
- 1MYSQL数据类型简介
- 2手把手从零搭建ChatGPT网站midjourney-AI绘画系统,附详细搭建部署教程文档_midjourney 搭建
- 3武汉星起航:依托自营优势与资源积累,创新一站式卖家孵化服务
- 4Kotlin成为Android开发首选语言——你绝对不能错过的
- 5【Element Ui】 vue3中修改el-form的rules后不触发自动校验,再次修改rules时清除验证信息_表单 rules 修改required 校验不生效
- 6Wireguard简易场景配置详解_allowed ips
- 7Unity AR Shadow 阴影
- 8左程云老师算法课笔记(一)_左程云算法笔记
- 9【第十二届“泰迪杯”数据挖掘挑战赛】【2024泰迪杯】B题基于多模态特征融合的图像文本检索—解题全流程(持续更新)_泰迪杯b题2024
- 10第十一篇【传奇开心果系列】BeeWare的Toga开发移动应用示例:Briefcase和Toga 哥俩好_toga beeware
OpenAI开源语音识别模型Whisper在Windows系统的安装详细过程_openai whisper
赞
踩
1、安装Python
安装完成之后,输入python -V可以看到版本信息,说明已经安装成功了。
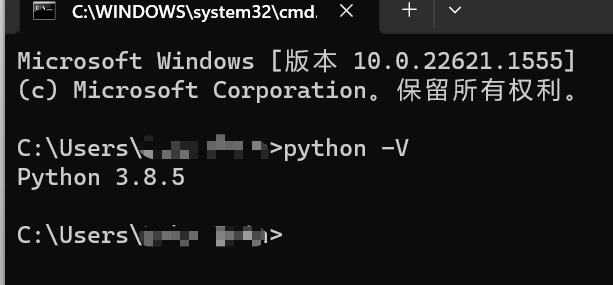
如果输入python -V命令没有看到上面的这样的信息,要么是安装失败,要么是安装好之后没有自动配置环境变量,如何配置环境变量可以从网上搜索。
Python的具体安装过程可以参考这篇文章。
2、安装FFmpeg
ffmpeg是专门做音视频处理用的软件,并且是开源的,点击这里进行下载
安装过程也是十分的简单,具体安装过程可以到网上搜索,因为我这里已经安装过了,所以没办法重新演示安装过程。
这里需要注意,我们安装完成之后还需要配置环境变量。
2.1、配置环境变量
如何配置环境变量,这里以Windows 11为例。
首先右击桌面上的“此电脑”,然后点击“属性”,然后点击“高级系统设置”,然后点击“环境变量”,然后点击“系统变量”中的“Path”,然后双击"Path"进入到设置"Path"窗口,然后点击“新建”,然后把你安装FFmpeg的位置写上,注意写到bin目录,最后记得点击“确定”。
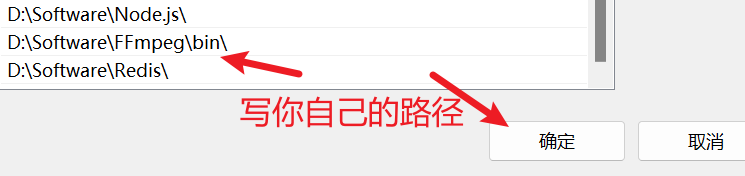
3、安装显卡驱动
如过你没有独立显卡,那么可以跳过这步。如果你使用的是AMD显卡,那你也可以跳过这步了。
这里我以NVIDIA显卡为例。
我自己电脑上的显卡是NVIDIA MX150 2GB显卡,所以我们安装驱动的时候也要选择与自己显卡类型一致的驱动。
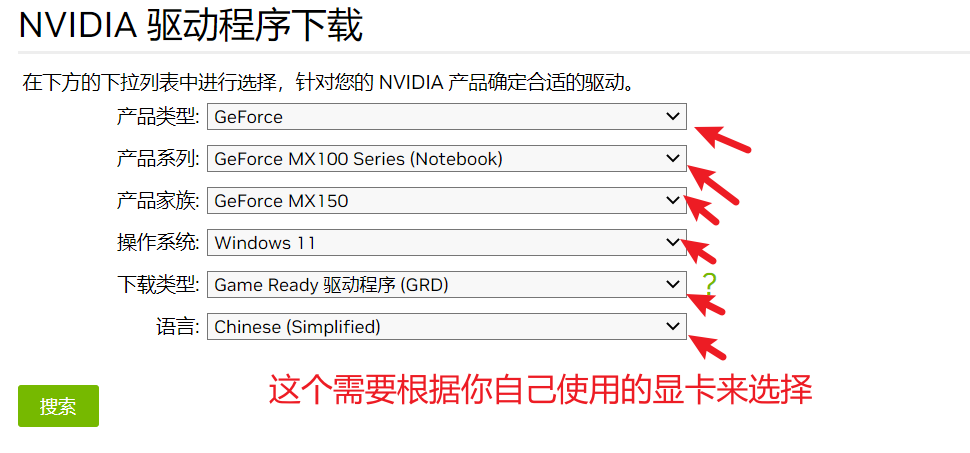
选择完成之后,点击“搜索”按钮,就可以看到有哪些可以下载的显卡驱动了,最后点击下载。
下载到本地之后,运行安装程序即可。
3.1、安装CUDA
安装完显卡驱动之后,我们打开显卡控制面板,找到显卡的信息,查看你显卡支持的CUDA版本。
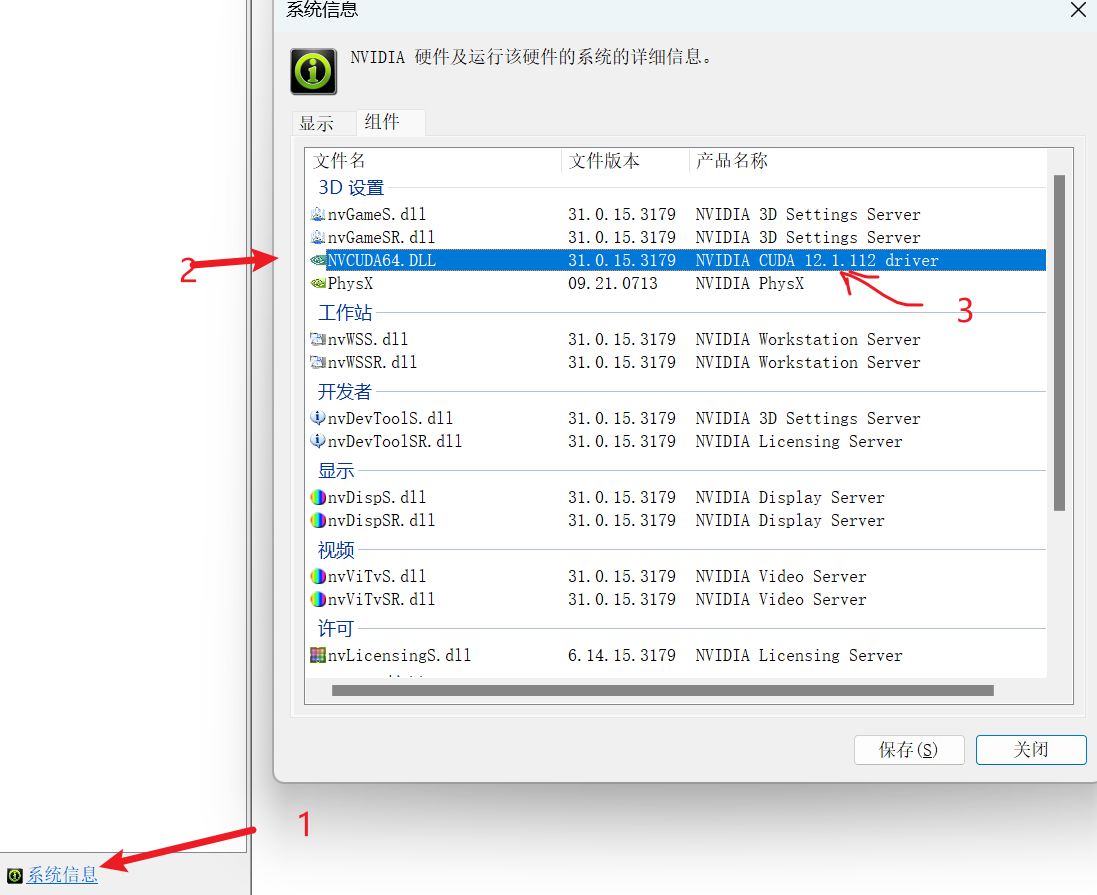
可以看到我这里是12.1版本。
然后我们可以去官网下载对应版本的CUDA了,点击这里去下载

你要根据自己使用的系统来选择。

下载完成之后,直接双击运行即可。
这里比较大,为了下载更快,我使用了多线程下载器IDM。
这里再提一句,我们一定要下载对应版本的CUDA。
运行之后,可以选择自己安装的位置。
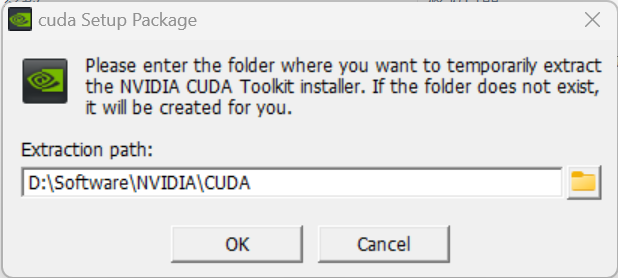
选择自定义安装,然后把前面两个勾选上。
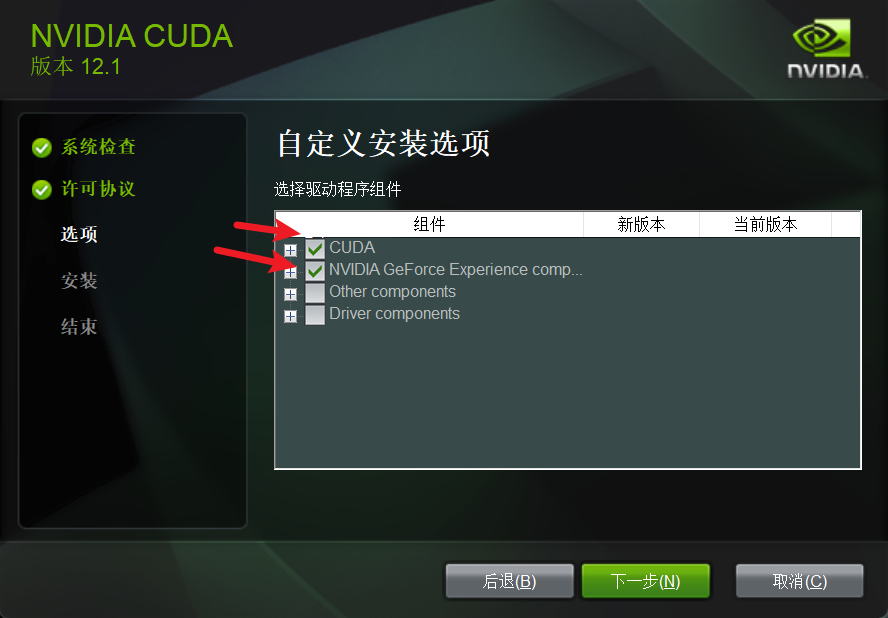
然后是选择安装的位置。

然后你可能会安装失败。
我在安装过程中就有一个没有安装成功,我们可以不管它。
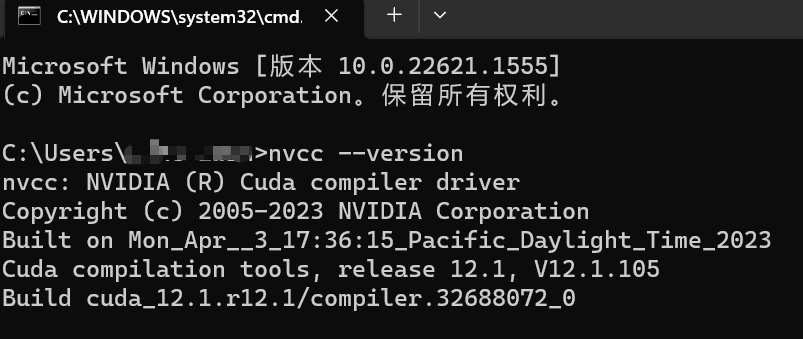
我们打开cmd命令行窗口,然后输入nvcc --version回车之后看到下面这些信息,说明安装成功了。
如果你们不懂,可以看参考文章。
如果有需要的话,最好还要安装一下cuDNN。这里我就不安装了。具体可以参考这篇文章。
4、安装PyTorch
简介:PyTorch是一个开源的Python机器学习库,其前身是著名的机器学习库Torch。2017年1月,由Facebook人工智能研究院(FAIR)基于Torch推出了PyTorch,它是一个面向Python语言的深度学习框架,不仅能够实现强大的GPU加速,同时还支持动态神经网络,这是很多主流深度学习框架比如Tensorflow等都不支持的。PyTorch既可以看作加入了GPU支持的numpy,同时也可以看成一个拥有自动求导功能的强大的深度神经网络。除了Facebook外,它已经被Twitter、CMU和Salesforce等机构采用。作为经典机器学习库Torch的端口,PyTorch 为 Python 语言使用者提供了舒适的深度学习开发选择。
这里说明一下,下载的PyTorch要与CUDA的版本一致,我这里使用的CUDA版本是12.1,但是我在官方PyTorch中没有找到该版本的下载命令。然后我是从网上找到一个命令安装了PyTorch。
pip --trusted-host pypi.tuna.tsinghua.edu.cn install torch==1.10.1+cu102 torchvision==0.11.2+cu102 torchaudio==0.10.1 -f https://download.pytorch.org/whl/torch_stable.html
- 1
安装完成之后可以进入python环境,如果输入import torch没有报错,说明就可以了。
import torch
print(torch.__version__)
print(torch.cuda.is_available())
- 1
- 2
- 3
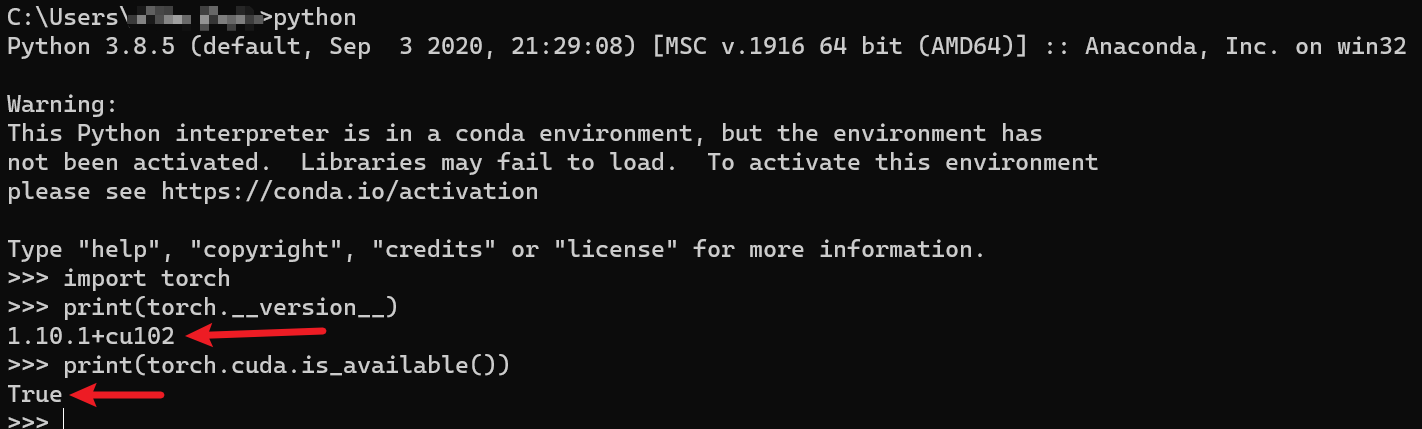
不过这里还是推荐大家下载与自己CUDA对应的版本。
5、安装whisper
安装whisper很简单,直接用一条命令即可。
pip install -U openai-whisper
- 1
不过使用这条命令安装会很慢,我们可以使用清华镜像。
pip install -U openai-whisper -i https://pypi.tuna.tsinghua.edu.cn/simple
- 1
6、whisper的使用
安装好后,我们使用下面的命令可以查看whisper如何使用。
whisper -h
- 1
我们现在就可以使用whisper来语音识别了。
whisper test.mp3 --model small --language Chinese
- 1
这里我们使用small模型,语言是中文,这样我们就可以把test.mp3音频文件转为文本并输出了。
我们可以指定输出的格式,默认是输出所有格式文件。
--output_format {txt,vtt,srt,tsv,json,all}
- 1
我们也可以直接传入视频来识别音频生成文件。
whisper test.mp4 --model small --output_format srt --language Chinese
- 1
如果你的显存不过用会报下面的错误。
RuntimeError: CUDA out of memory. Tried to allocate 226.00 MiB (GPU 0; 2.00 GiB total capacity;
1.34 GiB already allocated; 0 bytes free; 1.60 GiB reserved in total by PyTorch) If reserved
memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation.
See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
- 1
- 2
- 3
- 4
这个时候我们不要慌,我们还可以使用CPU,默认是使用GPU的,我们可以通过参数--device来指定使用CPU进行运算。
whisper test.mp4 --model small --output_format srt --device cpu --language Chinese
- 1
我们可以省略--language Chinese,这个时候可以自动识别出你音频的语言。
当我们使用CPU运算时,我们还可以指定使用的线程数量。
whisper test.mp4 --model small --output_format srt --device cpu --language Chinese --threads 8
- 1
7、总结
whisper对硬件的要不是很高,如果没有独显,也可以使用CPU来运行,但是使用CPU的运算算力不及GPU强。
写本篇文章主要是记录一下在本地安装whisper的过程。在安装过程遇到很多坑,这里记录一下,一则方便自己日后再次安装,二是方便看这篇文章的你。

