
- 1SQL基础——数据更新_更新产品表的价格使用sql语句
- 2【DevOps】全流程记录:CentOS7安装Gitlab服务器_recipe: gitlab:gitlab-rails
- 3javaee初阶———多线程(三)
- 4ubuntu18.04 下slowfast网络环境安装及模型测试( python3.9)_importerror: cannot import name 'cat_all_gather' f
- 5【测评】互联网校招技术岗&非技术岗测评题型(认知测试,性格测试,心理测试)_技术岗的测评
- 6kafka常用控制台命令集合_kafka-console-consumer.sh 如何看到key
- 7Vscode中css样式书写提示的插件及使用方法_vscode中css提示插件 bc为backgound-color
- 8【Git】git diff提示old mode 100644、new mode 10075_old mode 100644 new mode 100755
- 9Day1-正则表达式在NLP中的基本应用_第1关:正则表达式在 nlp 中的应用
- 10使用 proxySQL 来代理 Mysql
第一篇【传奇开心果系列】Python的pyttsx3库技术点案例示例:文本转换语言_pyttsx3 示例
赞
踩
传奇开心果短博文系列
- 系列短博文目录
- Python的pyttsx3库技术点案例示例系列
- 短博文目录
- 前言
- 一、pyttsx3主要特点和功能介绍
- 二、pyttsx3文字转语音操作步骤介绍
- 三、多平台支持介绍和示例代码
- 四、多语言支持介绍和示例代码
- 五、自定义语言引擎介绍和示例代码
- 六、调整语速和音量介绍和示例代码
- 七、异步支持介绍和示例代码
- 八、事件回调介绍和示例代码
- 九、使用pyttsx3进行文字转语音通常步骤示例代码
- 十、在语音反馈方面应用介绍和示例代码
- 十一、在语音交互界面方面应用介绍和示例代码
- 十二、在语音辅助阅读方面应用介绍和示例代码
- 十三、归纳总结
系列短博文目录
Python的pyttsx3库技术点案例示例系列
短博文目录
前言
 pyttsx3是一个用于将文本转换为语音的Python库。它提供了一种简单而灵活的方式,让开发者可以通过编程将文本转换为可听的语音输出。
pyttsx3是一个用于将文本转换为语音的Python库。它提供了一种简单而灵活的方式,让开发者可以通过编程将文本转换为可听的语音输出。
通过简单的步骤,开发者可以使用pyttsx3快速实现将文本转换为语音的功能,并在各种应用场景中应用,例如语音反馈、语音交互界面、语音辅助阅读等。
一、pyttsx3主要特点和功能介绍

-
多平台支持:pyttsx3可以在多个操作系统上运行,包括Windows、Mac和Linux等。
-
多语言支持:它支持多种语言,包括英语、中文、法语、德语、西班牙语等,可以根据需要选择合适的语言进行语音合成。
-
自定义语音引擎:pyttsx3允许用户选择不同的语音引擎,如SAPI5、nsss、espeak等,以适应不同的需求和平台。
-
调整语速和音量:开发者可以通过设置参数来控制生成语音的速度和音量,以满足个性化的需求。
-
异步支持:pyttsx3支持异步操作,可以在后台生成语音,而不会阻塞主线程的执行。
-
事件回调:它提供了事件回调机制,可以监听语音合成的进度和状态,以便在需要时执行相应的操作。
二、pyttsx3文字转语音操作步骤介绍
 使用pyttsx3进行文字转语音通常包括以下步骤:
使用pyttsx3进行文字转语音通常包括以下步骤:
-
安装pyttsx3库:可以使用pip命令来安装pyttsx3库,例如
pip install pyttsx3。 -
创建语音引擎:使用pyttsx3库创建一个语音引擎对象。
-
设置语言和声音:根据需要设置语言和声音引擎。
-
调整参数:可选地调整语速和音量等参数。
-
将文本转换为语音:使用语音引擎的
say()方法将文本转换为语音。 -
播放语音:使用语音引擎的
runAndWait()方法播放生成的语音。
三、多平台支持介绍和示例代码
 当使用pyttsx3进行文字转语音时,可以在不同操作系统上运行。以下是一个示例代码,展示了在Windows、Mac和Linux上使用pyttsx3的基本用法:
当使用pyttsx3进行文字转语音时,可以在不同操作系统上运行。以下是一个示例代码,展示了在Windows、Mac和Linux上使用pyttsx3的基本用法:
import pyttsx3 # 创建语音引擎对象 engine = pyttsx3.init() # 设置语言和声音 # Windows上的示例 # engine.setProperty('voice', 'com.microsoft.speech.platform.voice.SynthesizerVoice') # Mac上的示例 # engine.setProperty('voice', 'com.apple.speech.synthesis.voice.Alex') # Linux上的示例 # engine.setProperty('voice', 'voice_name') # 调整参数(可选) # engine.setProperty('rate', 150) # 设置语速,值越大语速越快 # engine.setProperty('volume', 0.8) # 设置音量,范围从0.0到1.0 # 将文本转换为语音 text = "Hello, World!" engine.say(text) # 播放语音 engine.runAndWait()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
在上述示例代码中,首先我们导入了pyttsx3库。然后,通过pyttsx3.init()方法创建了一个语音引擎对象engine。
接下来,根据需要设置语言和声音。在Windows上,可以使用engine.setProperty('voice', 'com.microsoft.speech.platform.voice.SynthesizerVoice')来设置语音引擎。在Mac上,可以使用engine.setProperty('voice', 'com.apple.speech.synthesis.voice.Alex')来设置语音引擎。在Linux上,可以根据系统中可用的语音引擎设置相应的值,例如engine.setProperty('voice', 'voice_name')。
如果需要,可以使用engine.setProperty('rate', 150)来调整语速,值越大语速越快。使用engine.setProperty('volume', 0.8)来调整音量,范围从0.0到1.0。
然后,我们将要转换为语音的文本赋值给变量text,并使用engine.say(text)将文本转换为语音。
最后,通过调用engine.runAndWait()方法播放生成的语音。
请注意,示例代码中的语音引擎设置部分需要根据具体操作系统和语音引擎进行相应的调整。你可以根据自己的需求和操作系统来设置合适的语音引擎。
四、多语言支持介绍和示例代码
 当使用pyttsx3进行多语言文字转语音时,可以根据需要选择合适的语言进行语音合成。以下是一个示例代码,展示了如何设置不同语言的语音合成:
当使用pyttsx3进行多语言文字转语音时,可以根据需要选择合适的语言进行语音合成。以下是一个示例代码,展示了如何设置不同语言的语音合成:
import pyttsx3 # 创建语音引擎对象 engine = pyttsx3.init() # 设置语言和声音 # 英语 engine.setProperty('voice', 'en') # 中文 # engine.setProperty('voice', 'zh') # 法语 # engine.setProperty('voice', 'fr') # 德语 # engine.setProperty('voice', 'de') # 西班牙语 # engine.setProperty('voice', 'es') # 将文本转换为语音 text = "Hello, World!" engine.say(text) # 播放语音 engine.runAndWait()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
在上述示例代码中,我们首先导入了pyttsx3库。然后,通过pyttsx3.init()方法创建了一个语音引擎对象engine。
接下来,根据需要设置语言和声音。在示例代码中,我们展示了几种常见语言的设置示例。
- 英语:使用
engine.setProperty('voice', 'en')来设置英语语音引擎。 - 中文:使用
engine.setProperty('voice', 'zh')来设置中文语音引擎。 - 法语:使用
engine.setProperty('voice', 'fr')来设置法语语音引擎。 - 德语:使用
engine.setProperty('voice', 'de')来设置德语语音引擎。 - 西班牙语:使用
engine.setProperty('voice', 'es')来设置西班牙语语音引擎。
你可以根据需要选择合适的语言和语音引擎。
然后,我们将要转换为语音的文本赋值给变量text,并使用engine.say(text)将文本转换为语音。
最后,通过调用engine.runAndWait()方法播放生成的语音。
请注意,示例代码中的语音引擎设置部分需要根据具体的语言和操作系统进行相应的调整。你可以根据自己的需求和操作系统来设置合适的语音引擎和语言。
五、自定义语言引擎介绍和示例代码
 pyttsx3允许用户选择不同的语音引擎来适应不同的需求和平台。以下是一个示例代码,展示了如何选择不同的语音引擎:
pyttsx3允许用户选择不同的语音引擎来适应不同的需求和平台。以下是一个示例代码,展示了如何选择不同的语音引擎:
import pyttsx3 # 创建语音引擎对象 engine = pyttsx3.init() # 设置语音引擎 # Windows上的示例,使用SAPI5引擎 # engine.setProperty('engine', 'sapi5') # Mac上的示例,使用nsss引擎 # engine.setProperty('engine', 'nsss') # Linux上的示例,使用espeak引擎 # engine.setProperty('engine', 'espeak') # 将文本转换为语音 text = "Hello, World!" engine.say(text) # 播放语音 engine.runAndWait()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
在上述示例代码中,我们首先导入了pyttsx3库。然后,通过pyttsx3.init()方法创建了一个语音引擎对象engine。
接下来,根据需要设置语音引擎。在示例代码中,我们展示了在不同平台上选择不同语音引擎的示例。
- 在Windows上,可以使用SAPI5引擎,使用
engine.setProperty('engine', 'sapi5')来设置语音引擎。 - 在Mac上,可以使用nsss引擎,使用
engine.setProperty('engine', 'nsss')来设置语音引擎。 - 在Linux上,可以使用espeak引擎,使用
engine.setProperty('engine', 'espeak')来设置语音引擎。
你可以根据自己的需求和平台选择合适的语音引擎。
然后,我们将要转换为语音的文本赋值给变量text,并使用engine.say(text)将文本转换为语音。
最后,通过调用engine.runAndWait()方法播放生成的语音。
请注意,示例代码中的语音引擎设置部分需要根据具体的平台和语音引擎进行相应的调整。你可以根据自己的需求和平台来设置合适的语音引擎。
六、调整语速和音量介绍和示例代码
 是的,使用pyttsx3,开发者可以通过设置参数来调整生成语音的速度和音量。以下是一个示例代码,展示了如何调整语速和音量:
是的,使用pyttsx3,开发者可以通过设置参数来调整生成语音的速度和音量。以下是一个示例代码,展示了如何调整语速和音量:
import pyttsx3 # 创建语音引擎对象 engine = pyttsx3.init() # 获取当前语音引擎的属性 rate = engine.getProperty('rate') # 获取当前语速 volume = engine.getProperty('volume') # 获取当前音量 # 设置新的语速和音量 new_rate = 150 # 新的语速(默认为100,可以调整为更高或更低的值) new_volume = 0.8 # 新的音量(默认为1,可以调整为0到1之间的值) # 设置语速和音量 engine.setProperty('rate', new_rate) engine.setProperty('volume', new_volume) # 将文本转换为语音 text = "Hello, World!" engine.say(text) # 播放语音 engine.runAndWait()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
在上述示例代码中,我们首先导入了pyttsx3库。然后,通过pyttsx3.init()方法创建了一个语音引擎对象engine。
接下来,我们使用engine.getProperty()方法获取当前语音引擎的属性,包括语速和音量。getProperty('rate')获取当前语速,getProperty('volume')获取当前音量。
然后,我们可以根据需要设置新的语速和音量。在示例代码中,我们将语速设置为150(默认为100),将音量设置为0.8(默认为1)。
通过engine.setProperty()方法,我们将新的语速和音量设置到语音引擎对象中,使用setProperty('rate', new_rate)设置新的语速,使用setProperty('volume', new_volume)设置新的音量。
接下来,我们将要转换为语音的文本赋值给变量text,并使用engine.say(text)将文本转换为语音。
最后,通过调用engine.runAndWait()方法播放生成的语音。
你可以根据需要调整语速和音量的值,以满足个性化的需求。
七、异步支持介绍和示例代码
 目前的pyttsx3库并不直接支持异步操作。pyttsx3库是一个同步库,它会在语音生成完成之前阻塞主线程的执行。
目前的pyttsx3库并不直接支持异步操作。pyttsx3库是一个同步库,它会在语音生成完成之前阻塞主线程的执行。
如果你需要在后台生成语音而不阻塞主线程,你可以考虑使用多线程或异步任务来实现。你可以将语音生成的任务放在一个单独的线程或异步任务中执行,以便在后台进行处理,同时不影响主线程的执行。
以下是一个示例代码,展示了如何使用多线程来在后台生成语音:
import pyttsx3 import threading def generate_speech(text): # 创建语音引擎对象 engine = pyttsx3.init() # 将文本转换为语音 engine.say(text) # 播放语音 engine.runAndWait() # 在主线程中执行其他任务 # 创建一个新的线程来生成语音 text = "Hello, World!" thread = threading.Thread(target=generate_speech, args=(text,)) thread.start() # 主线程继续执行其他任务 # 等待语音生成线程完成 thread.join() # 主线程继续执行其他任务
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
在上述示例代码中,我们首先导入了pyttsx3库和threading模块。然后,我们定义了一个generate_speech函数,用于在新的线程中生成语音。
在generate_speech函数中,我们创建了一个新的语音引擎对象engine,将文本转换为语音,并播放语音。
在主线程中,我们可以执行其他任务。然后,我们创建一个新的线程,将generate_speech函数作为目标函数,传入要转换为语音的文本作为参数。通过thread.start()方法启动线程。
主线程可以继续执行其他任务,而语音生成的任务会在新的线程中后台执行。如果需要等待语音生成线程完成,可以使用thread.join()方法进行等待。
请注意,使用多线程需要注意线程安全和资源管理等问题。确保在使用多线程时正确处理共享资源和线程同步。
另外,如果你更倾向于使用异步操作,你可以考虑使用其他异步库或框架来实现类似的功能,例如使用asyncio库或基于异步的语音合成服务。这些库和服务可以提供异步生成语音的功能,并与其他异步代码一起工作。
八、事件回调介绍和示例代码
 目前的pyttsx3库并不直接提供事件回调机制来监听语音合成的进度和状态。pyttsx3库是一个相对简单的文本到语音转换库,它没有内置的事件回调功能。
目前的pyttsx3库并不直接提供事件回调机制来监听语音合成的进度和状态。pyttsx3库是一个相对简单的文本到语音转换库,它没有内置的事件回调功能。
如果你需要监听语音合成的进度和状态,你可以考虑使用其他更专业的语音合成库或服务,这些库或服务通常提供更丰富的功能和事件回调机制。
一个常见的选择是使用Google Text-to-Speech (gTTS) API,它是一个功能强大的语音合成服务,支持多种语言和声音选项。你可以使用它的Python库来生成语音,并利用其事件回调机制来监听合成进度和状态。
以下是一个使用gTTS库的示例代码,展示了如何使用事件回调来监听语音合成的进度和状态:
from gtts import gTTS import time def on_progress(current, total): print(f"合成进度: {current}/{total}") def on_complete(): print("语音合成完成") # 要转换为语音的文本 text = "Hello, World!" # 创建gTTS对象,设置文本和语言 tts = gTTS(text, lang='en') # 设置事件回调 tts.on_progress(on_progress) tts.on_complete(on_complete) # 保存语音到文件 tts.save('output.mp3') # 等待合成完成 while not tts.done: time.sleep(0.1) # 打印合成的总时长 print(f"合成时长: {tts.total_duration} 秒")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
在上述示例代码中,我们首先导入了gTTS库和time模块。然后,我们定义了两个回调函数:on_progress和on_complete。
on_progress函数在语音合成过程中被调用,它接收两个参数:当前合成的片段数和总片段数。在这个示例中,我们简单地打印当前合成的进度。
on_complete函数在语音合成完成后被调用,它不接收任何参数。在这个示例中,我们简单地打印一条消息表示合成完成。
接下来,我们创建了一个gTTS对象,并设置要转换为语音的文本和语言。
然后,我们使用tts.on_progress方法将on_progress函数设置为合成进度的事件回调,使用tts.on_complete方法将on_complete函数设置为合成完成的事件回调。
接下来,我们通过调用tts.save方法将合成的语音保存到文件。
最后,我们使用一个循环等待语音合成完成,直到tts.done属性为True。在等待期间,我们使用time.sleep方法暂停一小段时间。
请注意,以上示例代码使用的是gTTS库,而不是pyttsx3库。这是因为pyttsx3库并不直接提供事件回调机制。如果你需要事件回调功能,你可能需要使用其他库或服务来实现。
九、使用pyttsx3进行文字转语音通常步骤示例代码
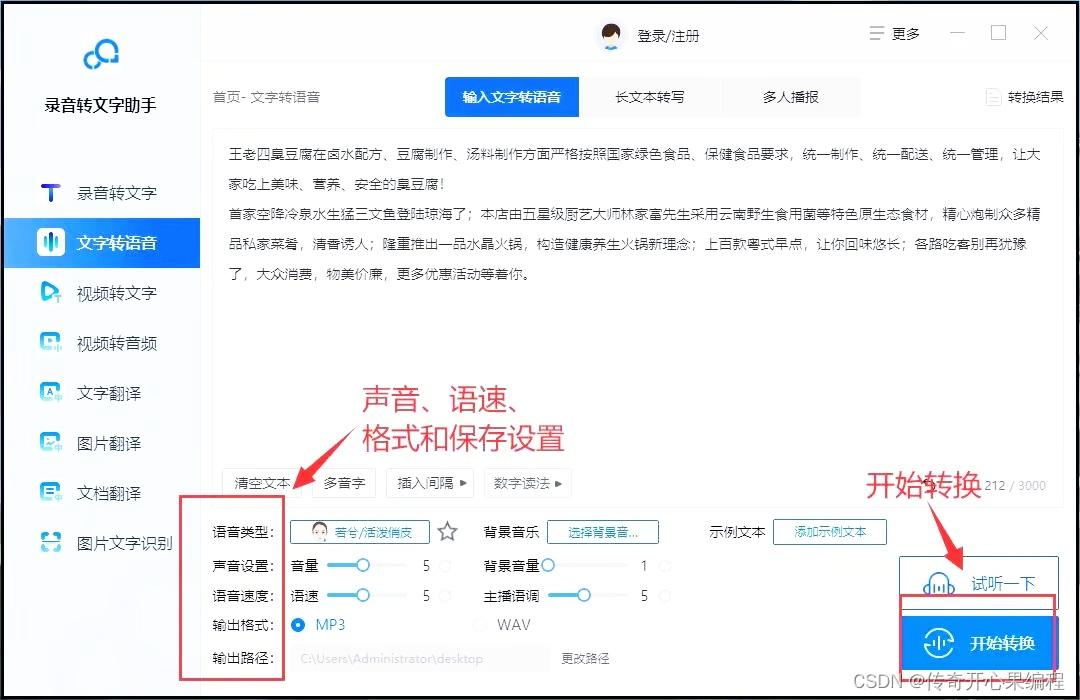 当使用
当使用pyttsx3库进行文字转语音时,通常的步骤如下:
- 安装
pyttsx3库:
pip install pyttsx3
- 1
- 导入
pyttsx3库:
import pyttsx3
- 1
- 创建一个
pyttsx3的引擎对象:
engine = pyttsx3.init()
- 1
- 设置引擎的属性(可选):
# 设置语速(默认为中等速度)
engine.setProperty('rate', 150)
# 设置音量(0.0到1.0之间,默认为1.0)
engine.setProperty('volume', 0.8)
# 设置语音声音(默认为系统默认声音)
voices = engine.getProperty('voices')
engine.setProperty('voice', voices[0].id) # 选择第一个声音
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 使用引擎进行文字转语音:
text = "Hello, World!"
engine.say(text)
- 1
- 2
- 播放语音:
engine.runAndWait()
- 1
完整的示例代码如下:
import pyttsx3 # 创建引擎对象 engine = pyttsx3.init() # 设置引擎属性 engine.setProperty('rate', 150) engine.setProperty('volume', 0.8) voices = engine.getProperty('voices') engine.setProperty('voice', voices[0].id) # 文字转语音 text = "Hello, World!" engine.say(text) # 播放语音 engine.runAndWait()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
以上代码将使用默认设置创建一个pyttsx3引擎对象,将字符串"Hello, World!"转换为语音并播放出来。你可以根据需要调整引擎的属性,例如语速、音量和声音等。
十、在语音反馈方面应用介绍和示例代码

pyttsx3是一个用于文字转语音(TTS)的Python库,它提供了一个简单而强大的接口来生成语音反馈。它支持多种语音引擎,并且可以在不同平台上运行。
使用pyttsx3进行语音反馈的步骤如下:
- 安装
pyttsx3库:
pip install pyttsx3
- 1
- 导入
pyttsx3库:
import pyttsx3
- 1
- 创建一个
pyttsx3的引擎对象:
engine = pyttsx3.init()
- 1
- 设置引擎的属性(可选):
# 设置语速(默认为中等速度)
engine.setProperty('rate', 150)
# 设置音量(0.0到1.0之间,默认为1.0)
engine.setProperty('volume', 0.8)
# 设置语音声音(默认为系统默认声音)
voices = engine.getProperty('voices')
engine.setProperty('voice', voices[0].id) # 选择第一个声音
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 使用引擎进行语音反馈:
text = "Hello, World!"
engine.say(text)
- 1
- 2
- 播放语音:
engine.runAndWait()
- 1
下面是一个完整的示例代码,演示了如何使用pyttsx3进行语音反馈:
import pyttsx3 # 创建引擎对象 engine = pyttsx3.init() # 设置引擎属性 engine.setProperty('rate', 150) engine.setProperty('volume', 0.8) voices = engine.getProperty('voices') engine.setProperty('voice', voices[0].id) # 语音反馈 text = "Hello, World!" engine.say(text) # 播放语音 engine.runAndWait()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
在上述示例中,我们创建了一个pyttsx3引擎对象,并设置了语速、音量和声音等属性。然后,我们使用engine.say()方法将文字转换为语音,并使用engine.runAndWait()方法播放语音。
你可以根据需要调整引擎的属性,选择不同的声音,以及在engine.say()方法中传入不同的文字进行语音反馈。pyttsx3库提供了更多功能和方法来控制语音的生成和播放,你可以查阅官方文档获取更多信息:https://pyttsx3.readthedocs.io
十一、在语音交互界面方面应用介绍和示例代码
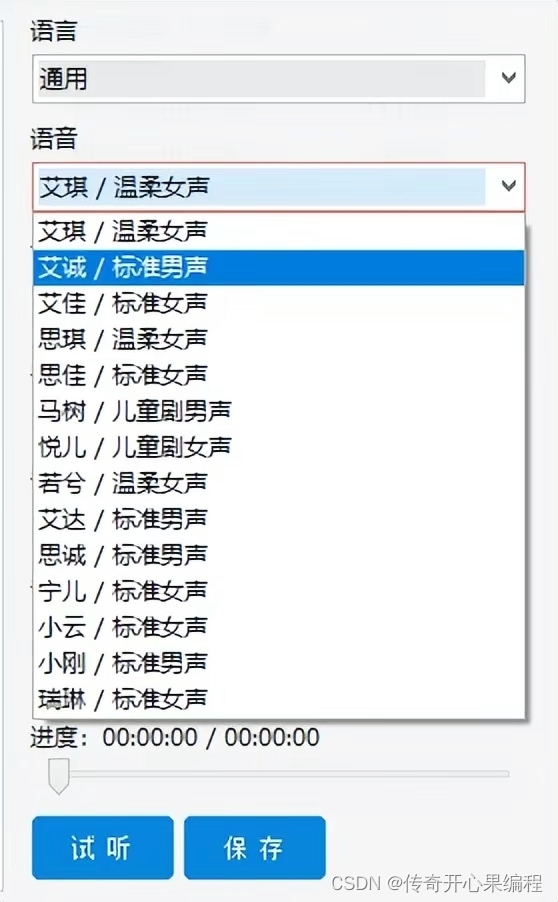
pyttsx3库可以与其他Python库和框架结合使用,创建语音交互界面。通过结合pyttsx3和其他库,你可以实现文字到语音的转换以及语音识别的功能,从而实现语音交互。
下面是一个简单的示例代码,演示了如何使用pyttsx3和SpeechRecognition库创建一个简单的语音交互界面:
import pyttsx3 import speech_recognition as sr # 创建引擎对象 engine = pyttsx3.init() # 设置引擎属性 engine.setProperty('rate', 150) engine.setProperty('volume', 0.8) voices = engine.getProperty('voices') engine.setProperty('voice', voices[0].id) # 创建语音识别器对象 recognizer = sr.Recognizer() # 使用麦克风进行语音输入 with sr.Microphone() as source: print("请说话...") audio = recognizer.listen(source) try: # 将语音转换为文字 text = recognizer.recognize_google(audio, language='zh-CN') print("你说的是:" + text) # 将文字转换为语音 engine.say("你说的是:" + text) engine.runAndWait() except sr.UnknownValueError: print("无法识别语音") except sr.RequestError as e: print("无法连接到语音识别服务:" + str(e))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
在上述示例中,我们使用pyttsx3创建了一个语音引擎对象,并设置了属性。然后,我们使用SpeechRecognition库创建了一个语音识别器对象。通过recognizer.listen(source)方法,我们使用麦克风进行语音输入,并将语音转换为文字。然后,我们使用engine.say()方法将文字转换为语音,并使用engine.runAndWait()方法播放语音。
你可以根据需要扩展这个示例,添加更多的语音交互功能,例如根据语音命令执行特定的操作,或者将语音输入转换为文本并进行进一步的处理。通过结合pyttsx3和其他库,你可以创建出更加复杂和强大的语音交互界面。
十二、在语音辅助阅读方面应用介绍和示例代码

pyttsx3库可以用于语音辅助阅读,将文本内容转换为语音进行朗读。这对于视觉障碍者、学习者或需要多任务处理的人士来说是非常有用的。
下面是一个示例代码,演示了如何使用pyttsx3进行语音辅助阅读:
import pyttsx3 # 创建引擎对象 engine = pyttsx3.init() # 设置引擎属性 engine.setProperty('rate', 150) engine.setProperty('volume', 0.8) voices = engine.getProperty('voices') engine.setProperty('voice', voices[0].id) # 待朗读的文本内容 text = """ 在Python中,可以使用pyttsx3库将文本转换为语音进行朗读。 这对于视觉障碍者、学习者或需要多任务处理的人士来说是非常有用的。 """ # 朗读文本内容 engine.say(text) engine.runAndWait()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
在上述示例中,我们创建了一个pyttsx3引擎对象,并设置了语速、音量和声音等属性。然后,我们定义了待朗读的文本内容,并使用engine.say()方法将文本转换为语音进行朗读。最后,使用engine.runAndWait()方法播放语音。
你可以根据需要调整引擎的属性,选择不同的声音,以及在engine.say()方法中传入不同的文本进行朗读。通过使用pyttsx3库,你可以实现自定义的语音辅助阅读功能,帮助用户更轻松地获取文本信息。
十三、归纳总结
 当使用
当使用pyttsx3库进行文本转语音时,以下是一些重要的知识点:
-
初始化引擎对象:使用
pyttsx3.init()方法初始化一个语音合成引擎对象。 -
设置引擎属性:使用
engine.setProperty()方法可以设置引擎的属性,如语速(rate)、音量(volume)和声音(voice)等。 -
获取可用的声音列表:使用
engine.getProperty('voices')方法可以获取可用的声音列表,然后通过engine.setProperty('voice', voice_id)设置所需的声音。 -
文本转语音:使用
engine.say(text)方法将文本转换为语音。 -
播放语音:使用
engine.runAndWait()方法播放语音,该方法会阻塞程序执行,直到语音播放完毕。 -
异步播放语音:使用
engine.startLoop()方法可以启动异步循环,然后使用engine.iterate()方法在循环中处理语音合成事件。 -
停止语音合成:使用
engine.stop()方法可以停止语音合成过程。 -
支持多种语音引擎:
pyttsx3库支持多种语音引擎,如SAPI5、nsss、espeak等。你可以通过pyttsx3.init(driverName='engine_id')指定要使用的语音引擎。 -
处理异常:在使用
pyttsx3时,可能会遇到各种异常情况,如无法连接到语音引擎、无法识别文本等。你可以使用异常处理机制来捕获和处理这些异常,以确保程序的稳定性。
 以上是使用
以上是使用pyttsx3库进行文本转语音的一些关键知识点。通过熟悉这些知识点,你可以开始使用pyttsx3创建自己的语音应用程序,实现文字到语音的转换和语音辅助功能。

