
- 1五层验证系统,带你预防区块链业务漏洞_华为五层防护网
- 2掌握Spark的数据可视化与报告技术
- 3你好Python -- 极简Python教程_我想对你说 python
- 4STM32能不能跑Linux_stm32h743 跑什么系统
- 5pycharm中Git第三方库安装_error: could not find a version that satisfies the
- 6深入浅出深度学习Pytroch_深入浅出深度学习tesla.txt
- 7数据结构——循环队列_循环队列的优点
- 8为什么字节跳动天天在高薪招人,但又很难进,真的缺人吗?
- 9Git及Tortoisegit下载安装及使用详细配置过程_tortoisegit下载远程代码
- 10有什么适合学习爬虫的电子书?_python爬虫电子书
Stable Diffusion WebUI 控制网络 ControlNet 插件实现精准控图-详细教程
赞
踩

本文收录于《AI绘画从入门到精通》专栏,专栏总目录:点这里,订阅后可阅读专栏内所有文章。
大家好,我是水滴~~
本文主要介绍 Stable Diffusion WebUI 一个比较重要的插件 ControlNet(控制网络),主要内容有:ControlNet 的工作原理、如果安装 ControlNet 插件、如何使用 ControlNet 插件、ControlNet 官方的 14 种模型及对应预处理器等。
文章内容包含大量的图例,希望能够帮助新手同学快速入门。
文章目录
- 前言
- 一、ControlNet 的工作原理
- 二、安装 ControlNet 插件
- 三、使用 ControlNet 插件
- 四、ControlNet 模型和预处理器
前言
ControlNet(控制网络)是一种先进的神经网络架构,它为基于扩散模型的 AI 绘画流程引入了精确的控制机制。通过整合额外的条件约束,ControlNet 显著增强了图像生成的可预测性和指导性。
在 ControlNet 的辅助下,用户能够对生成的艺术作品进行细致入微的指导,实现对构图、色彩、风格等多维度因素的把控,从而满足各种复杂场景和个性化需求。
这一技术为 AI 绘画领域带来了革命性的突破,使得 AI 绘画能够更好地满足用户的具体需求,成为一种真正的生产力工具。
下面是 ControlNet 相关的官方地址:
一、ControlNet 的工作原理
ControlNet 通过引入额外的条件来控制扩散模型的图像生成。这些条件可以是用户指定的图像特征、风格或者是某种特定的构图要求。在训练过程中,ControlNet 学习如何根据这些条件来调整扩散模型的参数,从而生成符合用户期望的图像。
具体来说,ControlNet 可以与任何稳定扩散模型一起使用,其最基本的形式是文本到图像的生成。除了使用文本提示作为条件来引导图像生成外,ControlNet 还增加了额外的条件,这些条件可以是用户提供的参考图像中的构图或人体姿势等。通过结合这些条件,ControlNet 能够生成与文本提示和参考图像更加匹配的图像。
如下图所示,输入一张跳舞的图片,ControlNet 会使用 Canny 边缘检测器检测其轮廓,并将其保存为控制图。然后,这张控制图被输入到 ControlNet 模型中,AI 就能够读懂图片上的人物轮廓。最终,大模型会结合提示词和控制图来生成相同轮廓的人物图片。

从输入图片中提取特定信息的过程称为预处理(annotator),每个 ControlNet 模型都与之对应的多种预处理器,这些预处理器能够完成不同精细度的控制。而存储这些控制信息的图片称为控制图(control map),这一控制图就如同一张精确的导航图,为后续的图像生成提供了明确的指引。在 ControlNet 1.1 版本中,一共有 14 种模型来处理不同方面的控制,这些模型还可以组合使用,产生复合控制的效果。
二、安装 ControlNet 插件
在 Stable Diffusion WebUI 中,ControlNet 是一种扩展插件,使用前我们需要先安装
sd-webui-controlnet插件。
首先,在 Stable Diffusion WebUI 界面中打开“扩展”选项卡,再选择“从网址安装”选项卡,在“扩展的GitHub仓库地址”文本框中输入下面地址,然后点击“安装”按钮:
https://github.com/Mikubill/sd-webui-controlnet
- 1
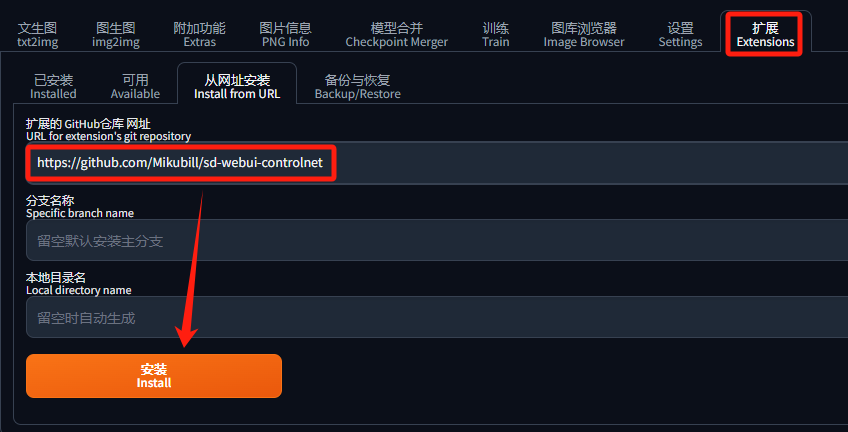
等待几分钟后,出现下图中的提醒表示安装完成,该插件会被安装在 \extensions\sd-webui-controlnet目录中:
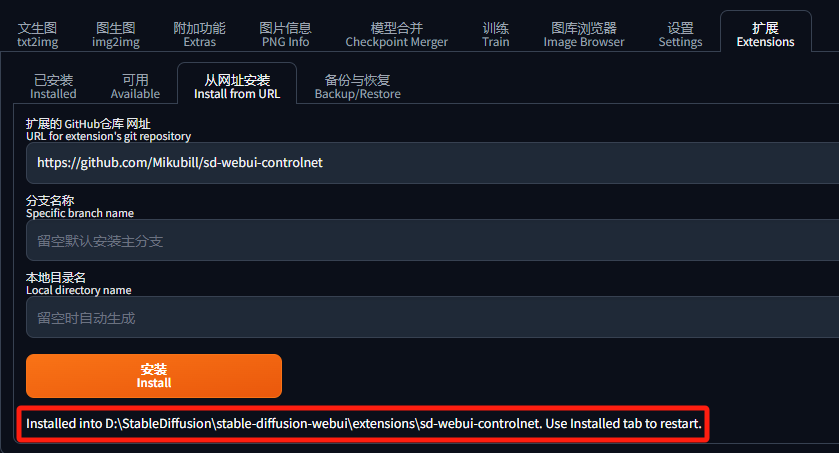
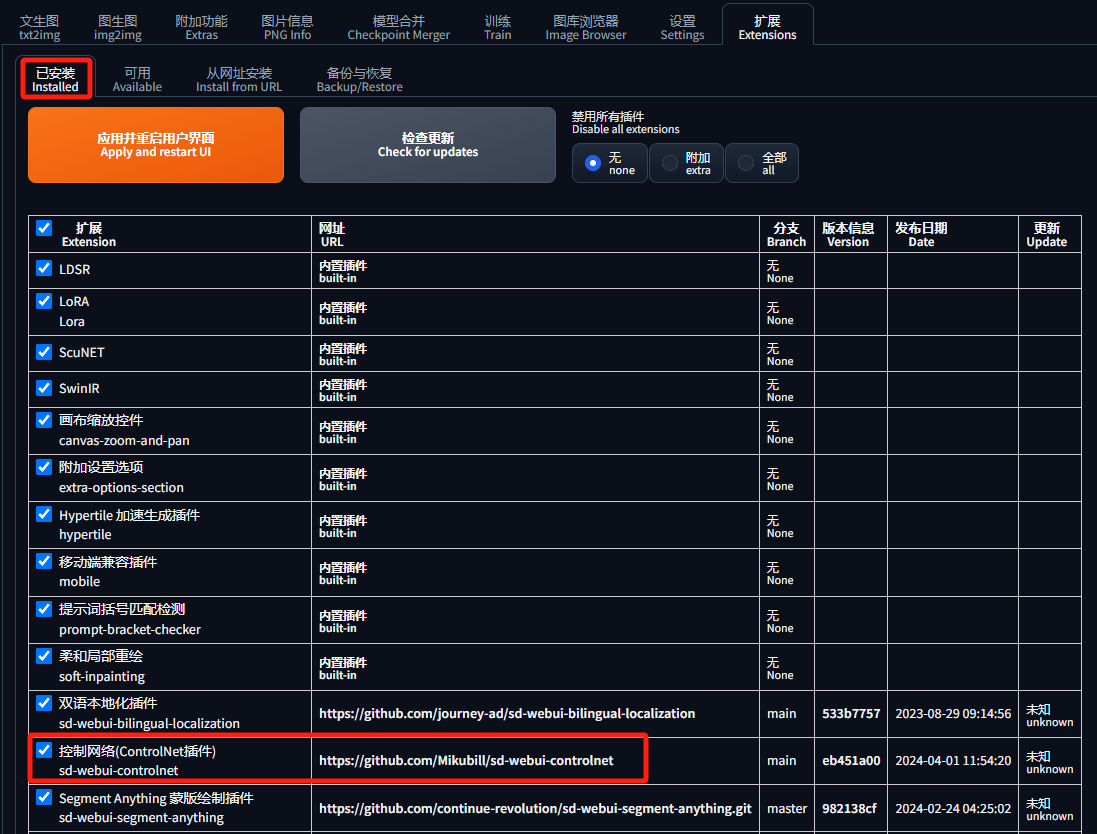
在“已安装”选项卡中可以看到该插件,点击“应用并重启用户界面”会重启 Stable Diffusion WebUI:
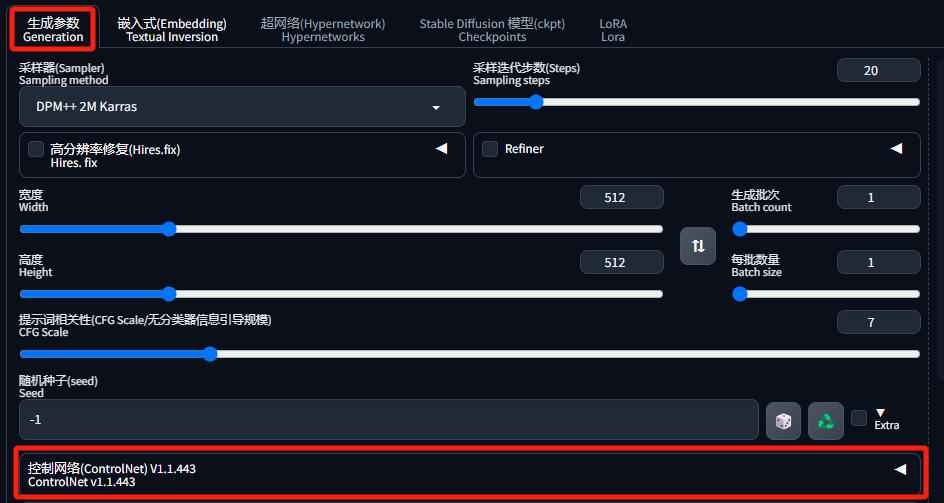
重启后,在“生成参数”里就能看到"ControleNet"了:
2.1 下载模型
安装 sd-webui-controlnet 插件时并不会为我们下载模型,需要我们手动下载。你可以从 HuggingFace 中下载(14个模型和它们的配置文件),或者从我分享的网盘中下载。
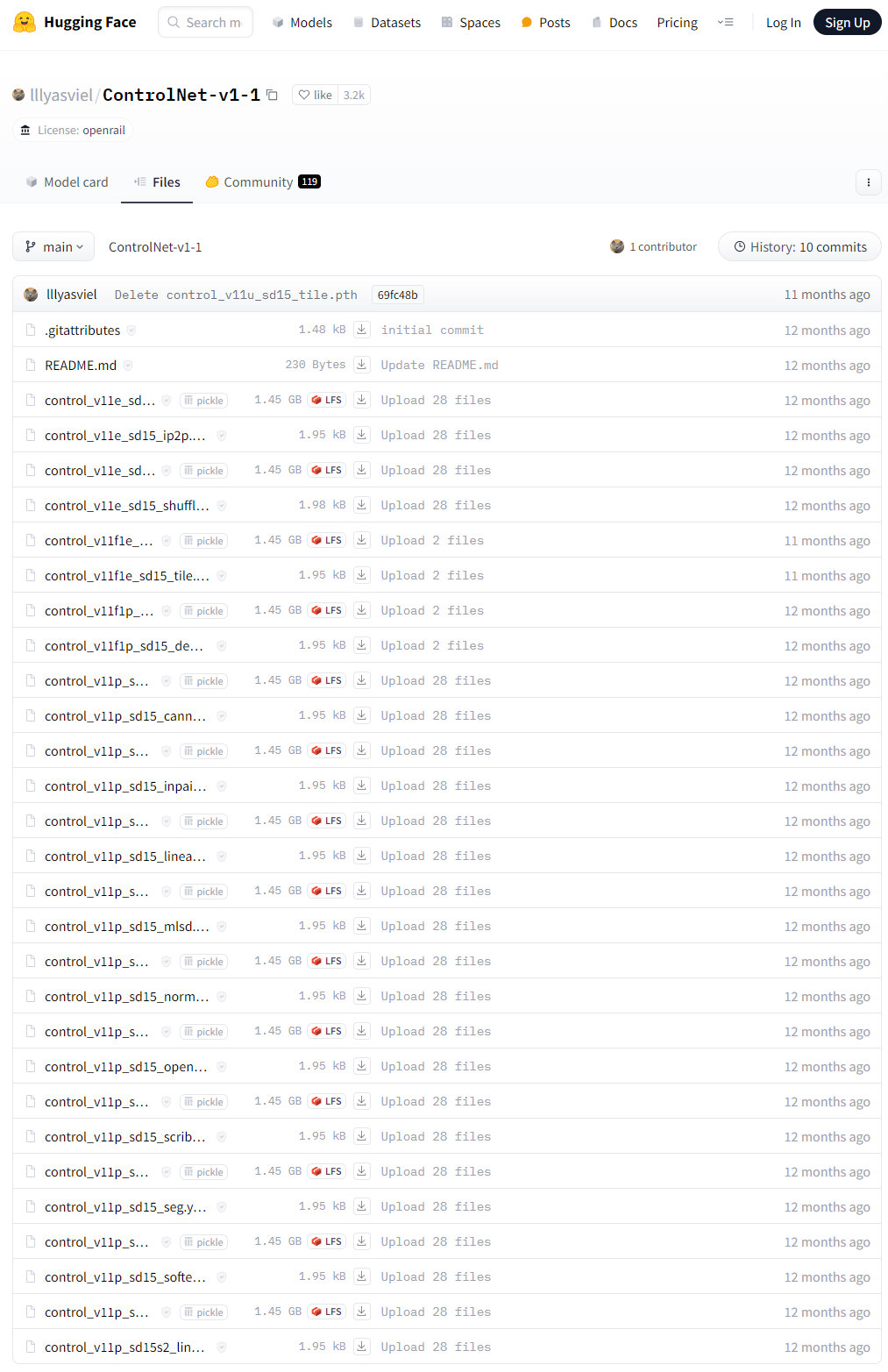
下载完成后,将模型文件放到 \extensions\sd-webui-controlnet\models目录中:
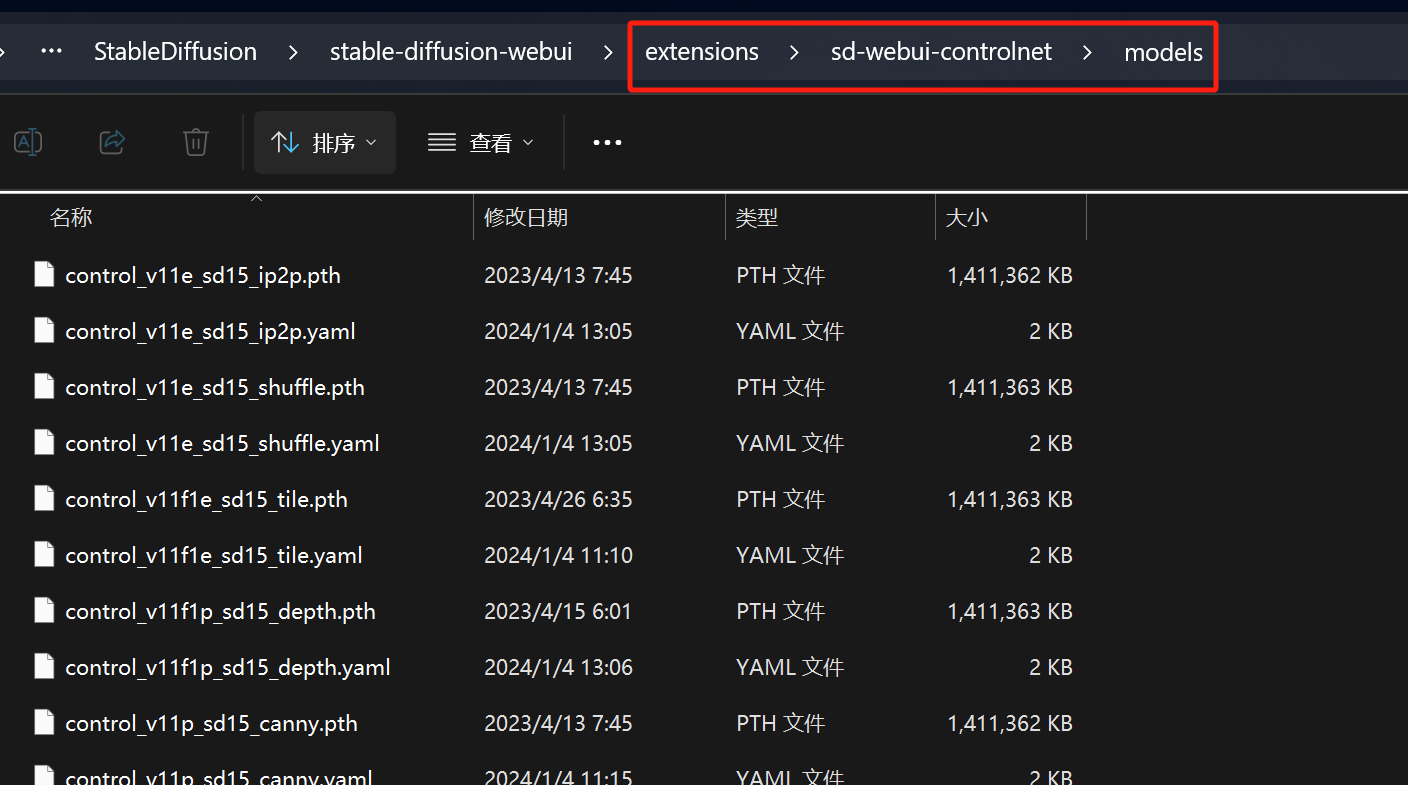
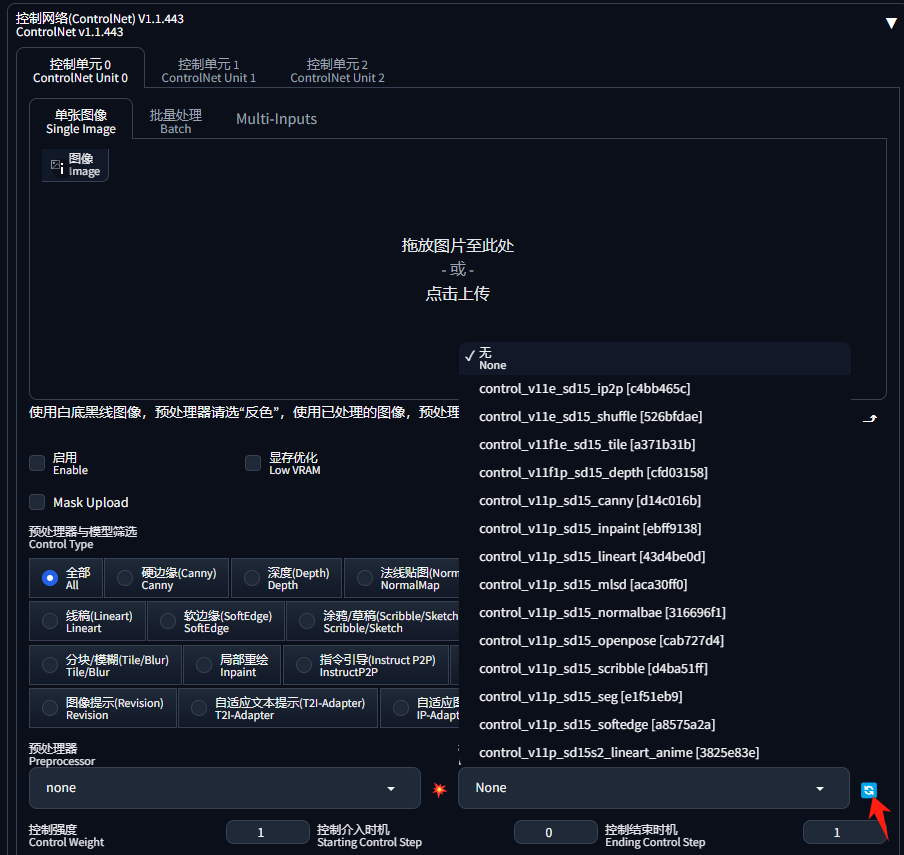
最后,在 ControlNet 界面,点击“刷新”按钮,“模型”就出来了:
2.2 下载预处理器
sd-webui-controlnet 还有很多预处理器需要提前下载,否则会在“预览”的时候自动下载,很耗费时间。这些文件我也上传到了我的网盘,直接去下载即可。
下载完成后,将预处理器文件放到 \extensions\sd-webui-controlnet\annotator\downloads目录中:
三、使用 ControlNet 插件
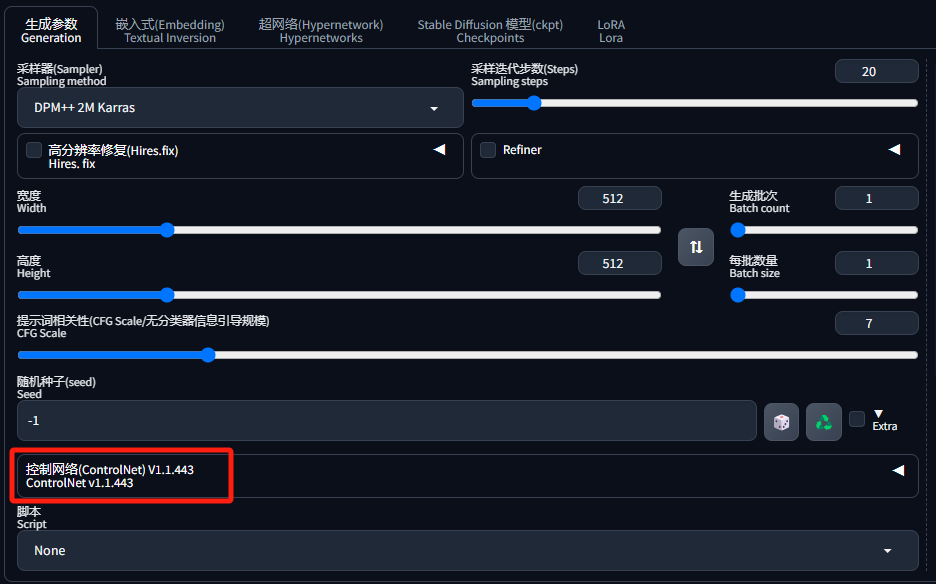
安装好 ControleNet 插件后,就可以在“生成参数”中找到该功能了:
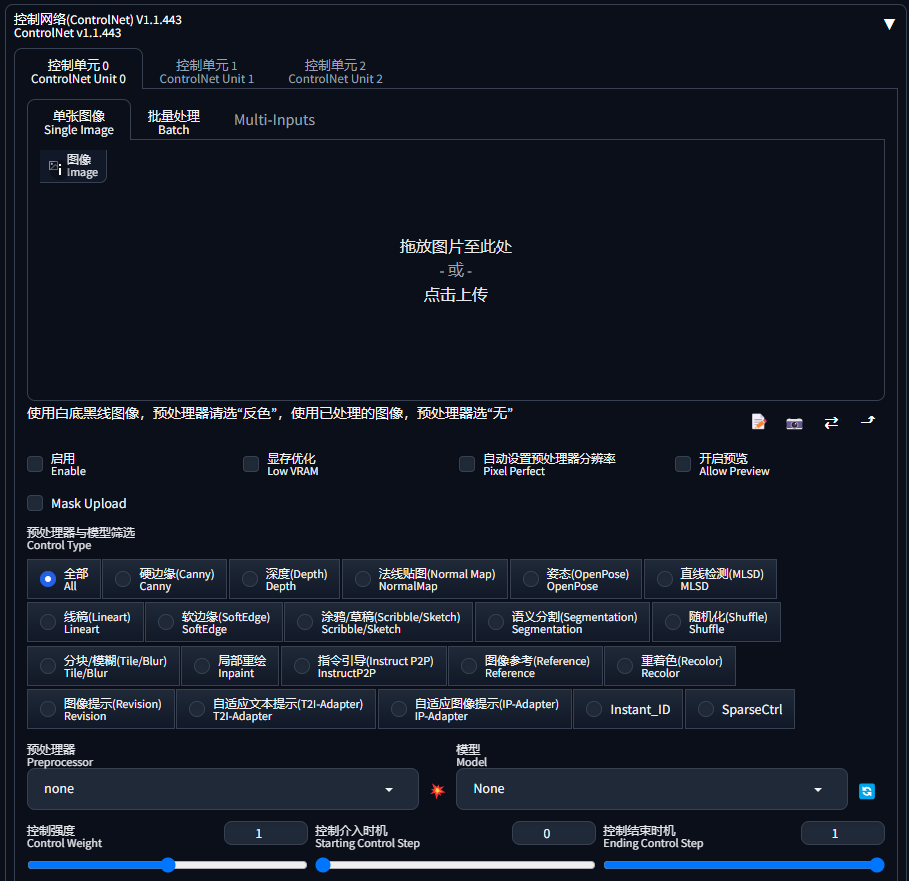
点击右侧的“三角”图标,即可展开 ControleNet:
3.1 参考图上传
有三种上传参考图的方式:
(1)单张图像,可以上传一张参考图:
(2)批量处理,可以指定图片目录:
(3)Multi-Inputs,可以同时上传张参考图:
3.2 控制选项
上传参考图功能下面还有一些选项:
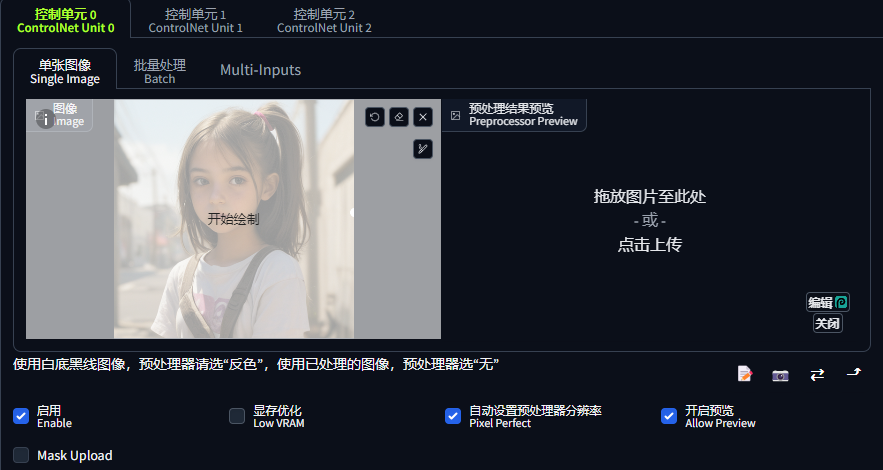
- 启用(Enable):只有勾选上“启用”复选框,该控制单元才会生效。
- 显存优化(Low VRAM):当显存小于 6G 时,可以勾选,但会减低处理速度。
- 完美像素模式(Pixel Perfect):有翻译成“自动设置预处理器分辨率”的。此选项旨在使生成的图片达到理想的像素状态。当启用时,ControlNet会尝试优化生成的图像,使其在像素级别上更接近预期的结果。通常我们勾选上。
- 开户预览(Allow Preview):当需要提前看下预处理器生成的控制图时,可以勾选上。
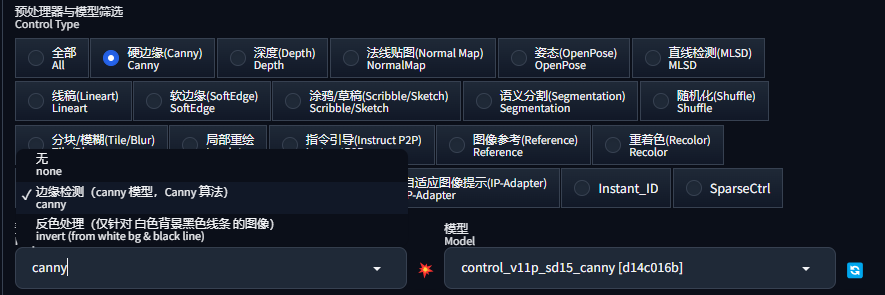
3.3 预处理器与模型筛选
预处理器与模型筛选(Control Type)部分就是我们选择预处理器和 ControlNet 模型的地方了:
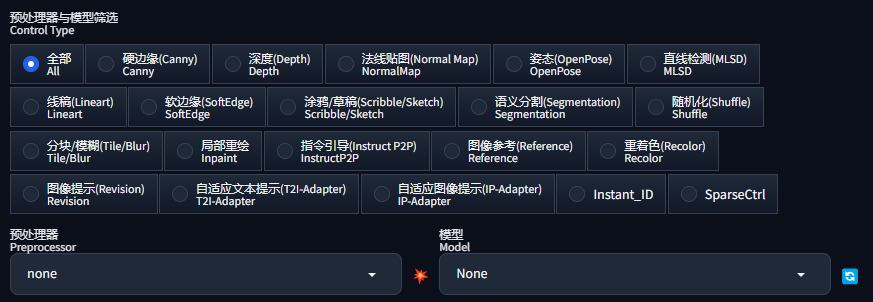
当我们点击一个类型后,如硬边缘,下面的“预处理器”和“模型”会自动筛选,我们就可以选择不同的“预处理器”了:
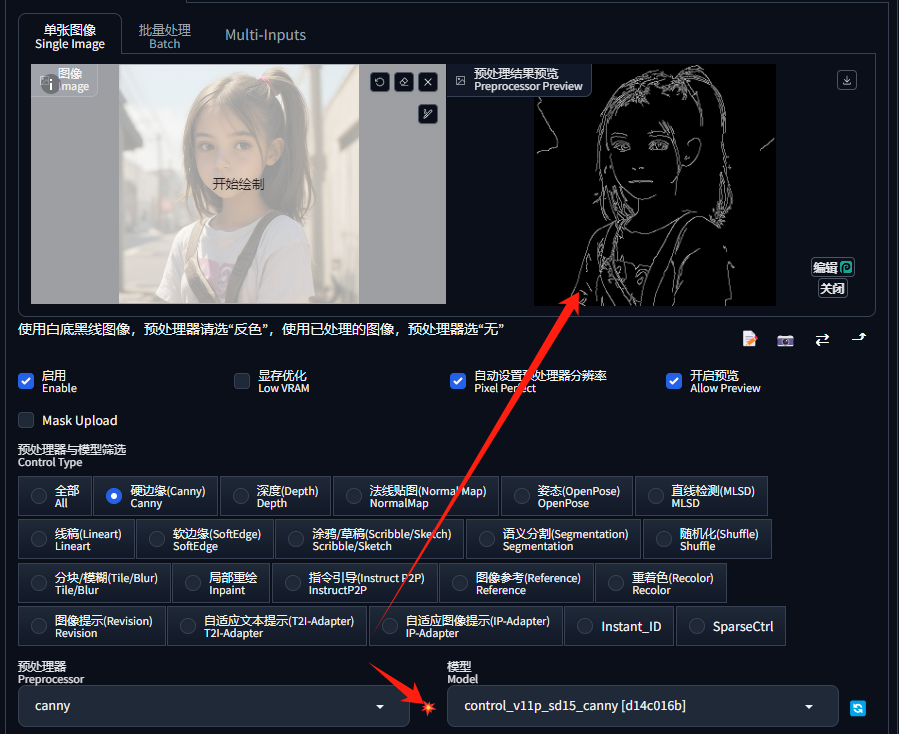
点击“预处理器”右边的“爆炸”按钮,还可以提前预览控制图:
3.4 控制参数
在模型下面还有一些控制选项:
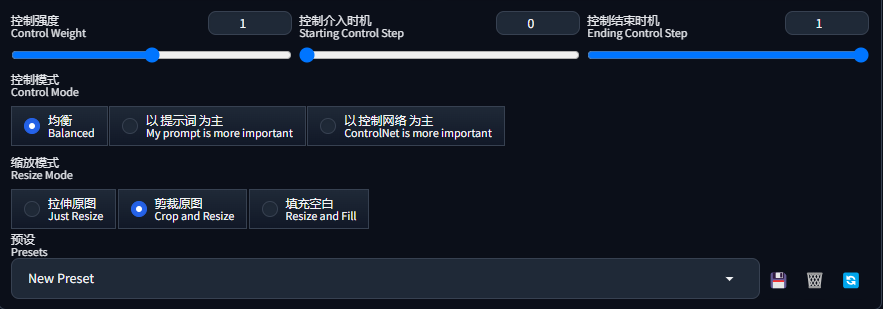
- 控制强度(Control Weight):代表使用 ControlNet 生成图片的权重占比影响。
- 控制介入时机(Starting Control Step):表示从多少百分比的采样步数开始控制,默认0表示从开始就介入。
- 控制结果时机(Ending Control Step):表示从多少百分比的采样步数结束控制,默认1表示直至结束。
- 控制模式(Control Mode):可以选择生成的图片是以“提示词”为主,还是以“ControlNet”为主,使用默认的“均衡”即可。
- 缩放模式(Resize Mode):当生成的图片与参考图不一致时,调整图像的模式。使用默认的剪裁原图即可,这样不会失真。
四、ControlNet 模型和预处理器
从 ControlNet 1.1 开始使用标准的命名规则(SCNNR)来命名所有模型:
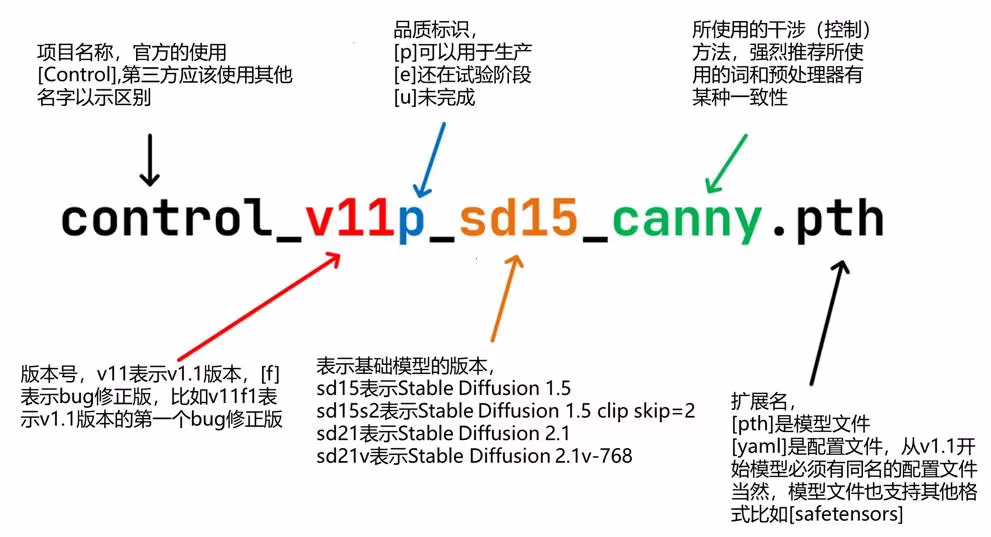
ControlNet 1.1 为我们提供 14 个模型,其中 11 个生产就绪模型和 3 个实验模型,并且它们都是 SD1.5 版本:
control_v11p_sd15_canny
control_v11p_sd15_mlsd
control_v11f1p_sd15_depth
control_v11p_sd15_normalbae
control_v11p_sd15_seg
control_v11p_sd15_inpaint
control_v11p_sd15_lineart
control_v11p_sd15s2_lineart_anime
control_v11p_sd15_openpose
control_v11p_sd15_scribble
control_v11p_sd15_softedge
control_v11e_sd15_shuffle
control_v11e_sd15_ip2p
control_v11f1e_sd15_tile
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
下面我们通过不同的控制方法,来分别介绍每一种模型的使用:
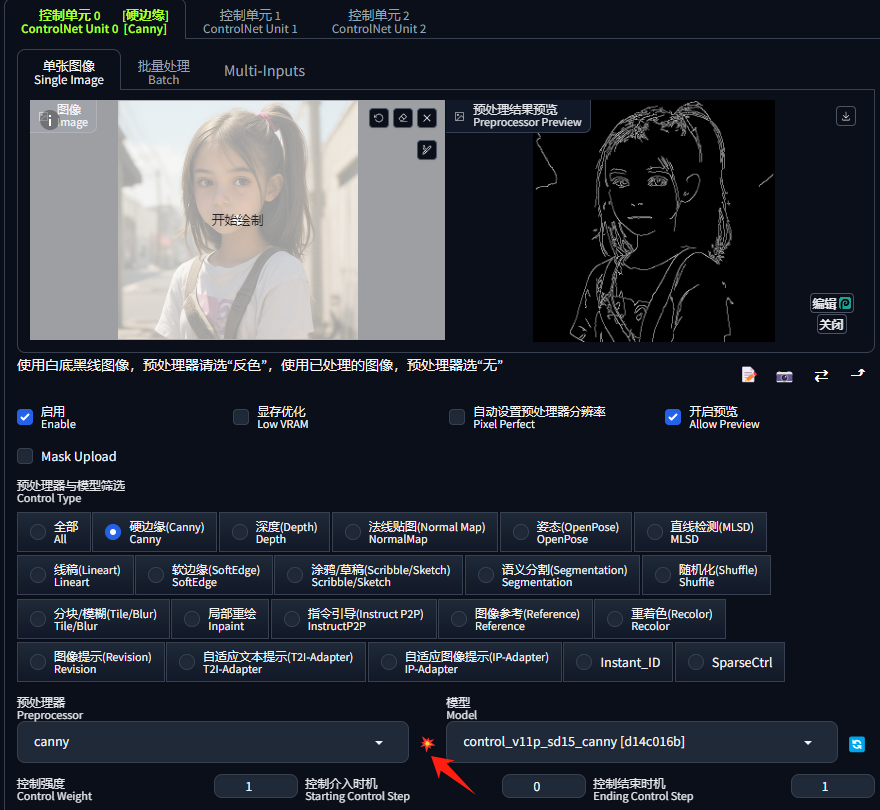
4.1 Canny(硬边缘)
Canny(硬边缘)在 ControlNet 中是一种重要的边缘检测模型,它主要用于识别并提取图像中的边缘特征。使用此模型生成的图像会遵循原图的轮廓,能够最大程度的还原照片。
模型信息
模型文件:control_v11p_sd15_canny.pth
配置文件:control_v11p_sd15_canny.yaml
预处理器:
canny:边缘检测,用于提取图像的轮廓,保留原始图像的构图。Canny 算法invert (from white bg & black line):反色处理,仅针对“白色背景黑色线条”的图像,例如:线稿
预处理器与效果展示
下图为canny预处理器生成的控制图和效果图:

下图为invert预处理器生成的控制图和效果图:

4.2 Depth(深度)
Depth(深度)用于生成立体深度图的,这张深度图能够反映出图像中各个部分的空间位置关系。在深度图中,亮度越高的区域代表该部分在空间中越靠前,而越暗或越灰的区域则表示该部分在空间中越靠后。这样的深度信息对于保持图像中物体的相对位置和层次感是非常重要的。
模型信息
模型文件:control_v11f1p_sd15_depth.pth
配置文件:control_v11f1p_sd15_depth.yaml
预处理器:
depth_midas:经典的深度估计器。depth_leres:更多细节,但也倾向于渲染背景。depth_leres++:比depth_leres有更多的细节。depth_zoe:细节程度介于 Midas 和 Leres 之间。depth_anything:新的、增强的深度模型(推荐)。depth_hand_refiner:只用于修复手部(局部重绘)。
预处理器与效果展示
原图:

下图为前五个预处理器生成的控制图和效果图:

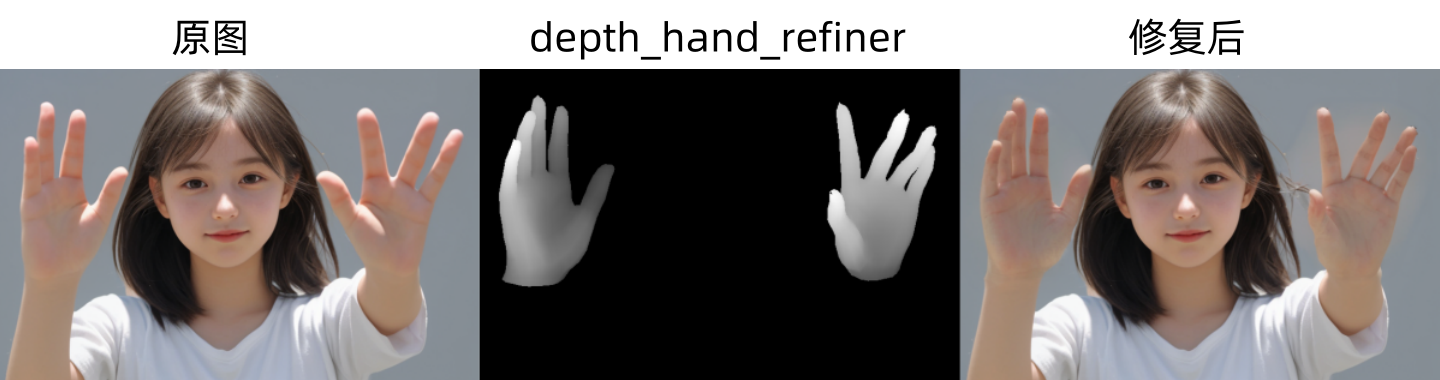
手部修复预处理器与效果展示
下图为depth_hand_refiner预处理器生成的控制图和修复手部效果图:
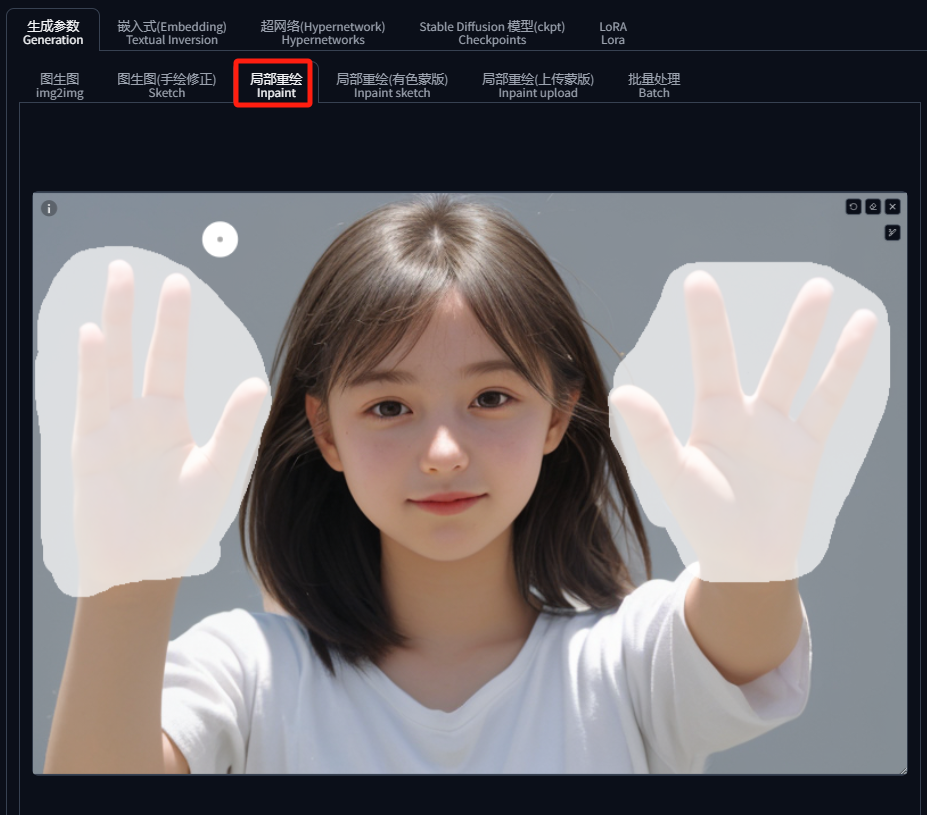
手部修复比较特殊,它是在“图生图”的“局部重绘”中操作的,具体步骤如下:
(1)首先,在“局部重绘”中上传原图,并使用画笔工具将坏的手部遮住:
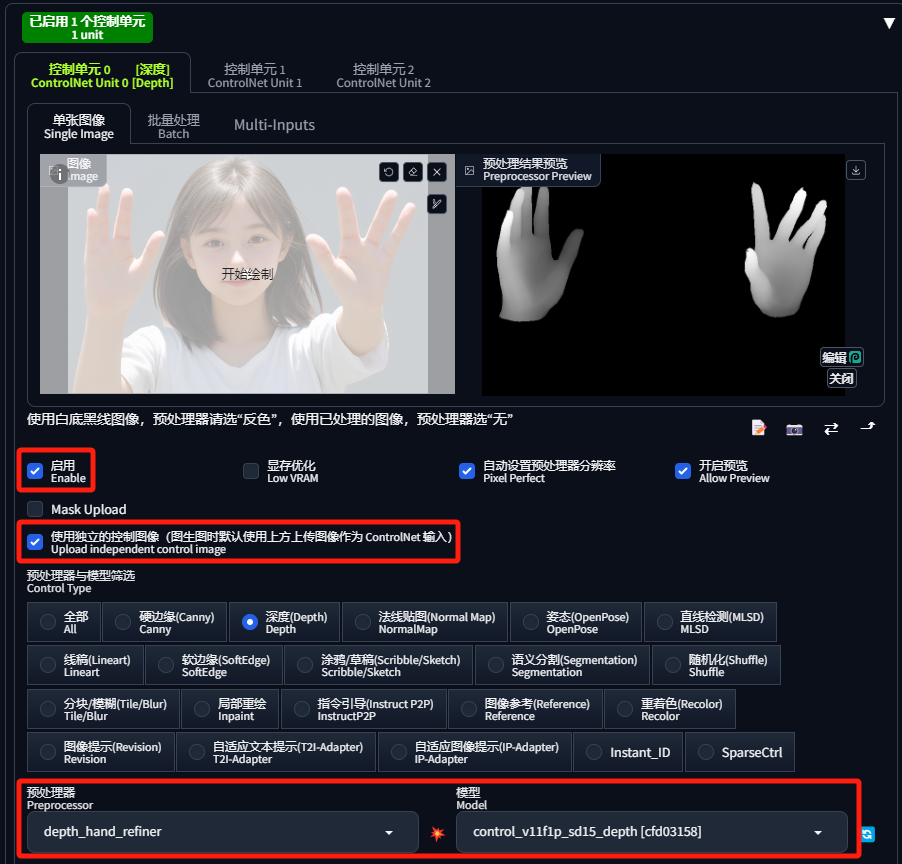
(2)然后,拉到下面的 “ControlNet 控制单元”勾选“启用”和“使用独立的控制图像”,并将上传原图;预处理器选择depth_hand_refiner,模型选择 control_v11f1p_sd15_depth;如果“开启预览”,还可以点击“爆炸”图标进行预览:
(3)点击“生成”后,便会生成一张修复好的图片:

4.3 Normal Map(法线贴图)
在计算机图形学中,法线贴图(Normal Map)是一种特殊类型的纹理,它使用颜色信息来模拟物体表面的微观细节和凹凸感。通常,法线图会使用三种颜色通道(红、绿、蓝)来存储这些信息,每种颜色代表空间中的一个方向,共同确定每个像素点表面上的一个垂直向量,即法线向量。这个法线向量告诉渲染系统光线如何与物体表面交互,从而创造出更加真实的光照效果。
在 ControlNet 的背景下,Normal Map(法线贴图)的概念被用来控制 AI 图像生成过程中的光影效果。通过输入法线图,AI 模型能够更好地理解物体的三维结构和表面细节,从而在生成的图像中模拟出更加准确的光照和阴影效果。这在需要精确控制物体表面细节和光影关系的场合非常有用,比如在游戏开发、电影特效制作或者任何需要高质量3D渲染的应用中。
模型信息
模型文件:control_v11p_sd15_normalbae.pth
配置文件:control_v11p_sd15_normalbae.yaml
预处理器:
normal_bae:这个预处理器主要用于还原图片主体的凹凸起伏特征,以及背景的凹凸起伏特征。它能够处理后生成的图片对于原图的还原程度和细节的把控以及质感的表达都非常的高。normal_dsine:最新的算法,更丰富的细节(推荐)。normal_midas:这个预处理器被认为是较为落后的算法,不建议使用,在非特殊情况下请选用normal_bae。
预处理器与效果展示
原图:

下图为这三个预处理器生成的控制图和效果图:


4.4 OpenPose(姿态)
OpenPose(姿态)可以检测人体的关键点,例如:头、肩膀、手的位置等。主要用于复制人体的姿势,而无需关心服装、发型、背景等信息。相比
Canny模型,OpenPose给 AI 更多的发挥空间。
模型信息
模型文件:control_v11p_sd15_openpose.pth
配置文件:control_v11p_sd15_openpose.yaml
预处理器:
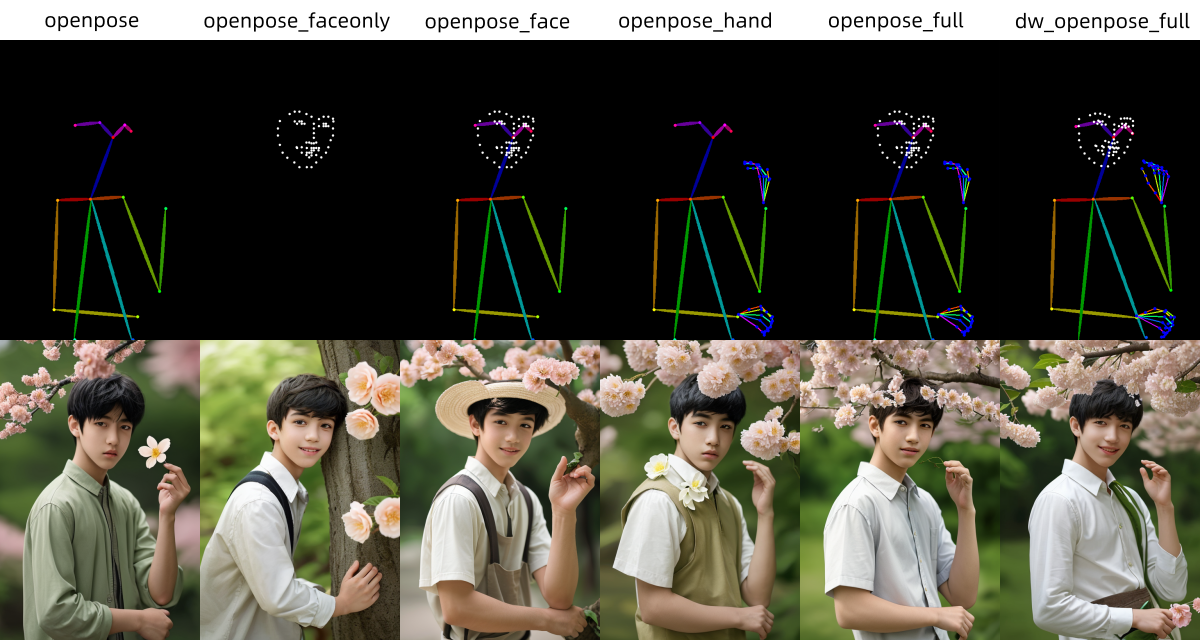
openpose:仅姿态。是最基本的 OpenPose 处理器,可检测眼睛、鼻子、眼睛、颈部、肩膀、肘部、手腕、膝盖和脚踝的位置。openpose_faceonly:仅面部细节。仅检测面部而不检测其他关键点。openpose_face:姿态+面部细节。会检测姿态和面部细节。openpose_hand:姿态+手部细节。会检测姿态和手部细节。openpose_full:姿态+面部细节+手部细节。会检测姿态、面部细节和手部细节。dw_openpose_full:姿态+面部细节+手部细节。使用 DWPose 新的算法,是openpose_full的增强版本(推荐)。
预处理器与效果展示
原图:

下图为这六种预处理器生成的控制图和效果图:
4.5 MLSD(线条检测)
MLSD(Mobile Line Segment Detection,线条检测)用于检测直线,对于提取具有直边的轮廓非常有用(曲线将被忽略),例如:室内设计、建筑物、街景、相框、纸张边缘等。
模型信息
模型文件:control_v11p_sd15_mlsd.pth
配置文件:control_v11p_sd15_mlsd.yaml
预处理器:
mlsd:直线检测invert (from white bg & black line):反色处理,仅针对“白色背景黑色线条”的图像,例如:线稿
预处理器与效果展示
下图为mlsd预处理器生成的控制图和效果图:
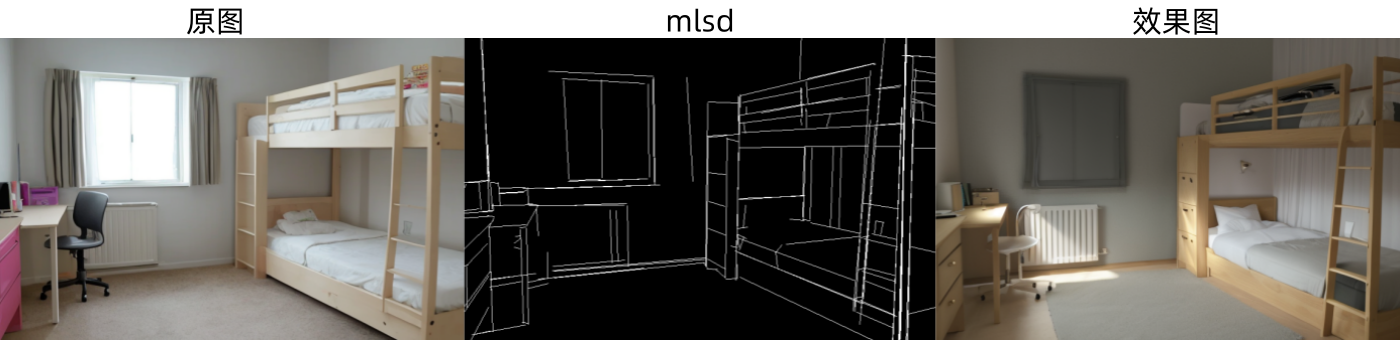
下图为invert预处理器生成的控制图和效果图:

4.6 Lineart(线稿)
Lineart(线稿)是一个专门用于提取线稿的模型,提取的线稿一般可以用作上色等后续创作的基础。这个模型可以针对不同类型的图片进行不同的处理,如动漫图片和素描图片。对于动漫图片,预处理器模型可以选择
lineart_anime或lineart_anime_denoise,后者比前者细节更丰富一些;对于素描图片,建议使用lineart_coarse预处理器,它能从图片中粗略提取线稿图,忽略不突出的细节,生成图片时自由度更高。
模型信息
模型文件:control_v11p_sd15_lineart.pth
配置文件:control_v11p_sd15_lineart.yaml
预处理器:
lineart_anime:线稿提取,针对动漫。lineart_anime_denoise:线稿提取,针对动漫,可去除波点阴影。lineart_coarse:线稿提取,针对草稿(素描)。lineart_realistic:线稿提取,针对照片(写实,推荐)。lineart_standard (from white bg & black line):线稿提取,仅针对黑白线稿。invert (from white bg & black line):反色处理,仅针对黑白线稿。
预处理器与效果展示
原图:

下图为这六个预处理器生成的控制图和效果图:

原图:

图为这六个预处理器生成的控制图和效果图:

原图:

为这六个预处理器生成的控制图和效果图:

4.7 Anime Lineart(动漫风格线稿)
Anime Lineart(动漫风格线稿)专门用于处理动漫风格的线稿,能够生成具有丰富细节和动漫风格的图像。
模型信息
模型文件:control_v11p_sd15s2_lineart_anime.pth
配置文件:control_v11p_sd15s2_lineart_anime.yaml
预处理器:与 Lineart 相同。
预处理器与效果展示
下图为这六个预处理器生成的控制图和效果图:

4.8 SoftEdge(软边缘)
SoftEdge(软边缘) 同样也用于检测图像的边缘信息。与 Canny 相比,SoftEdge 生成的边缘线条更模糊,降低了控制效果,为 AI 提供了更多自由。若觉得 Canny 束缚过多,不妨尝试 SoftEdge,或许能带来新的创作空间。
模型信息
模型文件:control_v11p_sd15_softedge.pth
配置文件:control_v11p_sd15_softedge.yaml
预处理器:
softedge_hed:软边缘检测,使用 HED 算法softedge_hedsafe:软边缘检测,使用 HED 算法softedge_pidinet:软边缘检测,使用 PiDiNet 算法softedge_pidisafe:软边缘检测,使用 PiDiNet 算法softedge_teed:软边缘检测,使用 TEED 算法
预处理器与效果展示
下图为这五个预处理器生成的控制图和效果图:

4.9 Scribble/Sketch(涂鸦/草稿)
Scribble/Sketch(涂鸦/草稿)会将图片变成涂鸦,就像手绘的一样。
模型信息
模型文件:control_v11p_sd15_scribble.pth
配置文件:control_v11p_sd15_scribble.yaml
预处理器:
scribble_hed:涂鸦处理,使用 HED 算法。 Holistically-Nested Edge Detection(HED)是一种边缘检测器,擅长生成像真人一样的轮廓。据 ControlNet 的作者称,HED 适合对图像进行重新着色和重新设计样式。scribble_pidinet:涂鸦处理,使用 PiDiNet 算法。Pixel Difference network (Pidinet)检测曲线和直线边缘。其结果与 HED 类似,但通常会产生更清晰的线条和更少的细节。scribble_xdog:涂鸦处理,使用 xDoG 算法。EXtendedDifferenceofGaussian (XDoG))是一种边缘检测方法技术。调整 xDoG 阈值并观察预处理器输出非常重要。t2ia_sketch_pidi:草稿差分,使用 PiDiNet 算法。通过 T2IA_Sketch_Pidi 处理后的图像,其边缘部分会呈现出一种手绘的效果,这种效果使得图像看起来更加生动和有趣。同时,由于它主要提取的是图像的轮廓信息,因此可以保留图像的主要特征,而忽略一些细节部分,从而实现对图像的简化和抽象化。invert (from white bg & black line):反色处理,仅针对“白色背景黑色线条”的图像。
预处理器与效果展示
下图为前四个预处理器生成的控制图和效果图:

下图为invert预处理器生成的控制图和效果图:

4.10 Segmentation(语义分割)
Segmentation(语义分割)用于标记参考图像中的对象类型,并分别使用不同的颜色来分割。
模型信息
模型文件:control_v11p_sd15_seg.pth
配置文件:control_v11p_sd15_seg.yaml
预处理器:
seg_anime_face:主义分割,主要用于识别动画面部结构。seg_ofade20k:语义分割,使用 OneFormer 算法,ADE20k 协议。seg_ofcoco:语义分割,使用 OneFormer 算法,COCO 协议。seg_ufade20k:语义分割,使用 UniFormer 算法,ADE20k 协议。
预处理器与效果展示
下图为这四个预处理器生成的控制图和效果图:

4.11 Shuffle(随机化)
Shuffle(随机化)的会搅动参考图,产生一种随机的效果。相当于将参考图打乱,使用大致相同的配色方案生成一个新的图片。
模型信息
模型文件:control_v11e_sd15_shuffle.pth
配置文件:control_v11e_sd15_shuffle.yaml
预处理器:shuffle
预处理器与效果展示
下图为这个预处理器生成的控制图和效果图:

4.12 Tile/Blur(分块/模糊)
Tile(分块)模型是一个能增强细节与画质的重绘模型。它保留了原图的构图、画风和人物主体,同时增加了更多细节,提升了画质,让画面更生动、更丰富。
模型信息
模型文件:control_v11f1e_sd15_tile.pth
配置文件:control_v11f1e_sd15_tile.yaml
预处理器:
blur_gaussian:模糊处理,高斯模糊。tile_colorfix:分块控制,颜色修正。tile_colorfix+sharp:分块控制,颜色修正+锐化。tile_resample:分块控制,仅重采样。
预处理器与效果展示
下图为这四个预处理器生成的效果图:

4.13 Inpaint(局部重绘)
Inpaint(局部重绘)类似于图生图的局部重绘。
模型信息
模型文件:control_v11p_sd15_inpaint.pth
配置文件:control_v11p_sd15_inpaint.yaml
预处理器:
inpaint_global_harmonious:局部重绘,仅整合绘制的蒙版。提高全局一致性并允许您使用高去噪强度。inpaint_only:局部重绘,生成式区域填充。不会更改未遮罩的区域。inpaint_only+lama:局部重绘,LaMa 算法 + 生成式区域填充。它往往会产生更干净的结果,并且有利于物体去除。
预处理器与效果展示
将原图的衣服涂上蒙版:
下图为这三个预处理器生成的效果图:

4.14 Instruct P2P(指令引导)
Instruct P2P(指令引导)模型能够利用文本精确地指导图片细节的生成。它能够在保持画面整体风格的同时,微调并修改部分内容,以满足特定需求。该模型无需额外的预处理器,只需输入相应的提示词,即可描述并实现期望的效果。
模型信息
模型文件:control_v11e_sd15_ip2p.pth
配置文件:control_v11e_sd15_ip2p.yaml
效果展示
下图为该模型使用不同的提示词生成的效果图:


