
- 1c++ 链表长度_Leetcode:刷完31道链表题的一点总结
- 2什么是软件安全性测试?如何进行安全测试?
- 3asp.net------C# MVC之接口返回json数据_asp.net返回json嵌套
- 4概念解析 | 威胁建模与DREAD评估:构建安全的系统防线_基于dread模型的风险分析:
- 5计算机科学与技术事业编考试,事业单位考试计算机科学与技术试题.doc
- 6软考-防火墙技术与原理_防火墙分为 工控防火墙和什么
- 7整理了27个Python人工智能库,建议收藏!
- 8Calendar类计算两个日期之间有多少天?_calendar 计算两个日期相差的天数
- 9【论文翻译】SOLD2: Self-Supervised Occlusion-Aware Line Description and Detection
- 10Python爬虫逆向案例:某天猫评论sign参数分析_淘宝sign参数
基于视觉的自动驾驶环境感知(单目、双目和RGB-D)_自动驾驶 视觉感知 地面线识别优势
赞
踩
视觉感知在自动驾驶中起着重要作用,主要任务之一是目标检测和识别。由于视觉传感器具有丰富的颜色和纹理信息,因此可以快速准确地识别各种道路信息。常用的技术基于提取和计算图像的各种特征,基于深度学习的方法具有更好的可靠性和处理速度,并且在识别复杂元素方面具有更大的优势。对于深度估计,视觉传感器由于其尺寸小和成本低,也被用于测距。单目相机使用来自单个视点的图像数据作为输入来估计对象深度,相比之下,立体视觉是基于视差和匹配不同视图的特征点,深度学习的应用也进一步提高了准确性。此外,SLAM可以建立道路环境模型,从而帮助车辆感知周围环境并完成任务。本文介绍并比较了各种目标检测和识别方法,然后解释了深度估计的发展,并比较了基于单目、立体和RGB-D传感器的各种方法,接下来回顾并比较了SLAM的各种方法。最后总结了当前存在的问题,并提出了视觉技术的未来发展趋势。
1. 应用背景与状况
环境感知是自动驾驶最重要的功能之一,环境感知的性能,如准确性、对光变化和阴影噪声的鲁棒性,以及对复杂道路环境和恶劣天气的适应性,直接影响自动驾驶技术的性能。自动驾驶中常用的传感器包括超声波雷达、毫米波雷达、激光雷达、视觉传感器等。尽管全球定位技术(如GPS、北斗、GLONASS等)相对成熟,能够进行全天候定位,但仍存在信号阻塞甚至丢失、更新频率低,以及在诸如城市建筑物和隧道的环境中的定位精度差的问题。
里程计定位具有更新频率快、短期精度高的优点,但长期累积误差较大。尽管激光雷达具有高精度,但也存在一些缺点,例如体积大、成本高和依赖天气。特斯拉和几家公司,如Mobileye、Apollo和MAXIEYE,使用视觉传感器进行环境感知。视觉传感器在自动驾驶中的应用有助于物体检测和图像处理,以分析障碍物和可驾驶区域,从而确保车辆安全到达目的地。与其它传感器相比,视觉图像尤其是彩色图像信息量极大,它们不仅包含物体的距离信息,还包含颜色、纹理和深度信息,从而能够通过信号检测同时进行车道线检测、车辆检测、行人检测、交通标志检测等。此外,不同车辆上的摄像头之间没有干扰。视觉传感器还可以实现同时定位和地图构建(SLAM)。
视觉环境感知在自动驾驶中的主要应用是目标检测识别、深度估计和SLAM。根据相机的工作原理,视觉传感器可以分为三大类:单目、立体和RGB-D。单目相机只有一个相机,立体相机有多个相机。RGB-D更复杂,除了能够捕捉彩色图像之外,它还搭载了几个不同的相机,可以读取每个像素与相机之间的距离。此外,视觉传感器与机器学习、深度学习和其它人工智能的集成可以获得更好的检测结果,本文将讨论以下三个方面。
1) 基于视觉的物体检测和识别,包括传统方法和基于深度学习的方法;
2) 基于单目、立体和RGBD的深度估计以及深度学习的应用;
3) 单目SLAM、立体SLAM和RGBD SLAM;
2. 目标检测与识别
1)传统方法
在自动驾驶中,识别道路、车辆和行人等道路要素,然后做出不同的决定是车辆安全驾驶的基础。目标检测和识别的工作流程如图1所示。图像采集由拍摄车身周围环境照片的相机进行,特斯拉使用了广角、中等焦距和长焦相机的组合。广角相机的视角约为150°,负责识别附近区域的大范围物体。中等焦距相机的视角约为50°,负责识别车道线、车辆、行人、红绿灯和其他信息。长焦相机的视角只有35°左右,但识别距离可以达到200~250m。它用于识别远处的行人、车辆、路标和其他信息,并通过多个相机的组合更全面地收集道路信息。

图像预处理消除了图像中的无关信息,保留了有用信息,增强了相关信息的可检测性,并简化了数据,从而提高了特征提取、图像分割、匹配和识别的可靠性。


为了完成图像中目标的识别,需要提取所需的特征,实现精确匹配,主要包括边缘特征、外观特征(轮廓、纹理、分散度和拓扑特征)、统计特征(如均值、方差、能量、熵等)和其它特征等。识别算法则是借助于匹配和机器学习方案!
2)基于深度学习的方法
与传统的目标检测和识别相比,深度学习需要基于大数据集的训练,但会带来更好的性能。传统的目标识别方法分别进行特征提取和分类器设计,然后将它们结合在一起。相比之下,深度学习具有更强大的特征学习和特征表示能力,通过学习数据库和映射关系,将相机捕获的信息处理到向量空间中,以便通过神经网络进行识别。

one-stage目标检测算法包括YOLO系列、SSD、Nanodet、YOLOX这类算法,two-stage算法主要包括Faster RCNN、Cascade RCNN范式。
3.深度估计
在自动驾驶系统中,适当的距离对于确保汽车的安全驾驶非常重要,因此需要从图像中进行深度估计。深度估计的目标是获得到物体的距离,并最终获得深度图,该深度图为一系列任务(如3D重建、SLAM和决策)提供深度信息,目前市场上主流的距离测量方法是单目、立体和基于RGBD相机的。
1)传统深度估计方法
对于固定的单目相机和物体,由于无法直接测量深度信息,因此,单目深度估计是先识别,然后测量距离。首先,通过图像匹配进行识别,然后根据数据库中目标的大小进行距离估计。由于在识别和估计阶段都需要与已建立的样本数据库进行比较,因此它缺乏自学习功能,并且感知结果受到数据库的限制,并且通常忽略未标记的目标,这导致了无法识别不常见目标的问题。然而,对于应用于自动驾驶的单目深度估计,目标主要是已知目标,例如车辆和行人,因此可以使用几何关系方法、数据回归建模方法和逆透视映射,并且可以通过车辆的运动来实现基于SFM(来自运动的结构)的单目高度估计。目前,单目相机由于其成本低、检测速度快、能够识别特定障碍物类型、算法成熟度高和识别准确,正逐渐成为视觉测距的主流技术。
几何关系法使用针孔相机成像原理。它使用沿着直线的光传播将三维世界中的物体投射到二维成像平面上,如图9所示,车辆距离可以通过图中的等式来计算。然而,要求摄像机的光轴必须与水平地面平行,这在实践中很难保证。
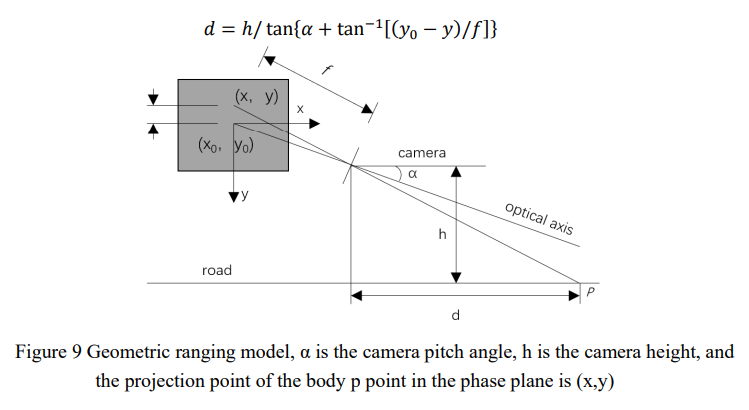
数据回归建模方法通过拟合函数来测量距离,以获得像素距离和实际距离之间的非线性关系。逆透视映射不仅广泛应用于单目测距,也广泛应用于环视相机。通过将透视图转换为“鸟瞰图”,如图10所示。由于“鸟瞰图”与真实道路平面具有线性比例关系,因此通过校准比例因子,可以根据逆透视变换视图中的像素距离计算实际车辆距离,这简单且易于实现。

然而,没有考虑汽车的俯仰和偏航运动,并且俯仰角的存在将使反向透视变换俯视图无法恢复实际道路俯视图的平行度,从而产生较大的测距误差。[91]提出了一种基于可变参数逆透视变换的距离测量模型,该模型动态补偿摄像机的俯仰角,不同道路环境下的车辆测距误差在5%以内,实时鲁棒性高。然而,在没有车道线和清晰道路边界的非结构化道路上,无法计算摄像机的俯仰角。[92]中提出了一种无累积误差的俯仰角估计方法,该方法使用Harris角点算法和金字塔Lucas Kanade方法来检测相机相邻帧之间的特征点。通过特征点匹配和成对几何约束求解其相机旋转矩阵和平移向量,并使用高斯-牛顿方法进行参数优化。然后,从旋转矩阵分解俯仰角速率,并从平移向量计算俯仰角。
SFM(Structure From Motion)是通过使用诸如多视图几何优化之类的数学理论从2D图像序列中确定目标的空间几何关系,以通过相机移动恢复3D结构。SFM方便灵活,但在图像序列采集中遇到场景和运动退化问题。根据图像添加顺序的拓扑结构,可以将其分为增量/顺序SFM、全局SFM、混合SFM和分层SFM。此外,还有语义SFM和基于深度学习的SFM。

另一方面,混合SFM结合了增量SFM和全局SFM的优点,并逐渐成为一种趋势。该pipelines可以概括为摄像机旋转矩阵的全局估计、摄像机中心的增量计算以及针对全局敏感问题的基于社区的旋转平均方法。与混合SFM相比,PSFM[109]将相机分为多个集群,在大规模场景和高精度重建方面具有优势。[110]建议SFMLearner使用光度一致性原理来估计每个帧的深度和姿态。基于此,[111]提出了SFM网络,添加了光流、场景流和3D点云来估计深度。

单目摄像头具有较高的接近识别率,因此被广泛应用于正面碰撞预警系统(FCWS),但它的环境适应性较差,在车辆行驶时,摄像头会因颠簸而抖动。在[113]中,对三种场景(静止、慢速移动和制动)进行了比较实验,结果将TTC的算术平均值作为警报阈值,这可以有效地避免摄像机抖动等异常情况,因此可以应用于更复杂的范围。[114]采用了消失点检测、车道线提取和3D空间车辆检测的组合来实现距离测量。然而,在照明不足和前方严重障碍物遮挡的情况下,距离误差显著增加。在[115]中,提出在检测和测距车辆前方的物体之前,使用单目视觉里程表结合GPS路面特征和几何测量来估计系统的绝对比例和姿态,并且可以使用物体的3D形状变化来实现相机本身和物体的定位。
2)基于深度学习的方式
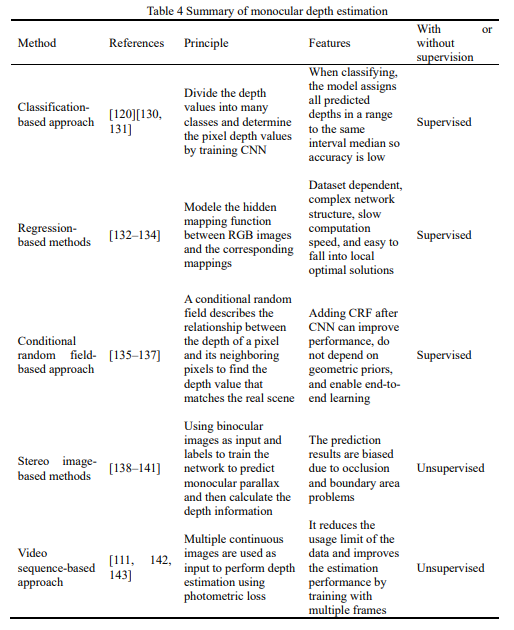
基于深度学习的单目深度估计的输入是捕获的原始图像,并且输出是深度图,其中每个像素值对应于输入图像的场景深度。基于深度学习的单目深度估计算法分为有监督学习和无监督学习,监督学习能够高精度地从单个图像和场景的结构中恢复尺度信息,因为它们使用地面真实深度值直接训练网络,但需要KITTI、Open Image、Kinetics、JFT-300M等数据集。
[116]使用马尔可夫随机场(MRF)来学习输入图像特征和输出深度之间的映射关系,但RGB图像和深度之间的关系需要人为假设。该模型难以模拟真实世界的映射关系,因此预测精度有限。2014年,[117]提出在多层中卷积和下采样图像,以获得整个场景的描述性特征,并使用它们来预测全局深度。然后,预测图像的局部信息由第二分支网络细化,其中全局深度将被用作局部分支的输入,以帮助预测局部深度。2015年,[118]基于上述工作提出了统一的多尺度网络框架。该框架使用更深的基础网络VGG,并使用第三精细尺度网络来进一步添加详细信息,以提高分辨率,从而更好地进行深度估计。2016年,[119]使用卷积神经网络模型进行车辆检测和定位,然后基于单目视觉原理计算距离。2018年,[120]提出了DORN框架,将连续深度值划分为离散区间,然后使用完全连接的层对卷积进行解码和膨胀,以进行特征提取和距离测量。同年,[121]比较了激光雷达,将输入图像转换为与激光雷达生成的点云数据相似的点云,然后使用点云和图像融合算法来检测和测量距离。[122]提议的MonoGRNet,它通过ROIAlign获取对象的视觉特征,然后使用这些特征来预测对象的3D中心的深度。2019年,[123]通过提出MonoGRNetV2将centROId扩展到多个关键点并使用3D CAD对象模型进行深度估计,对其进行了改进。[124]提出了BEV-IPM将图像从透视图转换为鸟瞰图(BEV)。在BEV视图中,基于YOLO网络检测底框(物体和路面之间的接触部分),然后使用神经网络预测的Box精确估计其距离。[125]建议使用卷积神经网络输出的多尺度特征图,基于两个分辨率的深度估计来预测不同分辨率的深度图,并且通过连续的MRF融合不同分辨率的特征图,以获得与输入图像相对应的深度图。[126]提出了3D-RCNN,其首先使用PCA缩小参数空间,然后基于R-CNN预测的每个目标低维模型参数生成2D图像和深度图。然而,只有在较低的空间分辨率下,CNN才能更好地处理全局信息。单目深度估计增强的有效性的关键是应该对输出值进行充分的全局分析,因此,2020[127]提出了AdaBins结构,它结合了CNN和transformer。利用transformer出色的全局信息处理能力,结合CNN的局部特征处理能力,深度估计的精度大大提高。

根据[128],端到端卷积神经网络框架用于车辆测距,以应对由于光变化和视点变化引起的测量误差。该算法基于将RGB信息转换为深度信息,结合检测模块作为输入,并最终基于距离模块预测距离。它的鲁棒性更好,并减少了由于复杂的驾驶环境(如光线不足和遮挡)导致的测距误差。2021,[129]提出了FIERY,一种端到端BEV概率预测模型,该模型将摄像机捕获的当前状态和训练中的未来分布输入到卷积GRU网络进行推理,作为估计深度信息和预测未来多模轨迹的一种方法。
3)传统双目深度估计
与单目相机不同,立体深度估计依赖于平行排列的相机产生的视差。它可以通过找到同一物体的点并进行精确的三角测量来获得场景中可驾驶区域和障碍物的深度信息。尽管没有LIDAR深度估计那么远,但它更便宜,并且可以在有公共视野的情况下重建环境的3D信息。然而,立体摄像机要求摄像机之间的高同步率和采样率,因此技术难点在于立体校准和立体定位,其中,使用最多的是双目摄像头,如图13。

三目相机的工作原理相当于使用两个双目立体视觉系统,如图14所示,它们沿着相同的方向和距离放置。三目立体视觉系统具有窄基线和宽基线。窄基线是左侧和中间相机的线,宽基线是左侧相机和右侧相机的线。窄基线增加了两个相机的共同视野,宽基线在每个可见距离处具有更大的最大视野[144]。三目立体视觉系统的三个摄像头从不同角度拍摄三幅图像,然后使用立体视觉匹配算法获得深度信息!

与单目测距类似,立体测距的工作原理是当实际物体被相机捕捉到图片中时,对其进行仿射变换。该过程包括相机的校准、图像的立体校正、视差图的计算和深度图的计算。由于视差,立体视觉系统需要对不同图像中捕获的对应点进行立体匹配,立体匹配主要分为全局匹配和局部匹配。虽然全局匹配具有较高的精度和较好的鲁棒性,但计算速度较慢,不能满足实时性要求,因此局部匹配主要应用于车辆。
4)基于深度学习的双目深度估计
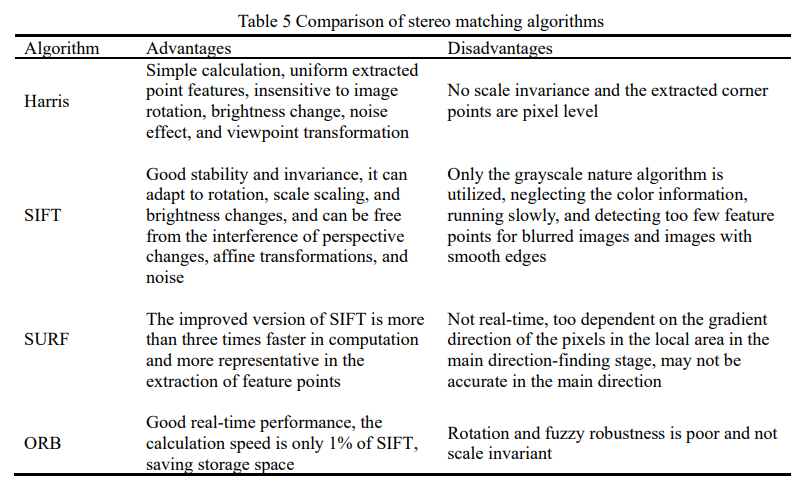
传统的基于立体的深度估计是通过匹配多幅图像的特征来实现的,尽管进行了广泛的研究,但在处理遮挡、无特征区域或具有重复图案的高纹理区域时,它仍然存在精度差的问题。近年来,基于深度学习的立体深度估计发展迅速,通过使用先验知识来表征特征作为学习任务,深度估计的鲁棒性得到了极大的提高。
2016年,[152]提出MC-CNN通过标记数据来构建训练集,在每个像素点生成正样本和负样本,其中正样本来自具有相同深度的两个图像块,负样本来自具有不同深度的图像块,然后训练神经网络来预测深度。然而,它的计算依赖于局部图像块,这在一些纹理较少或图案重复的区域中引入了较大的误差。因此,2017年[153]提出了GC Net,它对左图像和右图像执行多层卷积和下采样操作,以更好地提取语义特征,然后使用3D卷积处理Cost Vollumn,以提取左图像和右侧图像之间的相关信息以及视差值。2018年,[154]提出了PSMNet,其使用金字塔结构和零卷积来提取多分幅方面信息,并扩展感知领域和多个堆叠的HourGlass结构,以增强3D卷积,从而视差的估计更依赖于不同尺度的信息而不是像素级的局部信息。因此,可以获得更可靠的视差估计。[155]提出了MVSNet,其利用3D卷积运算成本体积正则化。它首先输出每个深度的概率。然后,它找到深度的加权平均值以获得预测的深度信息,使用多个图像之间的重建约束(光度和几何一致性)来选择预测的正确深度信息。2019年,[156]提出了基于它的P-MVSNet,它通过具有各向同性和各向异性3D卷积的混合3D Unet实现了更好的估计结构。然而,这些网络使用离散点进行深度估计,从而引入误差。[157]考虑到现有立体网络(例如,PSMNet)产生的视差图在几何上不一致,他们提出StereoDRNet,其将几何误差、光度误差和未确定视差作为输入,以产生深度信息并预测遮挡部分。这种方法提供了更好的结果,并显著减少了计算时间。2020年,[158]提出了一种用于连续深度估计的CDN。除了离散点的分布之外,还估计每个点处的偏移,并且离散点和偏移一起形成连续视差估计。
5)基于RGBD测距
RGBD相机通常包含三个相机:彩色相机、红外发射器相机和红外接收器相机,原理如图15所示。与通过视差计算深度的立体相机相比,RGB-D可以主动测量每个像素的深度。此外,基于RGBD传感器的3D重建具有成本效益和准确性,这弥补了单目和立体视觉传感器估计深度信息的计算复杂性和缺乏保证的准确性。
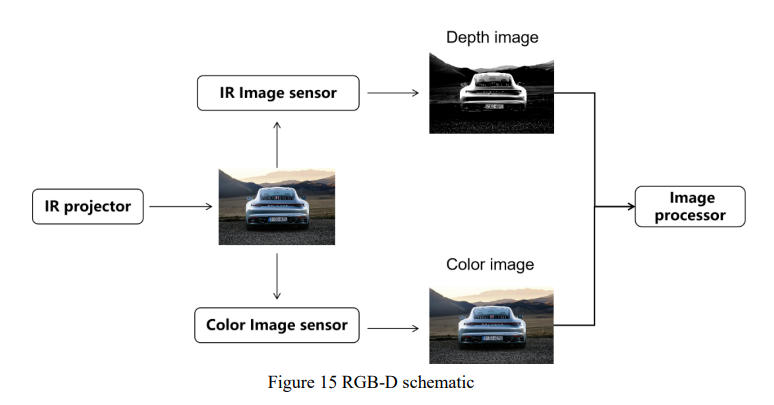
RGB-D测量像素距离,可分为红外结构光法和飞行时间(TOF)法。结构光的原理是红外激光器向物体表面发射一些具有结构特征的图案。然后红外相机将收集由于表面深度不同而产生的图案变化。与依赖于物体本身的特征点的立体视觉不同,结构光方法表征了透射光源,因此,特征点不会随场景而改变,这大大降低了匹配难度。根据不同的编码策略,有时间编码、空间编码和直接编码。时间编码方法可分为二进制码[160]、n值码[161]等。它具有易于实现、高空间分辨率和高3D测量精度的优点,但测量过程需要投影多个模式,因此它仅适用于静态场景测量。空间编码方法只有一个投影图案,并且图案中每个点的码字是基于其周围相邻点的信息(例如,像素值、颜色或几何)获得的。它适用于动态场景3D信息采集,但在解码阶段丢失空间相邻点信息会导致错误和低分辨率。空间编码分为非正式编码[162]、基于De Bruijn序列的编码[163]和基于M阵列的编码[164]。对每个像素执行直接编码方法。然而,它在相邻像素之间的色差很小,这对噪声非常敏感。它不适用于动态场景,包括[165]提出的灰色直接编码和[166]提出的彩色直接编码。
TOF通过连续向观察到的物体发射光脉冲,然后接收从物体反射回来的光脉冲。根据调制方法的不同,它通常可以分为脉冲调制和连续波调制。测量深度后,RGB-D根据生产时的单个相机位置完成深度和彩色像素之间的配对,并输出一对一的彩色图和深度图。可以在同一图像位置读取颜色信息和距离信息,并且可以计算像素的3D相机坐标以生成点云。然而,RGB-D容易受到日光或其他传感器发出的红外光的干扰,因此不能在室外使用。多个RGB D可以相互干扰,并且在成本和功耗方面具有一些缺点。
4.视觉SLAM
SLAM(同时定位和映射)分为激光SLAM和视觉SLAM。视觉SLAM使用视觉传感器作为唯一的环境感知传感器。单个视觉传感器的三角测量算法或多个视觉传感器的立体匹配算法可以以良好的精度计算深度信息。同时,由于它包含丰富的颜色和纹理信息,并具有体积小、重量轻、成本低等优点,因此成为当前的研究趋势。视觉SLAM根据视觉传感器类别分为单目视觉SLAM、立体视觉SLAM和RGB-D视觉SLAM。
1)单目SLAM
单目SLAM是一种简单、低成本且易于实现的系统,使用相机作为唯一的外部传感器。根据是否使用概率框架,单眼视觉SLAM分为两种类型。基于概率框架的单眼视觉SLAM构造联合后验概率密度函数,以描述给定从初始时刻到当前时刻的控制输入和观测数据的相机姿态和地图特征的空间位置,由于SLAM应用场景的未知复杂性,其目前被广泛使用。[167]提出了一种基于示例滤波器的SLAM,该SLAM分解运动路径的联合后验分布估计问题,并将其映射为具有示例滤波器的运动路径估计问题和已知路径下的路标估计问题。然而,为了确保定位精度,在复杂的场景和运动中需要更多的粒子,这大大增加了算法的复杂性,重新采样往往会导致样本耗尽和其他问题。[168]通过边缘化每个粒子特征的位置来改进粒子滤波方法,以获得该特征的观测序列用于更新粒子权重的概率,并且不需要状态向量中包括的特征位置。因此,即使在特征密集的环境中,算法的计算复杂度和样本复杂度仍然很低。[169]提出了基于扩展卡尔曼滤波的MonoSLAM,其使用稀疏特征图来表示环境,并通过概率估计来主动搜索和跟踪特征点。然而,EKFSLAM算法具有高复杂性、较差的数据关联问题和较大的线性化处理误差。[170]提出了FastSLAM,它仍然使用EKF算法来估计环境特征,但通过将移动机器人的姿态表示为粒子并将状态估计分解为采样部分和分辨率部分,计算复杂性大大降低。然而,它使用SLAM的过程模型作为采样粒子的直接重要函数可能会导致粒子退化的问题,这降低了算法的准确性。因此,[171]中提出的FastSLAM2.0使用EKF算法递归地估计移动机器人姿态,获得估计的均值和方差,并使用它们构建高斯分布函数作为重要函数。因此,解决了颗粒降解问题。对于具有非概率框架的单眼视觉SLAM,[172]提出了一种基于关键帧的单眼视力SLAM系统PTAM。该系统利用一个线程跟踪相机姿态,另一个线程绑定和调整关键帧数据以及所有特征点的空间位置。双线程并行性确保了算法的准确性和计算的效率。[173]提出了基于PTAM的ORB-SLAM,添加了第三个并行线程、环回检测线程和环回检测算法,可以减少SLAM系统产生的累积误差。由于ORB特征的旋转和尺度不变性,保证了每个步骤的内生一致性和良好的鲁棒性。图16显示了两者的比较。[174175]提出了ORB-SLAM2和ORB-SLAM3,并将其扩展到双筒望远镜、RGBD和鱼眼相机。[176]利用相机最近捕获的固定数量的图像作为局部束调整优化的关键帧,以实现SLAM。[177]提出了LIFT-SLAM,它将基于深度学习的特征描述符与传统的基于几何的系统相结合。使用神经网络从图像中提取特征,其基于从学习中获得的特征提供更准确的匹配。

2)双目SLAM
立体视觉SLAM使用多个摄像头作为传感器。由于绝对深度未知,单目SLAM无法获得运动轨迹和地图的真实大小。stereo可以通过视差简单而准确地计算场景中地标的真实3D坐标,然而,它需要更高精度的校准参数,并且成本高昂。在[178]中,通过固定基线提出的LSD-SLAM可以避免单眼SLAM中通常出现的尺度漂移,此外,通过组合两个视差源可以估计欠约束像素的深度。应用于立体视觉SLAM的ORB-SLAM2使用双线程提取左右图像的ORB特征点,然后计算双目视觉特征点并执行匹配。[179]提出了基于ORB-SLAM 2.0的DMS-SLAM,使用滑动窗口和基于网格的运动统计(GMS)特征匹配方法来查找静态特征位置,并在执行速度上有所提高。然而,基于点特征的算法在低纹理环境中不能很好地工作,因此[180]提出了基于ORB-SLAM2和LSD的PL-SLAM组合点和线特征,这可以保证在更广泛的场景中的鲁棒性能。[181]提出了一种立体视觉双四元数视觉SLAM框架,它使用贝叶斯框架进行姿态估计,对于地图的点云和光流,DQV-SLAM使用ORB函数在动态环境中实现可靠的数据关联。与基于过滤器的方法相比,性能更好。[182]提出了SOFT,一种基于特征跟踪的立体视觉里程计算。SLAM是通过位姿估计和基于特征点的位姿图的构建来实现的,与单目ORB相比,系统的全局一致性得到了保证。然而,当目标距离较远时,双目相机会退化为单目相机,因此,近年来围绕单眼ORB进行了大量的研究。
3)RGB-D SLAM
RGB-D视觉SLAM使用RGB-D传感器作为图像输入设备。该传感器集成了彩色相机和红外相机,以捕获彩色图像和相应的深度图像,因此正逐渐成为SLAM的趋势。[183]从RGB图像中提取特征点,然后将其与深度信息相结合,将特征点逆映射到3D空间,然后使用ICP(点云匹配算法)优化初始姿态。然而,当处于光强度变化的环境中时,RGB-D数据通常缺乏有效性,因此现在将其与IMU传感器计算的状态增量进行融合[184],以获得更好的结果。当前的深度SLAM由两部分组成,前端和后端。前端从相邻帧之间的图像中估计相机运动,并恢复场景的空间结构,而后端在不同时刻接收视觉里程计输出的相机姿态,以及来自环回检测的信息,并优化它们以获得全局一致的轨迹和地图。[185]使用Kinect RGB-D进行3D环境重建,KinectFusion技术可以将采集的每帧图像数据实时添加到3D地图中。尽管如此,它仍然需要高硬件配置,因为它占用了巨大的内存空间,并且SLAM的性能会长期恶化。[186]基于此提出了RGB-D SLAM问题的改进和优化。系统前端从每个帧的RGB图像中提取特征,结合RANSAC和ICP算法以获得并使用EMM(环境测量模型)模型来验证运动估计,后端基于姿势图优化构建地图。

5参考
[1] Vision-Based Environmental Perception for Autonomous Driving.

