
- 1git&github自学(8):发起Pull Request_pull requests
- 22022.11.20 第9次周报
- 3esp32cam和esp32-s3烧录human_face_detect实现人脸识别_quad_psram: psram id read error: 0x00ffffff, psram
- 4PHP-人员权限管理(RBAC)_php实现权限rubc
- 5Linux sysctl 网络相关参数_fwmark_reflect
- 6《Git与Github使用笔记》分享3款Git可视化工具_github可视化管理工具
- 7YOLOv8最新改进系列:融合最新顶会提出的HCANet网络中卷积和注意力融合模块(CAFM),有效提升小目标检测性能,大幅度拉升目标检测效果!遥遥领先!
- 8hive:函数:collect_list和collect_set (行转列-多行转单行)_collect_set 分列
- 9Java初阶(类和对象 ---- > 基础概念)_java类和对象的基本概念
- 10中国大学生计算机设计大赛之小程序开发全过程_计算机设计大赛小程序开发
【算法】—贪心算法详解
赞
踩
三.贪心算法
1.贪心算法:
①贪心算法的概念:
贪心算法就是不断选择在当前看来最好的选择,也就是说贪心算法并不从整体最优考虑,它所作出的选择只是在某种意义上的局部最优选择
虽然贪心算法不能对所有问题都得到整体最优解,但在一些情况下,即使贪心算法不一定能得到整体最优解,其最终结果却是最优解的很好近似
②贪心算法的选择:
用贪心法求解问题要满足以下条件:
- 贪心选择性:
所求问题的整体最优解可以通过一系列局部最优的选择,即贪心选择来达到——这是贪心算法可行的第一个基本要素,也是贪心算法与动态规划算法的主要区别
- 最优子结构性质:
当一个问题的最优解包含其子问题的最优解时,称此问题具有最优子结构性质——最优子结构性质是该问题可用 动态规划算法 or
贪心算法 求解的关键特征
③贪心算法与动态规划的差异:
-
相同:贪心算法和动态规划算法都要求问题*具有最优子结构性质
-
差异:
- 动态规划算法通常以自底向上的方式解各子问题
- 而贪心算法则通常以自顶向下的方式进行,以迭代的方式作出相继的贪心选择—即每作一次贪心选择就将所求问题简化为规模更小的子问题
经典硬币问题:

- 不能选择贪心,必须要用动态规划解决
④贪心算法的步骤:
- 从某一起点出发
- 在每一个解决问题步骤中,根据局部最优策略,得到一部分解,缩小问题规模
- 将所有解综合起来
不难看出,在以上的过程中,由于贪心算法的策略都是当前最优解,很显然高效和简介的代码(自顶向下利用迭代拆解问题)是它的最大优点
2.贪心算法中的经典问题:
贪心算法是一种解决问题的思想,由此列举出在以下几种常见问题中的贪心法:
1.找零问题
钱币找零问题是一个简单的问题,但也能很直观的体现出贪心算法的逻辑理念和思想
示例1:
题目描述:
假设商店老板需要找零n(≥0)元,钱币的面额有:100元,50元,20元,5元,1元,如何找零使得所需的钱币数最少?
输入描述:
在第一行给出测试例个数 N,代表需要找零的钱数,1≤N≤105
输出描述:
输出共有 5 行,每一行输出数据输出找零的金额与数量,详情看样例
**输入:**
365
**输出:**
100:3
50:1
20:0
5:3
1:0
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
思路分析:
- 贪心法:从最大硬币面值开始,计算这一类面值可以找的最大金额,每一类面值硬币的找零数量就是一个子问题,同时汇总以达到总硬币数最小的目标
注意:这里只需要考虑≤0时的不合法情况,因为存在面值为1的货币
def charge(t,n): global dic if n<=0: return0 # 每一次让当前最大面值的金额达到最大数目 for i in range(len(t)): cnt=n//t[i] dic[i]=dic.get(i,cnt) n%=t[i] return1 t=[1,5,20,50,100] t.sort(reverse=True) # 将数组逆序,由大及小遍历 n=int(input()) dic={} if charge(t,n): for key,value in dic.items(): print(f"{t[key]}:{value}") else: print("无法找零")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
示例2:
思路分析:
由于题设默认给出的开始状态的硬币一定可以达到最终状态,所以不判断不满足的情况(如不同的硬币数为奇数时)
贪心法:*遇到不相同就立即改变当前位置*
在对开始和结束时状态初始化完成后,遍历对应位置上的每一个数(从第一个到倒数第二个)其中’*’为1,’o’为0
-
若对应位置上的数不相同,则将该位置上的数变为end位置上的数,再将后一位置上的数翻面:
start[i+1] = abs(start[i+1]-1) # 0->1 1->0 start[i]=end[i]
def init(a): for i in input(): if i == '*': a.append(1) else: a.append(0) start=[] end=[] init(end) init(start) cnt=0 for i in range(len(end)-1): if start[i]!=end[i]: start[i+1] = abs(start[i+1]-1) # 0->1 1->0 start[i]=end[i] # 令其相等 cnt+=1 print(cnt)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
2.背包问题
背包问题:即有若干物品,每个物品有自己的价值和重量,背包有总重量,问题就是怎样将背包装的最大价值,背包问题也分很多种,很多需要用动态规划才能得到最优解
贪心算法中的背包问题:物品可以拆分的背包问题,所谓可拆分,就是物品不是一个整体,并不是严格要求只能是装或不装的情况——也就是在选择物品i装入背包中时,可以选择物品 i 的一部分,而不一定要全部装入背包中
示例1:
思路分析:
-
题目给出了汽车核载重量为 w,可供选择的物品的数量 n,每个物品的重量为 gi, 价值为 pi,很明显,物品是可以拆分的,因为可以只装入该物品重量的一部分
-
贪心法:
由可拆分性可知,要得到最大价值需要根据物品的性价比大小决定,也就是单位重量下物品的价值 :
-
ai=[(pi/gi),gi]:可以通过二维数组将每个物品的单价和重量放在一起储存
-
①若剩余的容量能装下当前最大价值的物品,则将其全部放入,总重量:
w-=a[1] 总价值+=a[0]*a[1] -
②若剩余的容量不能全部装下当前最大价值的物品,则可以等效为物品足够多,因此,能装入的重量为 w(能装多少装多少),
总价值+=w*a[0]
def getmax(val_num,w): res=0 # a[0]是单价 a[1]是总重量 for a in val_num: y=a[0]*a[1] if w>=a[1]: # 如果能装下当前最大价值的所含物品总数 w-=a[1] res+=y if w==0: return res else: # 如果装不下全部,可以看作是物品数量足够多 res+=w*a[0] # 能装多少装多少 return res n,w=map(int,input().split()) val_num=[] for i in range(n): g,p=map(int,input().split()) val_num.append([p/g,g]) val_num.sort(key=lambda x:x[0],reverse=True) print("%.1f"%getmax(val_num,w))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
-
示例2:
思路分析:
贪心算法:因为要使费用最低,因此,每一次要尽可能地找到最便宜的油价加油站,在起点到终点之间的最便宜的站点加尽可能多的油——可拆解
- 贪心判断:每经过一个点(包括起点)时,假设在此点加满油后,能走距离为D,会有如下三种情况:
-
若在所能走的D距离内,都没有加油站比当前所在的加油站油价更便宜:
则选择在此点加满油后,到达 最近的下一个点 继续重复贪心判断
-
若在所能走的D距离内,存在有加油站比当前的加油站油价更加便宜:
则只用选择加够能到 最近的便宜加油站 的油即可,在该点继续重复贪心判断
-
若在所能走的D距离内,都无法到达最近的下一点,则 no solution
这里设定终点的油价为0——因为若在某点判断距离范围内最近的且比它便宜的油价加油站就是终点,则直接可以开到终点
一题多解: 这里我的做法思路是:先判断最远距离,再判断中间是否有更便宜的加油站;
当然也可以先判断最便宜的加油站,在判断是否能走,能走,就直接到,不能走,就在中间再找最便宜的加油站
- 1
- 2
- 3
- 4
具体实现:
题中变量:
D1——总距离;C——油箱容量;D2——每升油能走的距离;P——起点油价;N——加油站数量(可为0)
-
初始化:构造二维数组sum:[…][0]表示距离,[…][1]表示油价
结构:sum[[当前站到起点距离, 当前站油价],…]
注意:这里将起点设为 [0, P],终点设为 [D1, 0]
-
贪心+递归函数:
-
参数:index—记录当前所在位置;c—记录当前邮箱剩余的油量
-
递归结束条件:
到达终点:index==N+1
-
递归体:
①先判断加满油时是否能到达下一加油站:
d=C*D2<sum[index+1][0]-sum[index][0]
不能达到则结束
②若能达到:
- 先根据距离判断能到达的最远加油站 m
m=index+1 while m<N+1: if sum[m][0]<=sum[index][0]+d <sum[m+1][0]: break m+=1- 1
- 2
- 3
- 4
- 5
-
如果在这些加油站中,有比当前加油站油价便宜的 j,只需加够到该站 j的油即可,再对 j 站递归:
要注意剩余油量c和理论油量c0之间的关系
for j in range(index+1,m+1): if sum[j][1]<sum[index][1]: # 如果存在加油站价格比当前站便宜 # 只用加够到该站的油即可 c0=(sum[j][0]-sum[index][0])/D2 **# 理论要加的油** if c<c0: # 当前油少 res+=sum[index][1]*(c0-c) # 只用再补上即可 price(j,0) # 递归 else: # 当前油多 price(j,c-c0) # 不用出钱 break- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 如果在这些加油站中,没有比当前加油站油价便宜的,则需要加满油,到达下一站后,再进行判断,即递归下一站index+1:
... elif j==m: # 之间没有加油站比当前站更便宜 res+=sum[index][1]*(C-c) # 加满油 c0=(sum[index + 1][0]-sum[index][0])/D2 **# 理论需要油量** c =C-c0 # 到达下一站剩余油量 price(index+1, c)- 1
- 2
- 3
- 4
- 5
- 6
-
-
返回res即为最小费用,最后要注意一个特例,就是若起点==终点时,费用为0
贪心+递归:
def price(index,c): # 当前所在位置index,油量和上一层能达到的最远加油点 global res # 递归结束条件——已经到达终点 if index==N+1: return res # 递归体 d=C*D2 if d<sum[index+1][0]-sum[index][0]: # 加满油也无法到达下一站 return 0 else: # 判断最远能达到的加油站位置m m=index+1 while m<N+1: if sum[m][0]<=sum[index][0]+d <sum[m+1][0]: break m+=1 for j in range(index+1,m+1): if sum[j][1]<sum[index][1]: # 如果存在加油站价格比当前站便宜 # 只用加够到该站的油即可 c0=(sum[j][0]-sum[index][0])/D2 # 理论要加的油 if c<c0: # 当前油少 res+=sum[index][1]*(c0-c) # 只用再补上即可 price(j,0) # 递归 else: # 当前油多 price(j,c-c0) # 不用出钱 break elif j==m: # 之间没有加油站比当前站更便宜 res+=sum[index][1]*(C-c) # 加满油 c0=(sum[index + 1][0]-sum[index][0])/D2 # 理论需要油量 c =C-c0 # 到达下一站剩余油量 price(index+1, c) **# 1.初始化** a=list(input().split()) D1,C,D2,P=[float(i) for i in a[:4]] N=int(a[4]) # sum[[当前站到起点距离,当前站油价],...] sum=[[0,P]] for i in range(N): di,pi=map(float,input().split()) sum.append([di,pi]) sum.append([D1,0]) **# 2.贪心+递归** res=0 if price(0,0)!=0: **# 传入起点和起点油量** print("%.2f"%res) elif D1==0: **# 这是个特殊案例 起点就是终点** print(0) else: print("No Solution")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
3.买卖股票的最佳时机
示例1:
思路分析:
这里题目要求找到一次交易能获得的最大利润
不难想到,找到最大和最小的极差即可,但这里要注意,要先买入才能卖掉,所以极大要出现在极小之后,所以目标就是找到区间内存在的极差,再选择所有区间内极差的最大值
①暴力法:超时
分别假设每一天买入股票后,遍历之后每一天,找到极差最大值
class Solution:
def maxProfit(self, prices: list[int]) -> int:
n=len(prices)
res=0
for i in range(n):
for j in range(i+1,n):
res=max(0,prices[j]-prices[i])
return res
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
②贪心法:
当利润小于0时,舍弃之前的股票,买入当前股票并计算接下去时间段内能达到的最大利润
具体实现:
-
构造差分数组profit:
profit[i]——记录prices[i+1]和prices[i]之间的差值,即为利润
-
记录当前总利润sum:
- 如果sum≤0,说明前面一段时间的总买卖是亏损的,不管profit[i]等于多少,都让sum=profit[i],表示摒弃前面买的,重新买入当前新的股票,与明天进行差分,计算利润profit,并继续判断sum
- 如果sum≥0,说明之前买卖的股票盈利,在此基础上,加上今天与明天的差分profit,继续判断sum
图解算法:
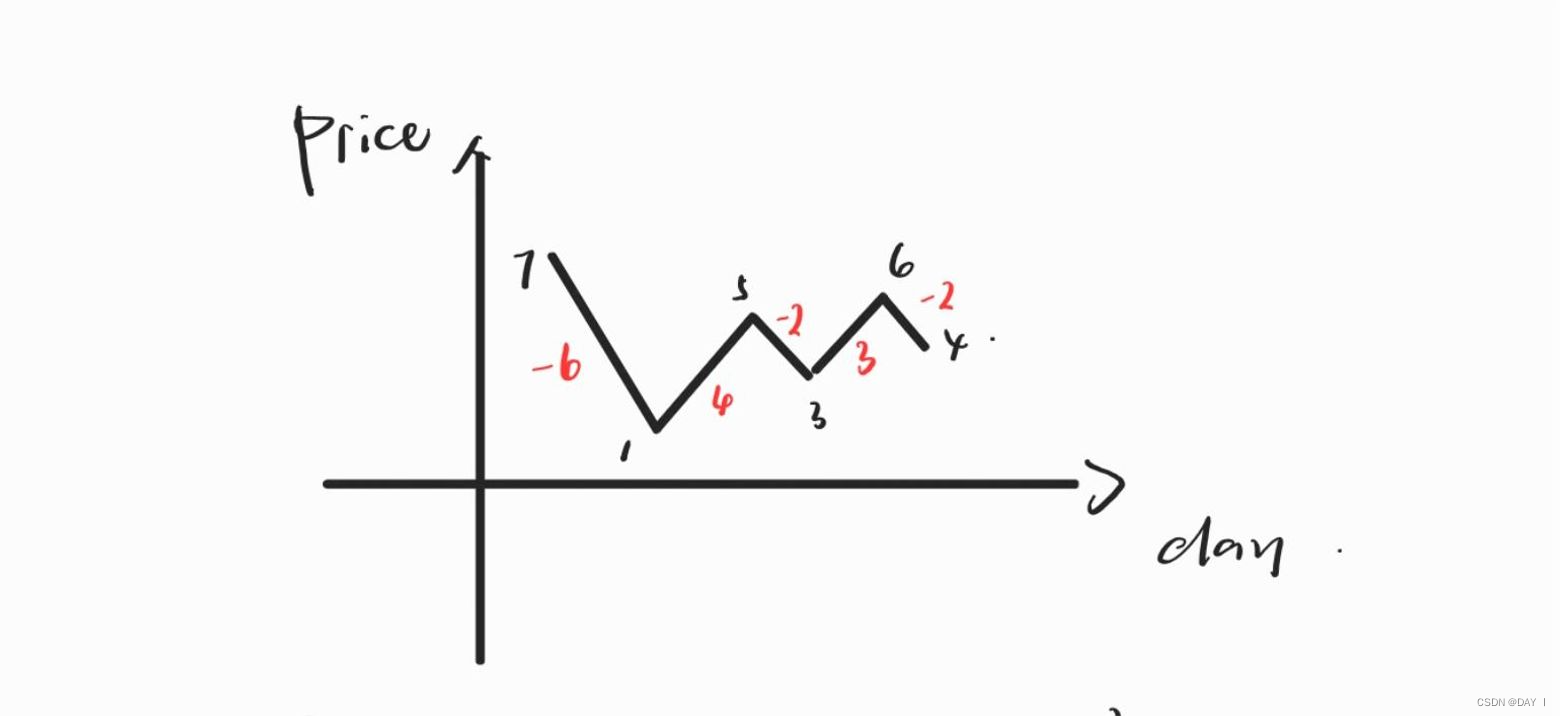
贪心+差分:
class Solution: def maxProfit(self, prices: list[int]) -> int: n=len(prices) # 差分数组 profit = [] for i in range(1,n): profit.append(prices[i]-prices[i-1]) # 求一次交易能达到的最大利润 sum=0 res=-1 for i in range(n-1): if sum>0: sum+=profit[i] else: sum=profit[i] if sum>res: res=sum res=max(0,res) return res
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
示例2:
思路分析:
这里和上一道题有所不同的是,此时的最大利润是所有买卖的到利润的总和,可以来自多次交易
- 因此,我们需要求得所有买卖获利的情况,计算他们的总和
贪心法:
每一轮买卖都要求得盈利最大的情况,也就是只要第二天股票价格变低,立刻选择在今天卖出,保持当前所获利润最大,如果仍处于上升趋势,则继续获利
- 也就是要获得所有股票上升的区段,并求得利润总和
具体实现:
-
利用pre来定位上升的起点
-
比较之后天的prices和pre:
-
若prices[i]-pre>0:
res+=prices[i]-pre并继续判断
-
若prices[i]-pre≤0:
pre=prices[i]更新pre指向新起点,重新判断
-
图解算法:
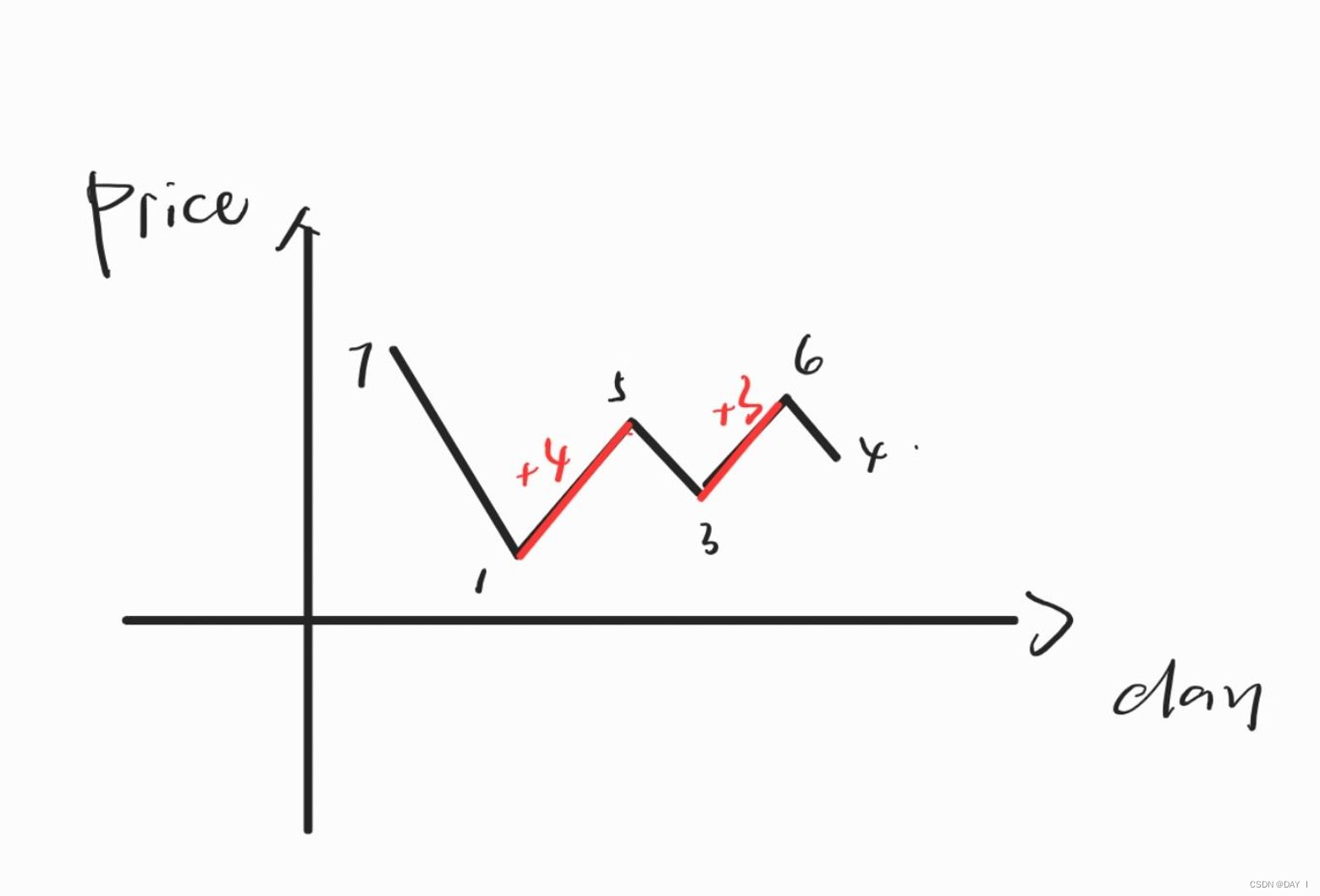
class Solution:
def maxProfit(self, prices: list[int]) -> int:
res=0
pre=prices[0]
n=len(prices)
for i in range(1,n):
if prices[i]>pre:
res+=prices[i]-pre
pre=prices[i]
else:
pre=prices[i]
return res
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
4.哈夫曼编码
在了解哈夫曼编码之前,我们先了解不同类型的编码方式:
(1)固定长度编码:不同字符之间用相等长度的二进制位表示
(2)可变长度编码:允许不同字符用不同长度的二进制位表示
(3)前缀编码:没有一个编码是另一个编码的前缀:
例如:不可能出现1,10,101这种以另一个二进制数为前缀的编码
(4)哈夫曼编码:字符集中的每一个字符作为一个叶子节点,各个字符出现的频度作为权值,构造哈夫曼树——也是一种前缀编码
二义性:
可以观察下列编码方式(非前缀编码):
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GhFEzD2l-1680427564756)(https://s3-us-west-2.amazonaws.com/secure.notion-static.com/6480921d-e582-4d38-8e46-aaf2de68f035/Untitled.png)]](https://img-blog.csdnimg.cn/31d97afaee22463481f275ac04a89c05.png)
可以看到,对一段非前缀编码数字解码时,通过不同的拆解方式,得到的解码也不相同,这是因为d,c具有相同的前缀,所以导致01和010只相差一位,就可以得到不同解
①哈夫曼编码: 是一种十分有效的编码方法,广泛用于数据压缩中,其压缩率通常在 20%~90% 之间。采用不等长编码使编码不会有歧义也就是无二义性,并且和等长编码相比更加节省空间
其中,贪心算法 的主要思路是通过每次查找最小权和次小权构建叶子节点,叶子节点的和作为父节点的权值,如此循环下来构成一棵完全二叉树,对应的左子树编码为0,右子树编码为1,通过遍历树即可得出最终的哈夫曼编码
实现方式:
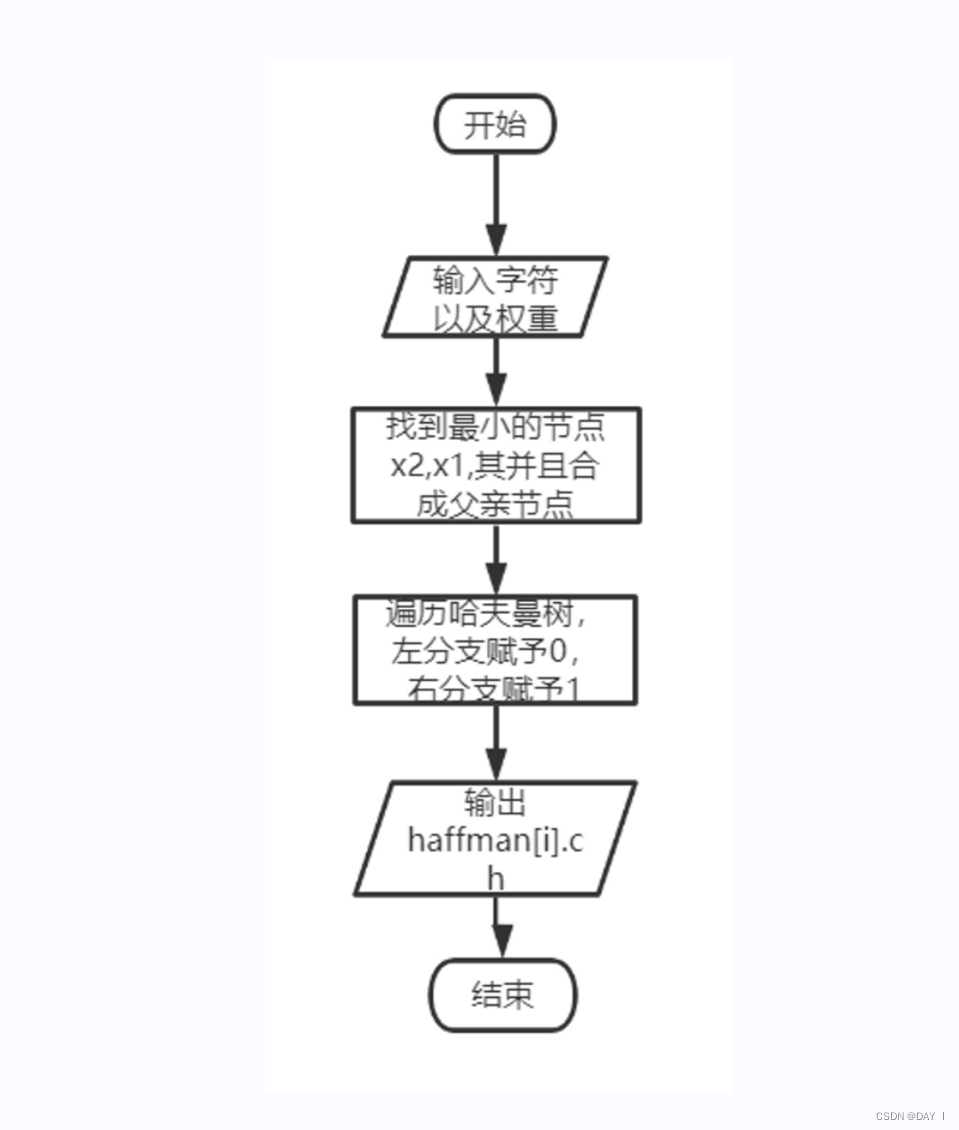
图解算法:
1.若已经得到了各初始字母结点的权值:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rocI8lwq-1680427564756)(https://s3-us-west-2.amazonaws.com/secure.notion-static.com/e090c65c-be37-4d68-b058-000d1b8ea992/Untitled.png)]](https://img-blog.csdnimg.cn/1722df941f1349bc85c9b56258d8c3c7.png)
2.选取最小的两个权值作为叶子节点(f,e),他们的和作为父节点
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NZEtEJQN-1680427564757)(https://s3-us-west-2.amazonaws.com/secure.notion-static.com/ef6eafd9-8aaa-473d-a5fc-9c7e01533e2c/Untitled.png)]](https://img-blog.csdnimg.cn/86c20d0085004251bf578907ffba40ce.png)
3.重复(2)中操作,直到所有结点均成为一棵完全二叉树上的叶子节点为止:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-182tlNtU-1680427564758)(https://s3-us-west-2.amazonaws.com/secure.notion-static.com/95d8f99d-f048-4c2b-8f92-62f3eb8614f5/Untitled.png)]](https://img-blog.csdnimg.cn/66f9eea21313447bafd90c980a690481.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4sFkLHnY-1680427564758)(https://s3-us-west-2.amazonaws.com/secure.notion-static.com/2b9a3036-83d3-4a50-9a00-a322e03d7116/Untitled.png)]](https://img-blog.csdnimg.cn/495670f91ef049b183116d411ccd9108.png)
a,c,d,e,f 最终全部变为叶子节点,由此,按照左边为0,右边为1的规则走,可以通过走过边上的数字组合成为二进制数,最终得到各字母的哈夫曼编码**
②哈夫曼编码的性质:
(1)每一个给定的初结点最后都会成为叶子结点,所以,权值越小,到根节点的路径长度也就越大
(2)假设初始时给定n个结点,由于要结合n-1次,每结合一次都会新增一个结点,因此,哈夫曼树的结点数为 2n-1 个
(3)哈夫曼树中不存在度为1的结点(也就是完全二叉树)
(4)哈夫曼树并不唯一,但所有哈夫曼树的带权路径长度一定是相同的
③哈夫曼树的引例:
- 可以看一个有意思的例子,来具体了解一下哈夫曼编码:
若有100道选择题,其中有60个A,20个B,15个C和5个D,两个人想要在考试中作弊,希望通过一种暗号进行传递,他们规定短为0,长为1,那么,应该如何设计编码使得传递更高效呢?
思路分析:
由题设可以分别确定A B C D的权值,因此,我们只用构造哈夫曼树即可:
| A | B | C | D | |
|---|---|---|---|---|
| 频次(权值) | 60 | 20 | 15 | 5 |
| 定长编码 | 000 | 001 | 010 | 011 |
| 哈夫曼编码 | 0 | 10 | 110 | 111 |
所以: A—0,B—10,C—110,D—111
那么它高效在哪呢?
对比定长编码,我们可以知道,100道题:
定长编码需要敲击桌子 300次,很难不被监考老师发现;
而哈夫曼编码只用敲击桌子 60x1+20x2+15x3+5x3= 160次,这大大降低了被发现的可能,所以得出结论:哈夫曼编码——好!
代码实现:
一.哈夫曼树的构造:
-
先将结点初始化:用二位数组记录它的结点名和权值
结构:arr=[结点名,权值]
-
构造哈夫曼树:
-
贪心法:
①不断处理结点数组—arr,直到arr内结点全部合并为一棵树
②每一轮循环,都让arr重新根据权重排序,从小到大
③排序后,选出最小的两个结点arr[0],arr[1]分别作为右节点r和左节点(也可以反过来)
-
将贪心选择出来的左右结点/子树合并为一棵树:
①如果当前队列(数组)里还有两个以上的节点个数:
将左右子树的结点名称合并,值相加,得到新的父结点:
1.tree增加一个键值对:
tree[ l[0]+r [0]]={‘left’: l, ‘right’: r}
树内键值对结构——字典套字典套列表:
{
树名(即树下所有结点名相加) :
{
left:【左子树/左叶子结点名, 左子树/左结点值】,
right:【右子树/右叶子结点名, 右子树/右结点值】
}
}
2.arr添加新结点——入队:
arr.append([l[0] + r[0], l[1] + r[1]])3.让左右这一轮选出的左右结点出队:
arr=arr[2:]②如果只剩下两个结点:
根据权值大小直接作为左右结点,并定义该树的根节点 ‘root’
-
# 1.初始化 s=list(input().split()) w=list(map(int,input().split())) # 构造一个嵌套列表存储每一个结点 arr = [[s[i], w[i]] for i in range(len(s))] # # [[结点:值],...]==[['a', 60], ['b', 20], ['c', 15], ['d', 5]] # 2.构造哈夫曼树——**字典套字典套列表** tree = {} while len(arr) > 1: **# 1 根据权重排序——从小到大** arr.sort(key=lambda x: x[1]) **# 2 选出最小的两个节点,分别作为左子树,右子树** r = arr[0] # 小的为右子树 l = arr[1] # 大的为左子树 if len(arr) > 2: # 将左子树和右子树的结点汇总,构成新的树 tree[l[0] + r[0]] = {'left': l, 'right': r} # 3.将最小权值的两个结点出队 arr = arr[2:] arr.append([l[0] + r[0], l[1] + r[1]]) else: # 只剩下一个结点和一棵树 tree['root'] = {'left': l, 'right': r} break
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
二.哈夫曼编码:
定义哈夫曼编码函数:
-
传入参数:
-
now_root : 传入构造的tree中,当前根节点(键)对应的值:
注意:这里的now_root为字典,储存这根下的左右子树,如:初始时now_root=tree[’root’],now_root为{‘left’: [‘bdc’, 40], ‘right’: [‘a’, 60]}
可以看到,now_root实际上是字典,使用时要注意用法
-
tree : 传入树本身
-
code:code=’’ 实际上是默认参数,不传实参时,默认为空字符;传实参时,值为实参
-
huffmancode:huffmancode={} 也为默认参数,用于记录结点对应的编码
-
-
dfs:
分别深根遍历左子树和右子树(方法类似),以左子树为例:
①当左子树不为叶子结点时:
即now_root[’left’][0]≠1:
解释:之前强调过,now_root实际上是存有左右子树信息的字典,而子树中字典的值又是一个列表,所以now_root[’left’] 先取出了 左子树信息的列表,再根据列表索引 …[0] 将左子树名取出,由于树的名称长度代表了树下有多少个结点,所以>1即表示不为叶子结点
-
这里选择每第一次到达某层就更新编码值,所以为右加 ’0’:
定义当前的
huffman_code=code+'0' -
由于不是叶子结点,继续递归:
huffman(tree[now_root['left'][0]],tree,huffman_code)
- tree[now_root[’left’][0]]——在tree树中找到键为左子树名称所对应的值(字典)
- 传入更新后的huffman_code
②当左子树为叶子结点时:
加上该边的二进制编码值 ’0’ ,并更新huffmancode字典中对应结点的编码值,结束
-
同理,继续对右子树操作,最终函数返回 huffmancode
**# 函数先传入默认参数** def huffman(now_root,tree,code='',huffmancode={}): # 1.dfs左子树 # 如果左子树不为叶子结点 if len(now_root['left'][0])!=1: huffman_code=code+'0' # 当前的哈夫曼编码加上'0' huffmancode=huffman(tree[now_root['left'][0]],tree,huffman_code) # 继续dfs # 如果左子树为叶子结点 else: huffman_code=code+'0' huffmancode[now_root['left'][0]]=huffman_code # 2.dfs右子树 # 如果右子树不为叶子结点 if len(now_root['right'][0])!=1: huffman_code=code+'1' # 当前的哈夫曼编码加上'1' huffmancode=huffman(tree[now_root['right'][0]],tree,huffman_code,huffmancode) # 继续dfs # 如果右子树为叶子结点 else: huffman_code=code+'1' huffmancode[now_root['right'][0]]=huffman_code return huffmancode
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
完整代码:
def huffman(now_root,tree,code='',huffmancode={}): # 1.dfs左子树 # 如果左子树不为叶子结点 if len(now_root['left'][0])!=1: huffman_code=code+'0' # 当前的哈夫曼编码加上'0' huffmancode=huffman(tree[now_root['left'][0]],tree,huffman_code) # 继续dfs # 如果左子树为叶子结点 else: huffman_code=code+'0' huffmancode[now_root['left'][0]]=huffman_code # 2.dfs右子树 # 如果右子树不为叶子结点 if len(now_root['right'][0])!=1: huffman_code=code+'1' # 当前的哈夫曼编码加上'1' huffmancode=huffman(tree[now_root['right'][0]],tree,huffman_code,huffmancode) # 继续dfs # 如果右子树为叶子结点 else: huffman_code=code+'1' huffmancode[now_root['right'][0]]=huffman_code return huffmancode **# 1.初始化** s=list(input().split()) w=list(map(int,input().split())) # 构造一个嵌套列表存储每一个结点 arr = [[s[i], w[i]] for i in range(len(s))] # # [[结点:值],...]==[['a', 60], ['b', 20], ['c', 15], ['d', 5]] **# 2.构造哈夫曼树——字典套字典套列表** tree = {} while len(arr) > 1: # 1 根据权重排序——从小到大 arr.sort(key=lambda x: x[1]) # 2 选出最小的两个节点,分别作为左子树,右子树 r = arr[0] # 小的为右子树 l = arr[1] # 大的为左子树 if len(arr) > 2: # 将左子树和右子树的结点汇总,构成新的树 tree[l[0] + r[0]] = {'left': l, 'right': r} # 3.将最小权值的两个结点出队 arr = arr[2:] arr.append([l[0] + r[0], l[1] + r[1]]) else: # 只剩下一个结点和一棵树 tree['root'] = {'left': l, 'right': r} break **# 3.对所给字符进行哈夫曼编码** huffmancode=huffman(tree['root'],tree) print("树:",tree) # 打印哈夫曼树 print("\\n对应编码:",huffmancode) # 打印哈夫曼编码 # 输出: 树: {'cd': {'left': ['c', 15], 'right': ['d', 5]}, 'cdb': {'left': ['cd', 20], 'right': ['b', 20]}, 'root': {'left': ['a', 60], 'right': ['cdb', 40]}} 对应编码: {'a': '0', 'c': '100', 'd': '101', 'b': '11'}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
以下为图论中的应用:
5.最小生成树—prim算法
首先,要了解一些基本概念:
(1)连通图的生成树是指:包含图中全部顶点,边尽可能少,但要连通的树
(2)最小生成树:为带权的连通无向图
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-AJ9EZAiK-1680427564759)(https://s3-us-west-2.amazonaws.com/secure.notion-static.com/2aaaaa44-ec43-4f91-af21-201d73af3e6a/Untitled.jpeg)]](https://img-blog.csdnimg.cn/dc8a4bee506b4d599e7d37d5396437e7.png)
①最小生成树的性质:
- 不唯一,但权值和相同
- 边数=顶点数-1
- 如果一个连通图本身就是树,则它本身就是一棵最小生成树
②prim算法:
Prim算法又称为"加点法",每次找出距离最小的边对应的点(此处的距离指的是未加点到最小生成树的距离),算法从某一个顶点s开始,逐渐将剩余n个点纳入最小生成树中
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-indn6SKR-1680427564759)(https://s3-us-west-2.amazonaws.com/secure.notion-static.com/25c4a52a-6db8-4a23-9519-31483208a767/Untitled.png)]](https://img-blog.csdnimg.cn/dbf31c23755c4786b4d98320a8e2153b.png)
③prim算法的步骤:
-
第一步:设图中所有顶点的集合为V,u代表已经加入最小生成树的顶点的集合,v代表未加入最小生成树的顶点的集合,由于从某点s开始,因此初始化:
u={s},v={V-u} -
第二步:在两个集合u,v中选择一条代价最小的边,将在v中连接这条边的那个顶点x加入到最小生成树顶点集合u中,并且更新与x相连的所有邻接点的权值
-
第三步:重复上述第二步,直到最小生成树顶点集合u中有n个顶点为止
最终目标:
u={V},v={}
图解算法:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hHmtk610-1680427564760)(https://s3-us-west-2.amazonaws.com/secure.notion-static.com/50819bbd-f235-4d86-91b2-debe764f986b/Untitled.png)]](https://img-blog.csdnimg.cn/0159bfbb55b349cd9ef1c24d5f0a1a26.png)
-
这是一张初始的无向图,以0作为起点,集合u={0},v={1,2,3,4,5,6}
-
构造min[]数组:索引表示图中结点,对应的值表示未加入的点到当前得到的最小生成树的最短距离*(即到最小生成树中点的最小距离)*
min的初始化:标记起点为0,其余点初始化为inf
-
加入起点0后,更新树组中与0相邻的点 1 和 3 的值
u={0},v={1,2,3,4,5}
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3raMggzV-1680427564760)(https://s3-us-west-2.amazonaws.com/secure.notion-static.com/f0d539ff-e29c-4b52-a745-771cd9237e18/Untitled.png)]](https://img-blog.csdnimg.cn/69d5b63e8525449eb63557afbb50b46f.png)
-
由于更新后数组中最小权值为5,则选择加入与0相邻的点 3
u={0,3},v={1,2,4,5}
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-G2D5r15o-1680427564760)(https://s3-us-west-2.amazonaws.com/secure.notion-static.com/d42190f3-4d4c-4f83-9237-89f2c15f9644/Untitled.png)]](https://img-blog.csdnimg.cn/a8c6306febdb414188304a1dc26788f8.png)
-
加入点3后,只用检查与3相邻的所有点到3的权值并更新即可 (因为与0相邻的所有点已经检查过,只用更新新加入点到相邻点的权值即可),而当选择下一个加入点时,是对所有u集合内的点进行搜查的,最终选择点 1
u={0,1,3},v={2,4,5}
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kOEg0kti-1680427564761)(https://s3-us-west-2.amazonaws.com/secure.notion-static.com/e2fd33ac-2aeb-43ce-aa6b-2a3fc1e7c204/Untitled.png)]](https://img-blog.csdnimg.cn/de0659b887aa49ca83cd4c0139d6c83b.png)
-
重复上述操作,直到所有点多加入最小生成树中为止
u={0,1,2,3,4,5},v={}
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-oualIV5O-1680427564761)(https://s3-us-west-2.amazonaws.com/secure.notion-static.com/1d637492-4819-496e-a54c-249dc12df719/Untitled.png)]](https://img-blog.csdnimg.cn/a84f62ad648949cc9b40390f798e7201.png)
对上述过程的min数组:
| min | 0 | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|---|
| ① | 0 | ∞ | ∞ | ∞ | ∞ | ∞ | ∞ |
| ② | 0 | 8 | ∞ | 5 | ∞ | ∞ | ∞ |
| ③ | 0 | 3 | ∞ | 5 | ∞ | 7 | 15 |
| ④ | 0 | 3 | 12 | 5 | 10 | 7 | 15 |
| ⑤ | 0 | 3 | 2 | 5 | 9 | 7 | 15 |
| ⑥ | 0 | 3 | 2 | 5 | 6 | 7 | 15 |
示例(模板题):
最小生成树(MST)
这里给几个样例:
# 样例一 4 5 1 2 2 1 3 2 1 4 3 2 3 4 3 4 3 ————>7 # 样例二 5 18 2 4 276 3 3 435 3 4 608 2 4 860 1 2 318 1 3 547 5 4 419 2 5 98 1 5 460 5 3 399 3 5 240 3 2 733 3 3 903 4 2 909 5 2 206 3 4 810 2 1 115 2 3 419 ————>729 # 样例三 6 10 1 2 6 1 3 1 1 4 5 2 3 5 2 5 3 3 4 5 3 5 6 3 6 4 4 6 2 5 6 6 ————>15
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
思路分析:
思路参考:Prim算法_CSDN博客_prim算法
prim算法的思路在之前已经叙述过,但要实现仍要做一些准备,代码解释如下:
-
lowcost[i]: 表示以 i为终点的边的最小权值
当lowcost[i]=0 说明以i为终点的边的最小权值=0,也就是表示i点加入了MST
-
mst[i]: 表示对应lowcost[i]的起点,边<mst[i],i>是MST的一条边,即点i的最小权值边在MST中对应的点(最小权值边的另一个点)
当mst[i]=0 表示起点i加入MST
-
graph[i][j]:这里用邻接矩阵存储
邻接矩阵:为对称矩阵,graph[i][j]=graph[j][i]的值表示边<i,j>对应的权值
注意有坑:因为可能存在两点之间有多条重复的边,选最小的即可
-
min:表示此轮prim找到的最小边的权值
贪心法:每一轮都会选择一个与MST相连的最小权值边和对应的点加入MST,min则表示边的权值
-
minid:表示此轮prim加入MST的点
-
初始化:
- 先将graph的第一行赋值给lowcost,表示以1为起点的MST的初始状态,并初始化lowcost[1]=0,因为点1已经在MST中了;
- 将mst赋值为1,mst[1]=0,表示除点1外的其他点当前的最小权值边都是以1为起点来初始化的,而此时点1已经在MST中了
-
将所有点加入到MST中(遍历n-1轮):
-
找到与当前MST连接的最小权值边:
每一轮先让min为∞,minid为0(如果循环结束仍为0,表示该图不连通)
对所有点进行遍历,如果点 j对应边的最小权值小于min,结束后则更新min的值,并将 j赋值给minid,结束后则将minid加入MST
…
if lowcost[j] < min and lowcost[j] != 0:min = lowcost[j]; minid = j;sum+=minlowcost[minid]=0…
当前的lowcost[j]如果小于min,由于不为∞,则既表示和MST有连接边,又表示为较小的权值边;而lowcost[j]!=0即表示点 j不在MST中;则循环一轮后表示 j为即将加入MST的点,min为此轮的最小权值
-
更新lowcost:
因为新加入一个点,所以有些点的最小权值会改变,由于加入点为minid,相当于解锁了graph[minid][],即根据graph表可得minid所连接的所有点对应边的权值,只用更新比当前lowcost小的即可
-
prim:
(空间爆了3个,邻接表存储空间大)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RXqCppNE-1680427564761)(https://s3-us-west-2.amazonaws.com/secure.notion-static.com/b8f93f88-c841-4889-8475-157ec1b4abfb/Untitled.png)]](https://img-blog.csdnimg.cn/ca7aace121a44d2c876550dbda5bbf9e.png)
global n,m,graph def prim(p): # 1.初始化 sum=0 lowcost=[-1 for _ in range(n+1)] # mst=[1 for _ in range(n+1)] # mst[1]=0 # 初始化点1 lowcost[1]=0 for i in range(2,n+1): lowcost[i]=graph[1][i] # 2.加入所有点 for i in range(n-1): min=float('inf') minid=0 for j in range(2,n+1): if lowcost[j]<min and lowcost[j]!=0: min=lowcost[j] minid=j if minid==0: return -1 # print(f"{mst[minid]}->{minid}={min}") # 打印MST加入的新边 sum+=min lowcost[minid]=0 for k in range(2,n+1): if lowcost[k]>graph[minid][k] and lowcost[k]!=0: # 判断不在树内的点k对应的lowcost[k]是否可以得到更小值 lowcost[k]=graph[minid][k] # mst[k]=minid # 更新点k对应的最小权值边在MST中对应的点 return sum n,m=map(int,input().split()) # n为点个数,m为边个数 # 1.构造邻接矩阵,从(1,1)开始存图 graph=[[float('inf')]*(n+1) for i in range(n+1)] for i in range(1,m+1): p1,p2,wi=map(int,input().split()) if wi<graph[p1][p2]: # 这里有坑,因为可能存在两点之间有多条重复的边,选最小的即可 graph[p1][p2]=wi graph[p2][p1]=wi # 2.prim res=prim(1) if res==-1: print('orz') else: print(res)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
6.单源最短路径—Dijkstra算法
首先要了解:
①单源最短路径:
对于有向带权图G=(V,E),其中每条边的权值都是非负 实数,给定V中的一个节点(称为源点),计算源点到其他各节点之间的最短路径,即单源最短路径
②Dijkstra算法:
Dijkstra算法是解决单源最短路径问题的**贪心算法:**Dijkstra算法基本思路是先求出源点 离当前节点最短的一条路径,然后根据当前最短路径末端点能够到达的点,求出下一条离源点最近的路径,直到求出源点到其他各节点的最短路径
定理:最短路径的子路径仍然是最短路径
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Z60c6AEB-1680427564761)(https://s3-us-west-2.amazonaws.com/secure.notion-static.com/ce4d9605-cb77-41d1-bf00-6c9970622697/Untitled.jpeg)]](https://img-blog.csdnimg.cn/b5374b52bc31443f87266d71f2db3634.png)
-
如图,源点A到C的最短路径为9:A→E→B→C,经过了B点,则此最短路径中从源点到B点的子路径一定是所有从源点到B点的路径中最短的那条
因为若为最短路径d,则一定要求所经过的点每一步都是最短的,否则不可能成立:
反证法:已知源点到点C的最短路径为 d,到我们假设到点B的子路径 L1不是B的最短路径,那么一定存在 L2<L1使得源点到B点最短,则当前d=L1+L(B→C)> L2+L(B→C),所以得出d不是最短路径,与题设不符,假设不成立
③Dijkstra算法的步骤:
- 找出从起点出发,可以前往的,路径最短的未处理点
- 对于该结点的邻接点,检查是否有前往他们的更短路径,如果有,则更新其最短路径
- 将该结点加入已处理队列中,后续不再处理该结点
- 重复1-4步,直到对图中除了终点的所有结点都进行了检查
- 得到最终路径
算法分析:
我们需要先构造三个数组:
- final[]: 标记各顶点是否已经找到最短路径
- dist[]:表示源点到该点的最短路径长度
- path[]: 当前到该点路径上的前驱
具体步骤:
- 初始化:
| A | B | C | D | E | |
|---|---|---|---|---|---|
| final[] | True | False | False | False | False |
| dist[] | 0 | 10 | ∞ | ∞ | 5—最小 |
| path[] | -1 | 0 | -1 | -1 | 0 |
- 第一轮寻找:
①循环遍历所有结点,找到还未确定最短路径且dist最小的结点vi
令final[vi]=True,表示vi已经找到了最短路径—d0=dist[vi]
②检查所有与vi相连的结点,若还未确定最短路径,则更新path与dist的值
更新为d=d0+wi
则有:
| A | B | C | D | E | |
|---|---|---|---|---|---|
| final[] | True | False | False | False | True |
| dist[] | 0 | 8 | 14 | 7—最小 | 5 |
| path[] | -1 | 4 | 4 | 4 | 0 |
-
第二轮寻找:
在余下未确定最短路径的所有点中,以dist最小的未顶点vi,重复上述操作:
| A | B | C | D | E | |
|---|---|---|---|---|---|
| final[] | True | False | False | True | True |
| dist[] | 0 | 8—最小 | 13 | 7 | 5 |
| path[] | -1 | 4 | 3 | 4 | 0 |
| A | B | C | D | E | |
|---|---|---|---|---|---|
| final[] | True | True | False | True | True |
| dist[] | 0 | 8 | 9—最小 | 7 | 5 |
| path[] | -1 | 4 | 4 | 4 | 0 |
-
最后寻找:
已经找不到其他为False的结点,将所有的结点设为True,返回数组
| A | B | C | D | E | |
|---|---|---|---|---|---|
| final[] | True | True | True | True | True |
| dist[] | 0 | 8 | 9 | 7 | 5 |
| path[] | -1 | 4 | 4 | 4 | 0 |
示例1(模板题):
n, m = map(int, input().split()) maxdist = float("inf") g = [[maxdist] * (n+1) for _ in range(n+1)] # 由于是密集图,m>>n,因此用邻接矩阵来存储,g[x][y]表示x指向y的距离 d = [maxdist] * (n+1) # 存储每个点距离起点的距离,初始化为距离最大,d[1]=0 st = [False] * (n+1) # 判断某一点的最短距离是否已经确定,False表示未确定,True表示确定 def dijkstra(): d[1] = 0 for i in range(1, n+1): # 因为要确定n个点的最短路,因此要循环n次 t = -1 for j in range(1, n+1): # 每次找到还未确定最短路的点中距离起点最短的点t if not st[j] and (t==-1 or d[t]>d[j]): t = j st[t] = True for j in range(1, n+1): # 用t来更新t所指向的点的距离 d[j] = min(d[j], d[t] + g[t][j]) if d[n] >= maxdist: return -1 else: return d[n] for _ in range(m): x, y, z = map(int, input().split()) g[x][y] = min(g[x][y], z) # 当出现重边时,只需取两个距离中的最小值 print(dijkstra())
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
示例2:
def dijkstra(A): # 1.初始化 final=[False for _ in range(n+1)] # dist存到该点需要的最少钱 dist=[float('inf') for _ in range(n+1)] dist[A]=100 # 2.dijkstra for _ in range(n): # 必须要将所有点遍历完才能结束算法 min=float('inf') node=0 for j in range(1,n+1): # 遍历所有点 if final[j]!=True and dist[j]<min: # 如果未被访问过 # 找出每一轮循环的最小值 min=dist[j] node=j final[node]=True # node为该轮的最小点,更新所连点的最小费用 for k in range(1,n+1): if graph[node][k]<float('inf'): #如果node和k有边 fare=dist[node]/(1-graph[node][k]) # node到k点的费用 if fare<dist[k]: # 如果费用比当前少 dist[k]=fare # 更新最少费用 return dist[B] # 1.初始化 n,m=map(int,input().split()) # graph扣除率 graph=[[float('inf')]*(n+1) for i in range(n+1)] # 邻接矩阵 for i in range(m): x,y,z=map(int,input().split()) if graph[x][y]>z: graph[x][y]=z*0.01 graph[y][x]=z*0.01 A,B=map(int,input().split()) # 2.dijkstra print("%.8f"%dijkstra(A)) 当出现重边时,只需取两个距离中的最小值 print(dijkstra())
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
3.总结
本章主要讲解了贪心算法的众多实际应用,包括找零,背包,编码以及图论相关的算法,后续仍会持续更新一些其他常见的算法,如果有错误请欢迎指正~~,感谢!!!
觉得本篇有帮助的话, 就赏个三连吧~


