
- 12024年Top5 后端NodeJS框架评估_node. js框架使用排名
- 2CPU的状态--内核态、用户态_用户模式的cpu
- 3vue+elementUI 通用模板组件form+button+table_vue表单样式模板
- 4navicat使用及SQL查询语法_navicat查询语句
- 5MySQL:ERROR 1698 (28000): Access denied for user ‘root’@’localhost’_error 1698 (28000): access denied for user 'root'@
- 6STM32C8T6控制智能小车代码_小车运动代码单片机
- 7Java IO:字节流、字符流、缓冲流分析及案例说明_java字符流和字符缓冲流复制文本的区别
- 8【硬件+代码】STM32 智能家居系统设计+原理图+设计报告_画出一个stm32实践项目的系统框图
- 9NVM下载、安装和配置教程-2023年12月18日
- 10蓝桥杯 — — 纯质数
apache mysql python win10_Canal+Kafka实现MySQL与Redis数据同步
赞
踩
思维导图
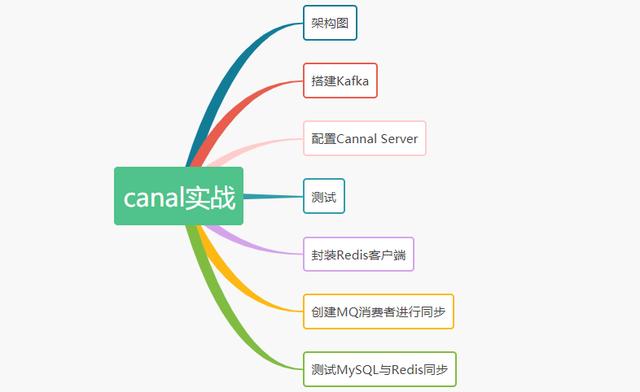
前言
在很多业务情况下,我们都会在系统中加入redis缓存做查询优化。
如果数据库数据发生更新,这时候就需要在业务代码中写一段同步更新redis的代码。
这种数据同步的代码跟业务代码糅合在一起会不太优雅,能不能把这些数据同步的代码抽出来形成一个独立的模块呢,答案是可以的。
架构图
canal是一个伪装成slave订阅mysql的binlog,实现数据同步的中间件。上一篇文章《canal入门》
我已经介绍了最简单的使用方法,也就是tcp模式。
实际上canal是支持直接发送到MQ的,目前最新版是支持主流的三种MQ:Kafka、RocketMQ、RabbitMQ。而canal的RabbitMQ模式目前是有一定的bug,所以一般使用Kafka或者RocketMQ。
本文使用Kafka,实现Redis与MySQL的数据同步。架构图如下:
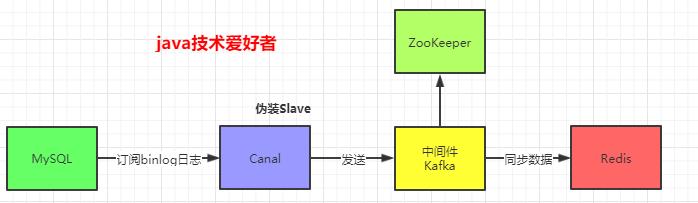
通过架构图,我们很清晰就知道要用到的组件:MySQL、Canal、Kafka、ZooKeeper、Redis。
下面演示Kafka的搭建,MySQL搭建大家应该都会,ZooKeeper、Redis这些网上也有很多资料参考。
搭建Kafka
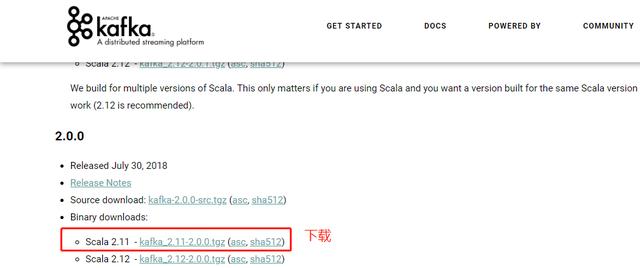
首先在官网下载安装包:
解压,打开/config/server.properties配置文件,修改日志目录:
log.dirs=./logs首先启动ZooKeeper,我用的是3.6.1版本:
接着再启动Kafka,在Kafka的bin目录下打开cmd,输入命令:
kafka-server-start.bat ../../config/server.properties我们可以看到ZooKeeper上注册了Kafka相关的配置信息:
然后需要创建一个队列,用于接收canal传送过来的数据,使用命令:
kafka-topics.bat --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic canaltopic创建的队列名是canaltopic。

配置Cannal Server
canal官网下载相关安装包:
找到canal.deployer-1.1.4/conf目录下的canal.properties配置文件:
# tcp, kafka, RocketMQ 这里选择kafka模式canal.serverMode = kafka# 解析器的线程数,打开此配置,不打开则会出现阻塞或者不进行解析的情况canal.instance.parser.parallelThreadSize = 16# 配置MQ的服务地址,这里配置的是kafka对应的地址和端口canal.mq.servers = 127.0.0.1:9092# 配置instance,在conf目录下要有example同名的目录,可以配置多个canal.destinations = example然后配置instance,找到/conf/example/instance.properties配置文件:
## mysql serverId , v1.0.26+ will autoGen(自动生成,不需配置)# canal.instance.mysql.slaveId=0# position infocanal.instance.master.address=127.0.0.1:3306# 在Mysql执行 SHOW MASTER STATUS;查看当前数据库的binlogcanal.instance.master.journal.name=mysql-bin.000006canal.instance.master.position=4596# 账号密码canal.instance.dbUsername=canalcanal.instance.dbPassword=Canal@****canal.instance.connectionCharset = UTF-8#MQ队列名称canal.mq.topic=canaltopic#单队列模式的分区下标canal.mq.partition=0配置完成后,就可以启动canal了。
测试
这时可以打开kafka的消费者窗口,测试一下kafka是否收到消息。
使用命令进行监听消费:
kafka-console-consumer.bat --bootstrap-server 127.0.0.1:9092 --from-beginning --topic canaltopic有个小坑。我这里使用的是win10系统的cmd命令行,win10系统默认的编码是GBK,而Canal Server是UTF-8的编码,所以控制台会出现乱码:
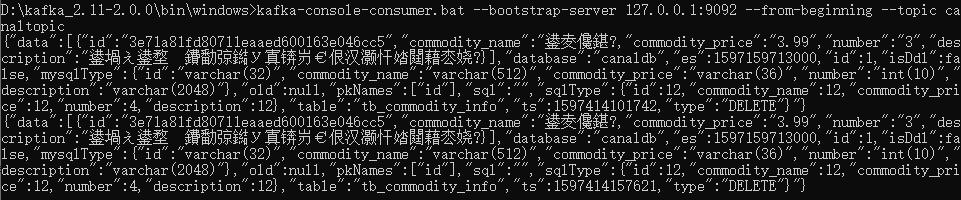
怎么解决呢?
在cmd命令行执行前切换到UTF-8编码即可,使用命令行:chcp 65001
然后再执行打开kafka消费端的命令,就不乱码了:

接下来就是启动Redis,把数据同步到Redis就完事了。
封装Redis客户端
环境搭建完成后,我们可以写代码了。
首先引入Kafka和Redis的maven依赖:
org.springframework.kafka spring-kafka org.springframework.boot spring-boot-starter-data-redis在application.yml文件增加以下配置:
spring: redis: host: 127.0.0.1 port: 6379 database: 0 password: 123456封装一个操作Redis的工具类:
@Componentpublic class RedisClient { /** * 获取redis模版 */ @Resource private StringRedisTemplate stringRedisTemplate; /** * 设置redis的key-value */ public void setString(String key, String value) { setString(key, value, null); } /** * 设置redis的key-value,带过期时间 */ public void setString(String key, String value, Long timeOut) { stringRedisTemplate.opsForValue().set(key, value); if (timeOut != null) { stringRedisTemplate.expire(key, timeOut, TimeUnit.SECONDS); } } /** * 获取redis中key对应的值 */ public String getString(String key) { return stringRedisTemplate.opsForValue().get(key); } /** * 删除redis中key对应的值 */ public Boolean deleteKey(String key) { return stringRedisTemplate.delete(key); }}创建MQ消费者进行同步
在application.yml配置文件加上kafka的配置信息:
spring: kafka: # Kafka服务地址 bootstrap-servers: 127.0.0.1:9092 consumer: # 指定一个默认的组名 group-id: consumer-group1 #序列化反序列化 key-deserializer: org.apache.kafka.common.serialization.StringDeserializer value-deserializer: org.apache.kafka.common.serialization.StringDeserializer producer: key-serializer: org.apache.kafka.common.serialization.StringDeserializer value-serializer: org.apache.kafka.common.serialization.StringDeserializer # 批量抓取 batch-size: 65536 # 缓存容量 buffer-memory: 524288根据上面Kafka消费命令那里,我们知道了json数据的结构,可以创建一个CanalBean对象进行接收:
public class CanalBean { //数据 private List data; //数据库名称 private String database; private long es; //递增,从1开始 private int id; //是否是DDL语句 private boolean isDdl; //表结构的字段类型 private MysqlType mysqlType; //UPDATE语句,旧数据 private String old; //主键名称 private List pkNames; //sql语句 private String sql; private SqlType sqlType; //表名 private String table; private long ts; //(新增)INSERT、(更新)UPDATE、(删除)DELETE、(删除表)ERASE等等 private String type; //getter、setter方法}public class MysqlType { private String id; private String commodity_name; private String commodity_price; private String number; private String description; //getter、setter方法}public class SqlType { private int id; private int commodity_name; private int commodity_price; private int number; private int description;}最后就可以创建一个消费者CanalConsumer进行消费:
@Componentpublic class CanalConsumer { //日志记录 private static Logger log = LoggerFactory.getLogger(CanalConsumer.class); //redis操作工具类 @Resource private RedisClient redisClient; //监听的队列名称为:canaltopic @KafkaListener(topics = "canaltopic") public void receive(ConsumerRecord, ?> consumer) { String value = (String) consumer.value(); log.info("topic名称:{},key:{},分区位置:{},下标:{},value:{}", consumer.topic(), consumer.key(),consumer.partition(), consumer.offset(), value); //转换为javaBean CanalBean canalBean = JSONObject.parseObject(value, CanalBean.class); //获取是否是DDL语句 boolean isDdl = canalBean.getIsDdl(); //获取类型 String type = canalBean.getType(); //不是DDL语句 if (!isDdl) { List tbCommodityInfos = canalBean.getData(); //过期时间 long TIME_OUT = 600L; if ("INSERT".equals(type)) { //新增语句 for (TbCommodityInfo tbCommodityInfo : tbCommodityInfos) { String id = tbCommodityInfo.getId(); //新增到redis中,过期时间是10分钟 redisClient.setString(id, JSONObject.toJSONString(tbCommodityInfo), TIME_OUT); } } else if ("UPDATE".equals(type)) { //更新语句 for (TbCommodityInfo tbCommodityInfo : tbCommodityInfos) { String id = tbCommodityInfo.getId(); //更新到redis中,过期时间是10分钟 redisClient.setString(id, JSONObject.toJSONString(tbCommodityInfo), TIME_OUT); } } else { //删除语句 for (TbCommodityInfo tbCommodityInfo : tbCommodityInfos) { String id = tbCommodityInfo.getId(); //从redis中删除 redisClient.deleteKey(id); } } } }}测试MySQL与Redis同步
mysql对应的表结构如下:
CREATE TABLE `tb_commodity_info` ( `id` varchar(32) NOT NULL, `commodity_name` varchar(512) DEFAULT NULL COMMENT '商品名称', `commodity_price` varchar(36) DEFAULT '0' COMMENT '商品价格', `number` int(10) DEFAULT '0' COMMENT '商品数量', `description` varchar(2048) DEFAULT '' COMMENT '商品描述', PRIMARY KEY (`id`)) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='商品信息表';首先在MySQL创建表。然后启动项目,接着新增一条数据:
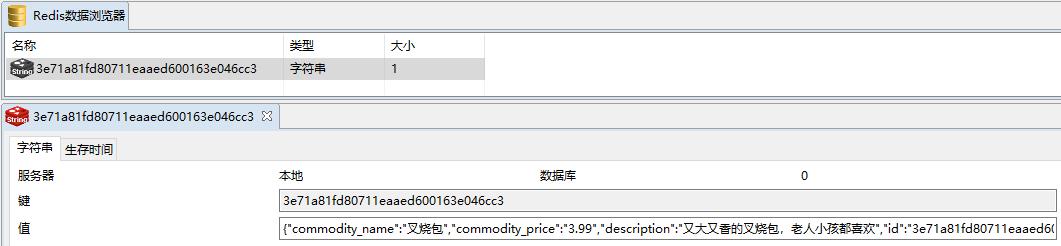
INSERT INTO `canaldb`.`tb_commodity_info` (`id`, `commodity_name`, `commodity_price`, `number`, `description`) VALUES ('3e71a81fd80711eaaed600163e046cc3', '叉烧包', '3.99', '3', '又大又香的叉烧包,老人小孩都喜欢');tb_commodity_info表查到新增的数据:

Redis也查到了对应的数据,证明同步成功!
如果更新呢?试一下Update语句:
UPDATE `canaldb`.`tb_commodity_info` SET `commodity_name`='青菜包',`description`='很便宜的青菜包呀,不买也开看看了喂' WHERE `id`='3e71a81fd80711eaaed600163e046cc3';
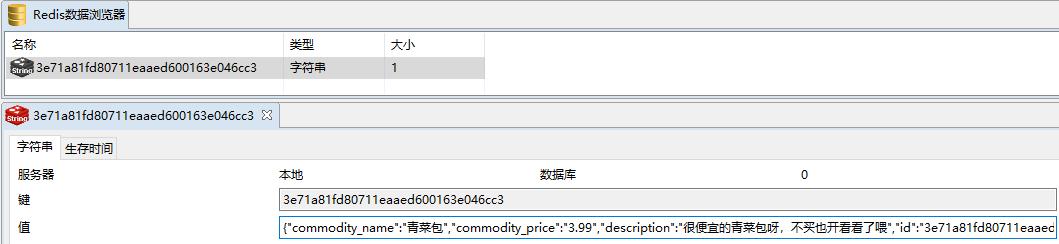
没有问题!
总结
那么你会说,canal就没有什么缺点吗?
肯定是有的:
- canal只能同步增量数据。
- 不是实时同步,是准实时同步。
- 存在一些bug,不过社区活跃度较高,对于提出的bug能及时修复。
- MQ顺序性问题。我这里把官网的回答列出来,大家参考一下。

尽管有一些缺点,毕竟没有一样技术或者产品是完美的,最重要是合适。
我们公司在同步MySQL数据到Elastic Search也是采用Canal+RocketMQ的方式。
参考资料:canal官网
絮叨
上面所有例子的代码都上传Github了:
https://github.com/yehongzhi/mall
如果你觉得这篇文章对你有用,点个赞吧
你的点赞是我创作的最大动力。
想第一时间看到我更新的技术文章,就关注我吧。点个关注,不怕迷路。
拒绝做一条咸鱼,我是一个努力让大家记住的程序员。我们下期再见!!!


