
- 1解决pycharm安装cv2模块无法安装的方法_pycharm的pytorch框架下安装不了cv2
- 2加解密工具类_aes加解密工具类
- 3OAuth 2 和 OAuth 2.1 之间的差异_oauth2.1
- 4原创 | 不瞒你说,我也参加过培训
- 5程序员的“高考”_蔺相如司马相如魏无忌长孙无忌 程序员
- 6PotatoPie 4.0 实验教程(29) —— FPGA实现摄像头图像均值滤波处理
- 7使用 pyarrow 将parquet转成spark能用的parquet_pyarrow.parquet
- 8java.net.ConnectException: Connection refused: no further information,zookeeper连接不上问题解决
- 9096-对象和对象使用-【视频讲解】_object detection in videos by high quality object
- 10Ubuntu关闭防火墙、关闭selinux、关闭swap_ubuntu关闭selinux
JupyterLab搭建Spark开发环境指南_Scala版本_jupyter notebook pyspark 环境配置
赞
踩
Spark运行在Jupyter Notebook中使用Scala指南
-
PySpark环境搭建较为容易,Scala更适合Spark开发。本文记录了成功搭建Scala环境的核心流程及主要配置项。
-
本文各版本选择,自选版本时请保证各工具之间版本适配。
| 软件/语言/工具 | 版本 |
|---|---|
| Java | jdk1.8.0_291 |
| Python3 | 3.10.6 |
| Scala | scala-2.12.12 |
| Spark | spark-3.1.2-bin-hadoop2.7 |
第一章 Mac安装Python
要在 MacOS 上更新或替换 Python 版本,可以按照以下步骤进行操作:
-
直接官网安装,官网下载地址。本文选择3.10.6版本,连接。和Windows一样,可视化界面安装。
安装完成后,运行
python3 --version和which python3查看版本和安装地址。或者借助Homebrew安装Python (推荐手动安装,可以清楚选择版本更容易适配)
brew install python@3.9- 1
-
验证 Python 版本:运行以下命令,验证新的 Python 版本是否正确安装和配置:
python --version- 1
这将显示新安装的 Python 版本号。
which python3- 1
也可以查看版本和安装地址。
-
pip 是 Python 的包管理器,用于安装 Python 包(如果你的 Python 版本较新,可能已经自带了 pip)。查看是否有pip。如果没有则需要手动安装 pip:
pip --version pip list- 1
- 2
-
配置环境变量前,首先查看安转目录:
pip3 show pip- 1
location部分会展示安装目录。
-
配置环境变量参考第二章
注意:在进行这些更改之前,请确保了解你的系统和其他应用程序对特定 Python 版本的依赖关系,并确保更改不会影响到其他项目或应用程序的正常运行。
第二章 新版Mac配置环境变量
-
环境变量加到.zshrc
Mac新系统默认终端是zsh不再是bash,默认启动的文件是.zshrc不是.bash_profile。(如果你的Mac仍然是bash则直接在.bash_profile添加环境变量) -
会出现的问题:每次打开Terminal都需要
source ~/.bash_profile,才能使用环境变量配置好的命令。比如jupyter-notebook
解决:
1、打开.zdhrc:vim ~/.zshrc
2、添加一行:source ~/.bash_profile,保存退出
3、终端输入:source ~/.zshrc,此时你在 .bash_profile中添加的环境变量都会一直作用成功
4、打开.bash_profile:vim ~/.bash_profile
5、添加环境变量:
本文涉及到的环境变量如下所示
# Java8
export JAVA_HOME=/Library/Java/JavaVirtualMachines/jdk1.8.0_291.jdk/Contents/Home
export PATH=$JAVA_HOME/bin:$PATH
# Python3
export PATH="/Library/Frameworks/Python.framework/Versions/3.10/bin:$PATH"
export PATH="/Library/Frameworks/Python.framework/Versions/3.10/libexec/bin:$PATH"
alias python="python3"
alias pip="pip3"
# Scala
export SCALA_HOME=/Users/cyp/SoftwareFolder/scala-2.12.12
export PATH=$PATH:$SCALA_HOME/bin
# Spark
export SPARK_HOME=/Users/cyp/SoftwareFolder/spark-3.1.2-bin-hadoop2.7
export PATH=$SPARK_HOME/bin:$PATH
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
第三章 安装 Jupyter Lab
JupyterLab比Jupyter可视化更好,本文选择安装JupyterLab。
要在 Mac 上安装 JupyterLab,你可以按照以下步骤进行操作:
-
前提:安装 Python/更新pip:见第一大步骤
-
安装 JupyterLab:
pip install jupyterlab- 1
这将安装 JupyterLab 及其依赖项。
-
启动:
jupyter lab- 1
这将启动 JupyterLab 服务器,并自动在你的默认浏览器中打开 Jupyter 用户界面。
-
创建一个新的 Notebook:在 Jupyter 用户界面中,点击 “New” 按钮,然后选择一个支持的编程语言(如Python、R、Julia等)创建一个新的 Notebook。
-
关闭
ctrl+c- 1
请注意,如果在 Mac 上使用多个 Python 版本,可能需要使用适当的命令和环境来确保在所需的 Python 环境中安装和运行 JupyterLab。
第四章 安装Scala/Spark/Scalakernel
当在 JupyterLab 中使用 Scala 语言构建和运行 Spark 时,可以使用 Scala kernel 或者使用 Toree kernel。
-
安装 JupyterLab:参考第三章
-
安装Scala,直接官网下载。配置环境变量。
-
安装Spark,直接官网下载。配置环境变量。
spark3.1.2 ->scala2.12.12
-
安装 Scala kernel:在 JupyterLab 中运行 Scala,你需要安装 Scala kernel:
pip install spylon-kernel- 1
-
安装Toree内核:Toree是一个支持Spark的Jupyter内核,可以在Scala环境中运行:
pip install toree- 1
-
在终端中运行以下命令以将 Toree 内核添加到 Jupyter Lab 中:
jupyter toree install --user --spark_home=/Users/cyp/SoftwareFolder/spark-3.1.2-bin-hadoop2.7- 1
-
验证
jupyter kernelspec list- 1
如果显示 apache_toree_scala 表示安转成功
第五章 运行/基本使用实例
-
启动JupyterLab:在完成 Scala kernel 的安装后,启动 JupyterLab 服务器。打开终端或命令提示符,导航到你希望的目录,并运行以下命令:
jupyter lab- 1
这将启动 JupyterLab 服务器,并自动在你的默认浏览器中打开 Jupyter 用户界面。
http://localhost:8888/lab
-
创建一个新的 JupyterLab:在 Jupyter 用户界面中,点击 “New” 按钮,然后选择 “Scala” 创建一个新的 Scala Notebook。
-
编写和运行 Scala 代码:在 Scala Notebook 中,你可以逐个单元格编写和运行 Scala 代码。每个单元格可以包含 Scala 代码、文本或可视化结果。你可以按顺序运行单元格,以交互方式执行代码并查看结果。
在 Scala Notebook 中,你可以使用 Spark API 来构建和执行 Spark 应用程序。以下是一个简单的示例:
import org.apache.spark.{SparkConf, SparkContext} import org.apache.spark.rdd.RDD object WordCount { def main(args: Array[String]): Unit = { val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("WordCountWrites") val sc: SparkContext = new SparkContext(conf) val inputRdd: RDD[String] = sc.makeRDD(List( "spark hello", "hive", "hadoop hbase", "spark hadoop", "hbase")) val flatRDD: RDD[String] = inputRdd.flatMap(x => x.split(" ")) // (_.split(" ")) val kvRdd: RDD[(String, Int)] = flatRDD.map(x => (x, 1)) //(_,1) //第一种 reduceByKey val reduceRes1: RDD[(String, Int)] = kvRdd.reduceByKey((x, y) => x + y) //(_+_) reduceRes1.collect().foreach(println) } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
-
运行效果展示,一步一步运行。
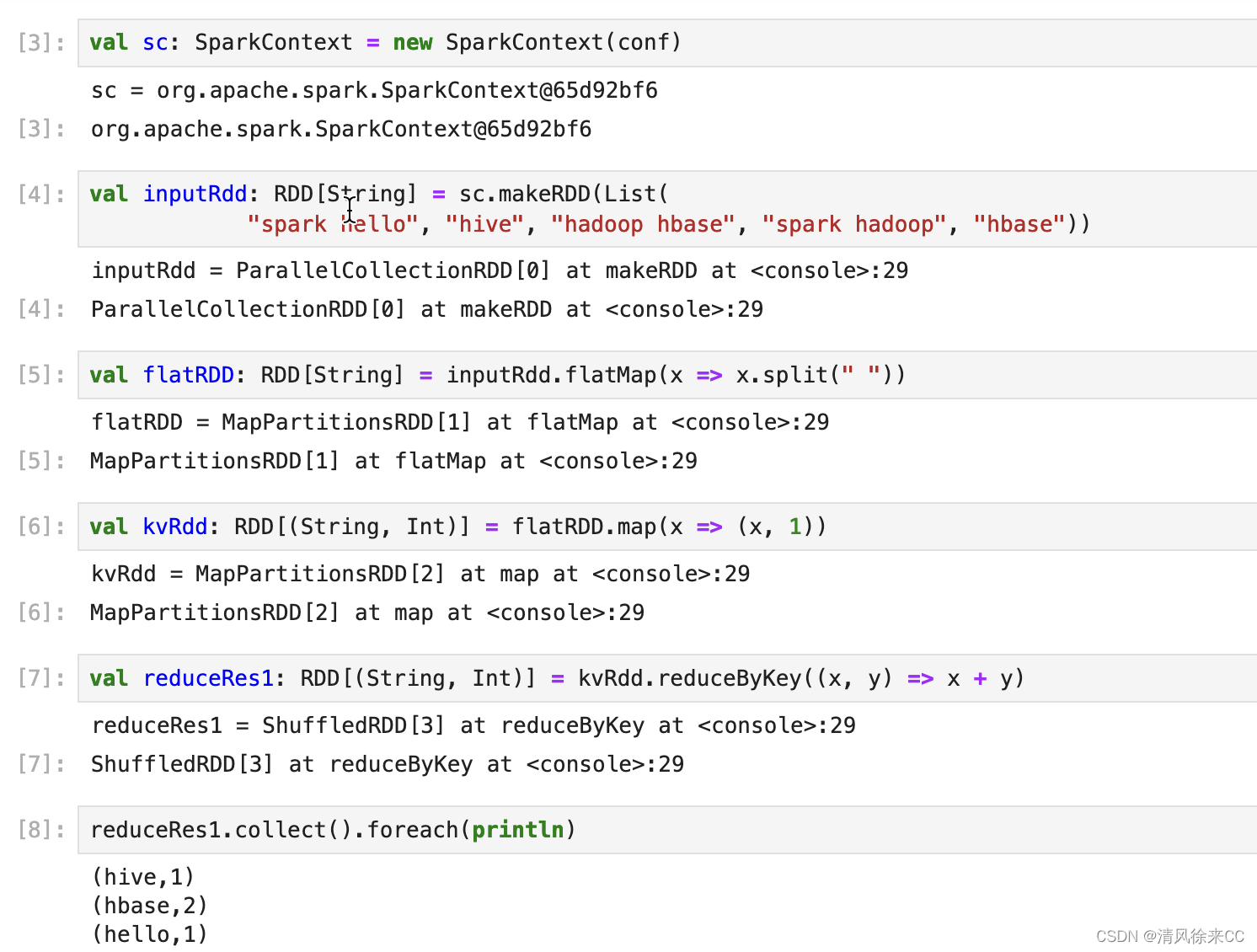
以上是使用 Scala 在 JupyterLab 中构建和运行 Spark 的基本步骤。

