
- 1【BUG解决】vscode debug python launch.json添加args不起作用_launch.json args
- 2git将某远程分支的某次提交合并到另一远程分支_将远程某一分支合并到另一分支上
- 3华为畅享20为什么没有计算机,华为畅享20 Pro强势来袭:即刻5G,不等待
- 4SSM+mysql+微信小程序李宁线上商城系统-计算机毕业设计源码48327_李宁 微信小程序
- 5线性代数总复习_矩阵带宽
- 6Swift 中的并发:Continuations_swift #selector support concurrency
- 7setting apk android,关于 appium 在安卓上频繁安装 unlock、setting.apk 的问题查找记录...
- 8【linux下的neo4j安装】_linux 安装neo4j
- 9软件工程毕设 基于java web的固定资产管理系统【源码 + 论文】_java企业资产管理系统源码
- 10CMake Error at /usr/local/share/cmake-3.22/Modules/FindPackageHandleStandardArgs.cmake:230 (message)_cmake error at /usr/share/cmake-3.22/modules/findp
hadoop集群环境搭建_hadoop集群搭建
赞
踩
hadoop运行模式有三种,本地模式、 伪分布式模式以及完全分布式模式
搭建本地运行模式测试
实验所用环境为云虚拟机4g内存,40g存储
创建虚拟机,配置子网和网关,确保虚拟机联网
卸载本地jdk并上传压缩包到/home/xxxx/software,安装jdk1.8和hadoop3.1.3
tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/
tar -zxvf jdk-8u212-linux-x64.tar.gz -C /opt/module/
- 1
- 2
通过/etc/profile.d配置环境变量,/etc/profile.d 下的脚本能自动执行,是因为在/etc/profile 中有一个for循环语句来调用这些脚本,关于bashrc与profile的区别
sudo vim /etc/profile.d/my_env.sh
source /etc/profile
- 1
- 2
my_env.sh文件中的配置
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_212
export PATH=$PATH:$JAVA_HOME/bin
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
hadoop的目录结构
hadoop100$ll
total 176
drwxr-xr-x 2 your-username your-username 183 Sep 12 2019 bin
drwxr-xr-x 3 your-username your-username 20 Sep 12 2019 etc
drwxr-xr-x 2 your-username your-username 106 Sep 12 2019 include
drwxr-xr-x 3 your-username your-username 20 Sep 12 2019 lib
drwxr-xr-x 4 your-username your-username 288 Sep 12 2019 libexec
-rw-rw-r-- 1 your-username your-username 147145 Sep 4 2019 LICENSE.txt
-rw-rw-r-- 1 your-username your-username 21867 Sep 4 2019 NOTICE.txt
-rw-rw-r-- 1 your-username your-username 1366 Sep 4 2019 README.txt
drwxr-xr-x 3 your-username your-username 4096 Sep 12 2019 sbin
drwxr-xr-x 4 your-username your-username 31 Sep 12 2019 share
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- bin 目录:存放对 Hadoop 相关服务(hdfs, yarn, mapred)进行操作的脚本
- etc 目录: Hadoop 的配置文件目录,存放 Hadoop 的配置文件
- lib 目录:存放 Hadoop 的本地库(对数据进行压缩解压缩功能)
- sbin 目录:存放启动或停止 Hadoop 相关服务的脚本
- share 目录:存放 Hadoop 的依赖 jar 包、 文档、 和官方案例
运行示例脚本进行测试
mkdir wcinput
cd wcinput
vim word.txt
hadoop yarn
hadoop mapreduce
hadoop java
jdk
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount wcinput wcoutput
cat wcoutput/part-r-00000
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
分布式运行模式环境搭建
3台虚拟机,安装jdk和hadoop,配合环境变量,配置集群
在同一个子网中启动hadoop26,hadoop28,hadoop100,设定ip地址分别为10.0.3.26,10.0.3.58,10.0.3.100,修改hostname和hosts文件(这里忘记手动指定实例的内网地址了)
10.0.3.26 hadoop26
10.0.3.58 hadoop58
10.0.3.100 hadoop100
- 1
- 2
- 3
由于使用ec2实例,用户不需要进行过多配置,利用上面本地创建的hadoop100实例创建ami,并以此为模板启动另外两台实例即可
利用scp进行服务器之间的数据拷贝。rsync 主要用于备份和镜像。具有速度快、避免复制相同内容和支持符号链接的优点 。rsync 只对差异文件做更新(方便更新配置),scp 是把所有文件都复制过去 http://c.biancheng.net/view/6121.html
编写xsync 集群分发脚本
scp -r $pdir/$fname $user@$host:$pdir/$fname 命令 递归 要拷贝的文件路径/名称 目的地用户@主机:目的地路径/名称 rsync -av $pdir/$fname $user@$host:$pdir/$fname 命令 选项参数 要拷贝的文件路径/名称 目的地用户@主机:目的地路径/名称 #分发脚本 #!/bin/bash if [ $# -lt 1 ] then echo Not Enough Arguement! exit; fi for host in hadoop26 hadoop58 hadoop100 do echo ==================== $host ==================== for file in $@ do if [ -e $file ] then #dirname和basename为取路径命令 pdir=$(cd -P $(dirname $file); pwd) fname=$(basename $file) ssh $host "mkdir -p $pdir" rsync -av $pdir/$fname your-username@$host:$pdir else echo $file does not exists! fi done done chmod +x xsync #复制到$PATH下 sudo cp xsync /bin/ #测试 sudo ./bin/xsync test

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
配置无密登录
由于ec2采用密钥登录,创建实例时已经配置过密钥,所以只需要将该私钥上传到实例的.ssh目录下并改名为rsa_id私钥即可相互免密
注意修改密钥权限,chmod 400 xxxx
在本地虚拟机需要通过ssh-keygen生成密钥,并通过ssh-copy-id将公钥上传到目标主机
集群规划
注意事项:
-
NameNode 和 SecondaryNameNode 不要安装在同一台服务器
-
ResourceManager 也很消耗内存,不要和 NameNode、 SecondaryNameNode 配置在同一台机器上
| hadoop26 | hadoop58 | hadoop100 | |
|---|---|---|---|
| HDFS | NameNode DataNode | DataNode | SecondaryNameNode DataNode |
| YARN | NodeManager | ResourceManager NodeManager | NodeManager |
配置文件
Hadoop 配置文件分两类:默认配置文件和自定义配置文件,只有用户想修改某一默认配置值时,才需要修改自定义配置文件,更改相应属性值
默认配置文件存放在 Hadoop 的 jar 包中,自定义配置文件core-site.xml、 hdfs-site.xml、 yarn-site.xml、 mapred-site.xml 四个配置文件存放在$HADOOP_HOME/etc/hadoop 路径上, 用户可以根据项目需求重新进行修改配置
配置hadoop26
核心配置文件core-site.xml
<configuration> <!-- 指定 NameNode 的地址 --> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop28:8020</value> </property> <!-- 指定 hadoop 数据的存储目录 --> <property> <name>hadoop.tmp.dir</name> <value>/opt/module/hadoop-3.1.3/data</value> </property> <!-- 配置 HDFS 网页登录使用的静态用户 --> <property> <name>hadoop.http.staticuser.user</name> <value>your-username</value> </property> </configuration>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
HDFS配置文件hdfs-site.xml
<configuration>
<!-- nn web 端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop26:9870</value>
</property>
<!-- 2nn web 端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop100:9868</value>
</property>
</configuration>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
YARN配置文件yarn-site.xml
<configuration> <!-- 指定 MR 走 shuffle --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- 指定 ResourceManager 的地址--> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop58</value> </property> <!-- 环境变量的继承 --> <property> <name>yarn.nodemanager.env-whitelist</name> <value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value> </property> </configuration>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
MapReduce配置文件mapred-site.xml
<configuration>
<!-- 指定 MapReduce 程序运行在 Yarn 上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
分发配置文件
#hadoop26 xsync /opt/module/hadoop-3.1.3/etc/hadoop/ //运行结果: hadoop26$ /opt/module/hadoop-3.1.3/etc/hadoop# xsync /opt/module/hadoop-3.1.3/etc/hadoop/ ==================== hadoop26 ==================== sending incremental file list sent 893 bytes received 18 bytes 1,822.00 bytes/sec total size is 107,741 speedup is 118.27 ==================== hadoop58 ==================== sending incremental file list hadoop/ hadoop/core-site.xml hadoop/hdfs-site.xml hadoop/mapred-site.xml hadoop/yarn-site.xml sent 3,479 bytes received 139 bytes 7,236.00 bytes/sec total size is 107,741 speedup is 29.78 ==================== hadoop100 ==================== sending incremental file list hadoop/ hadoop/core-site.xml hadoop/hdfs-site.xml hadoop/mapred-site.xml hadoop/yarn-site.xml sent 3,479 bytes received 139 bytes 7,236.00 bytes/sec total size is 107,741 speedup is 29.78
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
启动集群
指定worker
#hadoop26
vim /opt/module/hadoop-3.1.3/etc/hadoop/workers
//添加,不能空格不能空行
hadoop26
hadoop58
hadoop100
- 1
- 2
- 3
- 4
- 5
- 6
如果集群是第一次启动,需要在 hadoop26节点格式化 NameNode
注意:注意: 格式化 NameNode, 会产生新的集群 id, 导致 NameNode 和 DataNode 的集群 id 不一致,集群找不到已往数据。 如果集群在运行过程中报错,需要重新格式化 NameNode 的话, 一定要先停止 namenode 和 datanode 进程, 并且要删除所有机器的 data 和 logs 目录,然后再进行格式化。
#hadoop26
hdfs namenode -format
- 1
- 2
启动集群
#hadoop26
sbin/start-dfs.sh
Starting namenodes on [hadoop26]
Starting datanodes
hadoop58: WARNING: /opt/module/hadoop-3.1.3/logs does not exist. Creating.
hadoop100: WARNING: /opt/module/hadoop-3.1.3/logs does not exist. Creating.
Starting secondary namenodes [hadoop100]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
在配置了ResourceManager的节点 hadoop58启动yarn
#hadoop58
sbin/start-yarn.sh
Starting resourcemanager
Starting nodemanagers
hadoop26: Warning: Permanently added 'hadoop26,10.0.3.26' (ECDSA) to the list of known hosts.
hadoop58: Warning: Permanently added 'hadoop58,10.0.3.58' (ECDSA) to the list of known hosts.
- 1
- 2
- 3
- 4
- 5
- 6
- 7
可以使用jps命令查看各主机的集群进程
hadoop26$ jps
26609 Jps
26500 NodeManager
25909 NameNode
26057 DataNode
- 1
- 2
- 3
- 4
- 5
在本地查看配置好的hadoop
此处记得在aws控制台打开相应的端口
Web 端查看 HDFS 的 NameNode http://hadoop102:9870
[外链图片转存中…(img-yt8nQNS6-1650353437317)]
Web 端查看 YARN 的 ResourceManager http://hadoop103:8088
[外链图片转存中…(img-JHoglhj0-1650353437319)]
重启集群
#关闭yarn
sbin/stop-yarn.sh
#关闭dfs
sbin/stop-dfs.sh
#如果删除了data目录,需要重新格式化namenode
hdfs namenode -format
#再次启动集群
sbin/start-yarn.sh
sbin/start-dfs.sh
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
自动化脚本
#!/bin/bash if [ $# -lt 1 ] then echo "No Args Input..." exit ; fi case $1 in "start") echo " =================== 启动 hadoop 集群 ===================" echo " --------------- 启动 hdfs ---------------" ssh hadoop26 "/opt/module/hadoop-3.1.3/sbin/start-dfs.sh" echo " --------------- 启动 yarn ---------------" ssh hadoop58 "/opt/module/hadoop-3.1.3/sbin/start-yarn.sh" echo " --------------- 启动 historyserver ---------------" ssh hadoop26 "/opt/module/hadoop-3.1.3/bin/mapred --daemon start historyserver" ;; "stop") echo " =================== 关闭 hadoop 集群 ===================" echo " --------------- 关闭 historyserver ---------------" ssh hadoop26 "/opt/module/hadoop-3.1.3/bin/mapred --daemon stop historyserver" echo " --------------- 关闭 yarn ---------------" ssh hadoop58 "/opt/module/hadoop-3.1.3/sbin/stop-yarn.sh" echo " --------------- 关闭 hdfs ---------------" ssh hadoop26 "/opt/module/hadoop-3.1.3/sbin/stop-dfs.sh" ;; *) echo "Input Args Error..." ;; esac
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
jpsall.sh
#!/bin/bash
for host in hadoop26 hadoop58 hadoop100
do
echo =============== $host ===============
ssh $host jps
done
- 1
- 2
- 3
- 4
- 5
- 6
集群测试
hadoop fs -mkdir /input
hadoop fs -put ~/word.txt /input
hadoop fs -put /home/ecw-user/software/jdk-8u212-linux-x64.tar.gz /
- 1
- 2
- 3
注意此处上传之后不能在web端下载和预览文件,原因是没有开放端口,hadoop2和hadoop3存在端口差异
常用端口号
| 端口名称 | hadoop2.x | hadoop3.x |
|---|---|---|
| NameNode内部通信端口 | 8020/9000 | 8020/9000/9820 |
| NameNOde HTTP UI | 50070 | 9870 |
| MapReduce查看执行任务 | 8088 | 8088 |
| 历史服务器通信端口 | 19888 | 19888 |
另外由于实验使用实例,所以需要在控制台开放端口,开放端口较多可能存在安全隐患,指定/32ip,实例之间开放所有端口避免失败
查看存储数据
cd /opt/module/hadoop-3.1.3/data/dfs/data/current/BP-1521219625-10.0.3.26-1650095113435/current/finalized/subdir0/subdir0
cat blk_1073741825
hadoop java
hadoop cpp
hadoop c
golang java
rust php
hive
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
下载文件
hadoop fs -get /jdk-8u212-linuxx64.tar.gz ./
- 1
执行脚本程序
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /input /output
- 1
此处报错参考解决https://blog.csdn.net/xiaobao7865/article/details/111148603
xsync脚本同步确实挺好使
<configuration> <!-- 指定 MapReduce 程序运行在 Yarn 上 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>yarn.app.mapreduce.am.env</name> <value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value> </property> <property> <name>mapreduce.map.env</name> <value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value> </property> <property> <name>mapreduce.reduce.env</name> <value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value> </property> <property> <name>yarn.application.classpath</name> <value> /opt/module/hadoop-3.1.3/etc/hadoop, /opt/module/hadoop-3.1.3/share/hadoop/common/lib/*, /opt/module/hadoop-3.1.3/share/hadoop/common/*, /opt/module/hadoop-3.1.3/share/hadoop/hdfs, /opt/module/hadoop-3.1.3/share/hadoop/hdfs/lib/*, /opt/module/hadoop-3.1.3/share/hadoop/hdfs/*, /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/lib/*, /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/*, /opt/module/hadoop-3.1.3/share/hadoop/yarn, /opt/module/hadoop-3.1.3/share/hadoop/yarn/lib/*, /opt/module/hadoop-3.1.3/share/hadoop/yarn/*, </value> </property> </configuration>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
[外链图片转存中…(img-qG38beQF-1650353437320)]
配置历史服务器
编辑mapred-site.xml
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop26:10020</value>
</property>
<!-- 历史服务器 web 端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop26:19888</value>
</property>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
启动历史服务器
mapred --daemon start historyserver
- 1

配置日志的聚集
应用运行完成以后,将程序运行日志信息上传到 HDFS 系统上
注意:开启日志聚集功能, 需要重新启动 NodeManager 、 ResourceManager 和HistoryServer
配置yarn-site.xml
<!-- 开启日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置日志聚集服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop26:19888/jobhistory/logs</value>
</property>
<!-- 设置日志保留时间为 7 天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
关闭服务
sbin/stop-yarn.sh
mapred --daemon stop historyserver
- 1
- 2
重启服务
start-yarn.sh
mapred --daemon start historyserver
- 1
- 2
删除hdfs上已经存在的输出
hadoop fs -rm -r /output
- 1
测试wordcount
运行日志如下
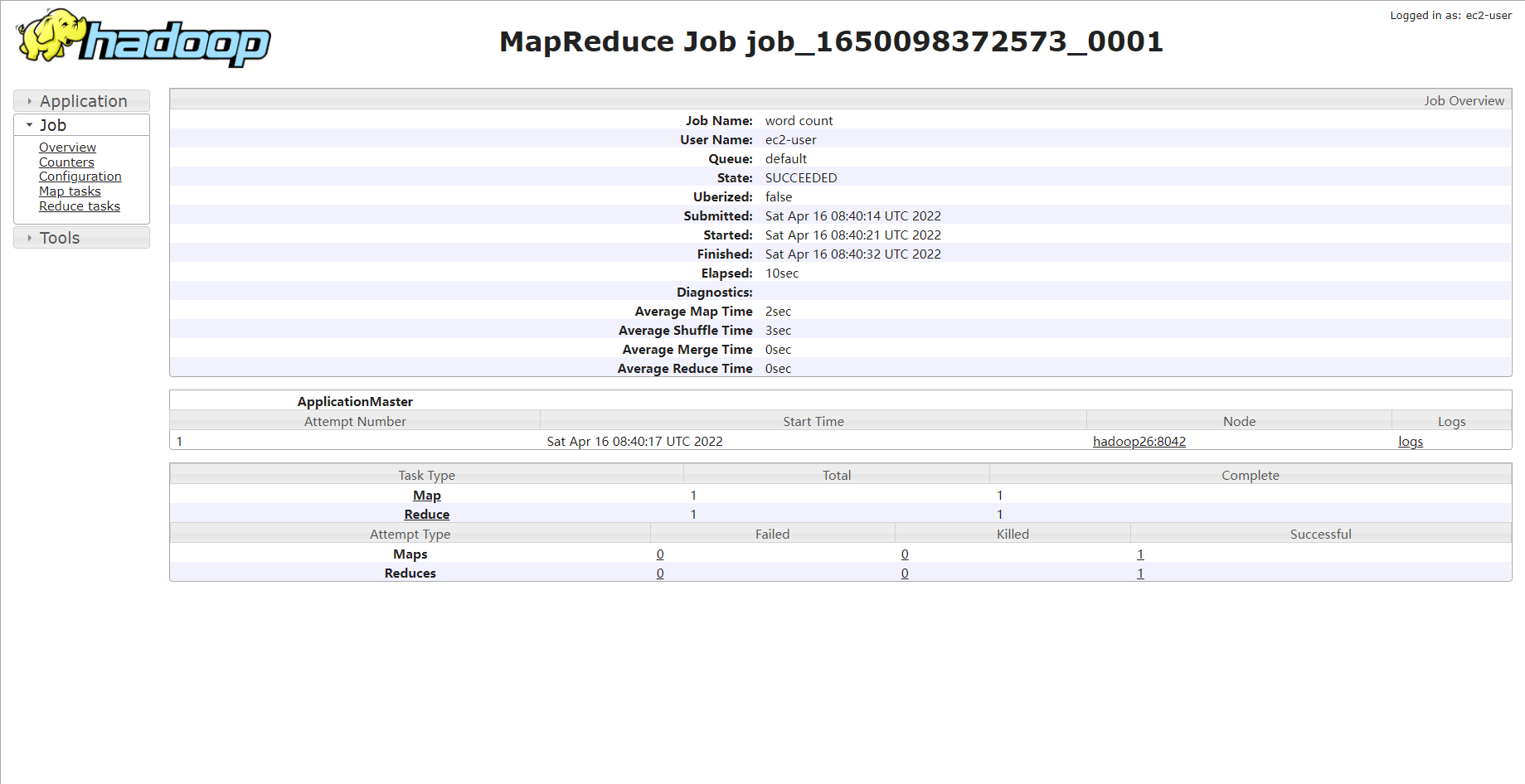
集群启动/停止方式总结
(1)各个模块分开启动/停止(前提配置 ssh )
-
整体启动/停止 HDFS
start-dfs.sh/stop-dfs.sh -
整体启动/停止 YARN
start-yarn.sh/stop-yarn.sh
(2)各个服务组件逐一启动/停止
- 分别启动/停止 HDFS 组件
hdfs --daemon start/stop namenode/datanode/secondarynamenode - 启动/停止 YARN
yarn --daemon start/stop resourcemanager/nodemanager
启动时遇到的问题
启动之后jps没有hadoop进程,大部分的问题可以通过查看logs解决,发现端口占用问题,需要kill相关进程

