
机器学习实验二-----决策树构建
赞
踩
决策树是机器学习中一种基本的分类和回归算法,是依托于策略抉择而建立起来的树。本文学习的是决策树的分类
1. 构建决策树流程
-
选择算法:常用的算法包括ID3、C4.5、CART等。
-
划分节点:根据数据特征和算法选择,递归地划分节点,直到满足停止条件。
-
决策树剪枝:对决策树进行剪枝操作,减少决策树的复杂度,提高泛化能力。
-
决策树评估:使用测试数据集评估决策树模型的性能,通常使用准确率、召回率、F1值等。
2.常用的三个算法
2.1 ID3
D3采用信息增益来划分属性。
2.12 信息熵
用来衡量数据集的混乱程度,信息熵越大,表明数据集的混乱程度越大,不确定性越大。
公式:
其中pi表示的是分类为xi这个样本在中的占比。
2.12信息增益
划分数据集之前之后信息发生的变化
公式:
信息增益越大,则意味着采用该属性a划分节点获得的纯度提升更大。在每次划分中采用信息增益最大的划分。
信息增益实际上就是数据集整体的信息熵减去使用特征 a进行划分后各子集的加权平均信息熵,即子集的信息熵的期望值。当信息增益越大时,意味着子集的信息熵的减少量越大,即数据集的不确定性减少的程度更大,信息熵变小。
2.2 C4.5
C4.5算法在ID3算法上做了提升,使用信息增益比来构造决策树,且有剪枝功能防止过拟合。
信息增益比:特征a对训练集D的信息增益比定义为特征a的信息增益与训练集D对于a的信息熵之比, 同样是信息增益比越大越好。
公式:
先剪枝:提前停止树的构建而对树”剪枝“,提前停止的策略有定义一个树的深度,到达指定深度自动停止构造;
后剪枝:先构造完整的子树,对于决策树中信息增益比较低的子树用叶子节点代替。
2.3 CART基尼指数
基尼指数是衡量数据集纯度或不确定性的一种指标,常用于决策树算法中的特征选择和节点划分。
公式:
基尼指数越小越好。
3.划分节点
划分节点就是根据我们选择的算法来进行划分的,我们这边拿C4.5算法来举例一下。拿鸢尾花来举例一下,我们有花萼长度,花萼宽度,花瓣长度,花瓣宽度四个特征值。我们分别计算一下每一个的熵,根据公式计算出信息增益比,选择按照信息增益比大小排序的特征来当划分的依据。这边假设我们排序就是花萼长度,花萼宽度,花瓣长度,花瓣宽度,那我们先按照花萼长度把根节点划分为左右子树,子树再根据花萼宽度把子树再继续划分,一直用递归来划分每一个节点。最后就得到整棵树。
4. 决策树的剪枝
决策树生成算法递归的产生决策树,直到不能继续下去为止,这样产生的树往往对训练数据的分类很准确,但对未知测试数据的分类缺没有那么精确,即会出现过拟合现象。
过拟合产生的原因在于在学习时过多的考虑如何提高对训练数据的正确分类,从而构建出过于复杂的决策树,解决方法是考虑决策树的复杂度,对已经生成的树进行简化。
剪枝:从已经生成的树上裁掉一些子树或叶节点,并将其根节点或父节点作为新的叶子节点,从而简化分类树模型。
剪枝分为预剪枝与后剪枝。
预剪枝是指在决策树的生成过程中,对每个节点在划分前先进行评估,若当前的划分不能带来泛化性能的提升,则停止划分,并将当前节点标记为叶节点。
后剪枝是指先从训练集生成一颗完整的决策树,然后自底向上对非叶节点进行考察,若将该节点对应的子树替换为叶节点,能带来泛化性能的提升,则将该子树替换为叶节点。
5.决策树构建
这个函数直接依据我们所给的数据用C4.5创建了决策树
clf.fit(X_train, y_train)6.决策树可视化
使用了export_graphviz函数从训练好的决策树模型中生成一个Graphviz格式的文本文件,然后使用graphviz.Source将这个文本文件转换为一个Graphviz对象,最后使用render方法将这个对象渲染为图形文件。
- dot_data = export_graphviz(clf, out_file=None,
- feature_names=["Sepal.Length", "Sepal.Width", "Petal.Length", "Petal.Width"],
- class_names=["setosa", "versicolor", "virginica"],
- filled=True, rounded=True,
- special_characters=True)
- graph = graphviz.Source(dot_data)
- graph.render("iris_decision_tree")
-
- graph.view()
运行这个代码得到创建的决策树会包含我们数据集内的所有东西,我的鸢尾花数据集中每个特征的信息增益比在不同的条件下就得到下面这棵树的划分标准。
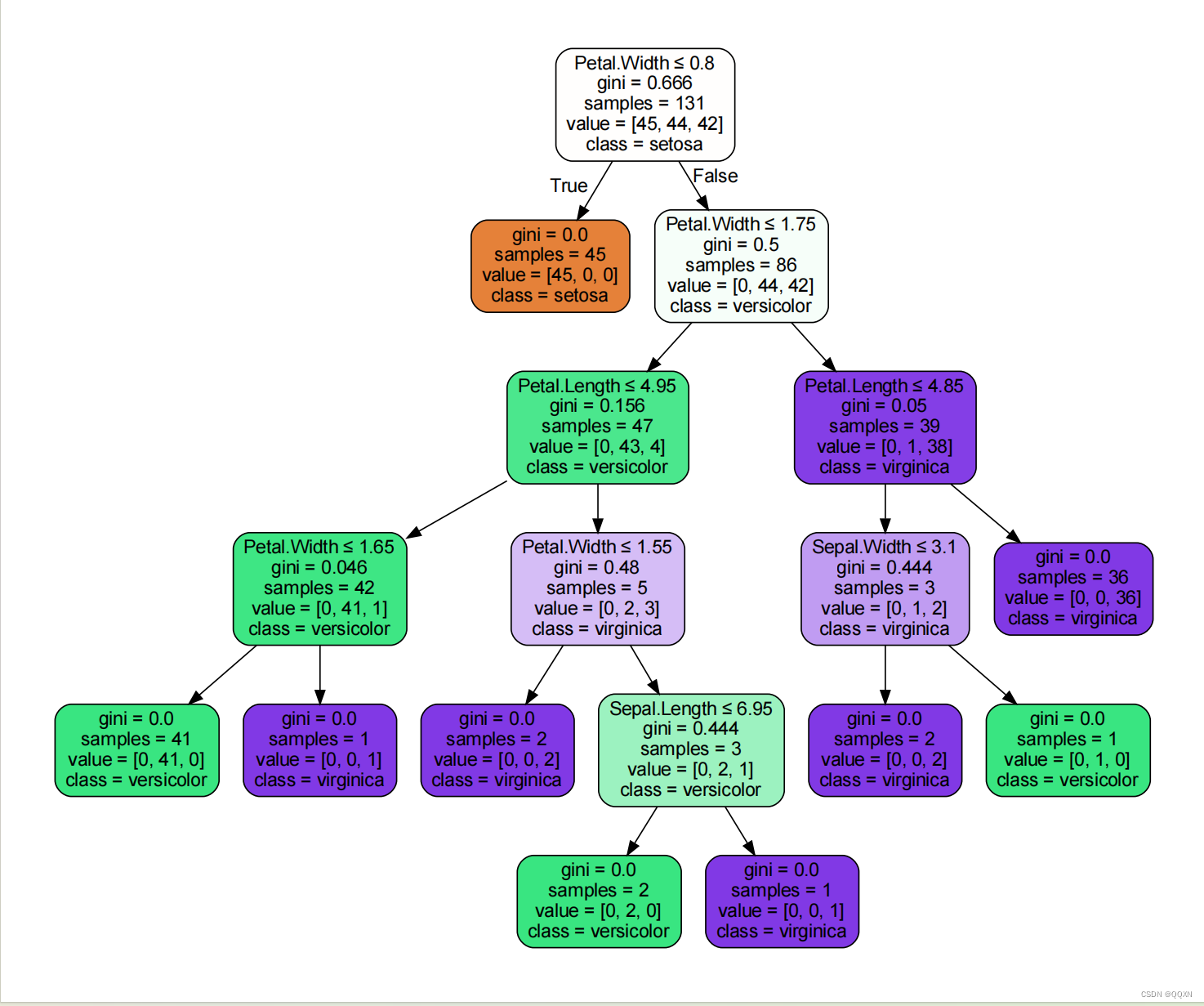
完整代码展现:
- import pandas as pd
- from sklearn.tree import DecisionTreeClassifier
-
-
- def load_data(train_file, test_file):
- train_data = pd.read_csv(train_file, sep='\s+')
- test_data = pd.read_csv(test_file, sep='\s+')
-
- X_train = train_data[["Sepal.Length", "Sepal.Width", "Petal.Length", "Petal.Width"]].values
- y_train = train_data["Species"].values
- X_test = test_data[["Sepal.Length", "Sepal.Width", "Petal.Length", "Petal.Width"]].values
- y_test = test_data["Species"].values
-
- return X_train, y_train, X_test, y_test
-
-
- clf = DecisionTreeClassifier()
-
- train_file = "C:\\Users\\李烨\\Desktop\\新建文件夹\\6\\iris.txt"
- test_file = "C:\\Users\\李烨\\Desktop\\新建文件夹\\6\\iristest.txt"
- X_train, y_train, X_test, y_test = load_data(train_file, test_file)
-
- clf.fit(X_train, y_train)
-
-
- def predict_flower(sepal_length, sepal_width, petal_length, petal_width):
- input_features = [[sepal_length, sepal_width, petal_length, petal_width]]
- prediction = clf.predict(input_features)
- if prediction[0] == 'setosa':
- print("预测类别:setosa")
- elif prediction[0] == 'versicolor':
- print("预测类别:versicolor")
- elif prediction[0] == 'virginica':
- print("预测类别:virginica")
- else:
- print("未知类别")
- return prediction[0]
-
-
- def get_input():
- sepal_length = float(input("请输入花萼长度:"))
- sepal_width = float(input("请输入花萼宽度:"))
- petal_length = float(input("请输入花瓣长度:"))
- petal_width = float(input("请输入花瓣宽度:"))
- return sepal_length, sepal_width, petal_length, petal_width
-
-
- print("实验二决策树分类")
- while True:
- try:
- user_input = input("输入 'exit' 退出:")
- if user_input.lower() == 'exit':
- print("程序结束")
- break
-
-
- sepal_length, sepal_width, petal_length, petal_width = get_input()
- result = predict_flower(sepal_length, sepal_width, petal_length, petal_width)
-
- except ValueError:
- print("输入有误,请重新输入。")
-
-
-



