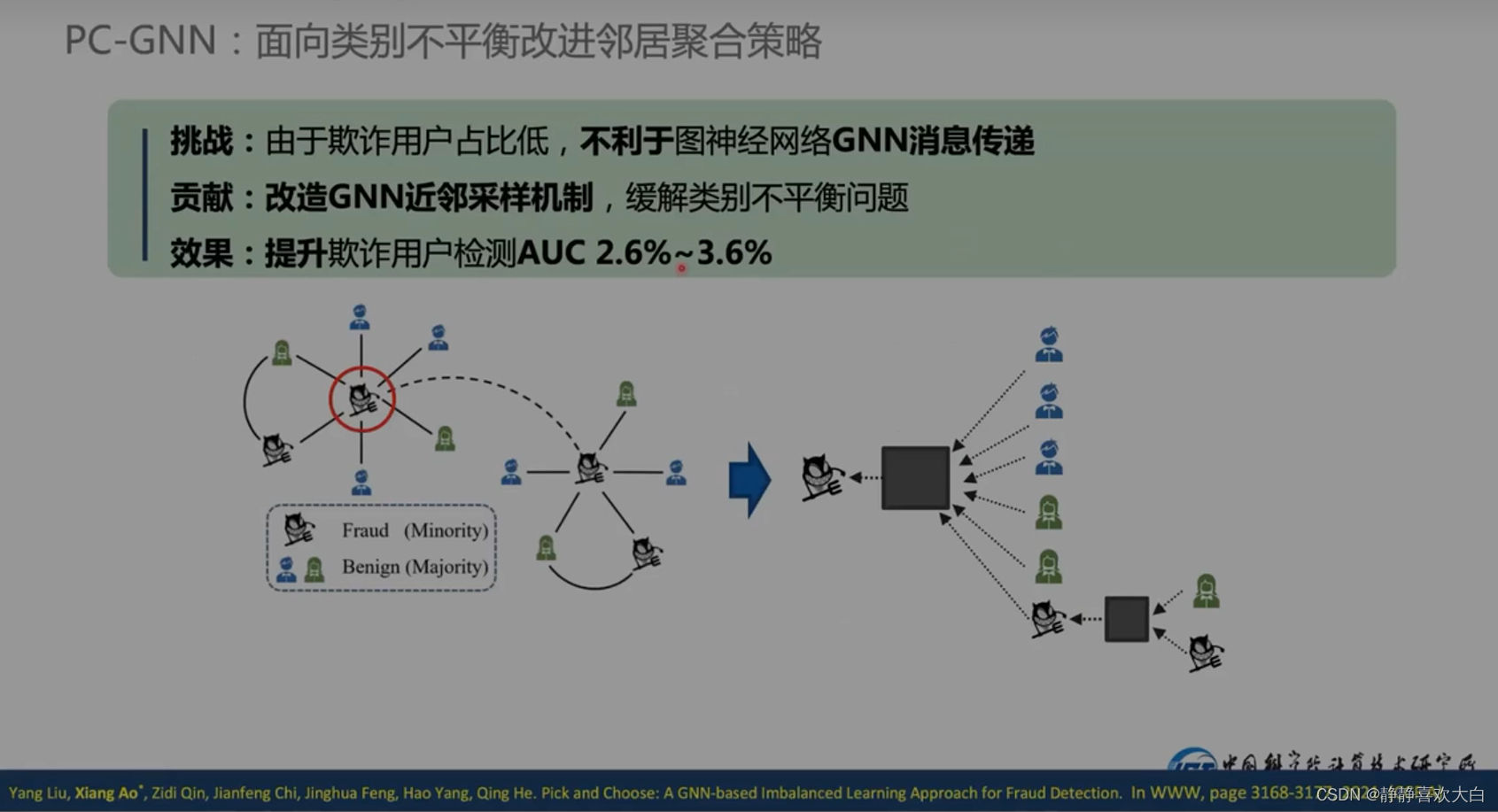
重采样
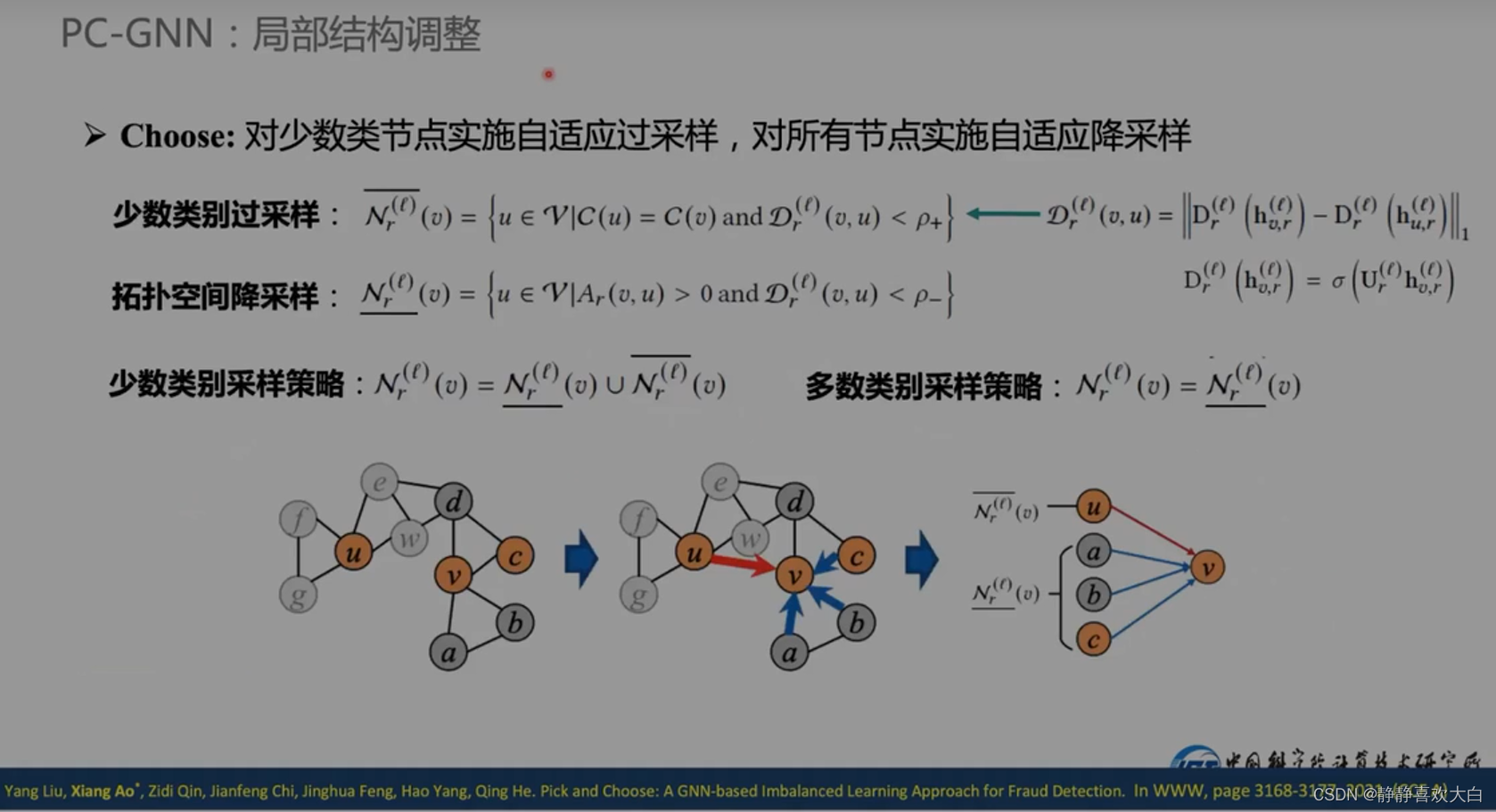
先对正常和非正常的节点采样差不多的量;之后距离自适应采样
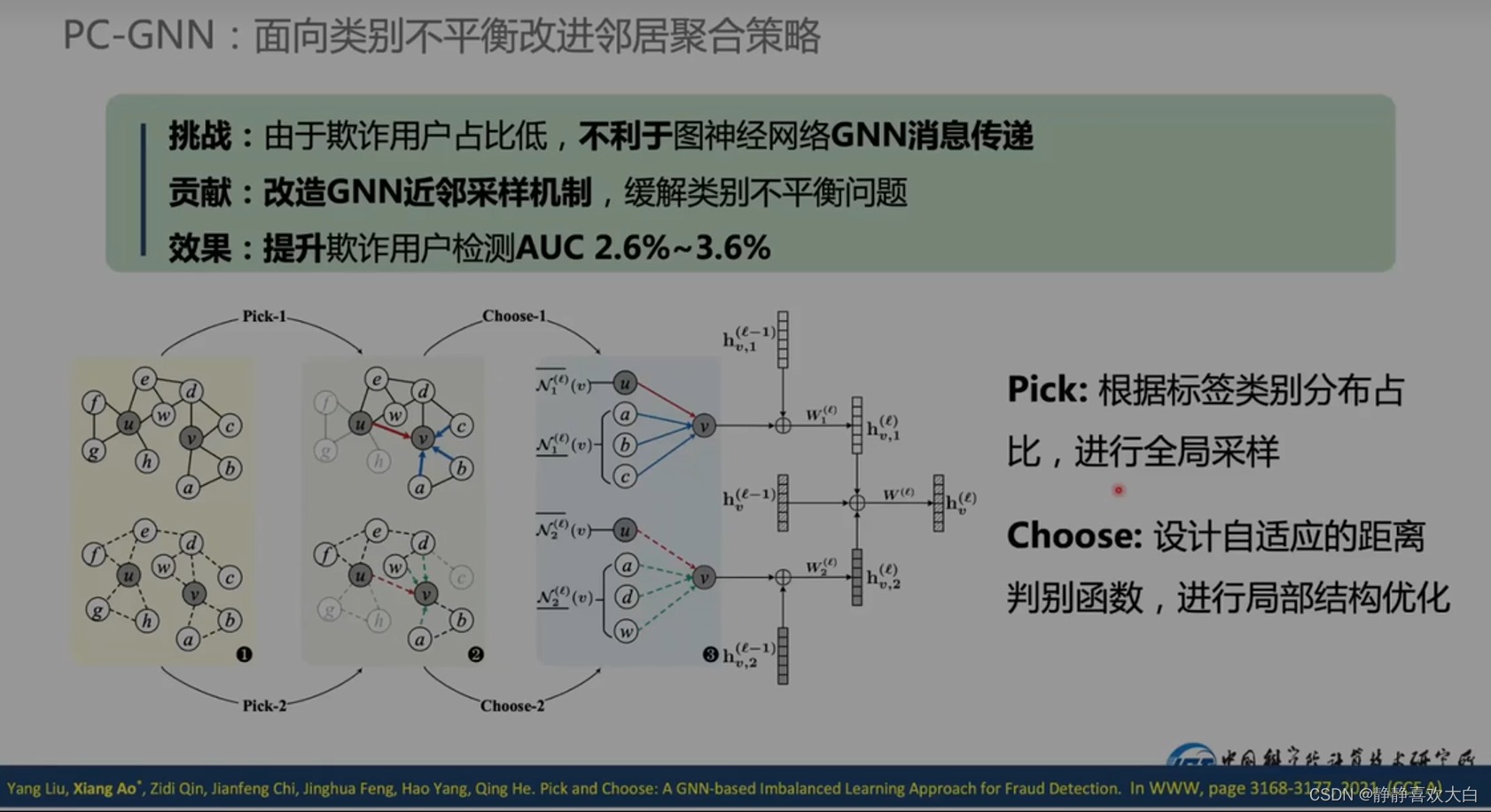

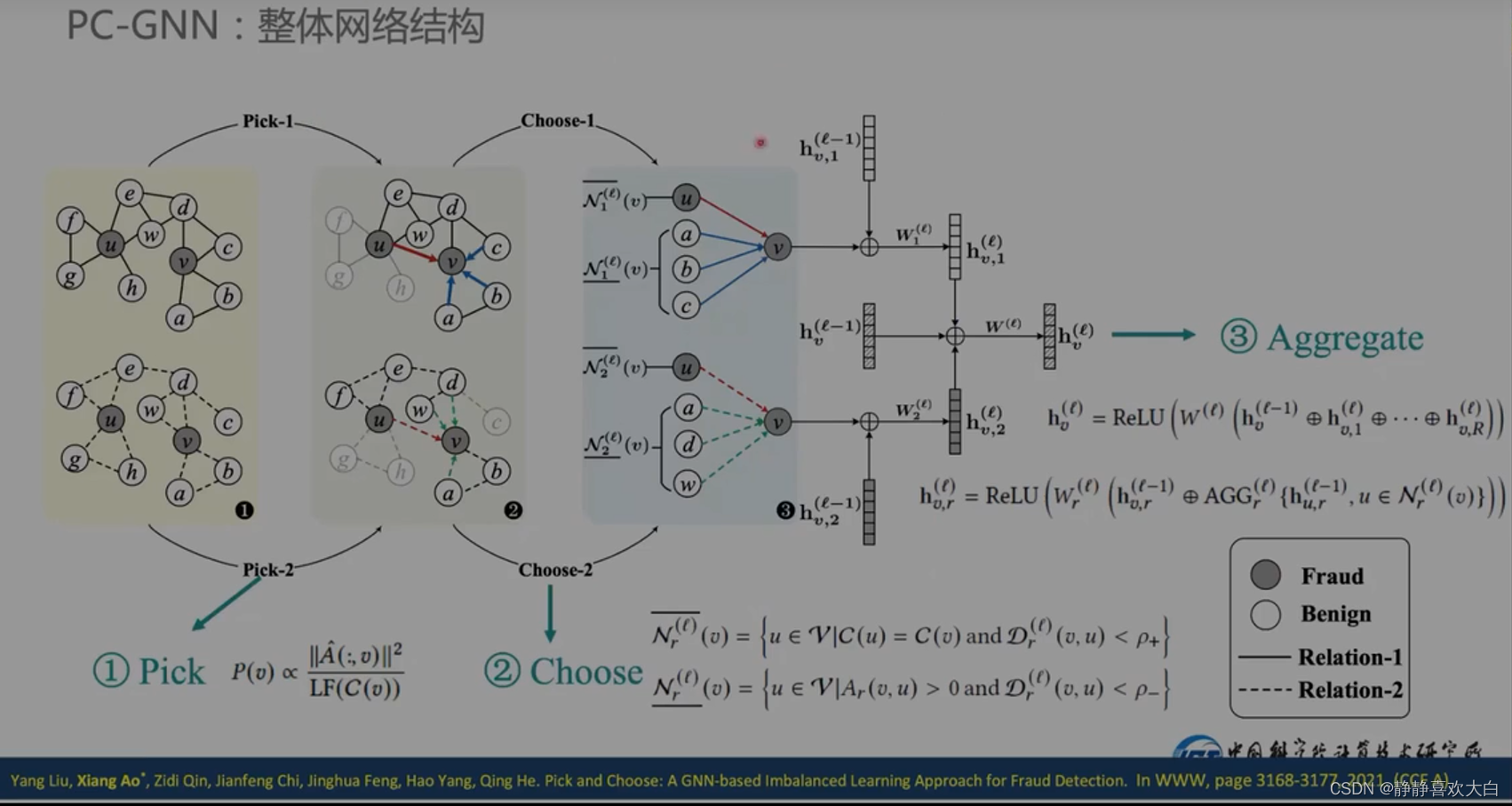
少数类别做过采样+降采样;多数类别值做降采样
框架
其实就是在GNN聚合之前做了采样(集合的扰动)
实验结果

baseline
 真实数据集上提升会多些
真实数据集上提升会多些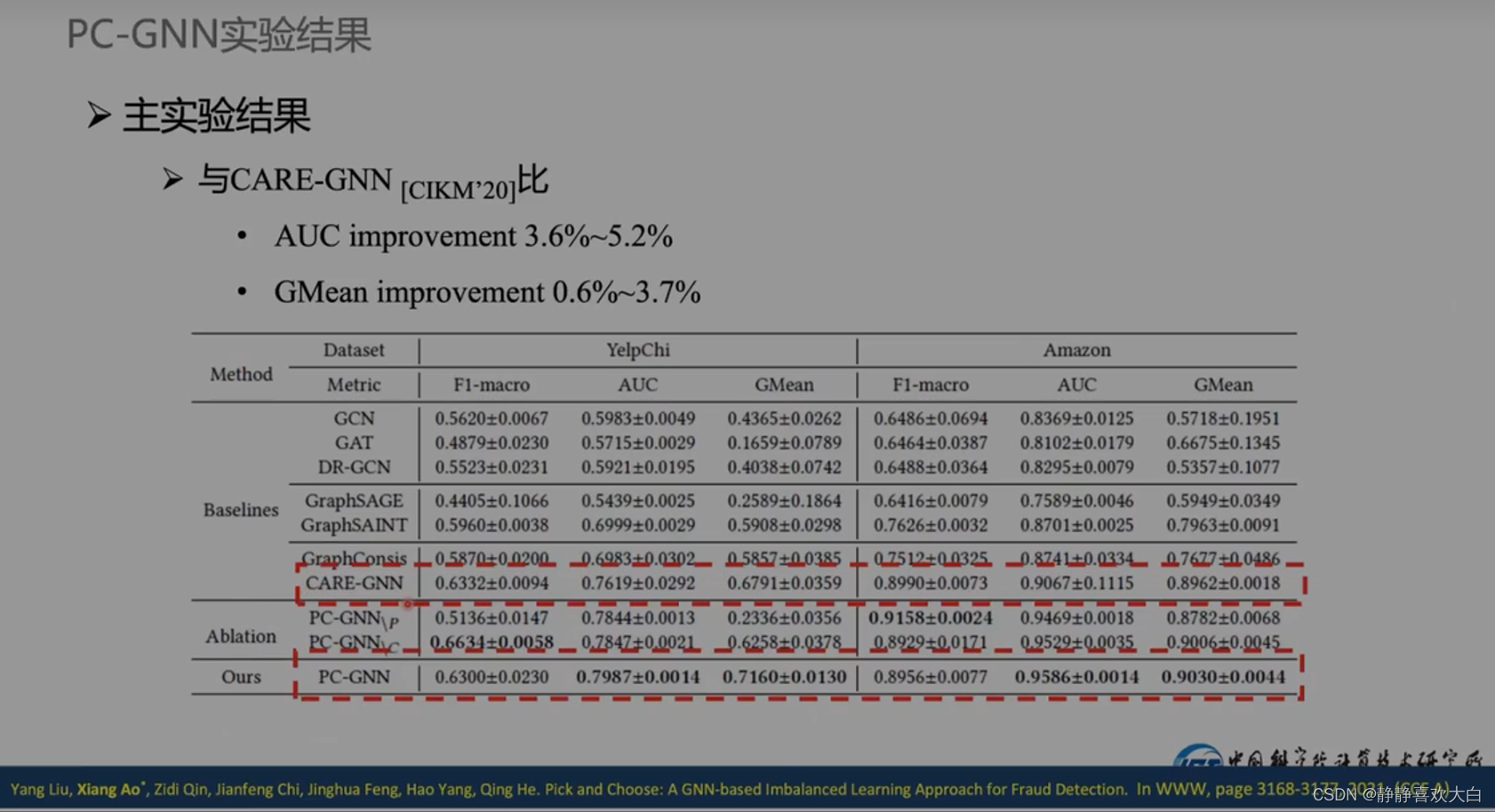
实验分析可以采纳
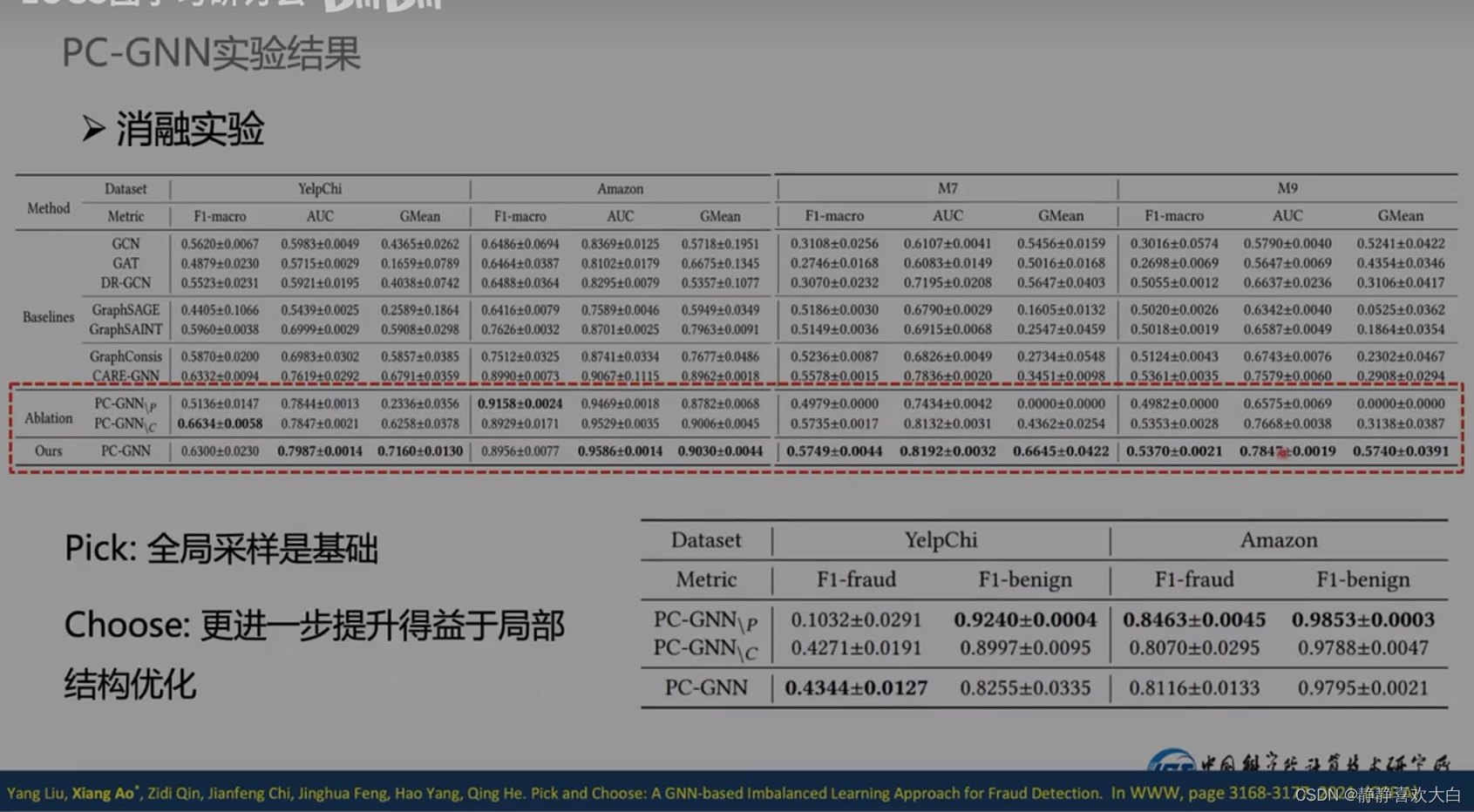
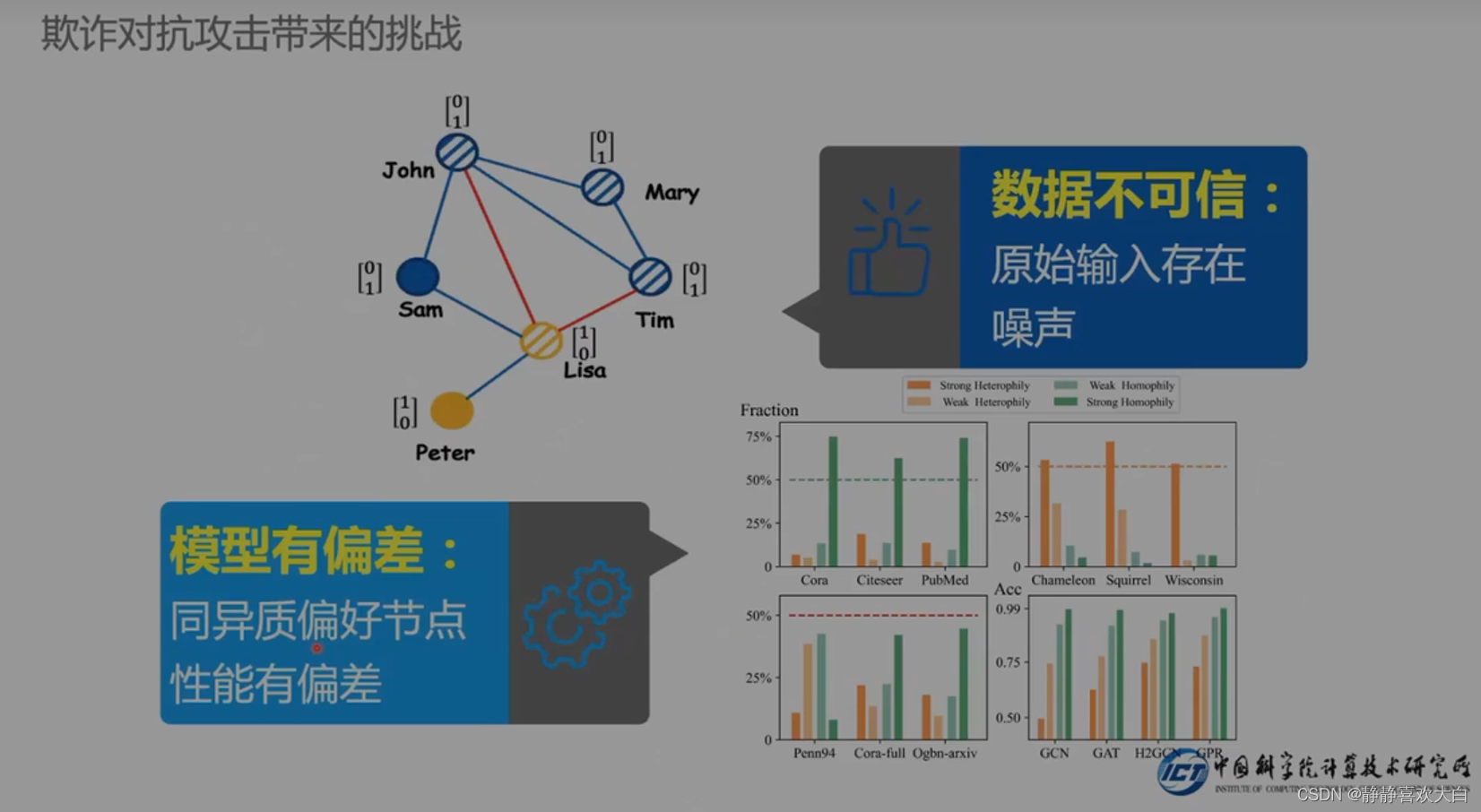
挑战2-标签不可信的解决
所谓的好人可能不是好人,有可能检测错误-误判(也就是白样本能不能用,用多少的问题)
可以采样小规模白样本套模型做(未做报告)
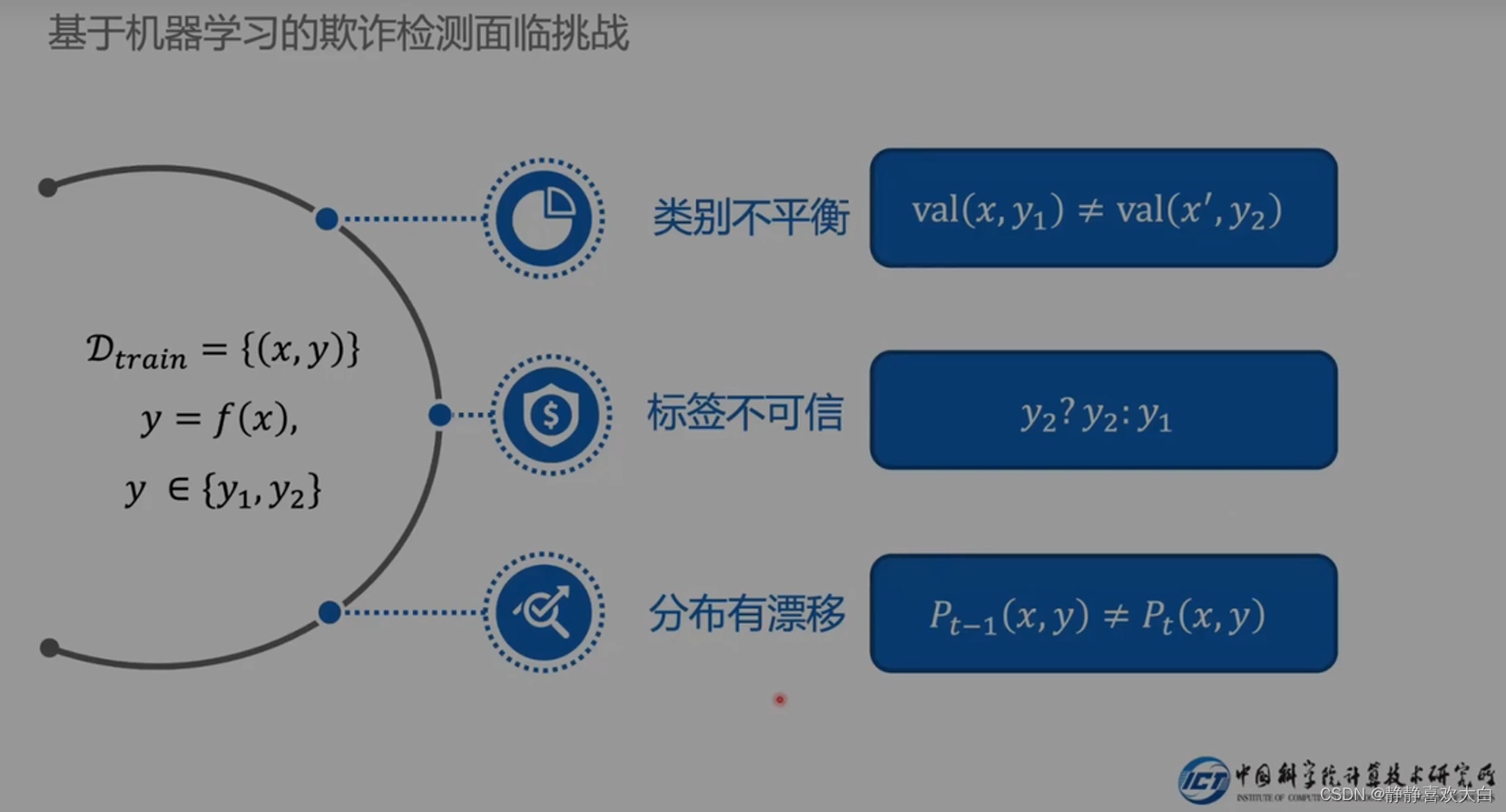
挑战3-分布有漂移的解决
时序图,在图变化过程中,图的分布发生了改变
引出下文做的欺诈对抗攻击
图机器学习应对欺诈对抗攻击

从数据角度出发
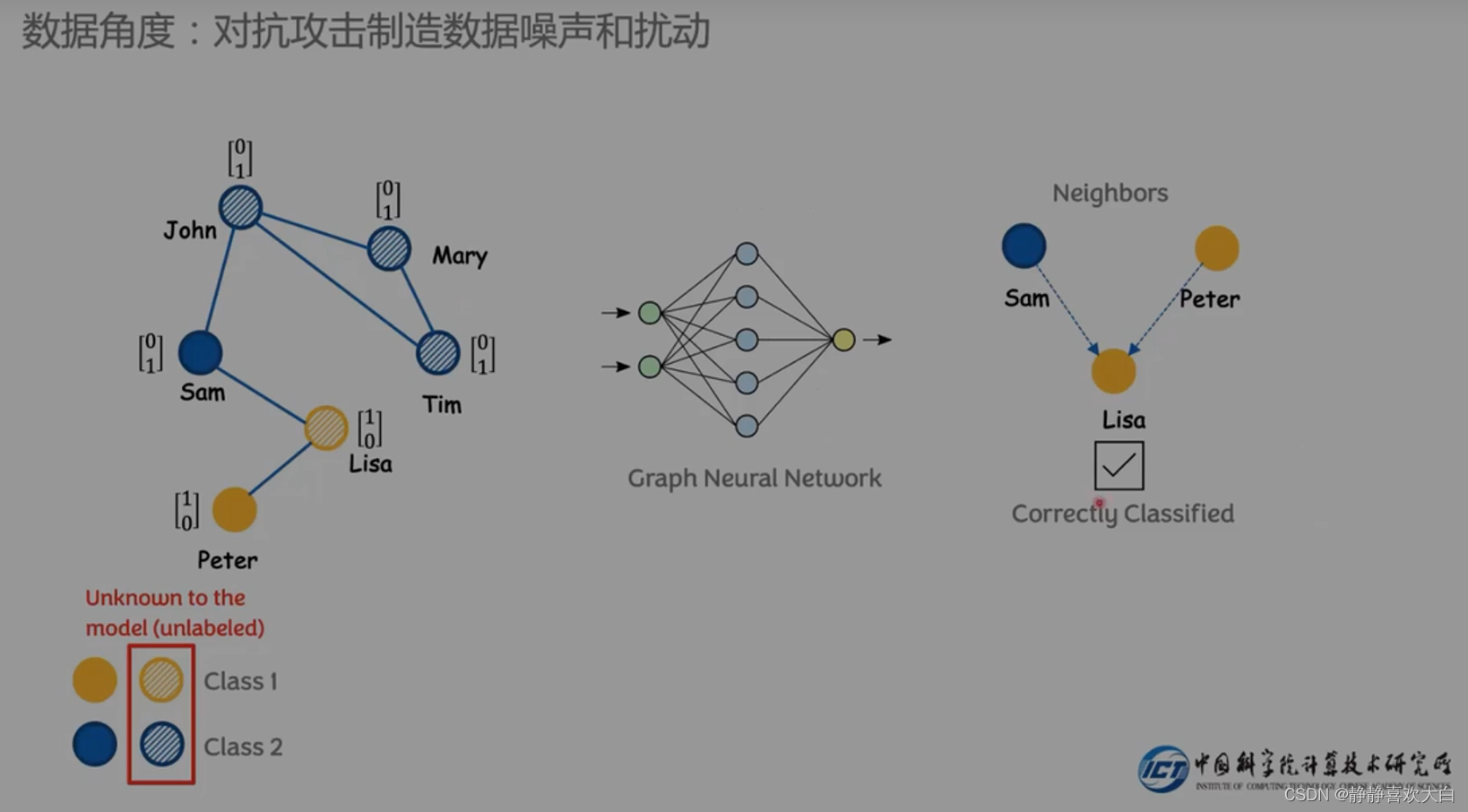
识别攻击恢复图结构
从数据的角度解决,识别噪声则消除该噪声
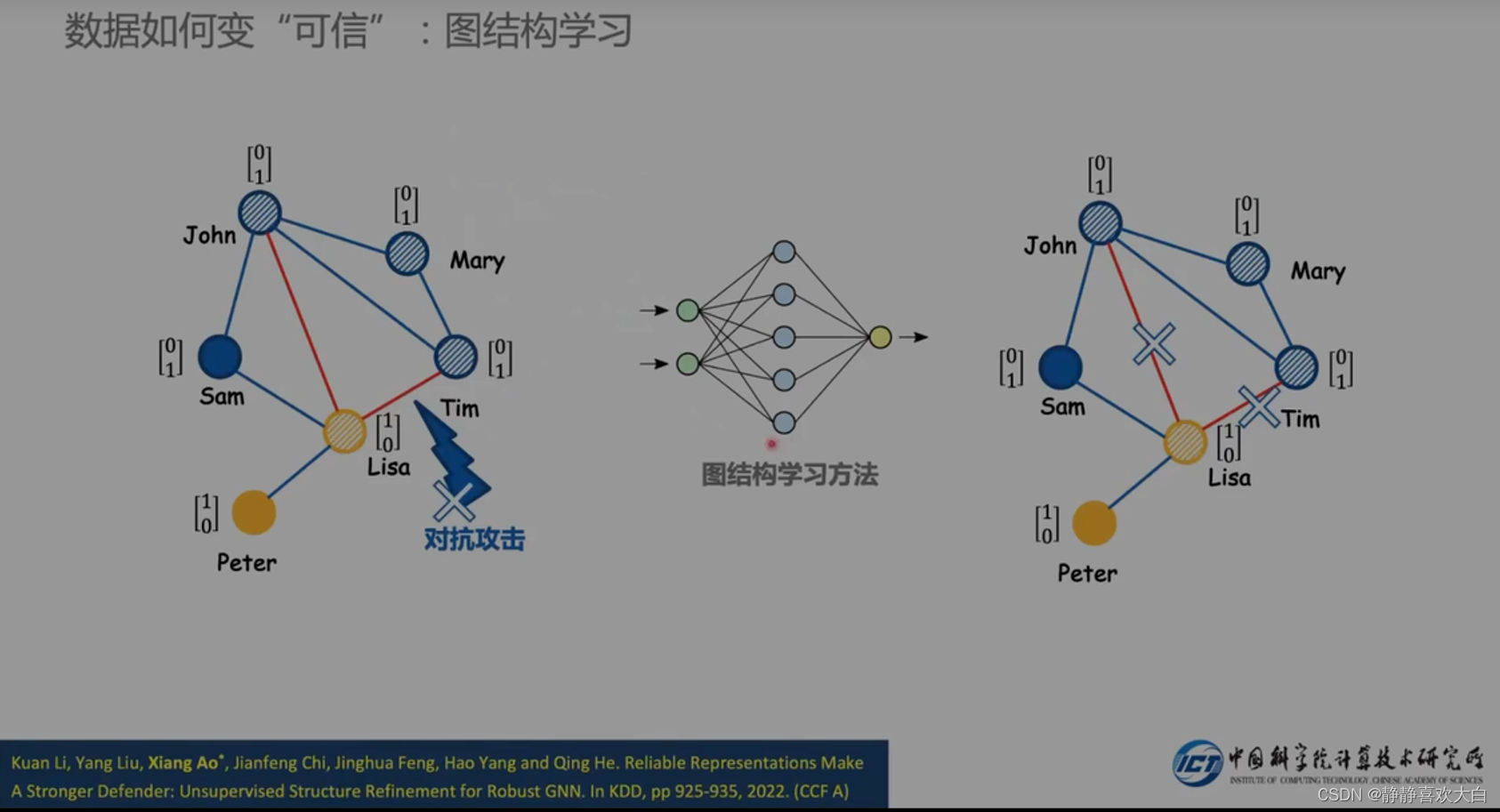
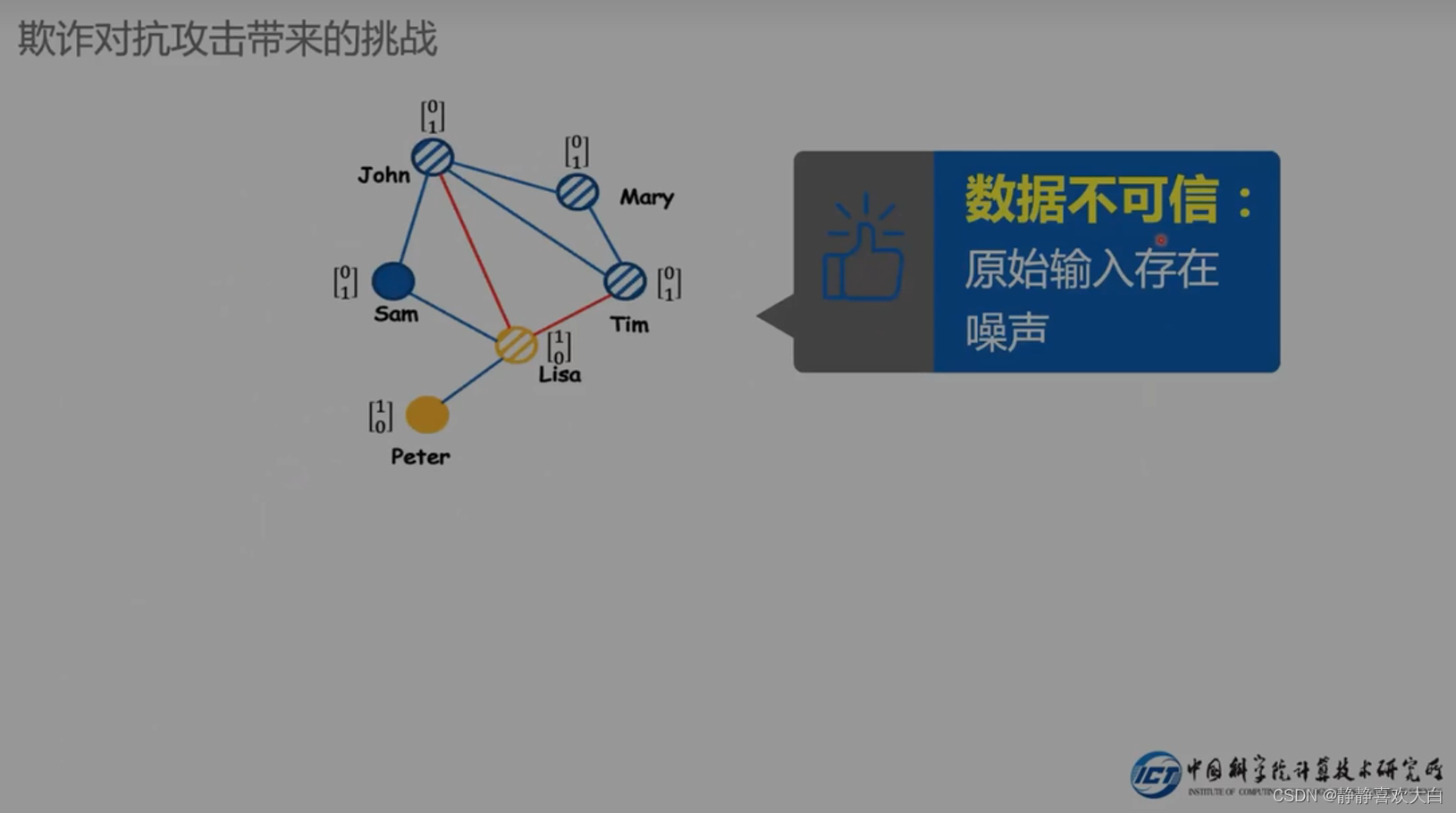
以往方法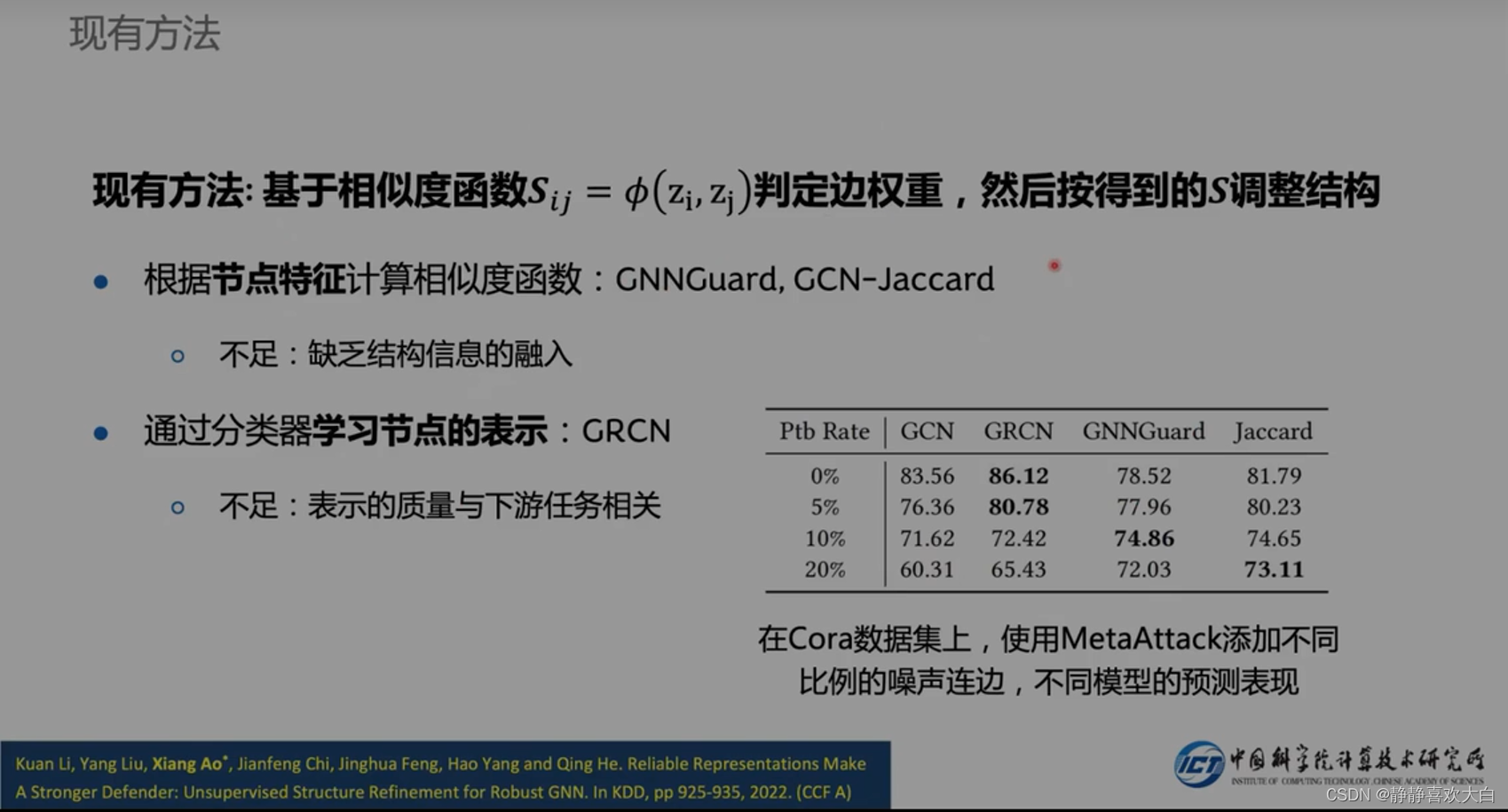
对比学习
在采样上改进

核心关键

图净化
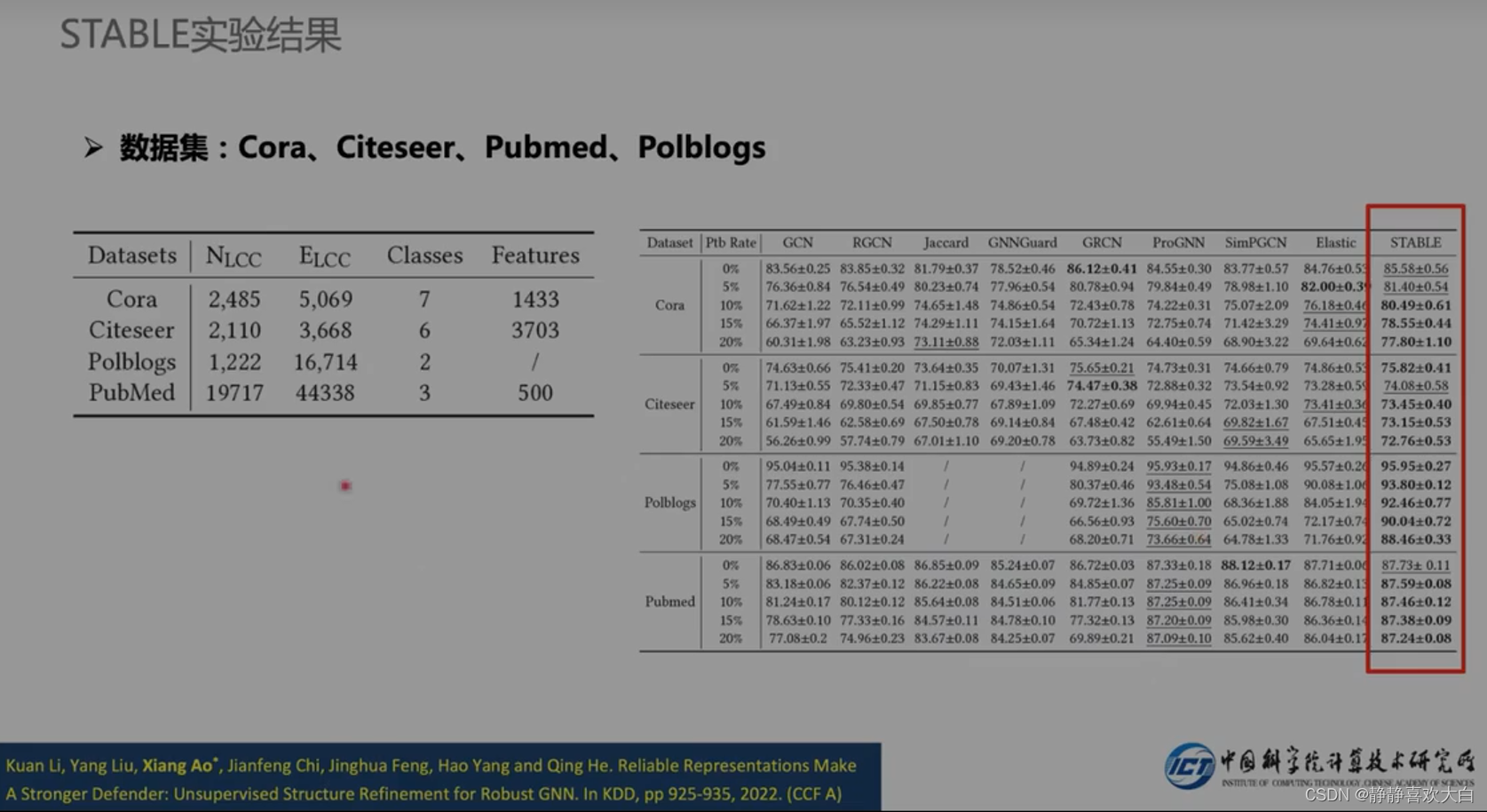
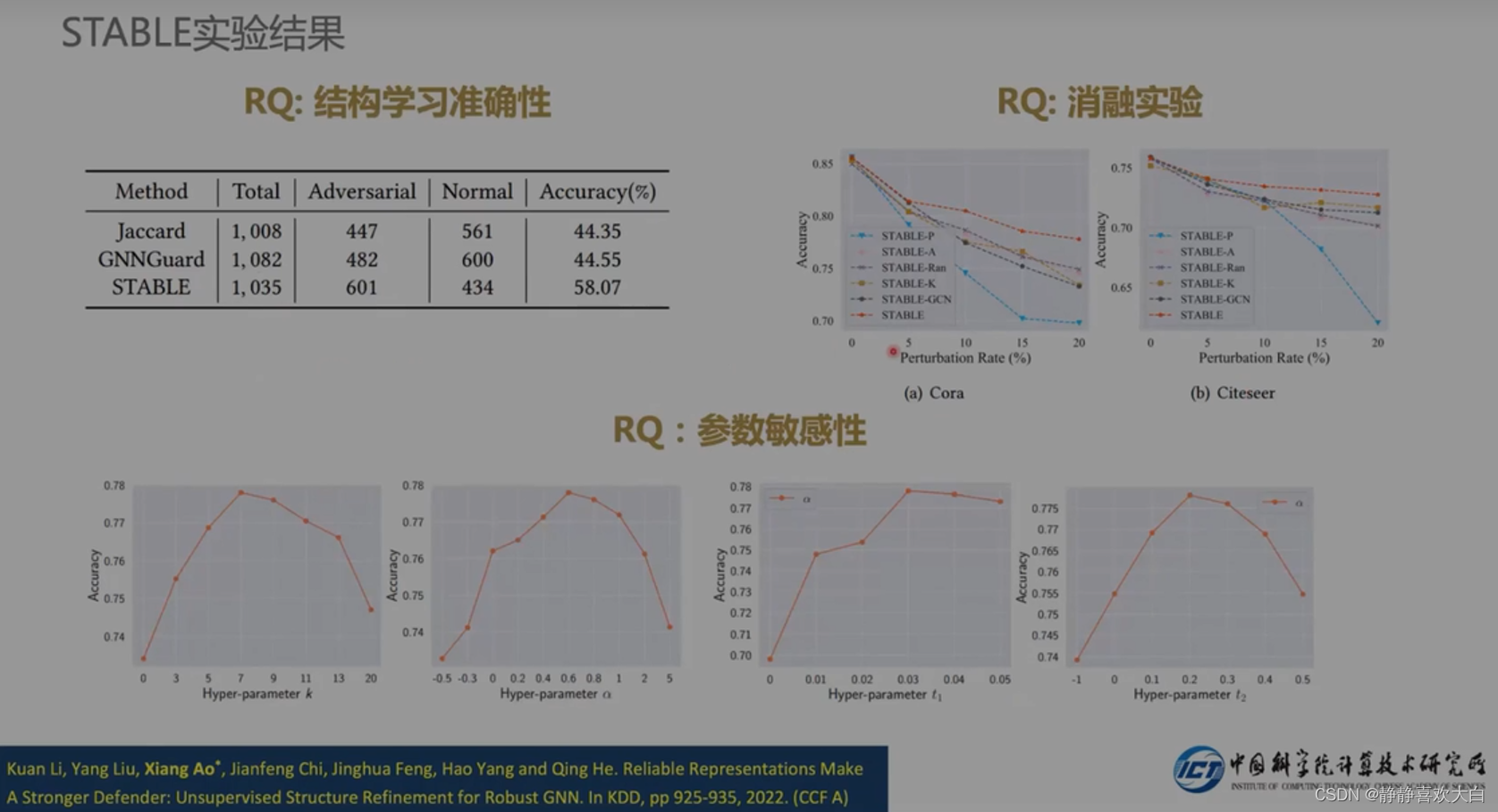
 实验
实验
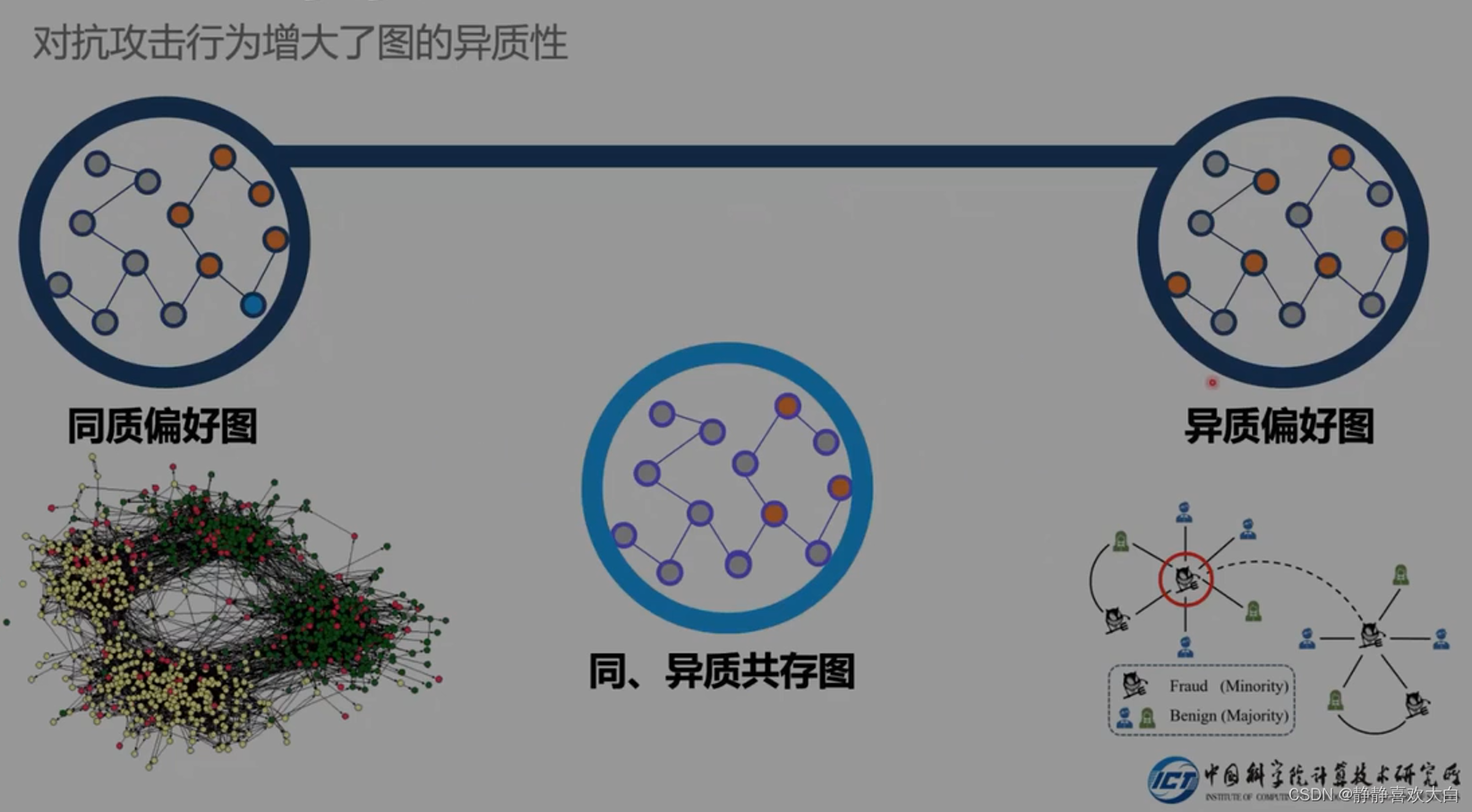
从攻击者角度出发 (倾向于添加异构边)
攻击者提升了自身的异质偏好的概率
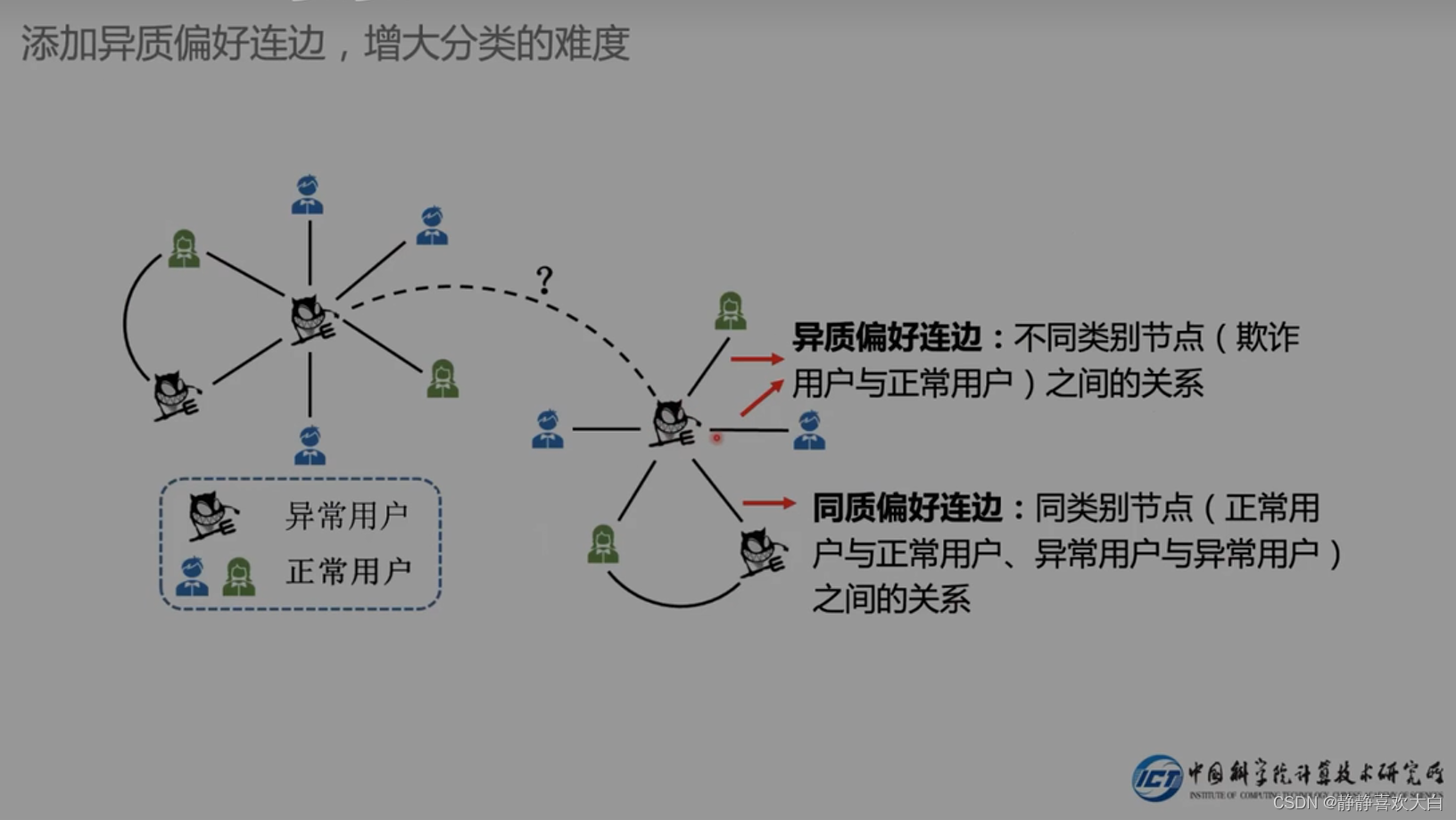


大部分情况下是正常节点,少数异常节点

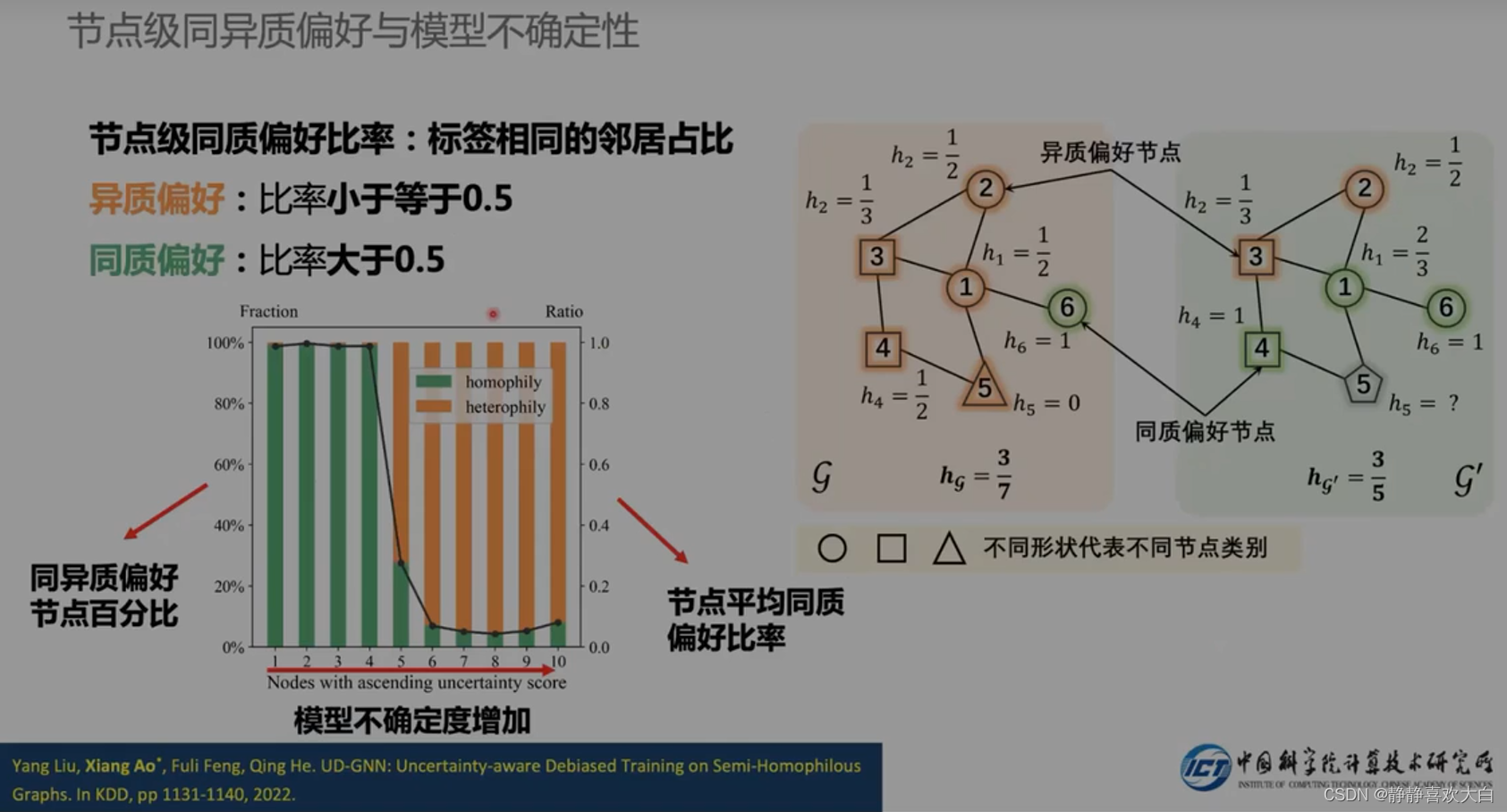
降低偏差,提升异质节点偏好的性能
在模型训练上改进(设置不同seed等)
直接置0(相当于做了mask)

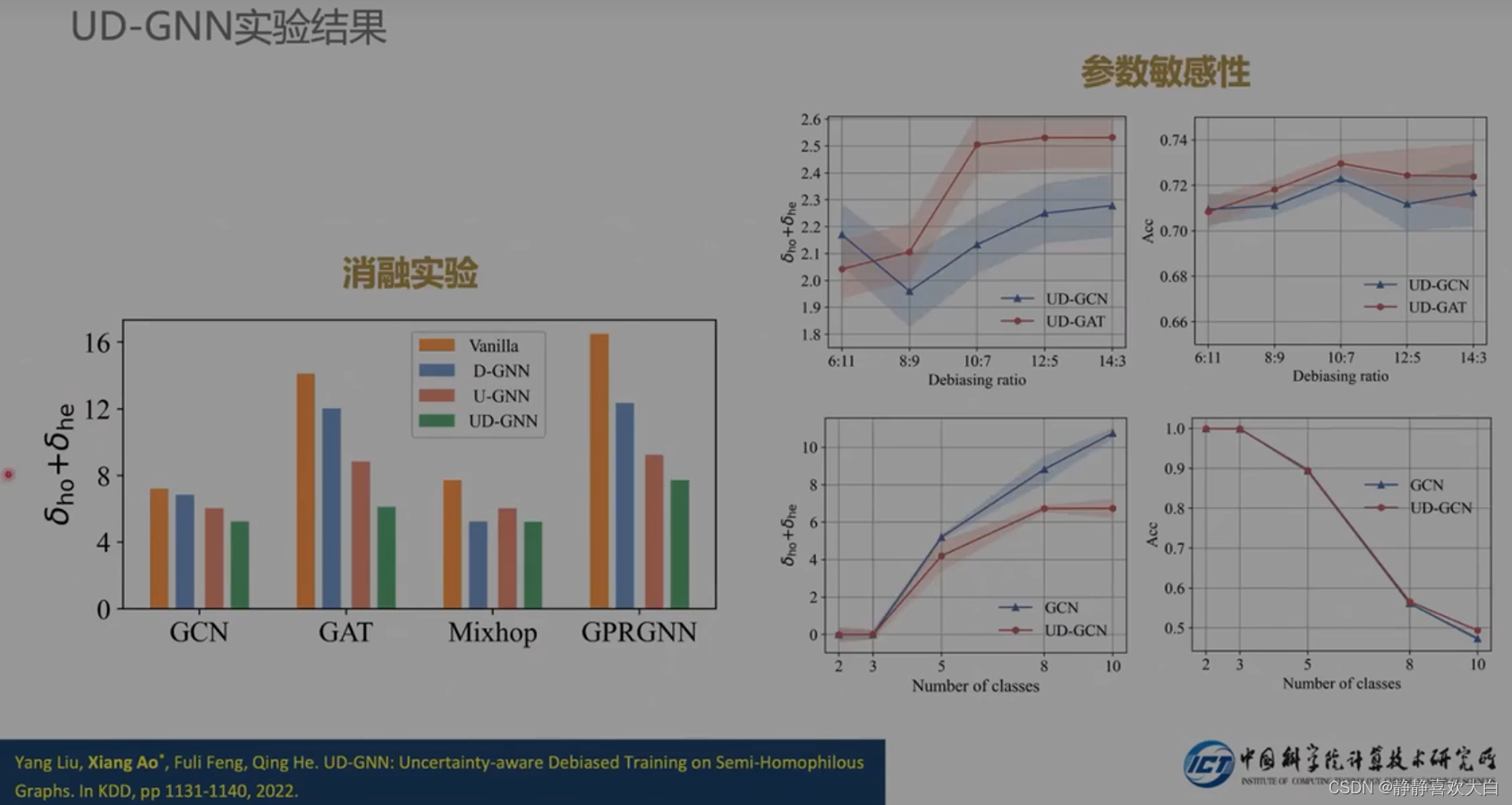
实验结果

总结展望
 数据缺失
数据缺失
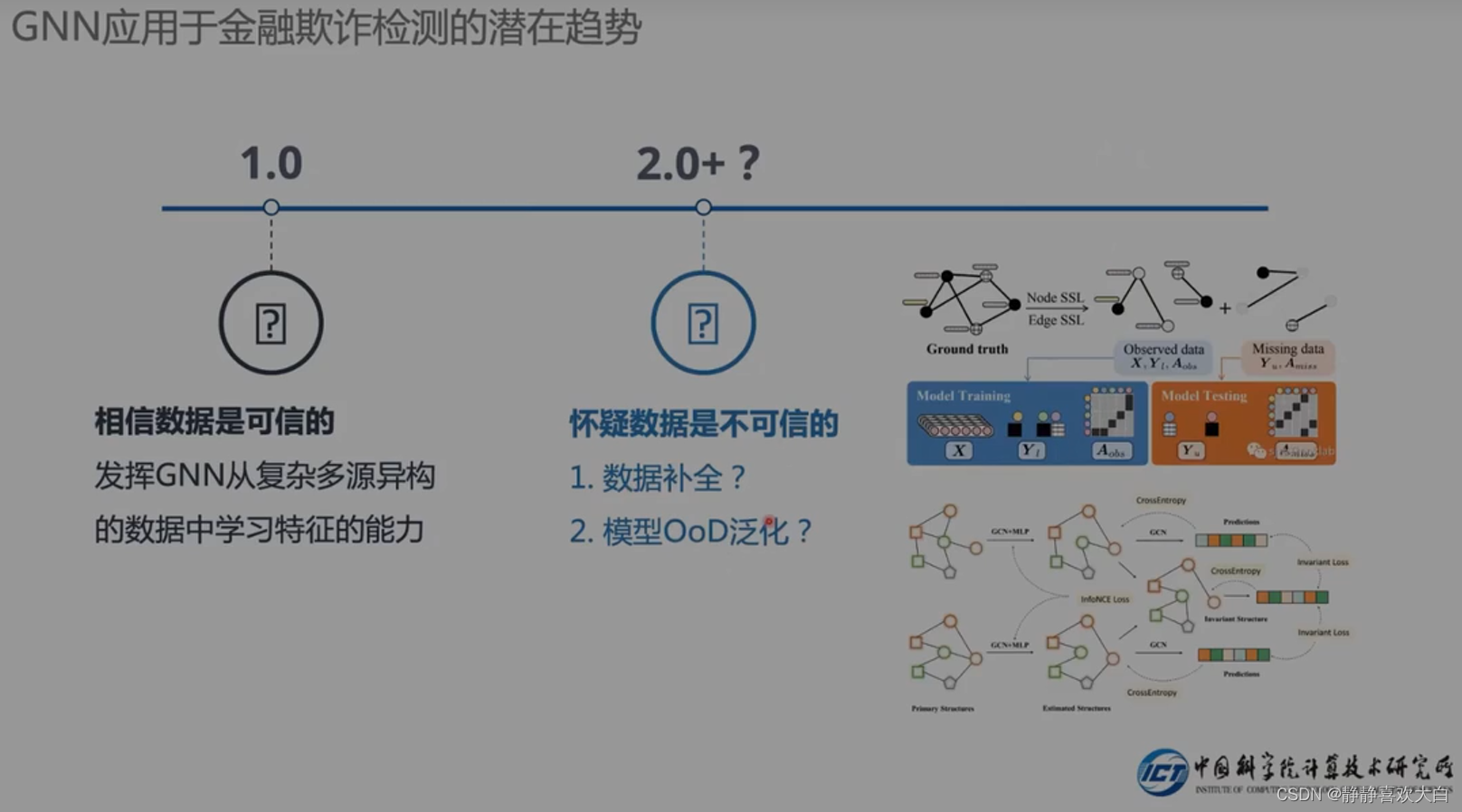 落地上
落地上

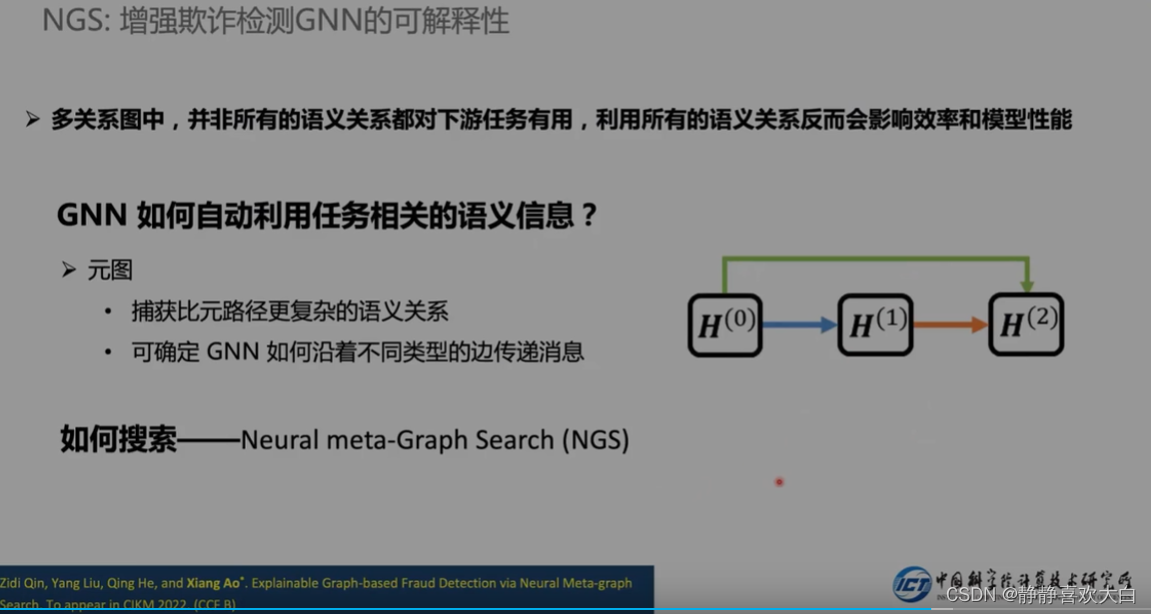
其中在可解释性上有初步研究成果
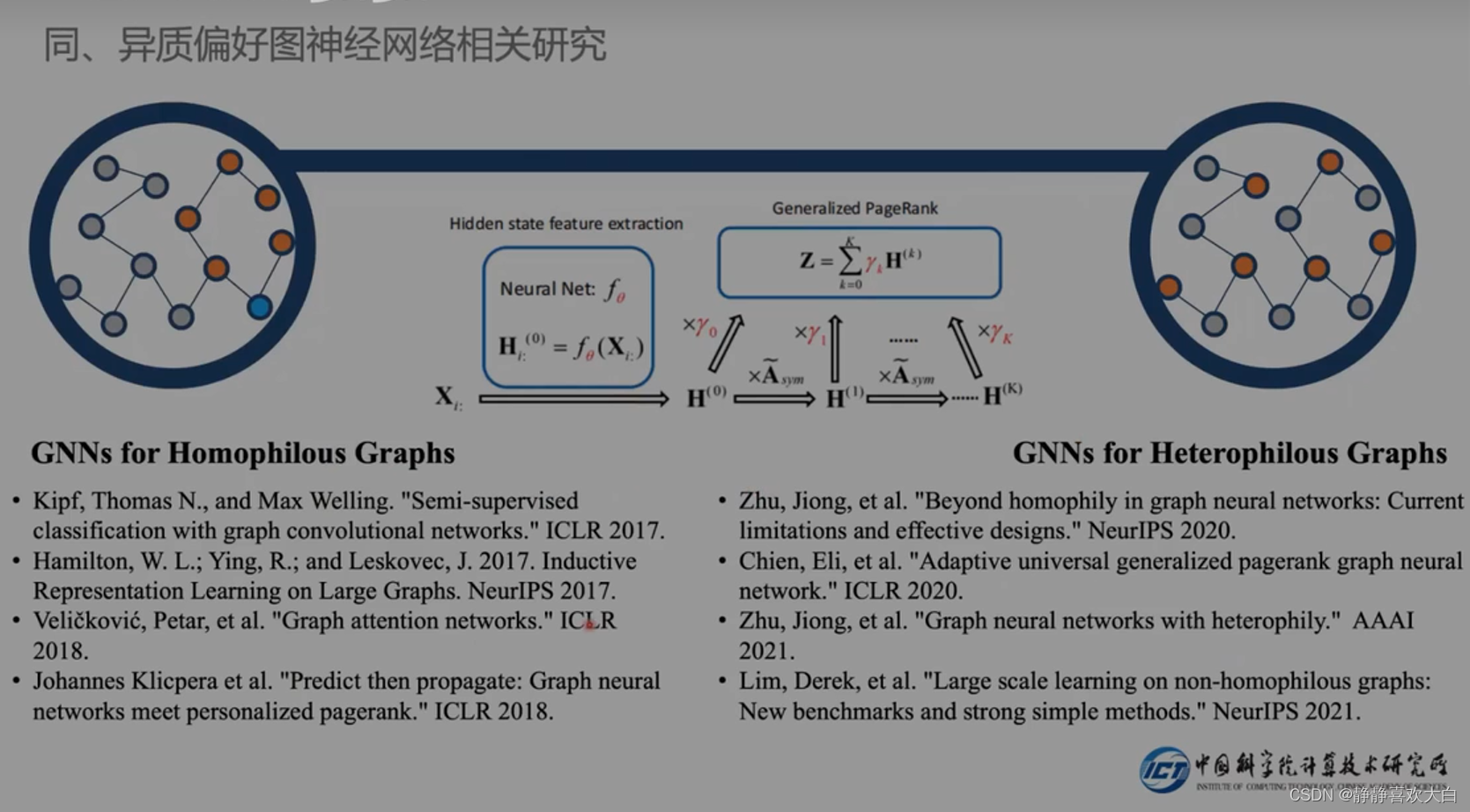
指定边关系传播(使用元图指导消息传递)
定义搜索空间,然后将NAS引入
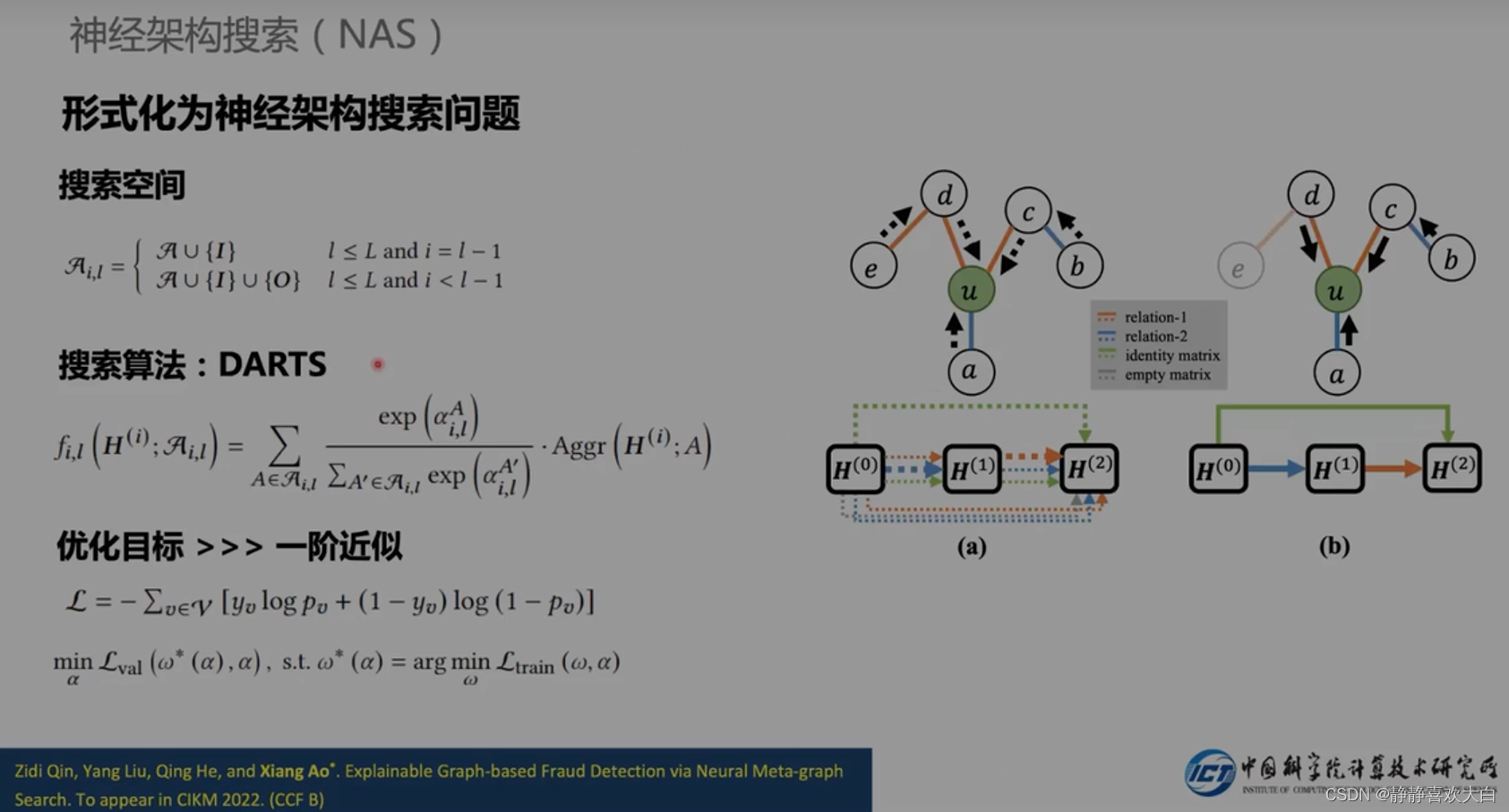
 发现特征传播就足够
发现特征传播就足够
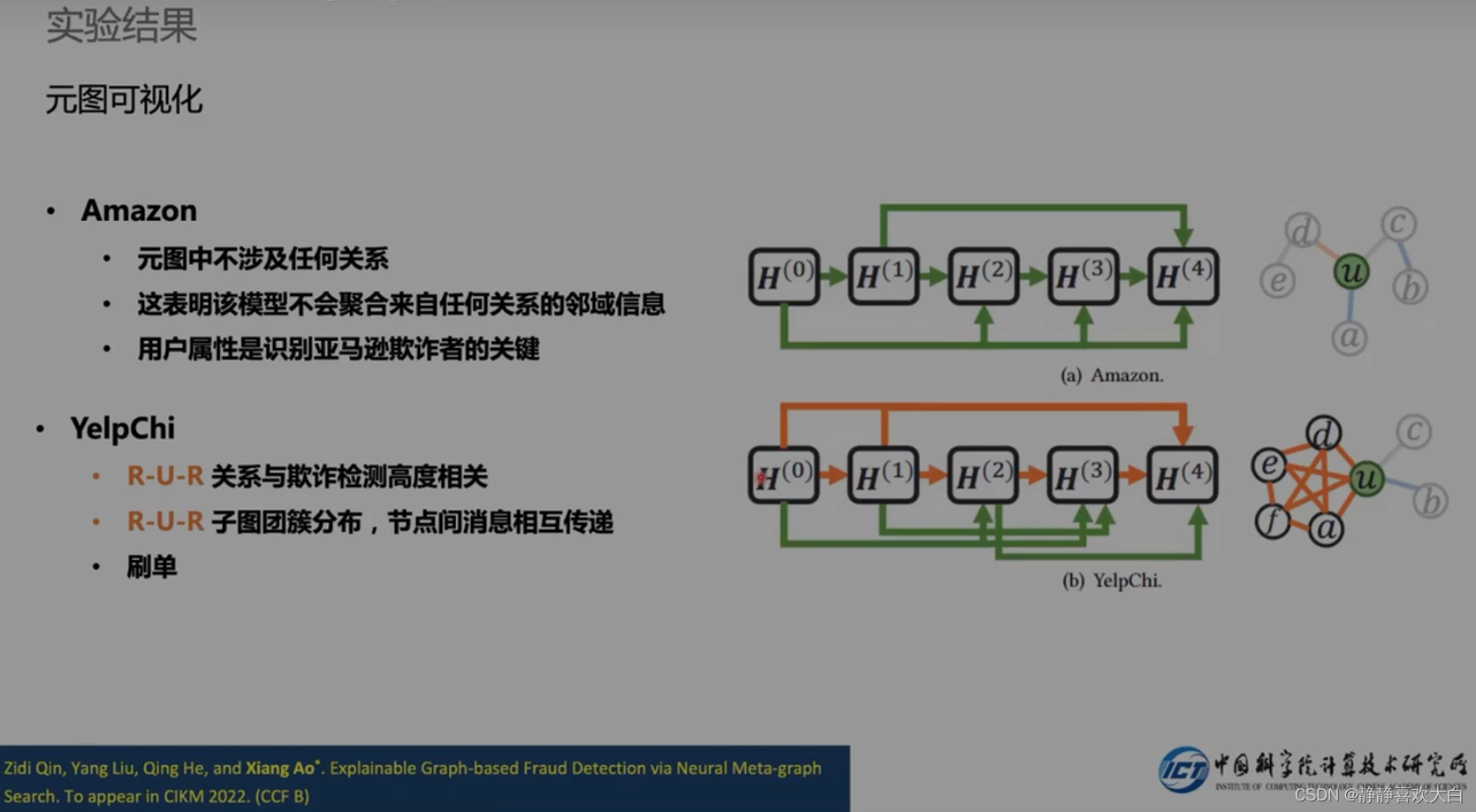


问答
1、异质偏好含义:
一条路径上两端节点label是相反的
2、构造的图稀疏
是的,现实生活中的图也是稀疏的(大规模稀疏图暂时也没什么好的方法,依旧处于探索中)
3、参考
LOGS 第2022/09/04期 ||中科院计算所敖翔:图机器学习应对金融欺诈对抗攻击

