- 1【AI绘画】Stable Diffusion 本地部署教程!小白必收藏!!_智能绘画本地部署
- 2数据结构与算法——排序算法_用两个栈实现冒泡排序
- 3深度神经网络 FPGA 设计与现状
- 4oracle使用EXISTS函数_oracle exists函数
- 5(免费版?)CLion Nova 强势登陆 C 和 C++ 开发领域
- 6Git(3): VS2019 + Gitee 回滚代码、删除分支_vs git 还原
- 7Ansible总结-基础部分(ansible-doc与常用模块)
- 8[RK3568 Android11] 教程之VMware虚拟机安装步骤_vmware安装安卓11
- 9最新免费 ChatGPT、GPTs、AI换脸(Suno-AI音乐生成大模型)
- 10Android Studio 使用SQLite数据库来创建数据库+创建数据库表+更新表再次往表添加字段_android studio 数据库
神经网络实用工具(整活)系列---使用OpenAI的翻译模型whisper实现语音(中、日、英等等)转中字,从此生肉变熟肉---提高篇(附带打包好的程序)_whisper 幻听
赞
踩
上一篇文章介绍了怎么用OpenAI的翻译模型whisper实现语音转中字的基本操作,在文章中也明确了该操作存在的三个问题:
- 处理速度慢。
- 存在幻听现象,字幕准确度不太理想。
- 要安装比较多的环境才能运行,对一般用户不太友好。
本篇文章将逐一介绍解决这些遗留问题的方法,并把整个项目开源。
对于编程小白,可以直接跳到文章的最后下载作者打包好的语言转中字软件玩一玩。
1. 优化处理速度
在前面的文章中我们使用的whisper版本是OpenAI开源的原版,其处理速度确实也就那样。基础篇的测试中,在一台配置为CPU 5900X、GPU 4090的PC上使用几个不同的模型将一集接近24分钟的《工作细胞》(日语语音)转为英语字幕所花的时间如下表所示:
| 使用模型 | tiny | base | small | medium | large |
| GPU 识别速度(s) | 240.86 | 252.37 | 193.85 | 224.00 | 291.68 |
| CPU 识别速度(s) | 1599.76 | 太慢了不测了 | 太慢了不测了 | 太慢了 不测了 | 太慢了不测了 |
虽然这个速度也不是完全不能接收,但终归还是差了点意思。特别是对于显卡本身就不好的同志,更是要命。
这个问题其实已经被人解决了,Const-me老哥在Windows平台上通过directx的并行计算接口对whisper实现了并行加速。这样一来,如果电脑装的是Windows操作系统,就可以直接下载老哥提供的程序以实现基于whisper的加速操作。
程序下载地址在这:https://github.com/Const-me/Whisper/releases/tag/1.11.0?file=1.11.0
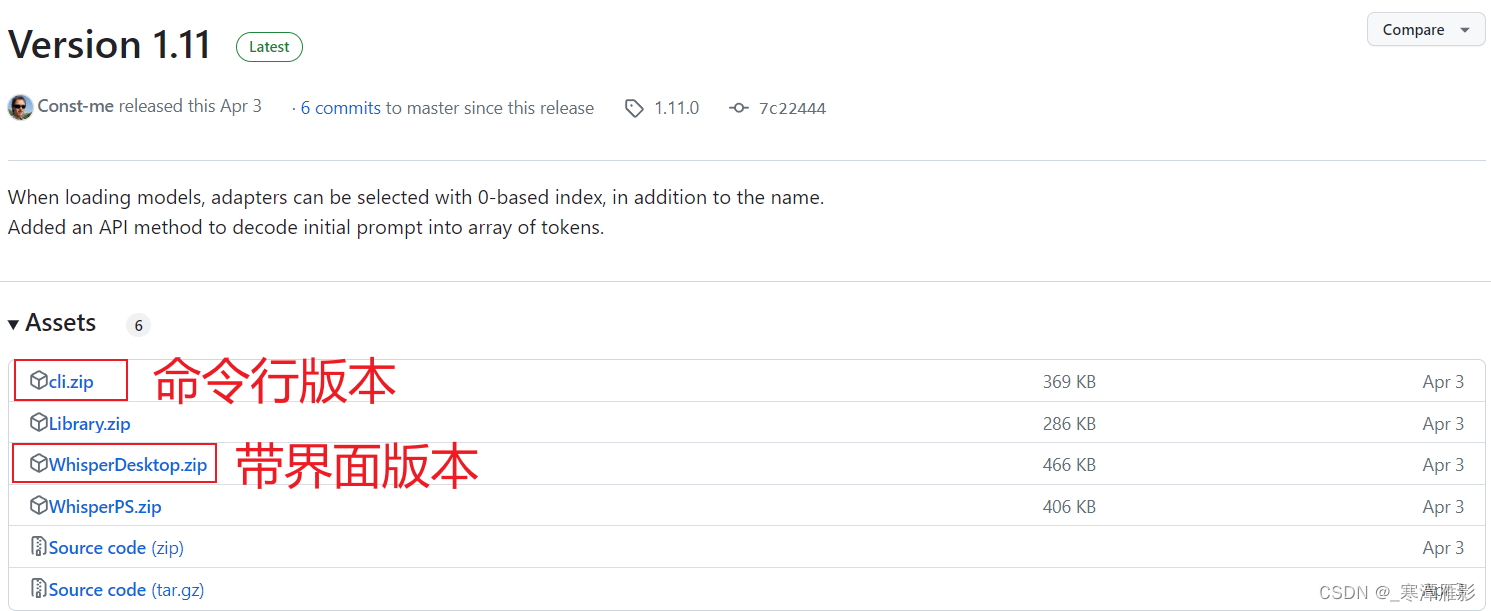
对于小白而言,直接下载带界面版本的程序就可以实现语音转文字的操作(如果语音是日语就输出日文,也可以选择翻译为英语)。由于我们基础篇已经实现了一个界面,因此这里下载了其命令行版本。
PS:还需要去下载对应的模型。地址在这:https://huggingface.co/ggerganov/whisper.cpp/tree/main
东西准备好后,通过如下的命令就可以实现语音转文字的操作了:
.\main.exe -f ".\1.mp4" -m .\models\ggml-medium.bin -l ja -t 8 -tr
- 1
运行速度对比如下(现在哪怕是核显都支持了Direct11,因此这里没有测试单独使用CPU的情况):
| 使用模型 | tiny | base | small | medium | large |
| 官方原版GPU 识别速度(s) | 240.86 | 252.37 | 193.85 | 224.00 | 291.68 |
| Const-me版GPU 识别速度(s) | 13.75 | 22.90 | 38.04 | 57.08 | 82.93 |
对比表的二三行可以看到速度提升了3-10+倍,普大喜奔!!!
到此速度的优化就结束了。PS:本人其实没做任何工作,哈哈哈。。。
2. vad优化
whisper在转非英文音频且音频没有人物对话的时候经常出现幻听现象,也就是在没有语音的片段也会输出大量重复且无意义的文字。为此,我们通过vad来选择语音中的对话部分,把其他部分过滤掉(具体的操作在这篇文章已经介绍了,因此这里只介绍实现细节)。
- 使用ffmpeg将视频中的语音转为silero-vad要求的16000khz采样频率且位宽为16的wav音频。
- 通过silero-vad识别语音中的人物语音起止时间,然后使用ffmpeg将识别到的人物语音片段分成多个文件输出,文件按一定的规律编号,并把语音的开始时间包含在文件名中。
- 使用whisper识别所有的语音片段(直接在命令行中写成-f file1 -f file2的形式即可),得到每个语音片段对应的文字。
- 通过文件名把每个语音片段对应的文字拼接在一起得到全部的字幕。
加上vad优化后跑一下工程会有肉眼可见的翻译质量提升,因此这里没有进行详细的测试,有兴趣的同志可以量化一下。
3. 程序发布
本工程中用到了whisper、vad和ffmpeg三个工具。
因为Const-me大神已经将whisper打包了,ffmpeg本身就有打包成exe的可执行程序可以直接下载,因此我们只需要将vad程序打包(这篇文章已经介绍了怎么使用C++版本的silero-vad,因此将其编译出来就得到了exe可执行文件),然后写个胶水程序把它们黏在一起即可。
在基础篇中我们已经用Python写了一个界面,因此可以通过修改这个程序将上述的三个功能黏在一起。具体的实现不表,有兴趣可到工程的开源地址查看(文章最后给出)。完成胶水程序后,就只剩下打包胶水程序本身的问题了(如果用可编译的语言写胶水程序的话则不存在这个问题,然而Python写起来确实快。。。)。
对于一个Python程序来说,最简单的打包方式是把整个Python解释器所在文件夹直接打包,然后写个bat脚本去调用就完事了。然而这么搞有一点点不优雅,而且打包的东西也太大了。为此,本项目使用Nuitka将Python编写的胶水程序(界面程序)打包成了可执行文件(这块网上有不少教程,以后有心情单独开一篇来讲)。
到此,我们就把语音转文字所有需要的工具以及调用它们的程序全部理清楚了,只需要把它们做成一个zip或者打包成一个安装包,即可在装有windows的不同电脑上运行。
项目地址
https://gitcode.net/oHanTanYanYing/whisper_vad
语音转文字软件下载
https://gitcode.net/oHanTanYanYing/whisper_vad/-/releases?spm=1033.2243.3001.5877