
- 1腾讯云网络云产品介绍第三章-负载均衡服务_腾讯云 弹性负载均衡
- 2Mac M1/M2 安装Tensorflow教程_mac在已经创建好的环境上如何再安装tensorflow
- 3vue回调函数中调用data中的数据的解决方法_vuedata调用data里面数据
- 4[刷机] 9008 刷机救砖笔记
- 5Kotlin 协程:深入理解 ‘lifecycleScope‘_kotlin lifecyclescope
- 6IDEA项目如何上传至GitHub(保姆级教程)_idea怎么上传github
- 71235813找规律第100个数_数学基础知识点类总结,解题规律典型应用题可收藏
- 8使用TortoiseGit如何回退代码版本_tortoisegit回退到指定版本
- 9ARM架构下部署docker_dockerarm 18.09.0.200 版本下载
- 10神经网络与深度学习(一)_神经网络 各模块贡献度分析
AI绘画专栏之Comfyui之AnimateDiffLCM更快效果更佳工作流分享
赞
踩
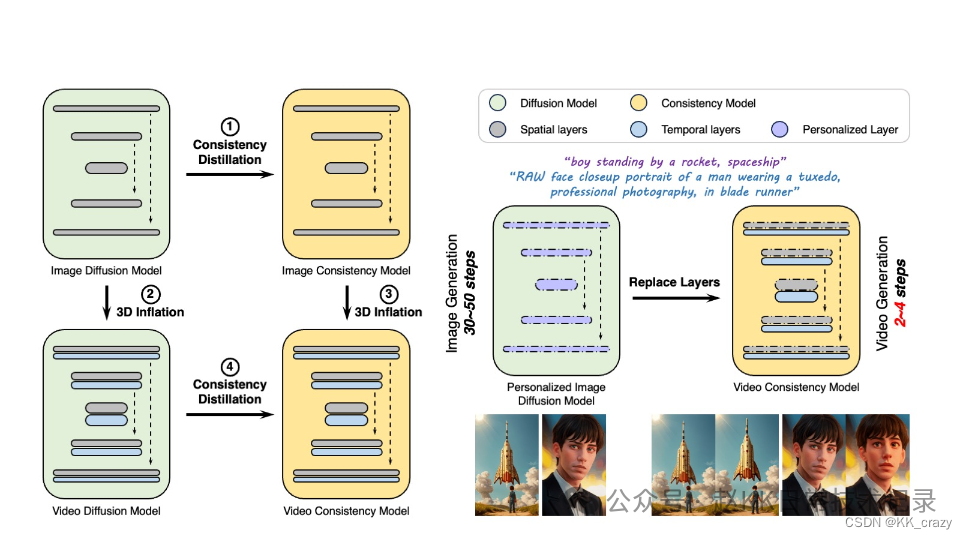
AnimateLCM能够在很少的步骤中生成高质量的视频。相比直接在原始视频数据集上应用一致性学习,该项目提出了一种解耦的一致性学习策略,分别对图像生成的基础知识和运动生成的基础知识进行提炼。这种策略提高了训练效率并提升了生成视频的视觉质量。
那么关于两个LCM的工作流,和模型
AnimateDiff 模型和LCM工作流链接:https://pan.quark.cn/s/4c93c8b2511b
- 1

AnimatediffLCM不仅仅是AnimateDiff与LCM的结合就完了,还对图像的质量,图像的一致性,和占用更低的显存做了优化,也就是说,两者兼得
示例
原理
视频扩散模型因其能够生成连贯且高保真度的视频而受到越来越多的关注。然而,迭代去噪过程使其计算密集且耗时,从而限制了其应用。受一致性模型(CM)的启发,该模型提炼了预训练的图像扩散模型以以最小的步骤加速采样,并在条件图像生成上成功扩展了潜在一致性模型(LCM),我们提出了AnimateLCM,允许在最小的步骤内生成高保真视频。我们没有直接在原始视频数据集上进行一致性学习,而是提出了一种解耦一致性学习策略,将图像生成先验和运动生成先验的蒸馏解耦,提高了训练效率,增强了生成视觉质量。此外,在稳定的扩散社区中实现即插即用适配器的组合,以实现各种功能~(例如,用于可控发电的ControlNet)。我们提出了一种有效的策略,使现有适配器适应我们提炼的文本条件视频一致性模型,或者从头开始训练适配器,而不会影响采样速度。我们在图像条件视频生成和布局条件视频生成中验证了所提出的策略,都取得了最佳效果。
下载模型放置位置
1.它是支持animatediffv3的
2.即使在 Windows 上的 256 GB rx 256 gpu 上以 256x8x600 的分辨率,当其他型号至少允许我以该分辨率创建时,这也会导致内存不足。但是LCM没有超过8GB
3.AnimateLCM,允许在最小的步骤内生成高保真视频。我们没有直接在原始视频数据集上进行一致性学习,而是提出了一种解耦一致性学习策略,将图像生成先验和运动生成先验的蒸馏解耦,提高了训练效率,增强了生成视觉质量。此外,在稳定的扩散社区中实现即插即用适配器的组合,以实现各种功能(例如,用于可控生成的 ControlNet)。我们提出了一种有效的策略,使现有适配器适应我们提炼的文本条件视频一致性模型,或者从头开始训练适配器,而不会影响采样速度。我们在图像条件视频生成和布局条件视频生成中验证了所提出的策略,都取得了最佳效果。
模型存放
sd15_t2v_beta.ckpt
ComfyUI/models/animatediff_models
sd15_lora_beta.safetensors
ComfyUI/models/loras
工作流必须的节点
https://github.com/Kosinkadink/ComfyUI-AnimateDiff-Evolved
https://github.com/Kosinkadink/ComfyUI-VideoHelperSuite
https://github.com/jojkaart/ComfyUI-sampler-lcm-alternative
ADE_StandardUniformContextOptions
SamplerLCMCycle
ADE_LoadAnimateDiffModel
LoraLoader
BNK_CLIPTextEncodeAdvanced
ADE_UseEvolvedSampling
LCMScheduler
ADE_ApplyAnimateDiffModelSimple
VAEDecode
SamplerCustom
领取comfyui工作流合集、超多AI合集已整理到https://yv4kfv1n3j.feishu.cn/docx/MRyxdaqz8ow5RjxyL1ucrvOYnnH

