- 1学习 Rust 的第一天:基础知识
- 2分辨率、帧率和码率三者之间的关系_码率和分辨率的关系
- 3Linux平台利用Ollama和Open WebUI部署大模型_open webui 如何添加模型
- 4当vue项目运行时,控制台出现“WebSocketClient.js:13 WebSocket connection to ‘ws://10.10.244.95:8080/ws‘ failed: E”_websocketclient.js:13 websocket connection to 'ws:
- 5基础笔记(三):网络协议之Tcp、Http
- 6idea中使用git合并分支_idea合并分支
- 7神经网络与深度学习(邱锡鹏)-学习笔记_深度学习是指一类模型吗
- 8github上想要下载单个文件 方法_git lfs 下载单个文件
- 9【Pycharm中python调用另一个文件类或者函数】_pycharm怎么引用其他py文件
- 10【前端素材】推荐优质在线茶叶电商Tea House平台模板(附源码)
神经网络与深度学习(一)_神经网络 各模块贡献度分析
赞
踩
一、序列
人工智能的子领域:
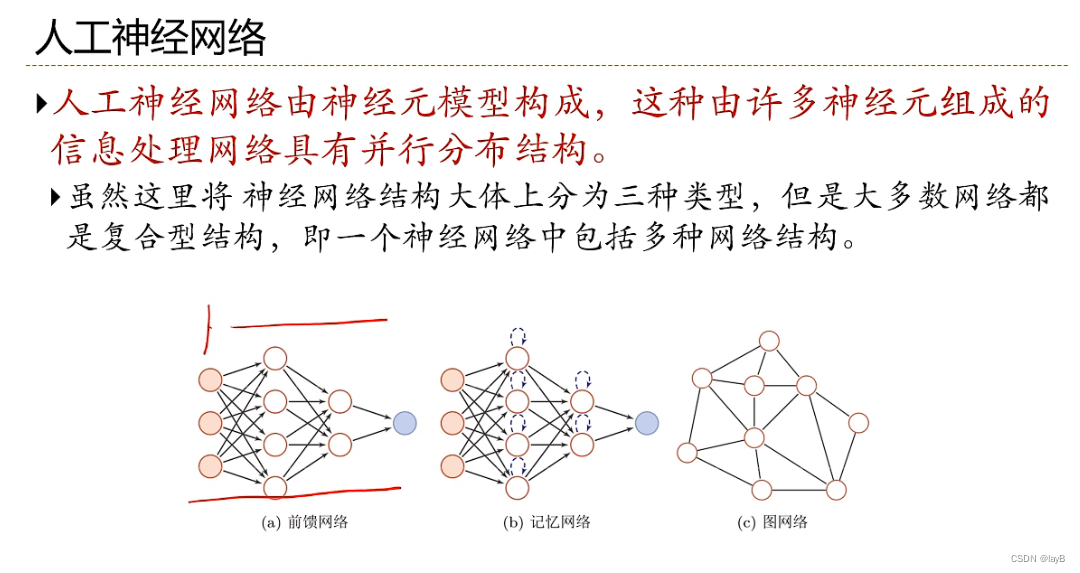
- 神经网络:一种以(人工)神经元为基本单元的模型
- 深度学习:一类机器学习问题,主要解决贡献度分配问题


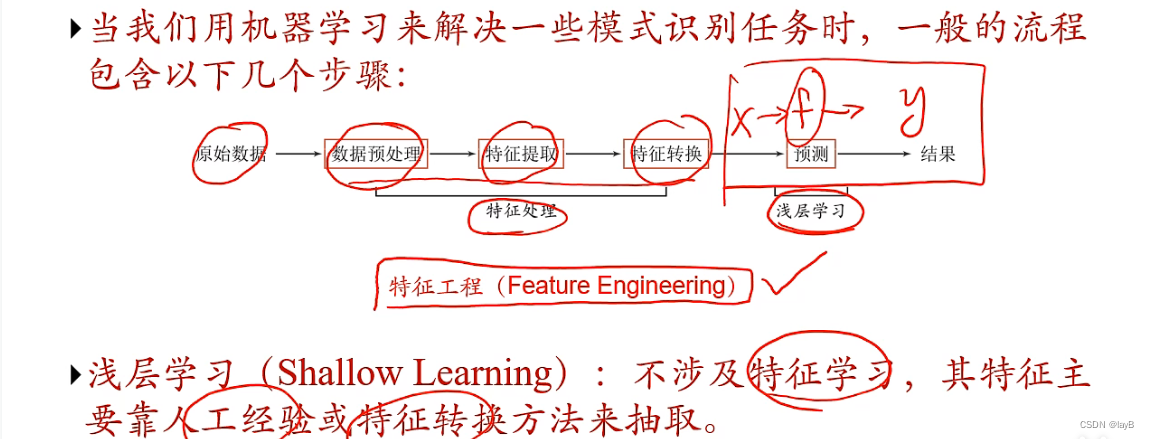

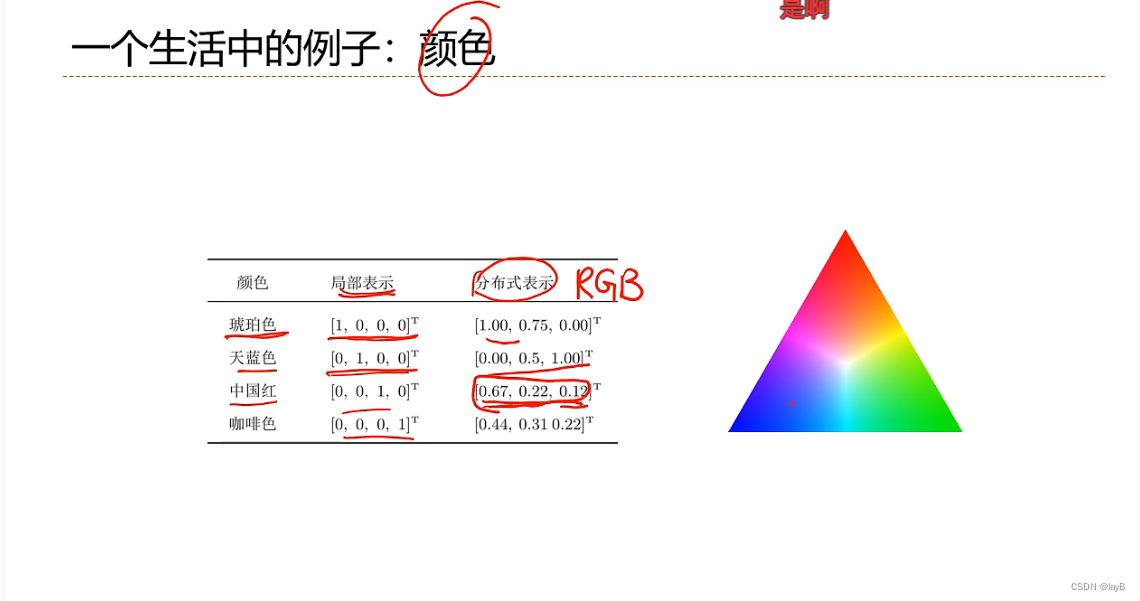
局部表示:一千种颜色一千种表示;分布式表示:RGB三值通过计算表示颜色
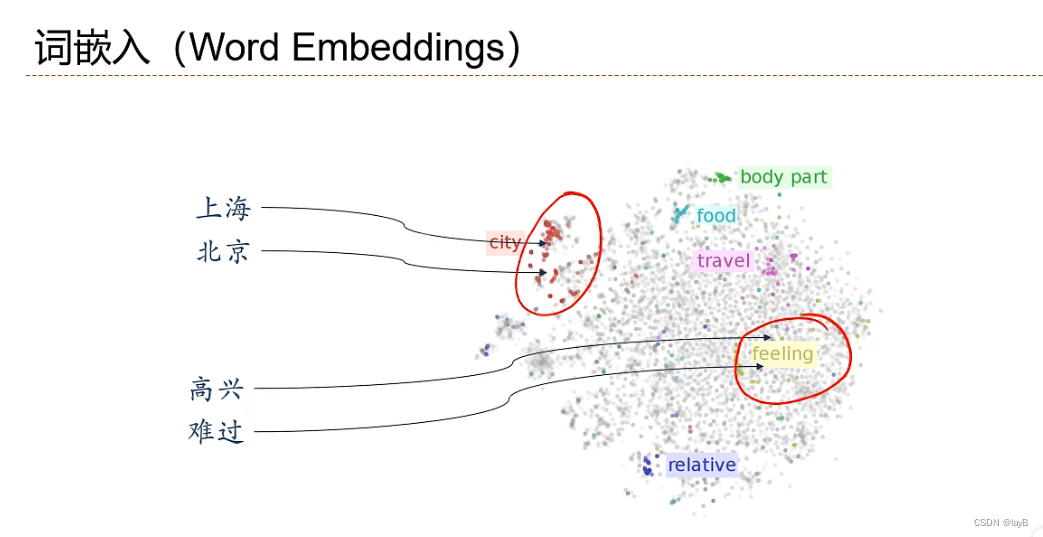
给出两个词就知道之间的关系
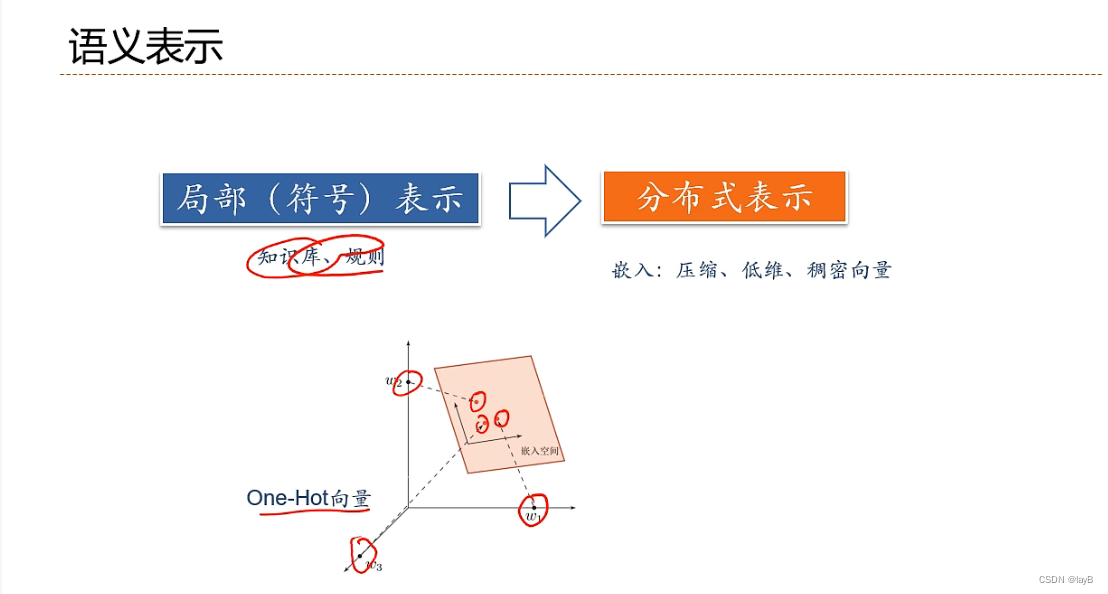
表示学习:如何自动从数据中学习好的表示
通过构建具有一定“深度”的模型,可以让模型来自动学习好的特征表示(从底层特征,到中层特征,再到高层特征),从而最终提升预测或识别的准确性。
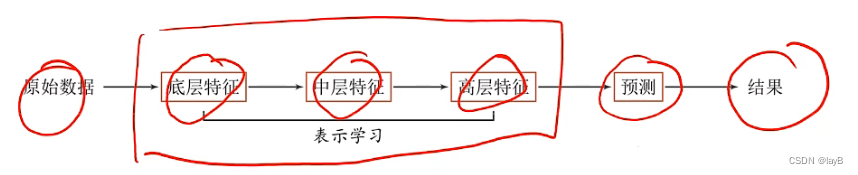

表示学习与深度学习:
一个好的表示学习策略必须具备一定的深度
- 特征重用:指数级的表示能力
- 抽象表示与不变性:抽象表示需要多步的构造
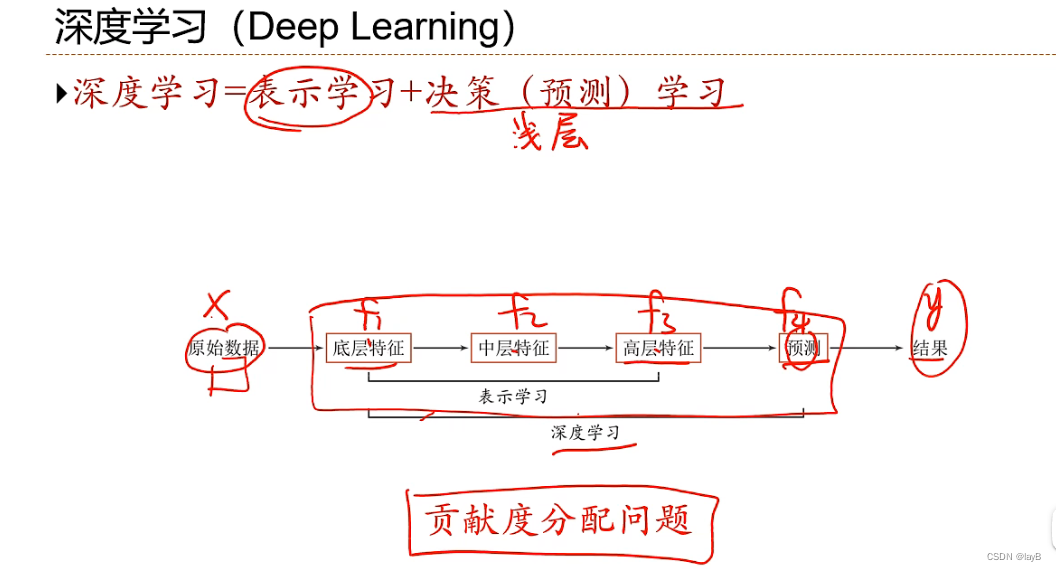
f1,f2,f3等等的贡献度分配问题
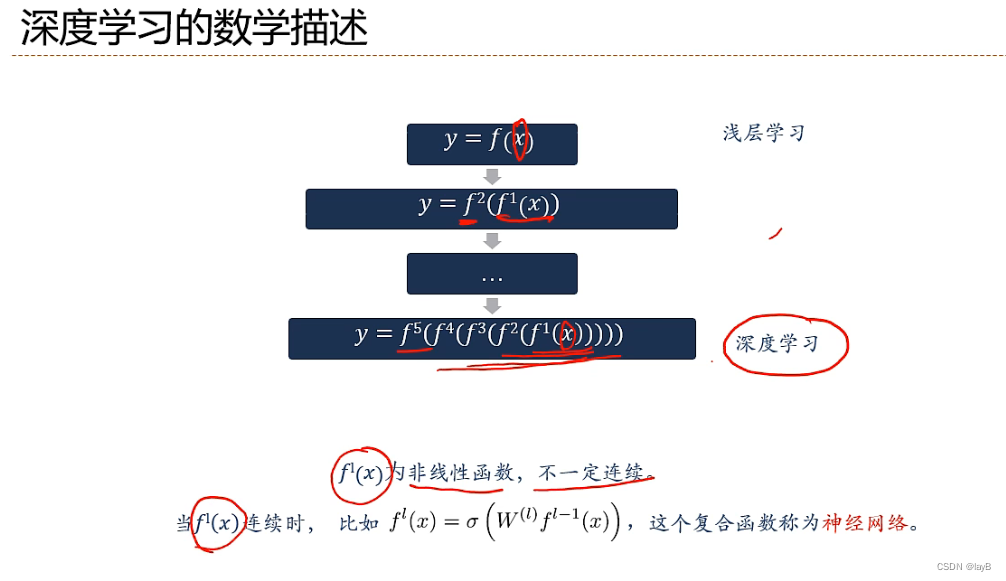
不断嵌套非线性函数,提取特征,从简单函数到一个非常深的复合函数,一直到最外层才进行分类
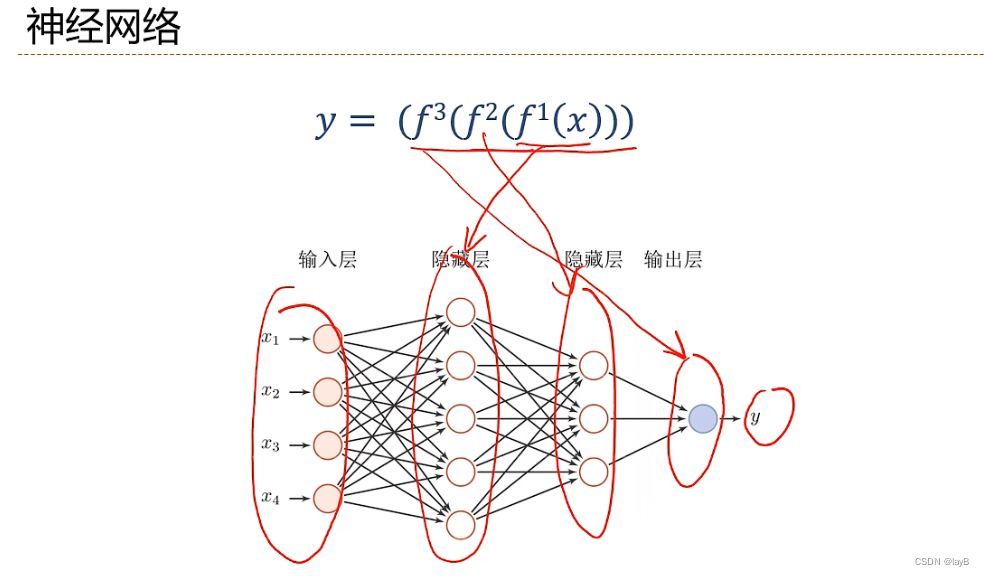
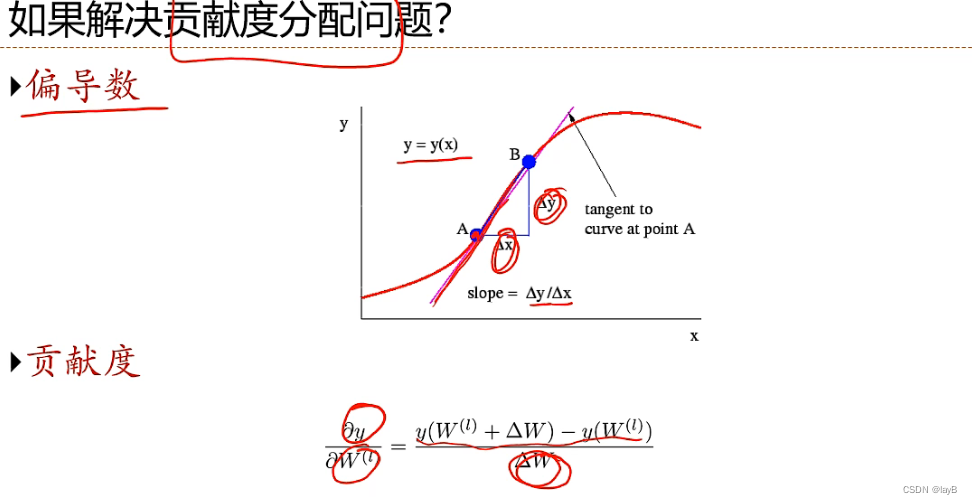
确定贡献度:y对中间的参数w进行扰动,如果扰动Δw对y的变化较大,则w的贡献度越大
二、机器学习
2.1机器学习定义
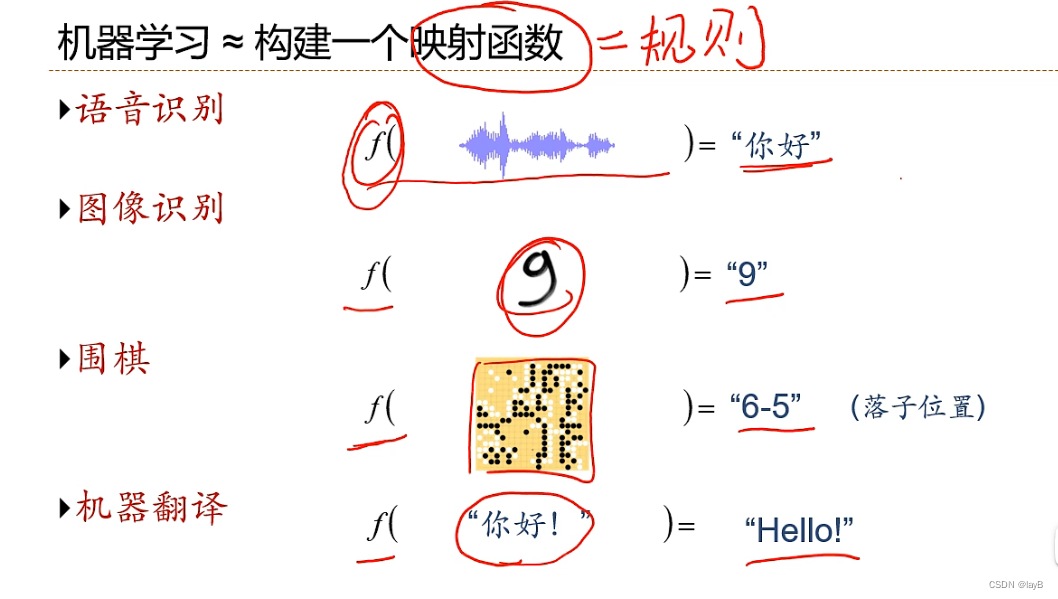
机器学习定义:从有限的观测数据中学习(或者猜测)出具有一般性的规律,并利用这些规律对未知数据进行预测的方法;通过算法使得机器能从大量数据中学习规律从而对新的样本做决策
规律:决策(预测)函数

 如何构建映射函数?
如何构建映射函数?
从大量数据中学习规律(function)x——>y
y连续是回归问题,离散则是分类问题
2.2 机器学习类型
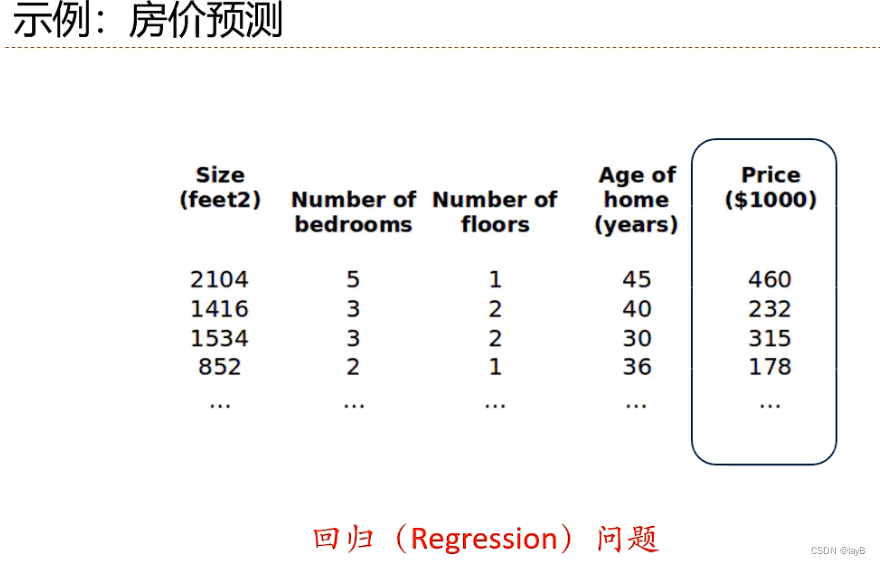
回归问题(Regression):
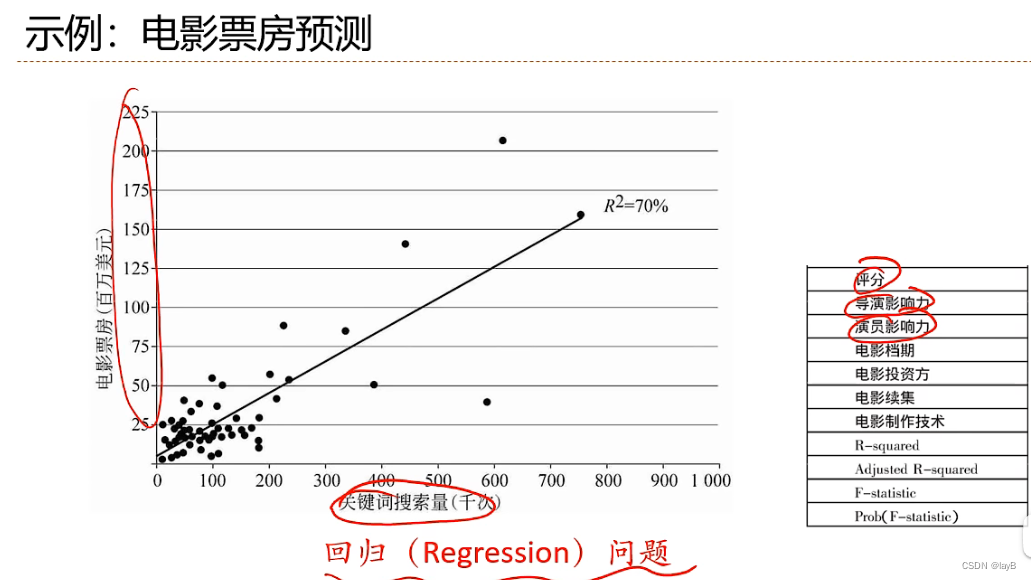
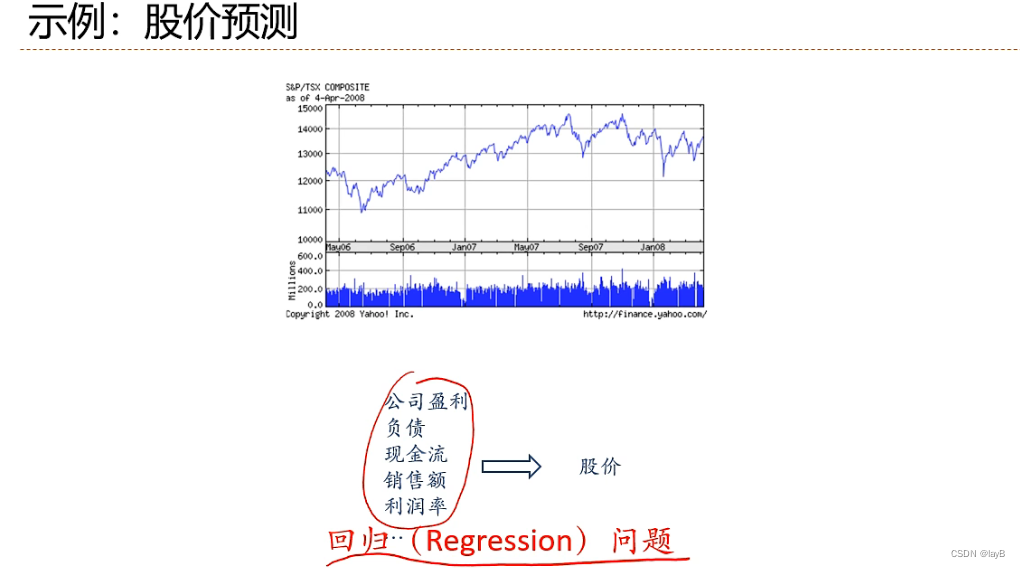
分类问题(Classification):

无监督学习:

强化学习:通过与环境进行交互来学习(不断试错)


- 监督学习:训练集为成对(x,y)样本,预测y=f(x)或者条件概率p(y|x)
- 无监督学习:训练集只有x,预测x的概率p(x)或者带隐变量z的p(x|z)(聚类,eg图片分类)
- 强化学习:训练集为智能体和环境交互的轨迹和累计奖励,优化目标是期望总回报
2.3机器学习的要素
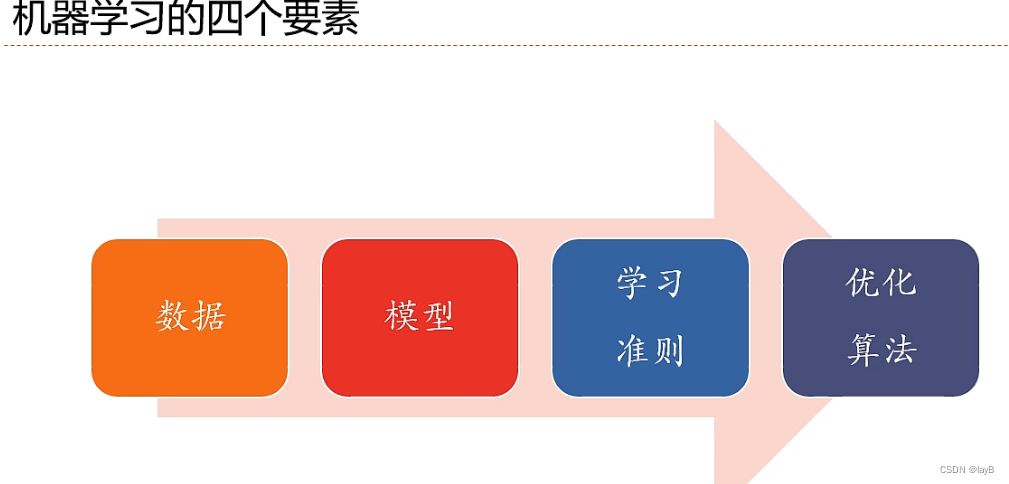
根据数据类型不同分类:
监督学习问题:(x,y)。若y连续,则是回归问题;若y离散,则为分类问题
无监督学习问题:x。
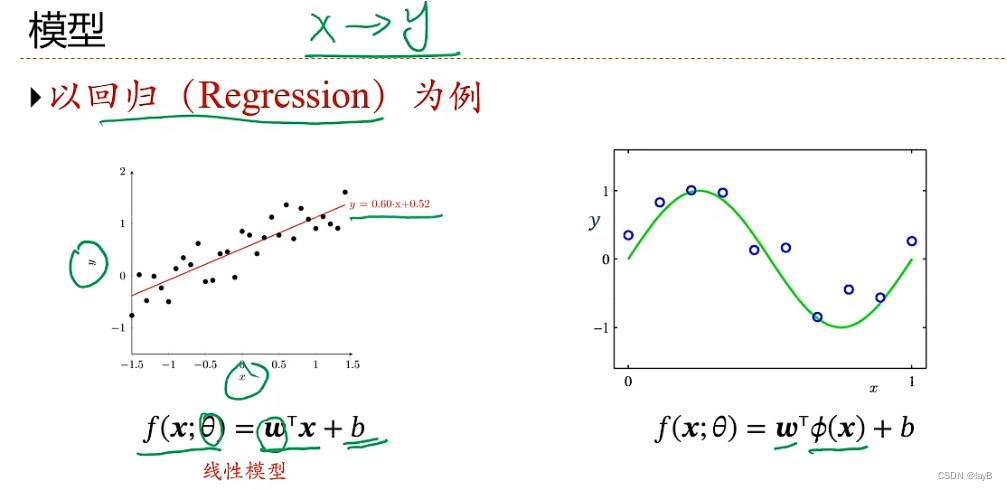
θ是系数总称,包括权重w和偏执b


在真实数据上的E(期望)

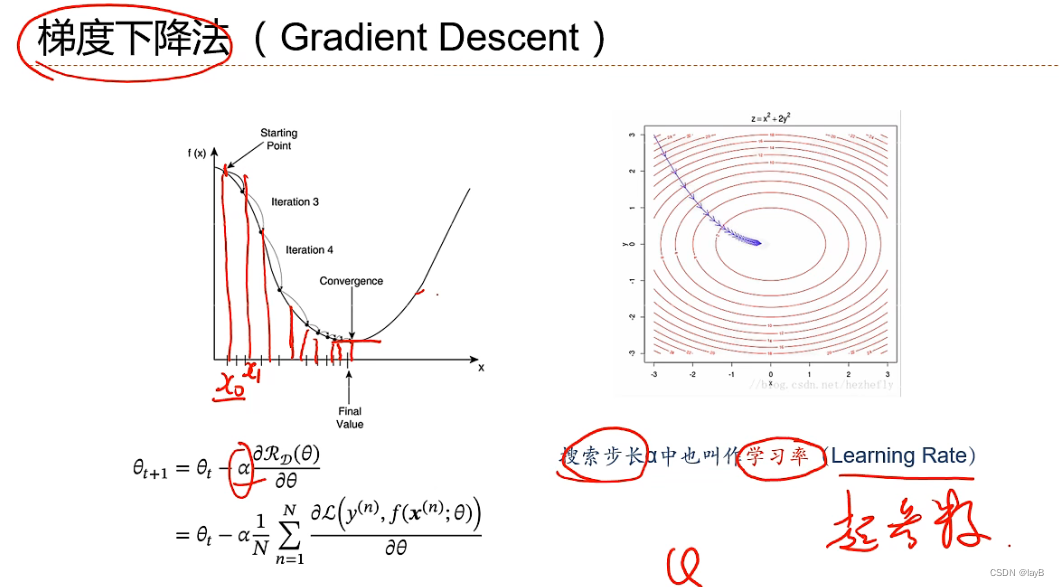
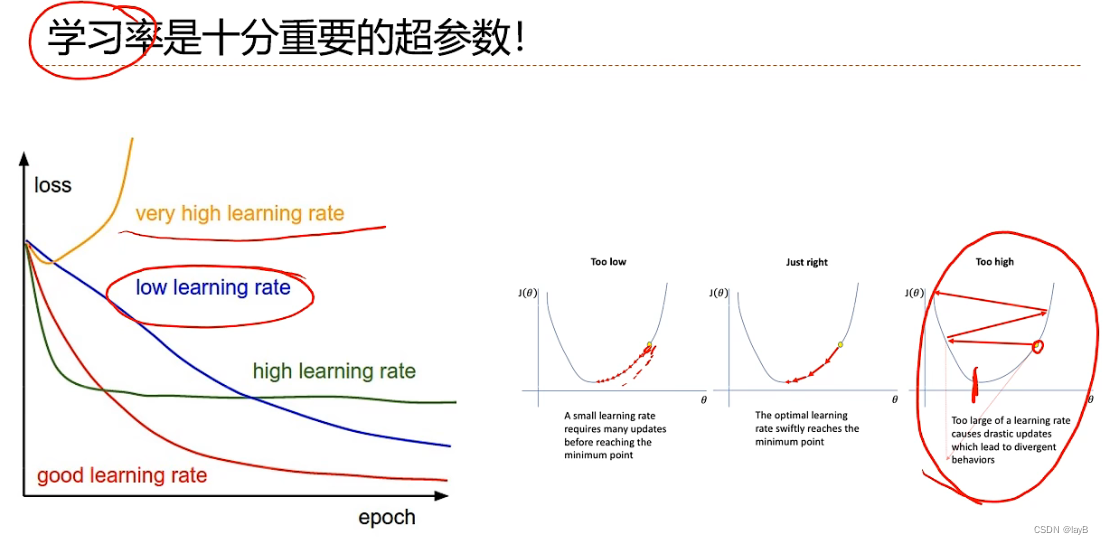
步长先大后小

折中:小批量随机梯度下降法

2.4 泛化和正则化
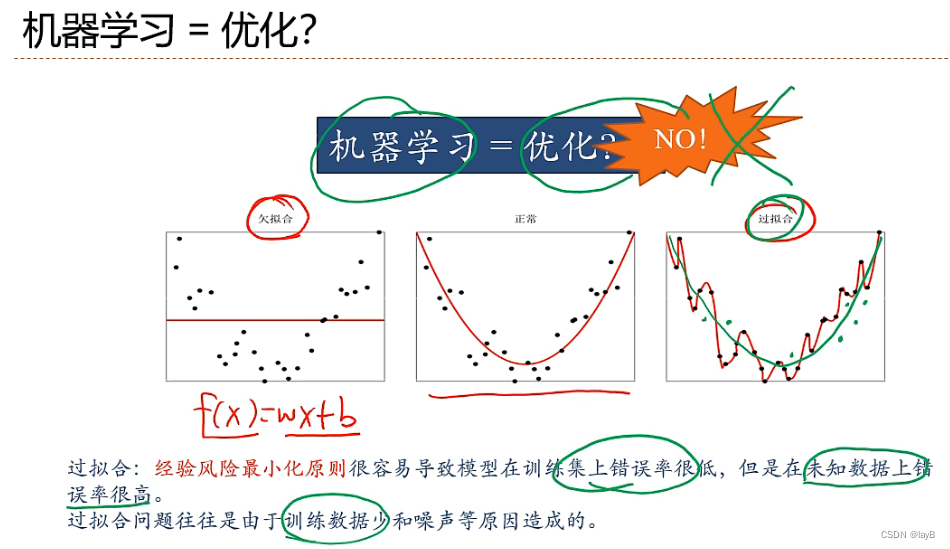
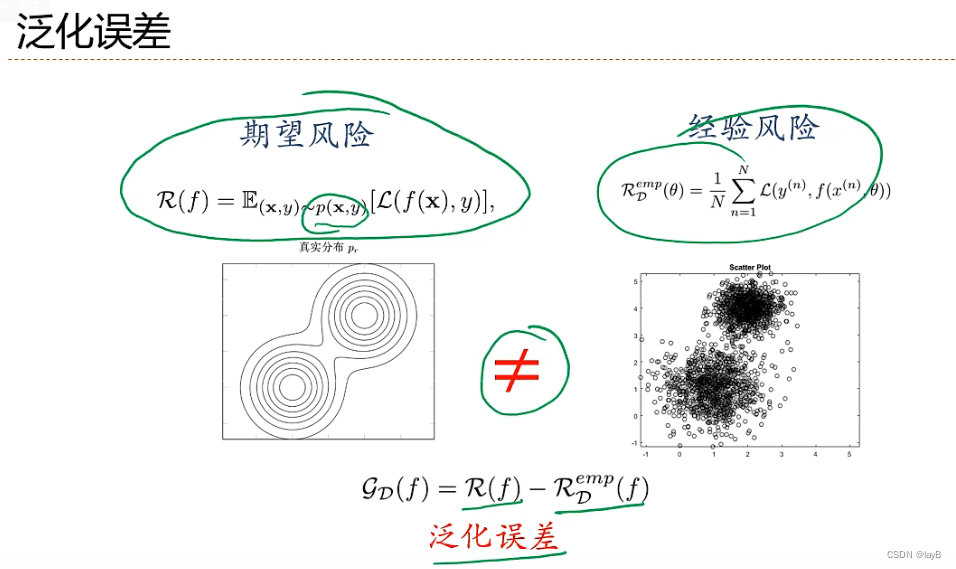
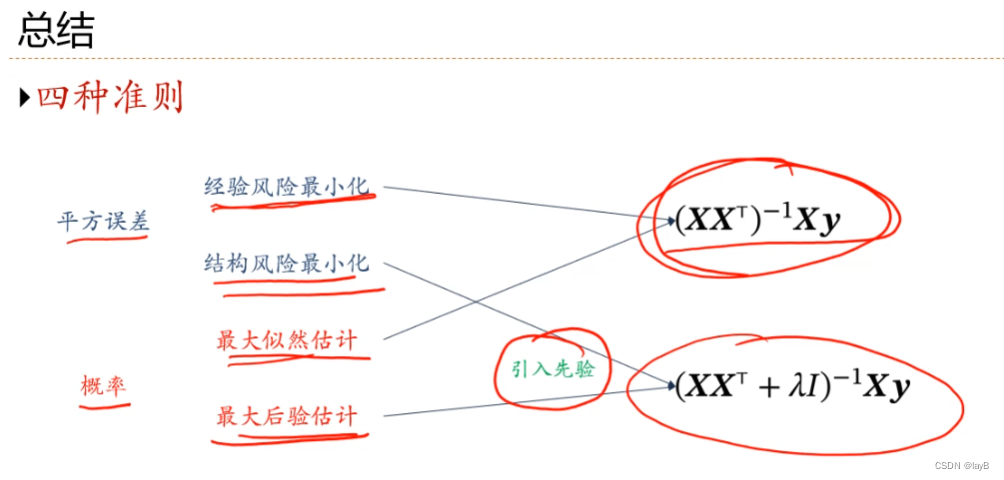
机器学习关注的不是在训练集上的错误率,而是在整个数据分布上的错误率,也就是期望风险。但是我们真实概率不知道,所以我们用经验风险代替
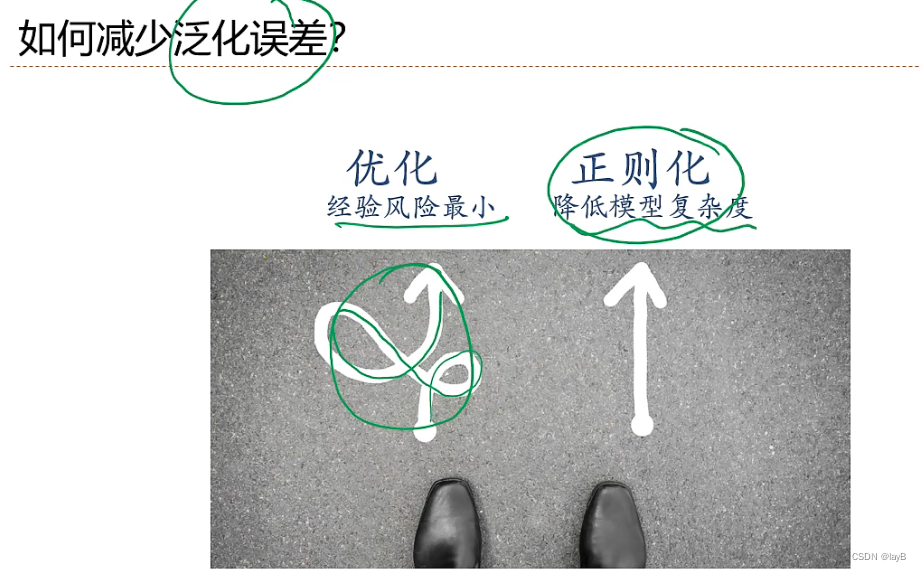
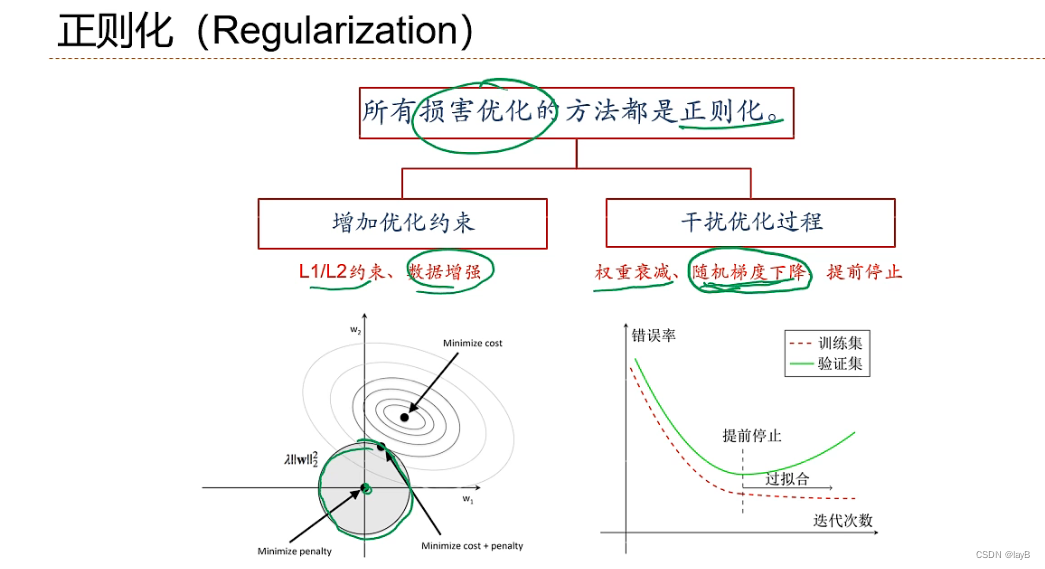
所有损害优化的方法都是正则化
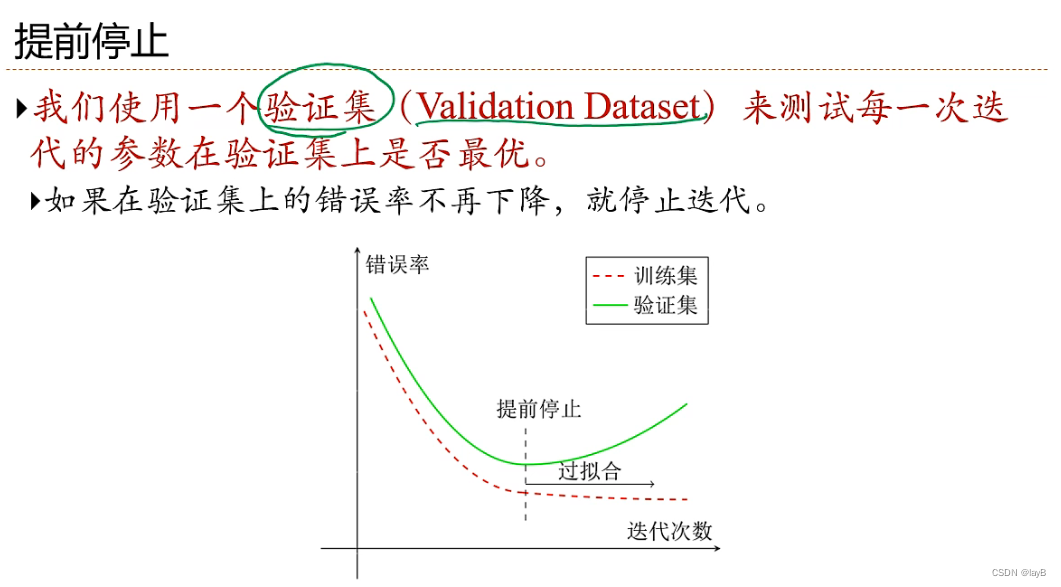
2.5线性回归
即最小二乘,算w算b
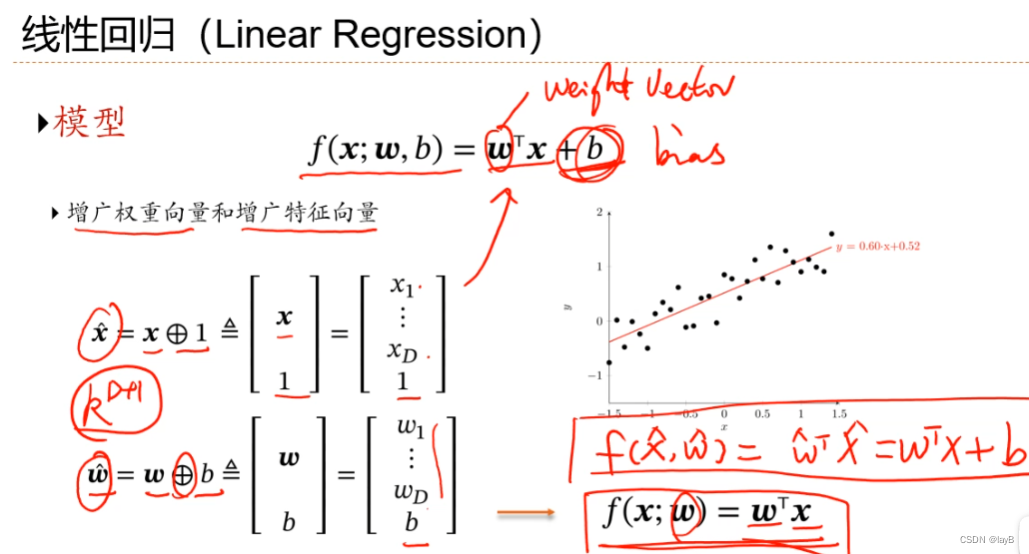
增广,加1维使直线过原点
eg:损失函数用平方损失函数

再


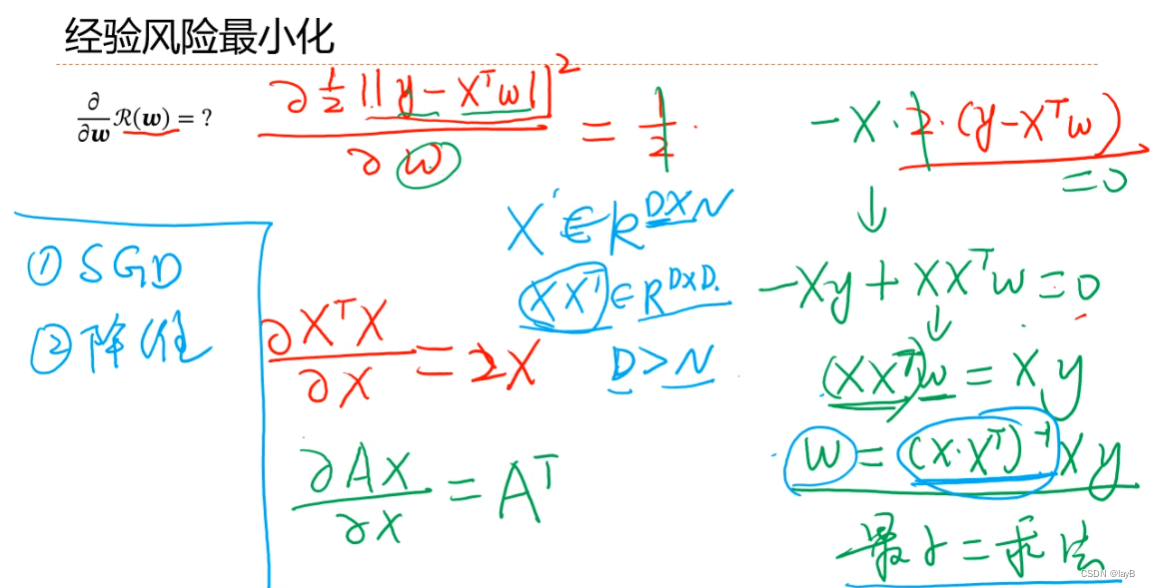
若xxT不可逆时:
共线时eg : Xi+Xj=0; y=WiXi+WjXj+b 因此Wi 和Wj 可以非常多解也可以同时非常大而保持y=0时结果不变,所以加上约束
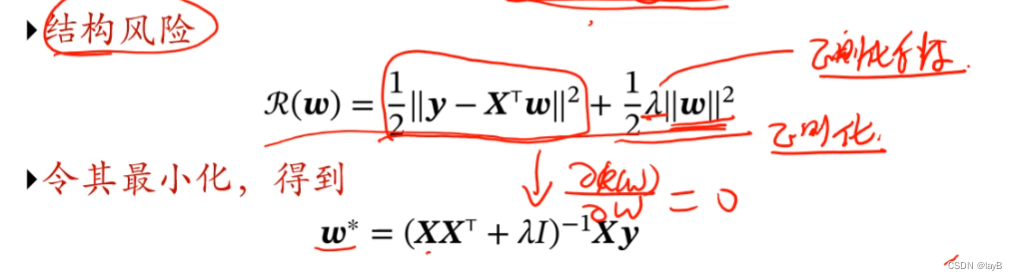
就是原基础xxT上对角线加上了λ,随之变成了可逆矩阵
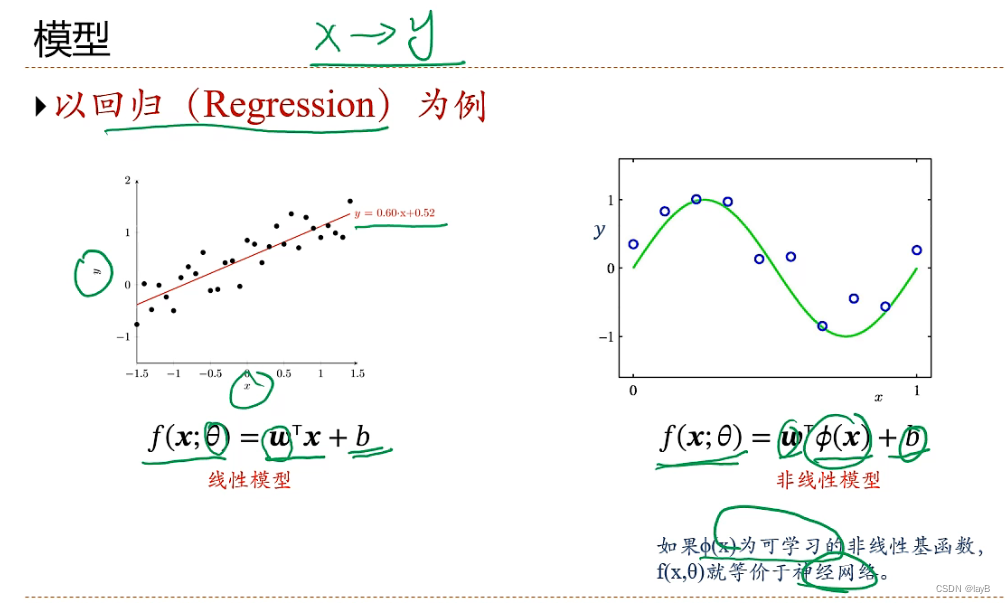
2.6多项式回归
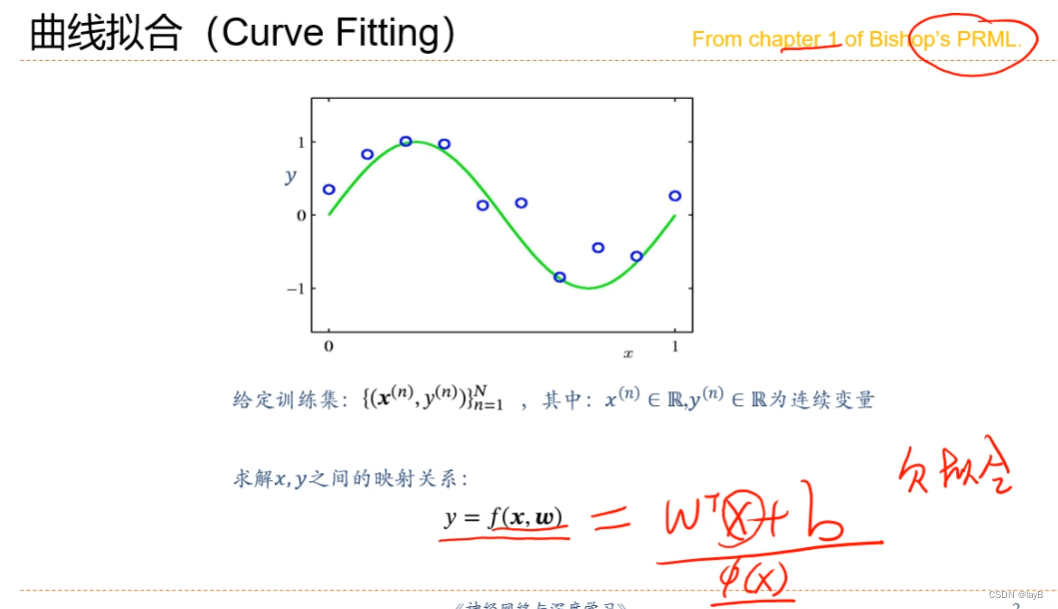
若线性则欠拟合;
y=f(x,w)中,设x=φ(x)
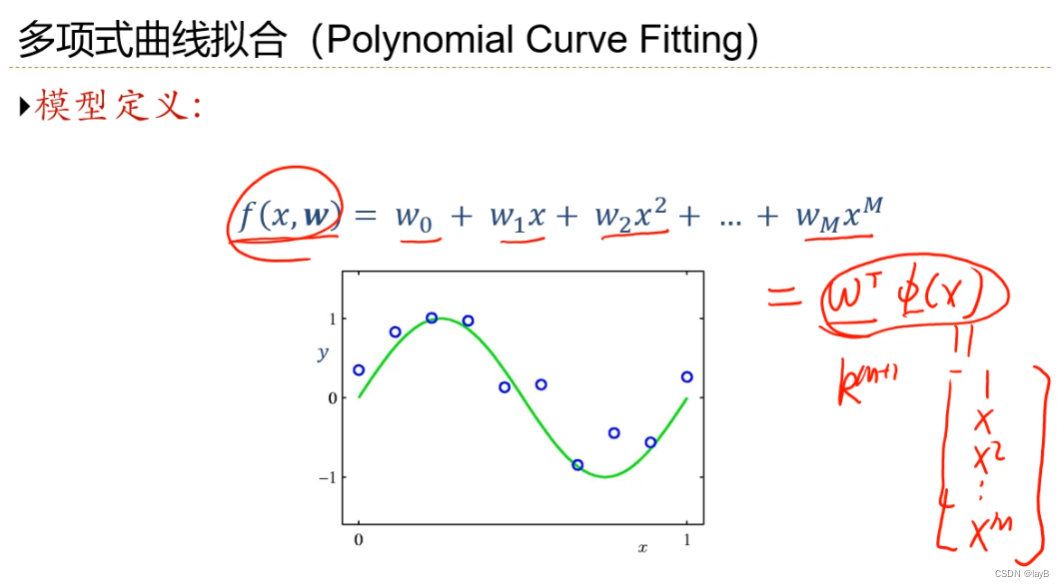
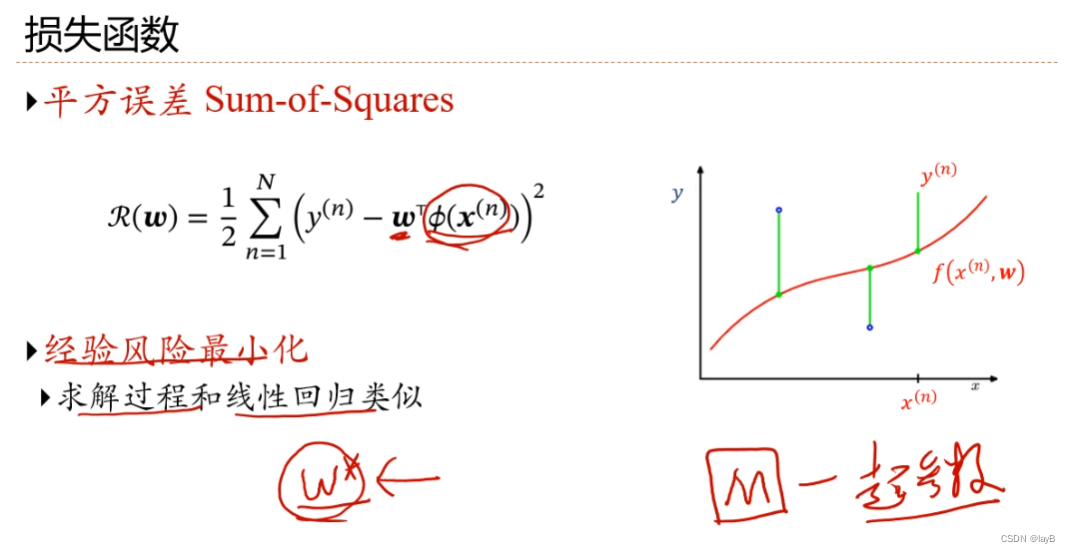
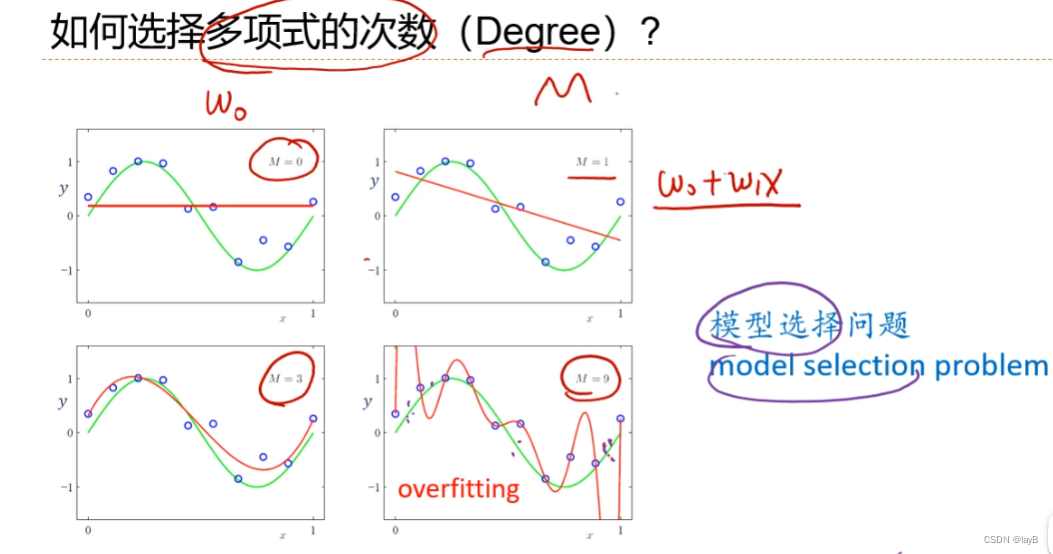
随着M(多项式的degree)的增大,曲线由欠拟合转化到过拟合
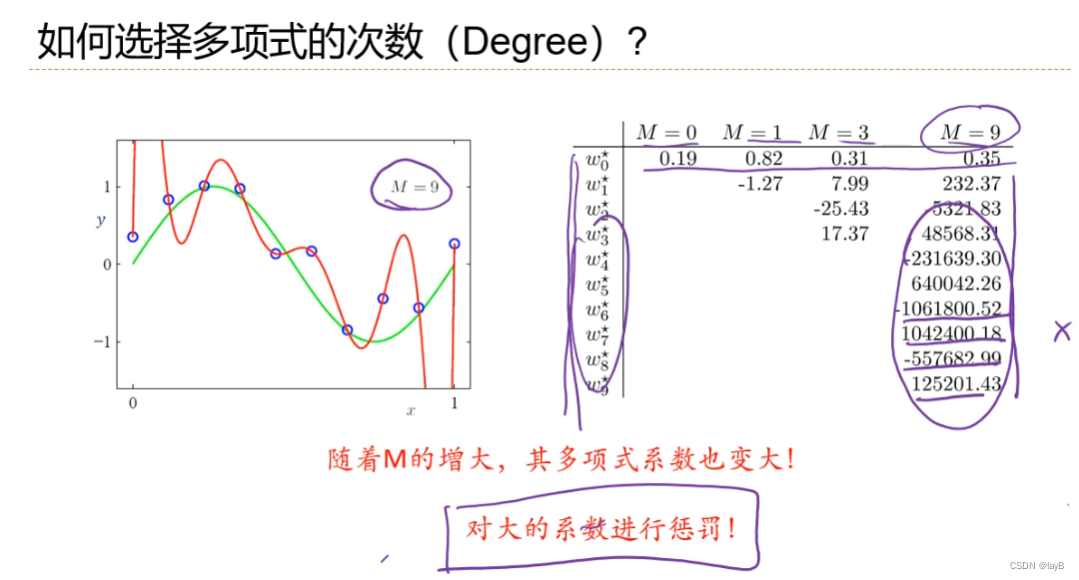
所以引入正则化项:

M=9时,确定λ的大小(对w惩罚的强弱,成正比) λ也是超参数,非常重要

另外控制过拟合:增加样本数量,经验风险趋向于期望风险
2.7 从概率角度看线性回归


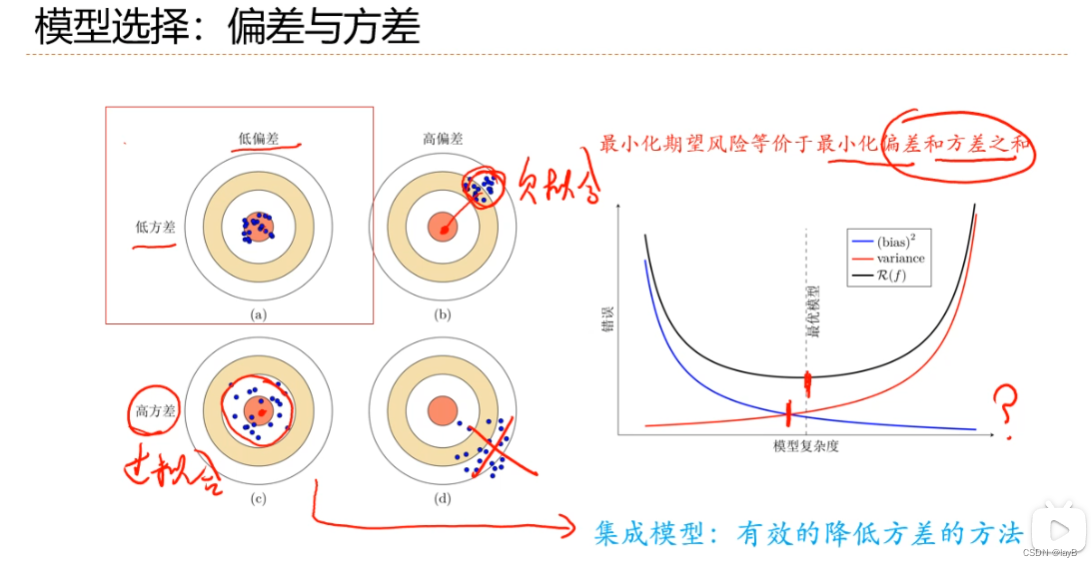
2.8模型选择与“偏差-方差”分解

模型越复杂训练错误越低,这样会导致过拟合



模型选择就是在模型复杂度与期望风险之间寻找一个平衡